An Efficient vLLM-Based Inference Pipeline for Unified Audio Understanding and Generation
Pith reviewed 2026-07-03 05:02 UTC · model grok-4.3
The pith
A vLLM extension for speech models handles delay patterns and multi-stream sampling while keeping classifier-free guidance at 80 percent of normal throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
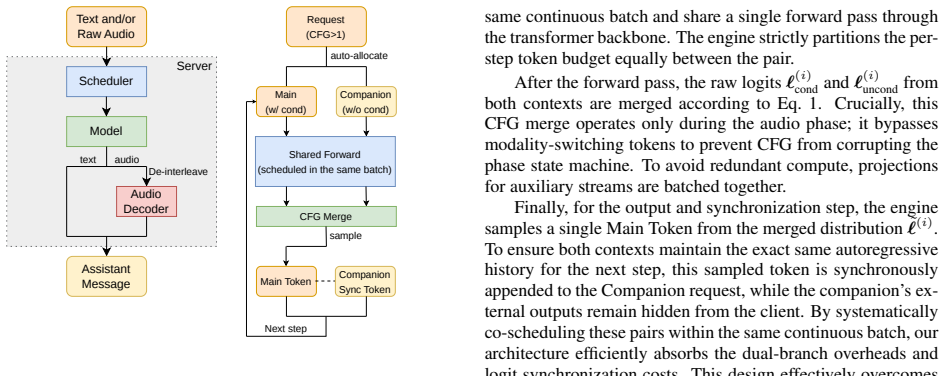
The paper claims that extending vLLM's autoregressive loop to perform delay-pattern de-interleaving and coordinated multi-stream sampling, together with an on-GPU acoustic decoder, produces a unified pipeline for speech understanding and generation. By placing paired conditional and unconditional requests into the same continuous batch and merging their logits, the implementation of classifier-free guidance reaches 80 percent of the throughput measured without guidance, even after absorbing the cost of dual requests and merging.
What carries the argument
Co-scheduling of paired conditional and unconditional requests inside vLLM's continuous batching loop, combined with native extensions for delay-pattern de-interleaving and multi-stream sampling.
If this is right
- Speech language models that use delay patterns or multi-token prediction can now run on a standard high-throughput engine instead of requiring a custom loop.
- Classifier-free guidance becomes practical for audio generation because the throughput penalty drops from roughly 50 percent to 20 percent.
- End-to-end waveform synthesis can be performed inside the same inference batch that produces the token sequences.
- The same continuous-batching infrastructure can serve both text-only understanding requests and full audio generation requests without separate code paths.
Where Pith is reading between the lines
- The co-scheduling pattern could be reused for other conditional-generation techniques that double the number of forward passes.
- Similar batch-level pairing might reduce guidance overhead in non-audio multimodal models that currently avoid CFG for speed reasons.
- Once the extensions are open-sourced, developers can test whether the same 80-percent retention holds when the acoustic decoder is replaced by a different waveform model.
Load-bearing premise
The added code for de-interleaving delay patterns and running coordinated multi-stream sampling fits into vLLM's existing autoregressive loop without large extra overhead or correctness problems.
What would settle it
Measure end-to-end tokens per second on the same hardware and batch size with the CFG co-scheduling turned on versus turned off; the ratio must stay near 80 percent for the central performance claim to hold.
Figures
read the original abstract
While Large Multimodal Models excel in comprehension, high-throughput inference engines lack native support for multimodal generation. This is severe in Speech Language Models, where generating multi-layered audio tokens via decoupled AR+NAR or synchronous Multi-Token Prediction (MTP) with delay-pattern interleaving conflicts with standard single-stream loops. We present a vLLM-based inference pipeline for unified speech understanding and generation. We extend autoregressive decoding to natively execute delay-pattern de-interleaving and coordinated multi-stream sampling, integrating an on-GPU acoustic decoder for end-to-end waveform synthesis. Crucially, we overcome the shared intuition that Classifier-Free Guidance (CFG) halves throughput. By co-scheduling paired conditional and unconditional requests within a continuous batch, our CFG implementation sustains 80% of non-CFG throughput, absorbing dual-request and logit merging overheads. We open-source our framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a vLLM-based inference pipeline for unified speech understanding and generation in Large Multimodal Models. It extends the autoregressive decoding loop to support delay-pattern de-interleaving and coordinated multi-stream sampling for multi-layered audio tokens, integrates an on-GPU acoustic decoder for end-to-end waveform synthesis, and implements Classifier-Free Guidance (CFG) via co-scheduling of paired conditional and unconditional requests within continuous batching, claiming this sustains 80% of non-CFG throughput while absorbing dual-request and logit-merging overheads. The framework is open-sourced.
Significance. If the empirical throughput result and integration claims hold under proper benchmarking, the work would provide a practical engineering contribution to high-throughput inference for speech language models, addressing the lack of native multimodal generation support in engines like vLLM. The open-sourcing of the framework is a positive aspect that enables reproducibility and further development in the field.
major comments (1)
- [Abstract] Abstract: The central empirical claim that co-scheduling paired conditional/unconditional requests sustains 80% of non-CFG throughput is stated without any measurements, error bars, baselines, implementation details, or evaluation section referenced. This absence makes it impossible to assess whether the dual-request and logit merging overheads are actually absorbed as described or if the extensions for delay-pattern de-interleaving integrate without correctness issues.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback highlighting the need for clearer empirical grounding in the abstract. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that co-scheduling paired conditional/unconditional requests sustains 80% of non-CFG throughput is stated without any measurements, error bars, baselines, implementation details, or evaluation section referenced. This absence makes it impossible to assess whether the dual-request and logit merging overheads are actually absorbed as described or if the extensions for delay-pattern de-interleaving integrate without correctness issues.
Authors: We agree the abstract as written does not reference the supporting measurements or evaluation section, which limits immediate verifiability of the 80% throughput claim and the overhead absorption. The full manuscript presents these results in Section 4 (including throughput comparisons against non-CFG baselines, multi-run error bars, and implementation details on co-scheduling and logit merging) and describes the delay-pattern de-interleaving and multi-stream sampling extensions in Section 3. We will revise the abstract to explicitly reference Section 4 and briefly note the measured throughput retention, while ensuring the claim is tied to the reported experiments rather than stated in isolation. revision: yes
Circularity Check
No significant circularity; empirical engineering result
full rationale
The paper presents an engineering implementation extending vLLM for multimodal audio generation, with the central claim being an empirical throughput measurement (80% of non-CFG) under co-scheduling of conditional/unconditional pairs. No equations, fitted parameters, predictions, or derivation chains are present in the provided text. The claim does not reduce to any self-definition, self-citation load-bearing step, or renamed known result; it is a direct report of measured performance after code changes. No load-bearing mathematical steps exist to inspect for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An Efficient vLLM-Based Inference Pipeline for Unified Audio Understanding and Generation
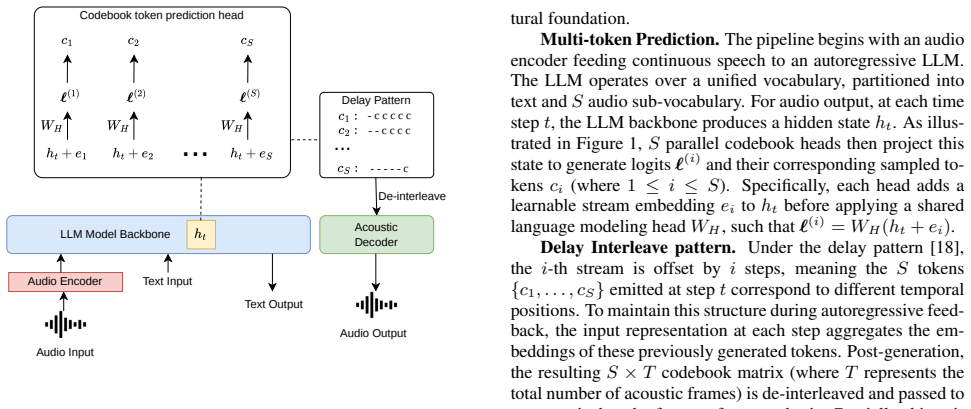
Introduction The rapid evolution of Large Language Models (LLMs) has transitioned artificial intelligence from text-only interfaces to rich, multimodal interactions. Recently, Speech Language Models (SpeechLMs) [1, 2, 3, 4] have emerged as a piv- otal frontier for unified audio understanding and generation. By modeling continuous audio signals as discrete...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
We identify the structural limitations of current text-centric inference engines in handling multimodal auto-regressive generation and propose a unified architecture that natively supports synchronous multi-stream sampling and delay- pattern de-interleaving for multi-codebook audio tokens
-
[3]
We design an end-to-end fused acoustic pipeline that inte- grates a lightweight audio decoder directly into the engine’s output pipeline, eliminating the need for an external vocoder service and enabling single-process waveform synthesis on GPU
-
[4]
We introduce a Paired Request Co-Scheduling strategy for CFG. By systematically pairing and co-scheduling condi- tional and unconditional requests within the same continuous batch, our system efficiently absorbs dual-branch overheads and logit synchronization costs, sustaining up to 80% of non- CFG throughput and effectively overcoming the shared intu- it...
-
[5]
Companion
Method We present a serving framework that enables high-throughput inference for unified audio understanding and generation within existing token-level continuous batching engines. We first de- scribe the class of models our framework targets (§2.1), then detail our unified serving pipeline (§2.3), and finally describe efficient Classifier-Free Guidance (...
-
[6]
Experiment 3.1. Experimental Setup We evaluate our framework on three fully open-source SpeechLM architectures that span different design points, all sharing a delay-pattern codec structure and supporting both au- dio understanding and generation: •Bagpiper[1]: A model utilizing a Qwen3-8B [22] backbone with 8 parallel codebook streams encoded via X-Codec...
-
[7]
Conclusion In this work, we presented a unified inference architecture that extends a continuous batching engine to natively support Speech Language Models. By integrating synchronous multi- stream sampling and delay-pattern de-interleaving into the gen- eration loop, our design effectively handles the complexities of multi-layered audio tokens. Through a...
-
[8]
The core technical contributions, including the system architecture design, frame- work implementation, and experimental evaluation, were inde- pendently conducted by the authors
Generative AI Use Disclosure Artificial intelligence tools were utilized exclusively for lan- guage editing and manuscript polishing. The core technical contributions, including the system architecture design, frame- work implementation, and experimental evaluation, were inde- pendently conducted by the authors
-
[9]
Acknowledgment This work used the Bridges2 at PSC and Delta/DeltaAI NCSA systems through CIS210014 from the ACCESS program, sup- ported by NSF #2138259, #2138286, #2138307, #2137603, and #2138296
-
[10]
Bagpiper: Solving Open-Ended Audio Tasks via Rich Captions
J. Tian, H. Wang, B.-H. Su, C.-y. Huang, Q. Wang, J. Shi, W. Chen, X. Gong, S. Arora, C.-J. Liet al., “Bagpiper: Solv- ing open-ended audio tasks via rich captions,”arXiv preprint arXiv:2602.05220, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Opuslm: A family of open unified speech language models,
J. Tian, W. Chen, Y . Peng, J. Shi, S. Arora, S. Bharadwaj, T. Maekaku, Y . Shinohara, K. Goto, X. Yueet al., “Opuslm: A family of open unified speech language models,”arXiv preprint arXiv:2506.17611, 2025
-
[12]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhuet al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tanget al., “Kimi-audio technical report,” arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Espnet-codec: Compre- hensive training and evaluation of neural codecs for audio, music, and speech,
J. Shi, J. Tian, Y . Wu, J.-w. Jung, J. Q. Yip, Y . Masuyama, W. Chen, Y . Wu, Y . Tang, M. Baaliet al., “Espnet-codec: Compre- hensive training and evaluation of neural codecs for audio, music, and speech,” in2024 IEEE Spoken language technology workshop (SLT). IEEE, 2024, pp. 562–569
2024
-
[15]
Codec does matter: Exploring the semantic shortcoming of codec for audio language model,
Z. Ye, P. Sun, J. Lei, H. Lin, X. Tan, Z. Dai, Q. Kong, J. Chen, J. Pan, Q. Liuet al., “Codec does matter: Exploring the semantic shortcoming of codec for audio language model,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 24, 2025, pp. 25 697–25 705
2025
-
[16]
Bscodec: A band-split neural codec for high-quality universal audio recon- struction,
H. Wang, J. Shi, J. Tian, B. Li, K. Yu, and S. Watanabe, “Bscodec: A band-split neural codec for high-quality universal audio recon- struction,”arXiv preprint arXiv:2511.06150, 2025
-
[17]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[18]
Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,
J. Kim, J. Kong, and J. Son, “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech,” inInter- national conference on machine learning. PMLR, 2021, pp. 5530–5540
2021
-
[19]
Natural tts synthesis by conditioning wavenet on mel spectrogram pre- dictions,
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y . Zhang, Y . Wang, R. Skerrv-Ryanet al., “Natural tts synthesis by conditioning wavenet on mel spectrogram pre- dictions,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 4779– 4783
2018
-
[20]
S. Arora, J. Tian, J. Shi, H. Futami, Y . Kashiwagi, E. Tsunoo, and S. Watanabe, “Optimizing conversational quality in spoken dialogue systems with reinforcement learning from ai feedback,” arXiv preprint arXiv:2601.19063, 2026
-
[21]
Moshi: a speech-text foundation model for real-time dialogue
A. D ´efossez, L. Mazar´e, M. Orsini, A. Royer, P. P´erez, H. J´egou, E. Grave, and N. Zeghidour, “Moshi: a speech-text foundation model for real-time dialogue,”arXiv preprint arXiv:2410.00037, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Efficient memory manage- ment for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory manage- ment for large language model serving with pagedattention,” in Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[23]
Sglang: Efficient execution of structured language model programs,
L. Zheng, L. Yin, Z. Xie, C. L. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalezet al., “Sglang: Efficient execution of structured language model programs,”Advances in neural information processing systems, vol. 37, pp. 62 557– 62 583, 2024
2024
-
[24]
Orca: A distributed serving system for{Transformer-Based}generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for{Transformer-Based}generative models,” in16th USENIX symposium on operating systems design and implementation (OSDI 22), 2022, pp. 521–538
2022
-
[25]
Discrete audio tokens: More than a survey!
P. Mousavi, G. Maimon, A. Moumen, D. Petermann, J. Shi, H. Wu, H. Yang, A. Kuznetsova, A. Ploujnikov, R. Marxeret al., “Discrete audio tokens: More than a survey!”arXiv preprint arXiv:2506.10274, 2025
-
[26]
Recent advances in discrete speech tokens: A review,
Y . Guo, Z. Li, H. Wang, B. Li, C. Shao, H. Zhang, C. Du, X. Chen, S. Liu, and K. Yu, “Recent advances in discrete speech tokens: A review,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[27]
Simple and controllable music genera- tion,
J. Copet, F. Kreuk, I. Gat, T. Remez, D. Kant, G. Synnaeve, Y . Adi, and A. D´efossez, “Simple and controllable music genera- tion,”Advances in neural information processing systems, vol. 36, pp. 47 704–47 720, 2023
2023
-
[28]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guidance,”arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Ualm: Unified au- dio language model for understanding, generation and reasoning,
J. Tian, S.-g. Lee, Z. Kong, S. Ghosh, A. Goel, C.-H. H. Yang, W. Dai, Z. Liu, H. Ye, S. Watanabeet al., “Ualm: Unified au- dio language model for understanding, generation and reasoning,” arXiv preprint arXiv:2510.12000, 2025
-
[30]
Audioldm: Text-to-audio generation with latent diffusion models.arXiv preprint arXiv:2301.12503,
H. Liu, Z. Chen, Y . Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley, “Audioldm: Text-to-audio generation with latent diffusion models,”arXiv preprint arXiv:2301.12503, 2023
-
[31]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
T. OLMo, P. Walsh, L. Soldaini, D. Groeneveld, K. Lo, S. Arora, A. Bhagia, Y . Gu, S. Huang, M. Jordanet al., “2 olmo 2 furious,” arXiv preprint arXiv:2501.00656, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Towards robust speech representation learning for thousands of languages,
W. Chen, W. Zhang, Y . Peng, X. Li, J. Tian, J. Shi, X. Chang, S. Maiti, K. Livescu, and S. Watanabe, “Towards robust speech representation learning for thousands of languages,” inProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 10 205–10 224
2024
-
[34]
High-fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved rvqgan,”Ad- vances in Neural Information Processing Systems, vol. 36, pp. 27 980–27 993, 2023
2023
-
[35]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
L. B. Allal, A. Lozhkov, E. Bakouch, G. M. Bl ´azquez, G. Penedo, L. Tunstall, A. Marafioti, H. Kydl´ıˇcek, A. P. Lajar´ın, V . Srivastav et al., “Smollm2: When smol goes big–data-centric training of a small language model,”arXiv preprint arXiv:2502.02737, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Flashattention-3: Fast and accurate attention with asyn- chrony and low-precision,
J. Shah, G. Bikshandi, Y . Zhang, V . Thakkar, P. Ramani, and T. Dao, “Flashattention-3: Fast and accurate attention with asyn- chrony and low-precision,”Advances in Neural Information Pro- cessing Systems, vol. 37, pp. 68 658–68 685, 2024
2024
-
[37]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha, “Mmau: A massive multi-task audio understanding and reasoning benchmark,”arXiv preprint arXiv:2410.19168, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[39]
A. Golden, S. Hsia, F. Sun, B. Acun, B. Hosmer, Y . Lee, Z. De- Vito, J. Johnson, G.-Y . Wei, D. Brookset al., “Is flash attention stable?”arXiv preprint arXiv:2405.02803, 2024
-
[40]
Understanding and mitigating numer- ical sources of nondeterminism in llm inference,
J. Yuan, H. Li, X. Ding, W. Xie, Y .-J. Li, W. Zhao, K. Wan, J. Shi, X. Hu, and Z. Liu, “Understanding and mitigating numer- ical sources of nondeterminism in llm inference,”arXiv preprint arXiv:2506.09501, 2025
-
[41]
Lib- rispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an asr corpus based on public domain audio books,” in2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.