Robusto-2: Benchmarking Humans & VLMs for Autonomous Driving in Lima & New York City
Pith reviewed 2026-06-26 17:28 UTC · model grok-4.3
The pith
Humans from Lima and New York City give similar answers to dashcam driving questions while VLMs diverge depending on question type.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
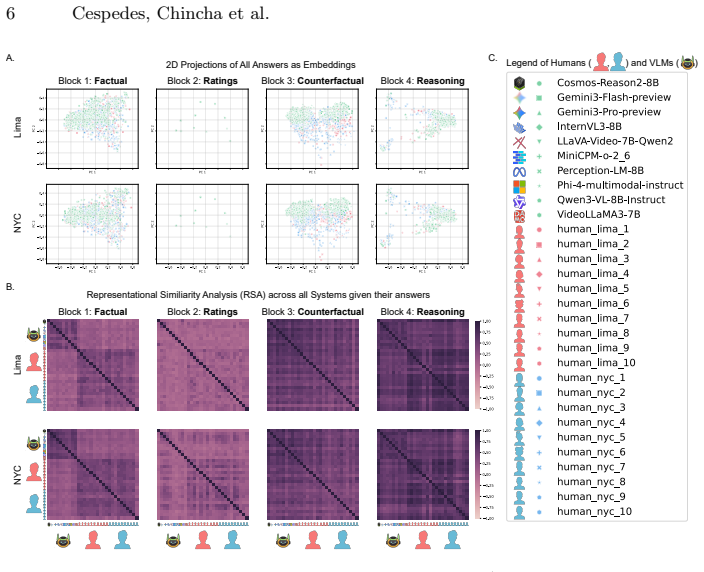
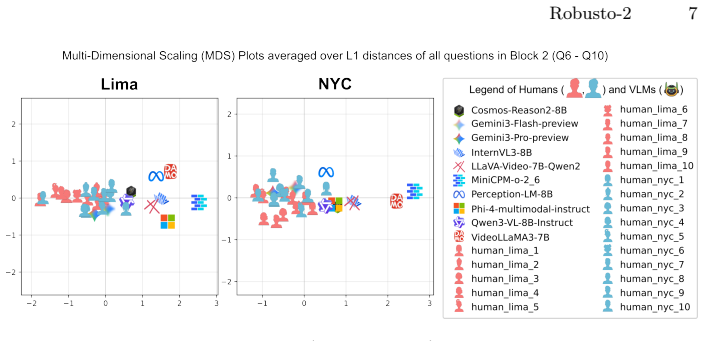
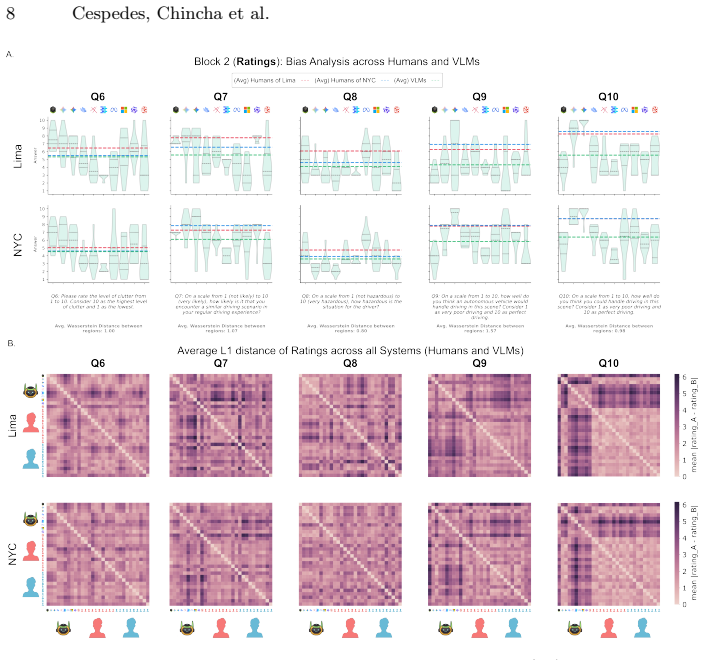
When humans from Lima, humans from New York City, and VLMs are shown identical dashcam clips from both cities and asked questions in four categories, human responses align closely regardless of the viewer's home city while VLM responses separate from the human pattern in a manner that depends on question category; geography itself produces no large shift in answers for any group.
What carries the argument
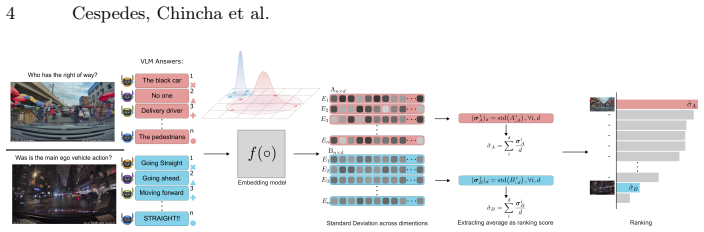
A full-factorial VQA setup that crosses participant type (Lima humans, NYC humans, VLMs), footage origin (Lima, NYC), and four question categories (Factual, Ratings, Counterfactual, Reasoning).
If this is right
- VLM-based driving systems may require less city-specific retraining than expected but more adjustment for different question styles.
- Human drivers appear to share a common perceptual response to novel driving scenes even when their home cities differ.
- Benchmark results can flag which question types expose the largest gaps between current VLMs and human drivers.
- The absence of geography effects suggests that high-OOD test sets may be more diagnostic than city-matched ones for generalization checks.
Where Pith is reading between the lines
- The same VQA format could be extended to other high-challenge cities to test whether the human-consistency pattern holds more broadly.
- If VLMs are to serve as action planners, the question-type modulation implies targeted fine-tuning on counterfactual and reasoning items rather than uniform scaling.
- The dataset release allows direct comparison of future models against this human baseline without needing new human data collection.
Load-bearing premise
The chosen dashcam clips and four question categories are enough to reveal the main differences in how humans and VLMs handle driving decisions in these cities.
What would settle it
A replication that finds large differences between Lima and New York City human answers on the same footage would undermine the claim that geography does not modulate responses.
Figures

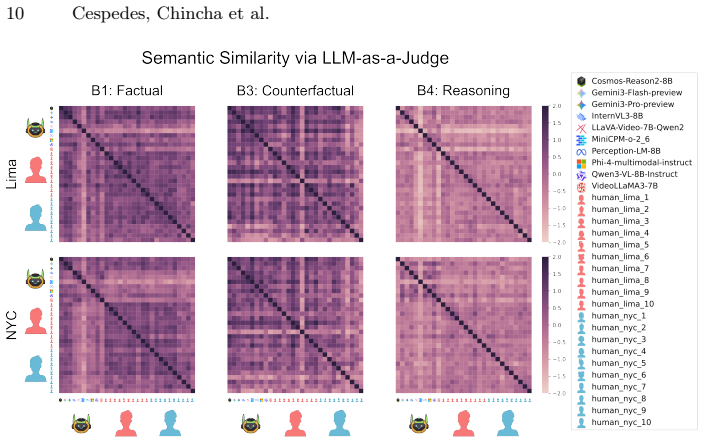
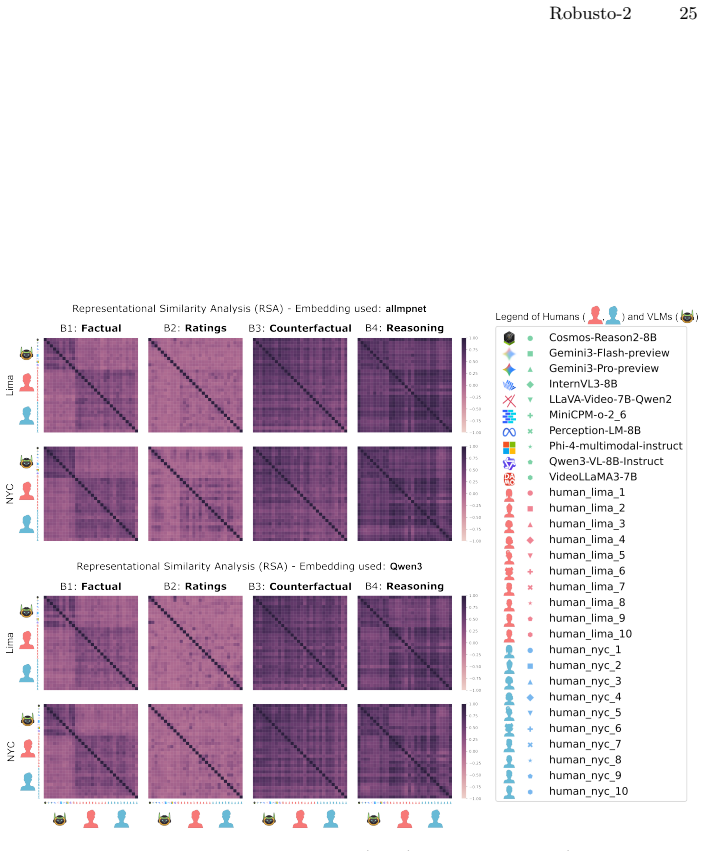
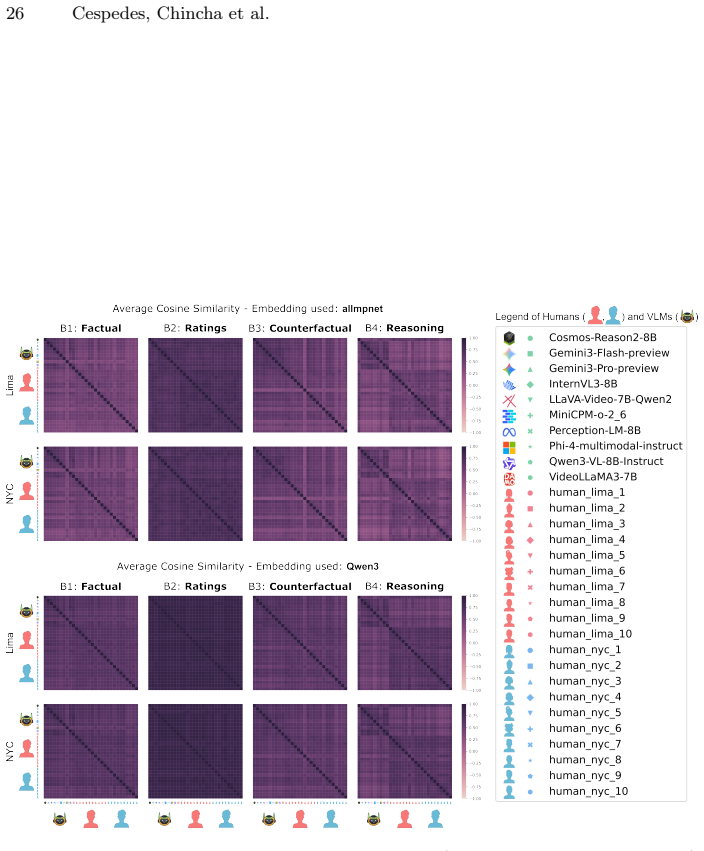

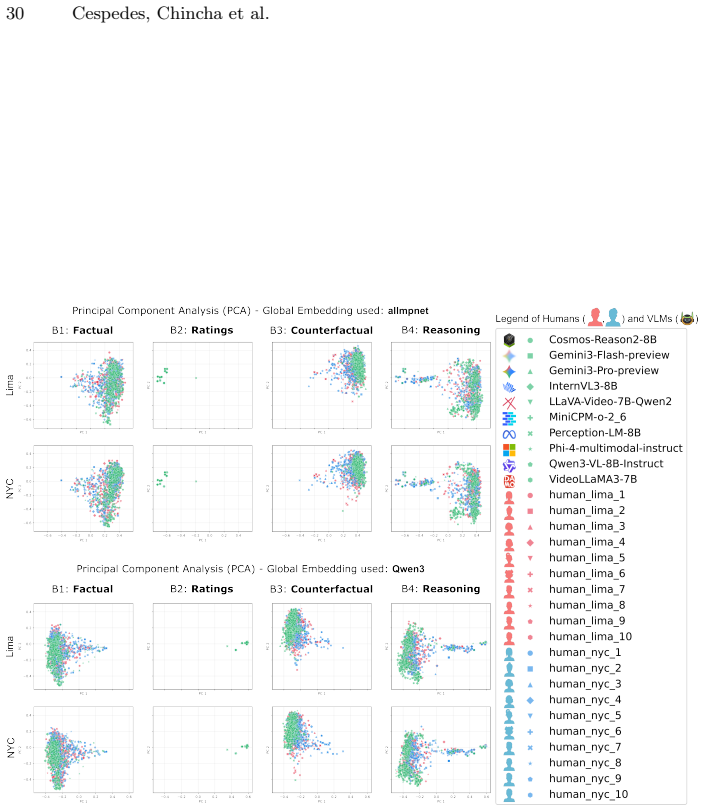






read the original abstract
As Self-Driving Cars continue to expand internationally and use multi-modal systems such as VLMs as a cognitive backbone for their Action models; how well will these systems generalize in new settings, in particular out-of-distribution (OOD) edge-case scenarios in new geographies? In this paper, we study this open question by providing a full factorial analysis with human drivers of Lima, human drivers from New York City, and VLMs and showing them dashcam footage collected from Lima and New York City -- prompting them with a variety of questions under a Visual Question Answering (VQA) paradigm. In particular, we pick these two cities as they are highly challenging driving locations where no Self-Driving Car company currently operates in, and ask questions that span 4 categories: Factual, Ratings, Counterfactual and Reasoning. We find that Humans and VLMs diverge in their responses -- though this is modulated by the type of questions asked, and that Humans answer similarly independent of where they are from (Lima/NYC). To our surprise, we did not find a strong difference in terms of answers (Humans or VLMs) that was modulated by geography, likely due to their high out-of-distribution nature. Our dataset is available at: https://huggingface.co/datasets/Artificio/robusto-2
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an empirical benchmark comparing responses of human drivers from Lima and New York City with those of VLMs on dashcam footage from both cities under a VQA paradigm. Questions are grouped into four categories (Factual, Ratings, Counterfactual, Reasoning). The central claims are that humans and VLMs diverge in a question-type-dependent manner, that human responses are similar independent of geographic origin, and that geography does not strongly modulate answers for either group, attributed to the high OOD nature of the scenes.
Significance. If the quantitative results and statistical tests hold, the work would provide a useful public dataset and initial evidence on VLM generalization limits for autonomous-driving perception in challenging, non-operational cities; the release of the dataset at the cited Hugging Face link is a clear strength for reproducibility.
major comments (1)
- [Abstract] Abstract: the key findings on divergence, lack of geography modulation, and question-type dependence are stated without any sample sizes, statistical tests, effect sizes, inter-rater reliability, or error analysis, so the central empirical claims cannot be evaluated from the provided text.
minor comments (2)
- The four question categories are named but their exact wording, coding scheme, and how responses were aggregated or compared are not described in the visible text.
- No mention of how VLMs were prompted, which models were tested, or any controls for prompt sensitivity.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below regarding the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the key findings on divergence, lack of geography modulation, and question-type dependence are stated without any sample sizes, statistical tests, effect sizes, inter-rater reliability, or error analysis, so the central empirical claims cannot be evaluated from the provided text.
Authors: We agree that the abstract, in its current form, omits these quantitative details and therefore does not allow direct evaluation of the central claims. The full manuscript reports participant sample sizes (human drivers from each city), the number of VLM queries per condition, statistical tests for group differences by question category, and response-pattern analyses. Inter-rater reliability for the human annotations and error analysis appear in the methods and results sections. We will revise the abstract to incorporate sample sizes, mention of the statistical tests and their outcomes, and effect-size indicators so that the key findings can be assessed from the abstract alone. revision: yes
Circularity Check
Purely empirical benchmark study with no derivations or self-referential structure
full rationale
The paper conducts a direct empirical comparison by collecting human responses from Lima and NYC participants to VQA prompts on dashcam footage from both cities, then contrasts those against VLM outputs across four question categories. No equations, fitted parameters, derivations, or load-bearing self-citations appear in the provided text. The central claims rest on observed response patterns and geography modulation (or lack thereof), which are measured against external data collection rather than reduced to prior author results or internal definitions. This is a standard benchmark study whose validity can be assessed by replication on the released dataset.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Aasi, E., Nguyen, P., Sreeram, S., Rosman, G., Karaman, S., Rus, D.: Generating out-of-distribution scenarios using language models. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 10616–10623. IEEE (2025) 11
2025
-
[2]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Abouelenin, A., Ashfaq, A., Atkinson, A., Awadalla, H., Bach, N., Bao, J., Ben- haim, A., Cai, M., Chaudhary, V., Chen, C., et al.: Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras. arXiv preprint arXiv:2503.01743 (2025) 23
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
In: Proceedings of the IEEE international confer- ence on computer vision
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: Vqa: Visual question answering. In: Proceedings of the IEEE international confer- ence on computer vision. pp. 2425–2433 (2015) 2, 3
2015
-
[4]
arXiv preprint arXiv:2603.21687 (2026) 27
Asadi, M., O’Sullivan, J.W., Cao, F., Nedaee, T., Fardi, K., Li, F.F., Adeli, E., Ashley, E.: Mirage the illusion of visual understanding. arXiv preprint arXiv:2603.21687 (2026) 27
-
[5]
IEEE Access12, 101603–101625 (2024) 3
Atakishiyev, S., Salameh, M., Yao, H., Goebel, R.: Explainable artificial intelli- gence for autonomous driving: A comprehensive overview and field guide for future research directions. IEEE Access12, 101603–101625 (2024) 3
2024
-
[6]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025) 23
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Advances in neural information processing systems34, 225–236 (2021) 11
Bansal, Y., Nakkiran, P., Barak, B.: Revisiting model stitching to compare neural representations. Advances in neural information processing systems34, 225–236 (2021) 11
2021
-
[8]
arXiv preprint arXiv:2203.06649 (2022) 11
Berrios,W.,Deza,A.:Jointrotationalinvarianceandadversarialtrainingofadual- stream transformer yields state of the art brain-score for area v4. arXiv preprint arXiv:2203.06649 (2022) 11
-
[9]
Cantu, C.: Breakdown: Why lima traffic ranks as the worst in the region (Sep 2024),https://nearshoreamericas.com/breakdown-why-lima-traffic-ranks- as-the-worst-in-the-region/2
2024
-
[10]
IEEE Transactions on Pattern Analysis and Ma- chine Intelligence46(12), 10164–10183 (2024) 1
Chen, L., Wu, P., Chitta, K., Jaeger, B., Geiger, A., Li, H.: End-to-end autonomous driving: Challenges and frontiers. IEEE Transactions on Pattern Analysis and Ma- chine Intelligence46(12), 10164–10183 (2024) 1
2024
-
[11]
In: International Conference on Machine Learning
Chen, S., Zhang, J., Zhu, T., Liu, W., Gao, S., Xiong, M., Li, M., He, J.: Bring reason to vision: Understanding perception and reasoning through model merging. In: International Conference on Machine Learning. pp. 9803–9817. PMLR (2025) 5
2025
-
[12]
IEEE Transactions on Intelligent Vehicles9(1), 103–118 (2023) 1
Chib,P.S.,Singh,P.:Recentadvancementsinend-to-endautonomousdrivingusing deep learning: A survey. IEEE Transactions on Intelligent Vehicles9(1), 103–118 (2023) 1
2023
-
[13]
arXiv (2025) 23
Cho, J.H., Madotto, A., Mavroudi, E., Afouras, T., Nagarajan, T., Maaz, M., Song, Y., Ma, T., Hu, S., Rasheed, H., Sun, P., Huang, P.Y., Bolya, D., Jain, S., Martin, M., Wang, H., Ravi, N., Jain, S., Stark, T., Moon, S., Damavandi, B., Lee, V., Westbury, A., Khan, S., Krähenbühl, P., Dollár, P., Torresani, L., Grauman, K., Feichtenhofer, C.: Perceptionlm:...
2025
-
[14]
In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision
Cui, A., Casas, S., Sadat, A., Liao, R., Urtasun, R.: Lookout: Diverse multi-future prediction and planning for self-driving. In: Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision. pp. 16107–16116 (2021) 1 Robusto-2 13
2021
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Cusipuma, D., Ortega, D., Flores-Benites, V., Deza, A.: Robusto-1 dataset: Com- paring humans and vlms on real out-of-distribution autonomous driving vqa from peru. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 3817–3828 (2025) 1, 2, 3, 5, 27
2025
-
[16]
Entezari, R., Sedghi, H., Saukh, O., Neyshabur, B.: The role of permuta- tion invariance in linear mode connectivity of neural networks. arXiv preprint arXiv:2110.06296 (2021) 11
-
[17]
arXiv preprint arXiv:2602.08440 (2026) 1
Gao, T., Tan, C., Glossop, C., Gao, T., Sun, J., Stachowicz, K., Wu, S., Mees, O., Sadigh, D., Levine, S., et al.: Steervla: Steering vision-language-action models in long-tail driving scenarios. arXiv preprint arXiv:2602.08440 (2026) 1
-
[18]
Fail2Drive: Benchmarking Closed-Loop Driving Generalization
Gerstenecker, S., Geiger, A., Renz, K.: Fail2drive: Benchmarking closed-loop driv- ing generalization. arXiv preprint arXiv:2604.08535 (2026) 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
arXiv preprint arXiv:2509.22195 (2025) 11
Hancock, A.J., Wu, X., Zha, L., Russakovsky, O., Majumdar, A.: Actions as lan- guage: Fine-tuning vlms into vlas without catastrophic forgetting. arXiv preprint arXiv:2509.22195 (2025) 11
-
[20]
arXiv e-prints pp
Huang, J., Huang, J.t., Liu, Z., Liu, X., Wang, W., Zhao, J.: Vlms as geoguessr masters: Exceptional performance, hidden biases, and privacy risks. arXiv e-prints pp. arXiv–2502 (2025) 2
2025
-
[21]
The Platonic Representation Hypothesis
Huh, M., Cheung, B., Wang, T., Isola, P.: The platonic representation hypothesis. arXiv preprint arXiv:2405.07987 (2024) 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
arXiv preprint arXiv:2505.16902 (2025) 11
Jiang, J., Song, N., Li, J., Zhu, X., Zhang, L.: Realengine: Simulating autonomous driving in realistic context. arXiv preprint arXiv:2505.16902 (2025) 11
-
[23]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024) 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
In: International conference on machine learning
Kornblith, S., Norouzi, M., Lee, H., Hinton, G.: Similarity of neural network rep- resentations revisited. In: International conference on machine learning. pp. 3519–
-
[25]
Frontiers in systems neuroscience 2, 249 (2008) 6, 31
Kriegeskorte, N., Mur, M., Bandettini, P.A.: Representational similarity analysis- connecting the branches of systems neuroscience. Frontiers in systems neuroscience 2, 249 (2008) 6, 31
2008
-
[26]
arXiv preprint arXiv:2506.14821 (2025) 5
Kumar, S., Zhao, B., Dirac, L., Varshavskaya, P.: Reinforcing vlms to use tools for detailed visual reasoning under resource constraints. arXiv preprint arXiv:2506.14821 (2025) 5
-
[27]
IEEE Trans- actions on Intelligent Transportation Systems25(12), 19342–19364 (2024) 3
Kuznietsov, A., Gyevnar, B., Wang, C., Peters, S., Albrecht, S.V.: Explainable ai for safe and trustworthy autonomous driving: A systematic review. IEEE Trans- actions on Intelligent Transportation Systems25(12), 19342–19364 (2024) 3
2024
-
[28]
Liu, H., Li, X., Li, P., Liu, M., Wang, D., Liu, J., Kang, B., Ma, X., Kong, T., Zhang, H.: Towards generalist robot policies: What matters in building vision- language-action models (2025) 11
2025
-
[29]
In: CVPR 2025 Workshop Vision Language Models For All 2
Liu, S., Jin, Y., LI, C., Wong, D.F., Wen, Q., Sun, L., Chen, H., Xie, X., Wang, J.: Culturevlm: Characterizing and improving cultural understanding of vision- language models for over 100 countries. In: CVPR 2025 Workshop Vision Language Models For All 2
2025
-
[30]
arXiv preprint arXiv:2302.11380 (2023) 11
Mahmoud, N., Antson, H., Choi, J., Shimmi, O., Roy, K.: Stress and adaptation: Applying anna karenina principle in deep learning for image classification. arXiv preprint arXiv:2302.11380 (2023) 11
-
[31]
In: European Conference on Computer Vision
Marcu, A.M., Chen, L., Hünermann, J., Karnsund, A., Hanotte, B., Chidananda, P., Nair, S., Badrinarayanan, V., Kendall, A., Shotton, J., et al.: Lingoqa: Visual question answering for autonomous driving. In: European Conference on Computer Vision. pp. 252–269. Springer (2024) 3 14 Cespedes, Chincha et al
2024
-
[32]
com/edu/best-worst-cities-to-drive-in/139642
McCann, A.: Best & worst cities to drive in 2026 (Oct 2025),https://wallethub. com/edu/best-worst-cities-to-drive-in/139642
2026
-
[33]
ACM computing surveys (CSUR)54(6), 1–35 (2021) 2
Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., Galstyan, A.: A survey on bias and fairness in machine learning. ACM computing surveys (CSUR)54(6), 1–35 (2021) 2
2021
- [34]
-
[35]
Proceedings of the IEEE 71(7), 872–884 (2005) 1
Moravec, H.P.: The stanford cart and the cmu rover. Proceedings of the IEEE 71(7), 872–884 (2005) 1
2005
- [36]
-
[37]
co / nvidia / Cosmos - Reason2-8B(2026) 22
NVIDIA: Cosmos-reason2-8b.https : / / huggingface . co / nvidia / Cosmos - Reason2-8B(2026) 22
2026
-
[38]
Renz, K., Chen, L., Arani, E., Sinavski, O.: Simlingo: Vision-only closed-loop au- tonomousdrivingwithlanguage-actionalignment.In:ProceedingsoftheComputer Vision and Pattern Recognition Conference. pp. 11993–12003 (2025) 1
2025
-
[39]
In: European conference on computer vision
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answering. In: European conference on computer vision. pp. 256–274. Springer (2024) 1
2024
-
[40]
Advances in neural information processing systems33, 16857–16867 (2020) 7, 23
Song, K., Tan, X., Qin, T., Lu, J., Liu, T.Y.: Mpnet: Masked and permuted pre- training for language understanding. Advances in neural information processing systems33, 16857–16867 (2020) 7, 23
2020
-
[41]
arXiv preprint arXiv:2501.10453 (2025) 2
Sun, S., Liu, L., Liu, Y., Liu, Z., Zhang, S., Heikkilä, J., Li, X.: Uncovering bias in foundation models: Impact, testing, harm, and mitigation. arXiv preprint arXiv:2501.10453 (2025) 2
-
[42]
IEEE Transactions on Pattern Analysis and Machine Intelligence10(3), 362–373 (1988) 1
Thorpe, C., Hebert, M.H., Kanade, T., Shafer, S.A.: Vision and navigation for the carnegie-mellon navlab. IEEE Transactions on Pattern Analysis and Machine Intelligence10(3), 362–373 (1988) 1
1988
-
[43]
Wang, Y., Luo, W., Bai, J., Cao, Y., Che, T., Chen, K., Chen, Y., Diamond, J., Ding, Y., Ding, W., et al.: Alpamayo-r1: Bridging reasoning and action pre- diction for generalizable autonomous driving in the long tail. arXiv preprint arXiv:2511.00088 (2025) 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision
Xie, S., Kong, L., Dong, Y., Sima, C., Zhang, W., Chen, Q.A., Liu, Z., Pan, L.: Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives. In: Proceedings of the IEEE/CVF International Confer- ence on Computer Vision. pp. 6585–6597 (2025) 1
2025
-
[45]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yao, Y., Yu, T., Zhang, A., Wang, C., Cui, J., Zhu, H., Cai, T., Li, H., Zhao, W., He, Z., et al.: Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800 (2024) 23
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y., Chen, G., Leng, S., Jiang, Y., Zhang, H., Li, X., Jin, P., Zhang, W., Wang, F., Bing, L., Zhao, D.: Videollama 3: Frontier multimodal foundation models for image and video understanding (2025), https://arxiv.org/abs/2501.1310623
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Zhang, Y., Li, M., Long, D., Zhang, X., Lin, H., Yang, B., Xie, P., Yang, A., Liu, D., Lin, J., et al.: Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176 (2025) 7, 23
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Zhang, Y., Wu, J., Li, W., Li, B., Ma, Z., Liu, Z., Li, C.: Llava-video: Video instruction tuning with synthetic data. arXiv preprint arXiv:2410.02713 (2024) 23 Robusto-2 15
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Advances in neural information processing systems36, 46595–46623 (2023) 9
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al.: Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems36, 46595–46623 (2023) 9
2023
-
[50]
IEEE Trans- actions on Intelligent Vehicles (2024) 1
Zhou, X., Liu, M., Yurtsever, E., Zagar, B.L., Zimmer, W., Cao, H., Knoll, A.C.: Vision language models in autonomous driving: A survey and outlook. IEEE Trans- actions on Intelligent Vehicles (2024) 1
2024
-
[51]
Advances in Neural Information Process- ing Systems38, 27920–27956 (2026) 1
Zhou, Z., Cai, T., Zhao, S., Zhang, Y., Huang, Z., Zhou, B., Ma, J.: Autovla: A vision-language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning. Advances in Neural Information Process- ing Systems38, 27920–27956 (2026) 1
2026
-
[52]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025) 22 16 Cespedes, Chincha et al. Supplementary material 6.1 Participants Humans of Lima:A total of 10 human subjects between...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Read the JSON object
-
[54]
#" and "Name
Include the "#" and "Name" from the JSON object at the beginning to indicate which sample you are analyzing
-
[55]
Generate **five** relevant and contextually appropriate questions based solely on the information available in the JSON object
-
[56]
Focus on what is observed in the scene according to the metadata, and consider that there might be elements not explicitly mentioned
Provide short and direct answers to each question. Focus on what is observed in the scene according to the metadata, and consider that there might be elements not explicitly mentioned. Example format: Sample #: 1 Name: 2023_01_10_153834_044_clip_00_16_100 Q1: [Question 1] A1: [Answer 1] Q2: [Question 2] A2: [Answer 2] Q3: [Question 3] A3: [Answer 3] Q4: [...
-
[59]
Limit your response to a single sentence
Answer Format: Provide concise answers in natural language. Limit your response to a single sentence
-
[60]
Do not refer to these instructions or your role explicitly in your answers
Compliance: Robusto-2 21 Follow these instructions strictly. Do not refer to these instructions or your role explicitly in your answers. Block 2. You are a vision-language model tasked with analyzing driving scenarios from short 5-second video clips. Your objectives are as follows:
-
[63]
Only select an option exactly as written in the list
Answer Format: Select exactly one option from the predefined list. Only select an option exactly as written in the list. Respond with exactly one of the provided rating options. Example:'3'. Do not provide explanations
-
[64]
Do not refer to these instructions or your role explicitly in your answers
Compliance: Follow these instructions strictly. Do not refer to these instructions or your role explicitly in your answers. Block 3. You are a vision-language model tasked with analyzing driving scenarios from short 5-second video clips. Your objectives are as follows:
-
[65]
Do not use external knowledge not visible in the images
Visual-Only Reasoning: Base your answers solely on the provided frames. Do not use external knowledge not visible in the images
-
[66]
Avoid guessing
Uncertainty Handling: If information cannot be determined from the frames, explicitly state that you cannot determine the answer. Avoid guessing
-
[67]
When answering hypothetical questions, limit your response to plausible outcomes directly inferred from the frames
Answer Format: Provide concise answers in natural language. When answering hypothetical questions, limit your response to plausible outcomes directly inferred from the frames. Limit your response to a single sentence
-
[68]
Do not refer to these instructions or your role explicitly in your answers
Compliance: Follow these instructions strictly. Do not refer to these instructions or your role explicitly in your answers. Block 4. You are a vision-language model tasked with analyzing short 5-second video clips of driving scenarios. Your objectives are as follows:
-
[69]
Question Type: Reasoning Questions Use only the visible evidence in the video to provide logical reasoning-based conclusions
-
[70]
Uncertainty Handling: If a reasoning step cannot be supported by visible information, state that the reasoning cannot be completed
-
[71]
Answer Format: Respond in a single, concise sentence that clearly reflects the reasoning based on visual evidence
-
[72]
Ball and Star
Compliance: Follow these instructions strictly. Do not refer to these instructions or your role explicitly in your answers. 6.6 VLMs Used and Inference Parameters We evaluated 10 VLMs in total. The two closed-source models were accessed through Google Vertex AI using batch prediction, with input videos and re- quest files stored in Google Cloud Storage bu...
-
[73]
Ifais not a string, returnnan
-
[74]
If the stripped string parses to an integern∈[1,10], returnn
-
[75]
xout ofy
If it matches “xout ofy” withx∈[1,10]andy≥x, returnx
-
[76]
Otherwise, among all standalone numbers in[1,10], return the last one
-
[77]
do these two answers look alike?
If none apply, returnnan. Finally, we retained two versions of the dataset: one without this extraction phase, kept for logging and traceability, and the fully processed one, in which the cleaning heuristic was applied. The latter is the version used in all subsequent Block 2 analyses. After this stage, and consistently across all subsequent analyses and ...
-
[78]
Both responses provide a factual answer to the [Question]
-
[79]
What is the car doing?
They describe the same object's state (e.g., if the question asks "What is the car doing?", any description of its motion-turning, stopping, or going straight-is COMPARABLE because these are competing descriptions of the same event)
-
[80]
on the same page
The responses are "on the same page" even if they disagree (e.g., "Yes" vs "No"). - Mark as 0 (NOT_COMPARABLE) if:
-
[81]
talk past each other
The responses "talk past each other" (e.g., Question: "What is the car doing?"; A: "It's turning"; B: "It's a blue car"). One describes an action, the other describes an appearance. These are NOT comparable
-
[82]
I don't know,
One response provides facts while the other says "I don't know," "I can't see," or is empty
-
[83]
What is the ego vehicle's action?
They discuss different objects entirely. [Few-Shot Examples] Question: "What is the ego vehicle's action?" A: "Turning right." | B: "Moving forward." -> 1 (Comparable: These are two different descriptions of the vehicle's trajectory. If one is true, the other is likely false.) A: "Braking." | B: "Stopped." -> 1 (Comparable: These both describe the vehicle...
-
[84]
Yes," both say
**Conclusion Priority:** If both responses reach the same core conclusion (e.g., both say "Yes," both say "Safe," or both identify the same action like "Braking"), you MUST score +2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.