Perception or Prejudice: Can MLLMs Go Beyond First Impressions of Personality?
Pith reviewed 2026-05-22 05:40 UTC · model grok-4.3
The pith
MLLMs often produce correct personality ratings without grounding them in observable video cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
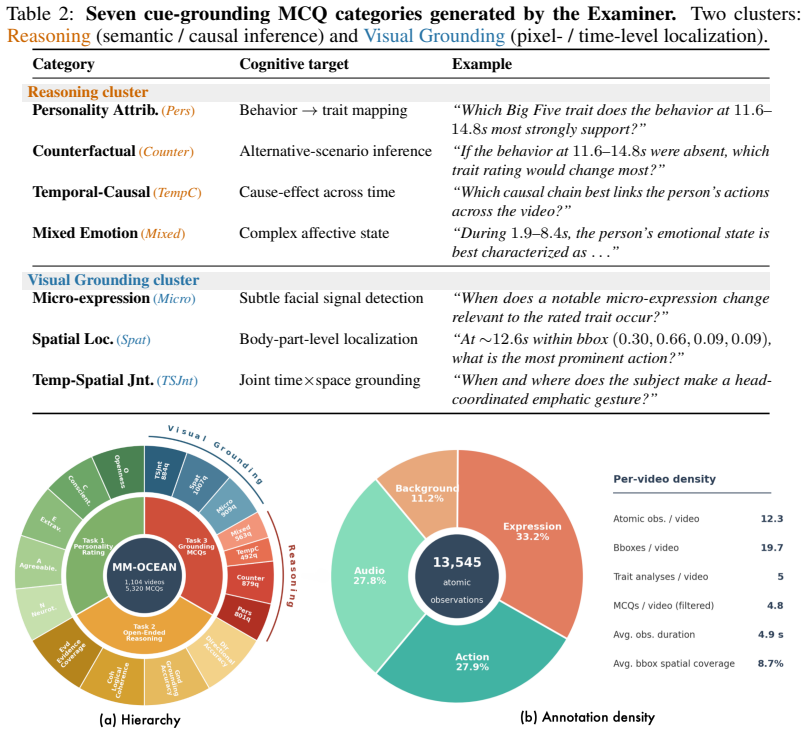
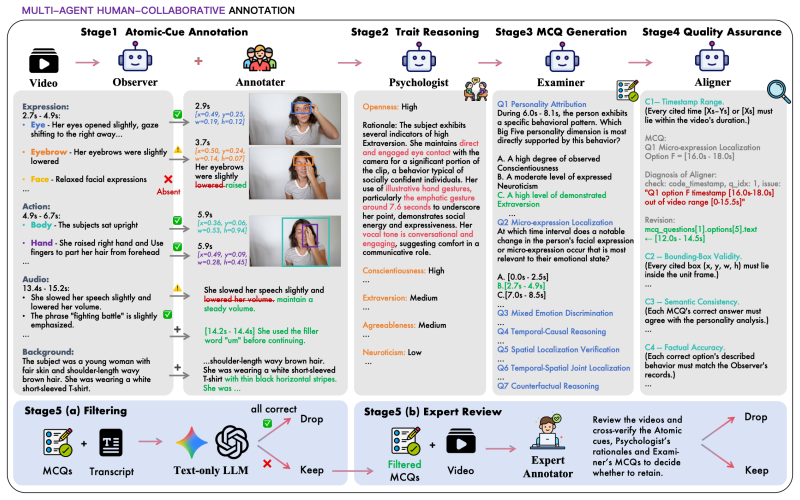
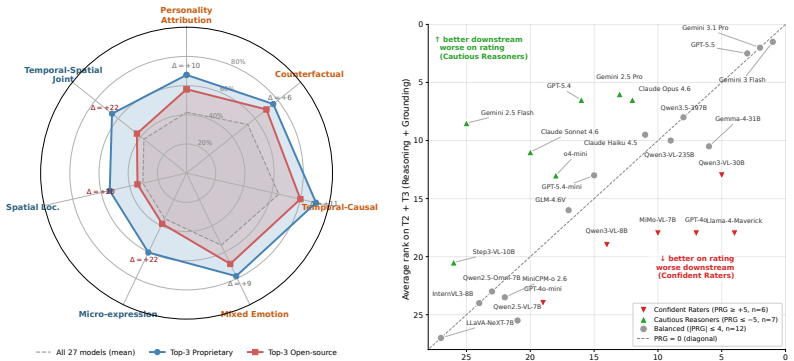
The authors establish that across the field of tested MLLMs, 51 percent of correct Big Five ratings are not grounded in retrieved cues, and holistic-grounding rates span only 0 to 33.5 percent. This disconnect is measured by requiring models to produce a rating, a reasoning step, and explicit grounding in timestamped observations on a dataset built through a multi-agent pipeline followed by human verification.
What carries the argument
The three-tier evaluation of rating, reasoning, and grounding together with four sample-level failure-mode metrics including Prejudice Rate and Holistic-Grounding Rate.
If this is right
- Standard numerical accuracy benchmarks for personality perception will overstate model capability if they ignore grounding.
- Model development must add mechanisms that retrieve and cite specific behavioral evidence rather than rely on first-impression patterns.
- Deployment in human-facing roles such as interviews or team evaluation requires grounding checks to reduce the risk of unexamined prejudice.
- New training objectives could reward explicit cue integration to close the observed gap between score and reason.
Where Pith is reading between the lines
- The same ungrounded pattern may appear in other multimodal tasks that involve interpreting human behavior.
- Training data or fine-tuning that explicitly penalizes correct-but-ungrounded answers could be tested as a direct remedy.
- Extending the approach to longer videos or live interactions would reveal whether the prejudice gap widens with more complex input.
Load-bearing premise
The multi-agent pipeline combined with human verification produces reliable timestamped behavioral observations that constitute valid ground truth for personality trait analyses.
What would settle it
Independent human re-annotation of a random subset of the videos followed by recomputation of the prejudice and holistic-grounding rates to check whether the reported percentages hold.
Figures

read the original abstract
Multimodal Large Language Models (MLLMs) are increasingly deployed in human-facing roles where personality perception is critical, yet existing benchmarks evaluate this capability solely on numerical Big Five score prediction, leaving open whether models truly perceive personality through behavioral understanding or merely prejudge through superficial pattern matching. We address this gap with three contributions. (i) A new task: we formalize Grounded Personality Reasoning (GPR), which requires MLLMs to anchor each Big Five rating in observable evidence through a chain of rating, reasoning, and grounding. (ii) A new dataset: we release MM-OCEAN (1,104 videos, 5,320 MCQs), produced by a multi-agent pipeline with human verification, with timestamped behavioral observations, evidence-grounded trait analyses, and seven categories of cue-grounding MCQs. (iii) Benchmark and analysis: we design a three-tier evaluation (rating, reasoning, grounding) plus four sample-level failure-mode metrics: Prejudice Rate (PR), Confabulation Rate (CR), Integration-failure Rate (IR), and Holistic-grounding Rate (HR), and benchmark 27 MLLMs (13 closed, 14 open). The analysis uncovers a striking Prejudice Gap: across the field, 51% of correct ratings are not grounded in retrieved cues, and the Holistic-Grounding Rate spans only 0-33.5%. These findings expose a disconnect between getting the right score and reasoning for the right reason, charting a roadmap for grounded social cognition in MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Grounded Personality Reasoning (GPR) as a new task requiring MLLMs to anchor Big Five personality ratings in observable video evidence via rating-reasoning-grounding chains. It releases the MM-OCEAN dataset (1,104 videos, 5,320 MCQs) constructed via a multi-agent pipeline plus human verification, containing timestamped observations and cue-grounding questions. The authors benchmark 27 MLLMs (13 closed, 14 open) using three-tier evaluation and four failure-mode metrics (Prejudice Rate, Confabulation Rate, Integration-failure Rate, Holistic-grounding Rate), reporting that 51% of correct ratings lack grounding in retrieved cues and that Holistic-Grounding Rates range from 0-33.5%.
Significance. If the central findings hold after validation, the work is significant for shifting personality-perception evaluation from score accuracy alone to process grounding, exposing a systematic disconnect between correct outputs and evidence-based reasoning in current MLLMs. The new task definition, dataset, and metrics provide concrete tools for measuring and improving social cognition capabilities relevant to human-facing applications.
major comments (1)
- [Dataset and evaluation setup] Dataset construction (multi-agent pipeline + human verification): The Prejudice Gap claim (51% of correct ratings ungrounded) and Holistic-Grounding Rate range (0-33.5%) are load-bearing on the fidelity of the ground-truth cue labels and MCQ distinctions. No inter-annotator agreement, pipeline error rates, or external validation metrics for cue extraction or grounding criteria are reported, leaving open whether the observed gap reflects model behavior or annotation artifacts.
minor comments (2)
- [Task formalization] Clarify the exact rules used to map timestamped observations to the seven categories of cue-grounding MCQs and how these categories map to the four failure-mode metrics.
- [Benchmark results] Provide statistical significance tests or confidence intervals for the 51% figure and the per-model Holistic-Grounding Rates to support cross-model comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address the single major comment below, committing to strengthen the manuscript's reporting on dataset validation.
read point-by-point responses
-
Referee: [Dataset and evaluation setup] Dataset construction (multi-agent pipeline + human verification): The Prejudice Gap claim (51% of correct ratings ungrounded) and Holistic-Grounding Rate range (0-33.5%) are load-bearing on the fidelity of the ground-truth cue labels and MCQ distinctions. No inter-annotator agreement, pipeline error rates, or external validation metrics for cue extraction or grounding criteria are reported, leaving open whether the observed gap reflects model behavior or annotation artifacts.
Authors: We agree that quantitative validation of the ground-truth labels is essential for interpreting the Prejudice Gap and Holistic-Grounding Rates. The MM-OCEAN construction used a multi-agent pipeline for initial extraction followed by human verification, but the initial submission did not report inter-annotator agreement or pipeline error rates. In the revised manuscript we will add a dedicated subsection reporting Cohen's kappa for cue relevance and grounding judgments during human verification, plus error rates observed in the pipeline. This will clarify that the reported gaps primarily reflect model behavior rather than annotation artifacts. revision: yes
Circularity Check
New task, dataset, and empirical rates show no circular reduction
full rationale
The paper defines a new task (Grounded Personality Reasoning), constructs MM-OCEAN via multi-agent pipeline plus human verification, and reports direct empirical statistics (51% ungrounded correct ratings, HR 0-33.5%) from three-tier evaluation of 27 MLLMs. These quantities are computed from the newly annotated data rather than obtained by fitting parameters to model outputs and relabeling them as predictions, or by any self-citation chain that supplies the central result. No equations, uniqueness theorems, or ansatzes are invoked that would make the reported gap equivalent to the input annotations by construction. The analysis is therefore self-contained as a standard benchmark study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Big Five personality traits can be reliably inferred from observable behavioral cues in short videos.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Nalini Ambady and Robert Rosenthal. Thin slices of expressive behavior as predictors of interpersonal consequences: A meta-analysis.Psychological bulletin, 111(2):256, 1992
work page 1992
-
[3]
Anthropic. Claude Haiku 4.5. https://www.anthropic.com/claude/haiku, 2025. Claude Haiku 4.5; accessed 2026-05-04
work page 2025
-
[4]
Anthropic. Claude Opus 4.6. https://www.anthropic.com/claude/opus, 2025. Claude Opus 4.6; accessed 2026-05-04
work page 2025
-
[5]
Anthropic. Claude Sonnet 4.6. https://www.anthropic.com/claude/sonnet, 2025. Claude Sonnet 4.6; accessed 2026-05-04
work page 2025
-
[6]
The claude 3 model family: Opus, sonnet, haiku.Claude-3 Model Card, 1(1):4, 2024
AI Anthropic. The claude 3 model family: Opus, sonnet, haiku.Claude-3 Model Card, 1(1):4, 2024
work page 2024
-
[7]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Murray R Barrick and Michael K Mount. The big five personality dimensions and job perfor- mance: a meta-analysis.Personnel psychology, 44(1):1–26, 1991
work page 1991
-
[9]
Towards interactive intelligence for digital humans
Yiyi Cai, Xuangeng Chu, Xiwei Gao, Sitong Gong, Yifei Huang, Caixin Kang, Kunhang Li, Haiyang Liu, Ruicong Liu, Yun Liu, et al. Towards interactive intelligence for digital humans. arXiv preprint arXiv:2512.13674, 2025
-
[10]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[11]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
European Parliament Council and the. Regulation (eu) 2024/1689 of the european parliament and of the council of 13 june 2024 laying down harmonised rules on artificial intelligence and amending regulations (ec) no 300/2008,(eu) no 167/2013,(eu) no 168/2013,(eu) 2018/858,(eu) 2018/1139 and (eu) 2019/2144 and directives 2014/90/eu,(eu) 2016/797 and (eu) 202...
work page 2024
-
[13]
Nonverbal leakage and clues to deception.Psychiatry, 32 (1):88–106, 1969
Paul Ekman and Wallace V Friesen. Nonverbal leakage and clues to deception.Psychiatry, 32 (1):88–106, 1969. 10
work page 1969
-
[14]
Hugo Jair Escalante, Heysem Kaya, Albert Ali Salah, Sergio Escalera, Ya ˘gmur Güçlütürk, Umut Güçlü, Xavier Baró, Isabelle Guyon, Julio CS Jacques Junior, Meysam Madadi, et al. Modeling, recognizing, and explaining apparent personality from videos.IEEE Transactions on Affective Computing, 13(2):894–911, 2020
work page 2020
-
[15]
Mmbench-video: A long-form multi-shot benchmark for holistic video understanding
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, and Kai Chen. Mmbench-video: A long-form multi-shot benchmark for holistic video understanding. Advances in Neural Information Processing Systems, 37:89098–89124, 2024
work page 2024
-
[16]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
work page 2025
-
[17]
On the accuracy of personality judgment: a realistic approach.Psychological review, 102(4):652, 1995
David C Funder. On the accuracy of personality judgment: a realistic approach.Psychological review, 102(4):652, 1995
work page 1995
-
[18]
Moody5: Personality-biased agents to enhance interactive storytelling in video games
Francesco Garavaglia, Renato Avellar Nobre, Laura Anna Ripamonti, Dario Maggiorini, and Davide Gadia. Moody5: Personality-biased agents to enhance interactive storytelling in video games. In2022 IEEE Conference on Games (CoG), pages 175–182. IEEE, 2022
work page 2022
-
[19]
Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
work page 2021
-
[20]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team Glm, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Google DeepMind. Gemma 4. https://deepmind.google/models/gemma/, 2025. Gemma- 4-31B-it; accessed 2026-05-04
work page 2025
- [22]
-
[23]
Multimodal large language model
-
[24]
Google DeepMind. Gemini 3.1 pro. https://deepmind.google/models/gemini/, 2025. Gemini 3.1 Pro; accessed 2026-05-04
work page 2025
-
[25]
Google DeepMind. Gemini 3 flash. https://deepmind.google/models/gemini/, 2025. Gemini 3 Flash; accessed 2026-05-04
work page 2025
-
[26]
The distress analysis interview corpus of human and computer interviews
Jonathan Gratch, Ron Artstein, Gale M Lucas, Giota Stratou, Stefan Scherer, Angela Nazarian, Rachel Wood, Jill Boberg, David DeVault, Stacy Marsella, et al. The distress analysis interview corpus of human and computer interviews. InLrec, volume 14, pages 3123–3128. Reykjavik, 2014
work page 2014
-
[27]
Ya˘gmur Güçlütürk, Umut Güçlü, Marcel AJ van Gerven, and Rob van Lier. Deep impression: Audiovisual deep residual networks for multimodal apparent personality trait recognition. In European conference on computer vision, pages 349–358. Springer, 2016
work page 2016
-
[28]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Step3-vl-10b technical report.arXiv preprint arXiv:2601.09668, 2026
Ailin Huang, Chengyuan Yao, Chunrui Han, Fanqi Wan, Hangyu Guo, Haoran Lv, Hongyu Zhou, Jia Wang, Jian Zhou, Jianjian Sun, et al. Step3-vl-10b technical report.arXiv preprint arXiv:2601.09668, 2026
-
[30]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Oliver P John, Laura P Naumann, and Christopher J Soto. Paradigm shift to the integrative big five trait taxonomy.Handbook of personality: Theory and research, 3(2):114–158, 2008
work page 2008
-
[32]
Caixin Kang, Yifei Huang, Liangyang Ouyang, Mingfang Zhang, Ruicong Liu, and Yoichi Sato. Can mllms read the room? a multimodal benchmark for assessing deception in multi-party social interactions.arXiv preprint arXiv:2511.16221, 2025
-
[33]
Fantom: A benchmark for stress-testing machine theory of mind in interactions
Hyunwoo Kim, Melanie Sclar, Xuhui Zhou, Ronan Bras, Gunhee Kim, Yejin Choi, and Maarten Sap. Fantom: A benchmark for stress-testing machine theory of mind in interactions. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14397–14413, 2023
work page 2023
-
[34]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[35]
Jeff T Larsen, A Peter McGraw, and John T Cacioppo. Can people feel happy and sad at the same time?Journal of personality and social psychology, 81(4):684, 2001
work page 2001
-
[36]
Xiaomi mimo-vl-miloco technical report.arXiv preprint arXiv:2512.17436, 2025
Jiaze Li, Jingyang Chen, Yuxun Qu, Shijie Xu, Zhenru Lin, Junyou Zhu, Boshen Xu, Wenhui Tan, Pei Fu, Jianzhong Ju, et al. Xiaomi mimo-vl-miloco technical report.arXiv preprint arXiv:2512.17436, 2025
-
[37]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
work page 2024
-
[38]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[39]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
work page 2024
-
[40]
Single-to-dual-view adaptation for egocentric 3d hand pose estimation
Ruicong Liu, Takehiko Ohkawa, Mingfang Zhang, and Yoichi Sato. Single-to-dual-view adaptation for egocentric 3d hand pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 677–686, 2024
work page 2024
-
[41]
SFHand: Learning Embodied Manipulation by Streaming Egocentric 3D Hand Forecasting
Ruicong Liu, Yifei Huang, Liangyang Ouyang, Caixin Kang, and Yoichi Sato. Sfhand: A streaming framework for language-guided 3d hand forecasting and embodied manipulation. arXiv preprint arXiv:2511.18127, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. Tempcompass: Do video llms really understand videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, 2024
work page 2024
-
[43]
Generalizing gaze estimation with outlier- guided collaborative adaptation
Yunfei Liu, Ruicong Liu, Haofei Wang, and Feng Lu. Generalizing gaze estimation with outlier- guided collaborative adaptation. InProceedings of the IEEE/CVF international conference on computer vision, pages 3835–3844, 2021
work page 2021
-
[44]
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023
work page 2023
-
[45]
Robert R McCrae and Paul T Costa. Validation of the five-factor model of personality across instruments and observers.Journal of personality and social psychology, 52(1):81, 1987
work page 1987
-
[46]
Meta. Llama 4 Maverick. https://ai.meta.com/blog/ llama-4-multimodal-intelligence/ , 2025. Llama-4-Maverick (FP8 variant); ac- cessed 2026-05-04. 12
work page 2025
-
[47]
Iftekhar Naim, Md Iftekhar Tanveer, Daniel Gildea, and Mohammed Ehsan Hoque. Auto- mated analysis and prediction of job interview performance.IEEE Transactions on Affective Computing, 9(2):191–204, 2016
work page 2016
-
[48]
OpenAI. GPT-5. https://openai.com/index/introducing-gpt-5/, 2025. Large lan- guage model
work page 2025
-
[49]
GPT-5.4.https://openai.com/, 2025
OpenAI. GPT-5.4.https://openai.com/, 2025. GPT-5.4; accessed 2026-05-04
work page 2025
-
[50]
OpenAI. GPT-5.4-mini. https://openai.com/, 2025. GPT-5.4-mini; accessed 2026-05-04
work page 2025
-
[51]
GPT-5.5.https://openai.com/, 2025
OpenAI. GPT-5.5.https://openai.com/, 2025. GPT-5.5; accessed 2026-05-04
work page 2025
-
[52]
OpenAI. o4-mini. https://openai.com/index/introducing-o3-and-o4-mini/ , 2025. Reasoning-capable language model
work page 2025
-
[53]
Liangyang Ouyang, Yifei Huang, Mingfang Zhang, Caixin Kang, Ryosuke Furuta, and Yoichi Sato. Multi-speaker attention alignment for multimodal social interaction.arXiv preprint arXiv:2511.17952, 2025
-
[54]
SocialDirector: Training-Free Social Interaction Control for Multi-Person Video Generation
Liangyang Ouyang, Ruicong Liu, Caixin Kang, Yifei Huang, and Yoichi Sato. Socialdirector: Training-free social interaction control for multi-person video generation.arXiv preprint arXiv:2605.10079, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Context-aware per- sonality inference in dyadic scenarios: Introducing the udiva dataset
Cristina Palmero, Javier Selva, Sorina Smeureanu, Julio Junior, Jacques CS, Albert Clapés, Alexa Moseguí, Zejian Zhang, David Gallardo, Georgina Guilera, et al. Context-aware per- sonality inference in dyadic scenarios: Introducing the udiva dataset. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1–12, 2021
work page 2021
-
[56]
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Recasens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Perception test: A diagnostic benchmark for multimodal video models.Advances in Neural Information Processing Systems, 36:42748–42761, 2023
work page 2023
-
[57]
Chalearn lap 2016: First round challenge on first impressions-dataset and results
Víctor Ponce-López, Baiyu Chen, Marc Oliu, Ciprian Corneanu, Albert Clapés, Isabelle Guyon, Xavier Baró, Hugo Jair Escalante, and Sergio Escalera. Chalearn lap 2016: First round challenge on first impressions-dataset and results. InEuropean conference on computer vision, pages 400–418. Springer, 2016
work page 2016
-
[58]
Meld: A multimodal multi-party dataset for emotion recognition in conversa- tions
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. Meld: A multimodal multi-party dataset for emotion recognition in conversa- tions. InProceedings of the 57th annual meeting of the association for computational linguistics, pages 527–536, 2019
work page 2019
-
[59]
Qwen Team. Qwen3.5. https://qwen.ai/blog?id=qwen3.5, 2025. Large language model
work page 2025
-
[60]
Counterfactual thinking.Psychological bulletin, 121(1):133, 1997
Neal J Roese. Counterfactual thinking.Psychological bulletin, 121(1):133, 1997
work page 1997
-
[61]
Hossein Saberi and Reza Ravanmehr. Transformer-based personality trait recognition enhanced by contextual augmentation.International Journal of Web Research, 9(1):1–24, 2026
work page 2026
-
[62]
Emobench: Evaluating the emotional intelligence of large language models
Sahand Sabour, Siyang Liu, Zheyuan Zhang, June Liu, Jinfeng Zhou, Alvionna Sunaryo, Tatia Lee, Rada Mihalcea, and Minlie Huang. Emobench: Evaluating the emotional intelligence of large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5986–6004, 2024
work page 2024
-
[63]
Social iqa: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. Social iqa: Commonsense reasoning about social interactions. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4463–4473, 2019
work page 2019
-
[64]
Cheng Tang, Chao Tang, Steven Gong, Thomas M Kwok, and Yue Hu. Robot character generation and adaptive human-robot interaction with personality shaping.arXiv preprint arXiv:2503.15518, 2025. 13
-
[65]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen Team. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models
Yufan Wu, Yinghui He, Yilin Jia, Rada Mihalcea, Yulong Chen, and Naihao Deng. Hi-tom: A benchmark for evaluating higher-order theory of mind reasoning in large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10691–10706, 2023
work page 2023
-
[70]
Next-qa: Next phase of question- answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question- answering to explaining temporal actions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9777–9786, 2021
work page 2021
-
[71]
Hainiu Xu, Runcong Zhao, Lixing Zhu, Jinhua Du, and Yulan He. Opentom: A comprehensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8593–8623, 2024
work page 2024
-
[72]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Wen-Jing Yan, Xiaobai Li, Su-Jing Wang, Guoying Zhao, Yong-Jin Liu, Yu-Hsin Chen, and Xiaolan Fu. Casme ii: An improved spontaneous micro-expression database and the baseline evaluation.PloS one, 9(1):e86041, 2014
work page 2014
-
[74]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[75]
Modeling context in referring expressions
Licheng Yu, Patrick Poirson, Shan Yang, Alexander C Berg, and Tamara L Berg. Modeling context in referring expressions. InEuropean conference on computer vision, pages 69–85. Springer, 2016
work page 2016
-
[76]
You are a non- interpretive behavior recorder. Record only what is observable; never explain why
Zhu Zhang, Zhou Zhao, Yang Zhao, Qi Wang, Huasheng Liu, and Lianli Gao. Where does it exist: Spatio-temporal video grounding for multi-form sentences. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10668–10677, 2020. 14 Appendix Contents Appendix Overview The appendix is grouped thematically. Cross-references in...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.