ProvenAI: Provenance-Native Traces of Evidence in Generated Answers
Pith reviewed 2026-06-26 01:11 UTC · model grok-4.3
The pith
Meaningful transparency in retrieval-grounded QA requires traceable links across retrieved, cited, and behaviourally influential evidence as three distinct, independently measured layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
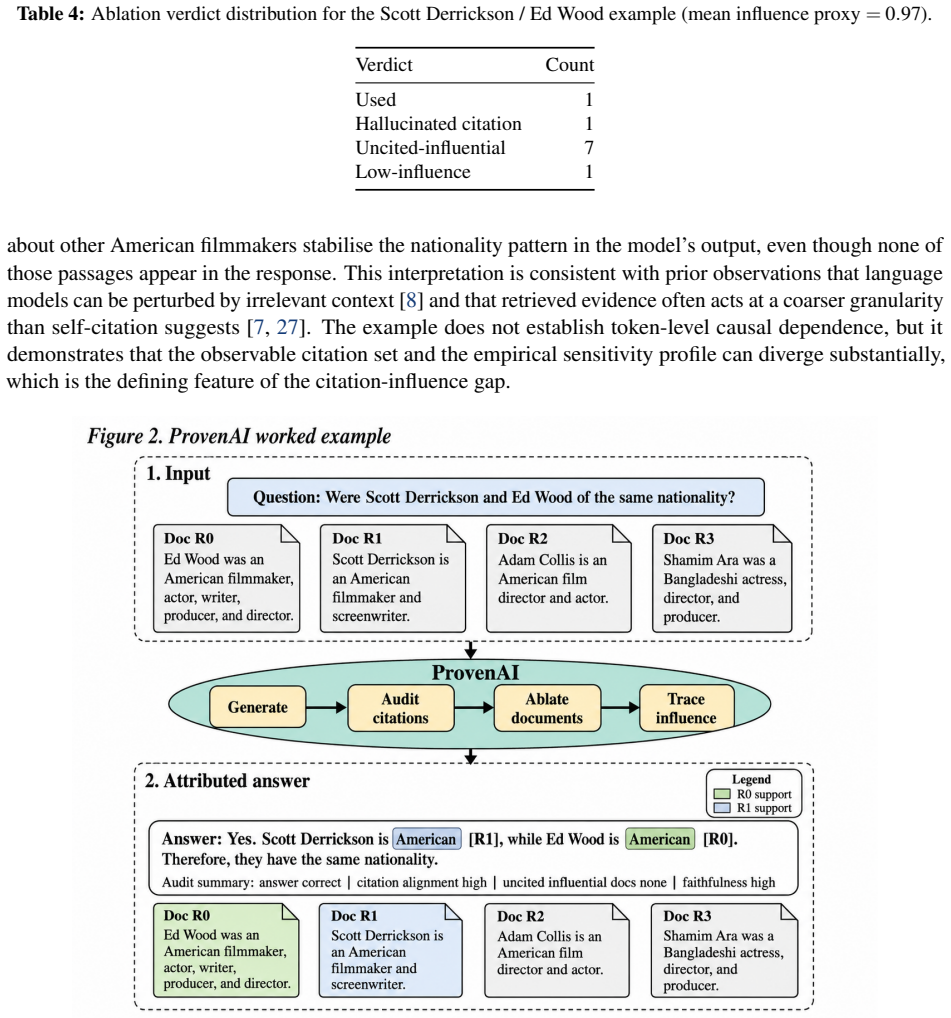
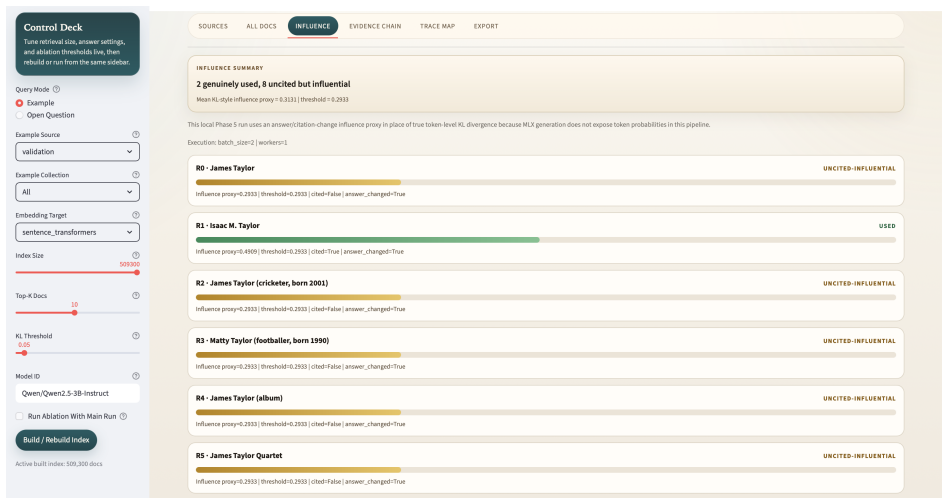
ProvenAI decomposes transparency in multi-hop QA into answer correctness, citation fidelity against benchmark supporting evidence, and per-document influence under leave-one-resource-out intervention. On 7,405 HotpotQA validation examples the system records 53.53 percent answer accuracy and 71.55 percent mean citation fidelity while surfacing cases in which a clean citation audit occurs alongside weak influence from one cited source and measurable shifts from seven uncited sources. The framework formalises a faithfulness condition linking surface proxies to token-level KL-divergence and composes the three layers with emerging cryptographic provenance methods.
What carries the argument
Three-layer measurement pipeline of answer correctness, citation fidelity, and leave-one-resource-out influence estimation, implemented through a seven-stage process of normalisation, indexing, generation, auditing, ablation, evaluation and inspection.
If this is right
- Citation audits must be supplemented by explicit influence measurement to verify which sources shaped an answer.
- Retrieval-grounded systems require separate reporting of retrieved evidence, cited evidence, and behaviourally influential evidence.
- Batch pipelines can systematically expose citation-influence gaps across thousands of examples.
- The three layers can be composed with cryptographic provenance records for autonomous discovery workflows.
- Multi-hop QA benchmarks benefit from joint evaluation of correctness, fidelity and ablation-based influence.
Where Pith is reading between the lines
- The same three-layer audit could be applied to single-hop or open-domain retrieval tasks to check whether the gap persists outside multi-hop settings.
- Developers might use influence scores to prioritise retrieval re-ranking or to trigger generation re-runs when influential documents are missing from citations.
- User-facing interfaces could display the influence layer alongside citations to let readers distinguish decorative references from causally active ones.
- Integration with database provenance techniques could allow the three layers to be recorded as immutable traces for later verification.
Load-bearing premise
Removing one resource at a time accurately isolates that document's causal effect on the generated answer without being confounded by the model's own generation process or by retrieval ordering.
What would settle it
An experiment showing that citation-fidelity scores alone predict answer correctness at the same rate as the full three-layer measurement, with no additional explanatory power from the influence layer.
Figures

read the original abstract
Retrieval-augmented systems routinely present citations alongside generated answers, yet a citation does not confirm that the corresponding source meaningfully shaped the output. This paper introduces ProvenAI, a framework that decomposes transparency in multi-hop question answering into three independently measurable layers: answer correctness, citation fidelity against benchmark supporting evidence, and per-document influence under leave-one-resource-out intervention. Targeting the HotpotQA distractor benchmark through a seven-stage pipeline covering data normalisation, retrieval indexing, citation-aware answer generation, attribution auditing, ablation-based influence estimation, batch evaluation, and interactive inspection, ProvenAI evaluates 7,405 validation examples drawn from a canonical corpus of 509,300 passages. The system achieves 53.53% answer accuracy alongside a mean citation-fidelity score of 71.55%, and a worked example surfaces what we call the citation-influence gap: a clean citation audit co-occurring with a profile in which one cited source registers only weak influence while seven uncited sources demonstrably shift the output. We formalise the relationship between the implemented surface proxy and a token-level KL-divergence target through a stated faithfulness condition, ground the framework in causal-mediation analysis and database-provenance theory, and discuss how the three measurement layers compose with cryptographic provenance architectures emerging in autonomous scientific discovery. ProvenAI establishes that meaningful transparency in retrieval-grounded QA requires traceable links across retrieved, cited, and behaviourally influential evidence as three distinct, independently measured layers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProvenAI, a seven-stage framework that decomposes transparency in retrieval-augmented multi-hop QA into three layers—answer correctness, citation fidelity against benchmark supporting evidence, and per-document influence measured by leave-one-resource-out ablation—evaluated on 7,405 HotpotQA validation examples from a 509,300-passage corpus. It reports 53.53% answer accuracy and 71.55% mean citation fidelity, presents a worked example of a 'citation-influence gap,' formalizes a faithfulness condition relating a surface proxy to token-level KL divergence, and grounds the approach in causal-mediation analysis and database-provenance theory.
Significance. If the three layers can be shown to be independently measurable, the work would usefully demonstrate that citations do not guarantee behavioral influence and would support provenance-native architectures for trustworthy RAG. The scale of the evaluation (7,405 examples) and the concrete gap example are strengths; the explicit grounding in external causal-mediation and provenance literature is also noted.
major comments (2)
- [ablation-based influence estimation] § on ablation-based influence estimation (within the seven-stage pipeline): the leave-one-resource-out procedure does not include controls that hold retrieval ordering or attention patterns fixed, so the output delta mixes direct document contribution with indirect re-ranking and generation-trajectory effects; this directly undermines the claim that influence is independently measurable from citation fidelity.
- [formalising the relationship between the implemented surface proxy and a token-level KL-divergence target] Section formalizing the faithfulness condition: the paper states that the implemented surface proxy relates to a token-level KL-divergence target via a 'faithfulness condition' but supplies neither the explicit functional form nor any derivation or validation that the proxy isolates causal influence; this is load-bearing for the independence of the three layers.
minor comments (2)
- [Abstract] The abstract reports numerical results (53.53% accuracy, 71.55% fidelity) without accompanying standard errors or confidence intervals, which would improve interpretability of the citation-influence gap.
- [seven-stage pipeline] The seven-stage pipeline is described at a high level; a diagram or explicit pseudocode would clarify the data flow between citation-aware generation and attribution auditing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the ablation procedure and the formalization of the faithfulness condition. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [ablation-based influence estimation] § on ablation-based influence estimation (within the seven-stage pipeline): the leave-one-resource-out procedure does not include controls that hold retrieval ordering or attention patterns fixed, so the output delta mixes direct document contribution with indirect re-ranking and generation-trajectory effects; this directly undermines the claim that influence is independently measurable from citation fidelity.
Authors: We agree that the leave-one-resource-out ablation measures the net effect on the final output, which can include indirect effects via re-ranking or attention changes. This is intentional: our definition of per-document influence is the observable change in system behavior when a resource is removed from the available corpus, reflecting real-world deployment where all pipeline components interact. Citation fidelity audits surface attribution against benchmark evidence, while influence quantifies behavioral impact; these remain distinct even when influence propagates through re-ranking. To clarify this distinction and avoid any implication of isolating purely direct effects, we will revise the relevant section to explicitly define influence as the total causal effect in the full pipeline and add a note on the difference from controlled direct-effect isolation. revision: partial
-
Referee: [formalising the relationship between the implemented surface proxy and a token-level KL-divergence target] Section formalizing the faithfulness condition: the paper states that the implemented surface proxy relates to a token-level KL-divergence target via a 'faithfulness condition' but supplies neither the explicit functional form nor any derivation or validation that the proxy isolates causal influence; this is load-bearing for the independence of the three layers.
Authors: We acknowledge that the manuscript states the faithfulness condition at a high level without supplying the explicit functional form, derivation, or validation steps. In the revised version we will add the mathematical definition of the surface proxy, the precise statement of the faithfulness condition relating it to token-level KL divergence, and a short derivation under the stated assumptions (including the conditions under which the proxy approximates causal influence). This addition will be placed in the formalization section to better support the claimed independence of the three measurement layers. revision: yes
Circularity Check
No circularity: three layers defined via external benchmarks and cited theory
full rationale
The paper operationalizes answer correctness, citation fidelity, and leave-one-resource-out influence as distinct measurements on HotpotQA without any equations or fitted parameters that reduce one layer to another by construction. The framework is explicitly grounded in external causal-mediation analysis and database-provenance theory rather than self-citation chains or internal definitions. No self-definitional steps, fitted-input predictions, or ansatz smuggling appear in the described pipeline or claims. The central assertion that the layers are independently measurable therefore rests on the external grounding and benchmark results rather than reducing to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The stated faithfulness condition relating the surface proxy to token-level KL-divergence holds.
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 9459–9474, 2020
2020
-
[2]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2369–2380, 2018
2018
-
[4]
MultiHop-RAG: Benchmarking Retrieval-Augmented Generation for Multi-Hop Queries
Yixuan Tang and Yi Yang. MultiHop-RAG: Benchmarking retrieval-augmented generation for multi-hop queries.arXiv preprint arXiv:2401.15391, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Liu, Tianyi Zhang, and Percy Liang
Nelson F. Liu, Tianyi Zhang, and Percy Liang. Evaluating verifiability in generative search engines. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7001–7025, 2023
2023
-
[6]
Enabling large language models to generate text with citations
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. Enabling large language models to generate text with citations. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6465–6482, 2023
2023
-
[7]
Model internals-based answer attribution for trustworthy retrieval-augmented generation
Jirui Qi, Gabriele Sarti, Raquel Fernández, and Arianna Bisazza. Model internals-based answer attribution for trustworthy retrieval-augmented generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6006–6031, 2024
2024
-
[8]
Chi, Nathanael Schärli, and Denny Zhou
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H. Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. InProceedings of the 40th International Conference on Machine Learning (ICML), pages 31210–31227, 2023
2023
-
[9]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), pages 9802–9822, 2023
2023
-
[10]
LLM-powered automated cloud forensics: From log analysis to investigation
Dalal Alharthi and Rozhin Yasaei. LLM-powered automated cloud forensics: From log analysis to investigation. In2025 IEEE 18th International Conference on Cloud Computing (CLOUD), pages 12–22. IEEE, 2025
2025
-
[11]
Dalal Alharthi and Ivan Roberto Kawaminami Garcia. Cloud investigation automation framework (CIAF): An AI-driven approach to cloud forensics.arXiv preprint arXiv:2510.00452, 2025
-
[12]
Introducing the Model Context Protocol
Anthropic. Introducing the Model Context Protocol. https://www.anthropic.com/news/ model-context-protocol, 2024. Accessed: 2026-05-07
2024
-
[13]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas O˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, 2020. 11
2020
-
[14]
Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs.IEEE Transactions on Big Data, 7(3):535–547, 2021
2021
-
[15]
MuSiQue: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[16]
Jiawei Chen, Hongyu Lin, Xianpei Han, and Le Sun. Benchmarking large language models in retrieval- augmented generation.arXiv preprint arXiv:2309.01431, 2023
-
[17]
Self-RAG: Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[18]
Ethan David James Parks and Dalal Alharthi. Predictive maps of multi-agent reasoning: A successor- representation spectrum for LLM communication topologies.arXiv preprint arXiv:2605.11453, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Sentence-BERT: Sentence embeddings using siamese BERT- networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992, 2019
2019
-
[20]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
FActScore: Fine-grained atomic evaluation of factual precision in long-form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. FActScore: Fine-grained atomic evaluation of factual precision in long-form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 12076–12100, 2023
2023
-
[22]
Ragas: Automated Evaluation of Retrieval Augmented Generation
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. RAGAS: Automated evaluation of retrieval augmented generation.arXiv preprint arXiv:2309.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Measuring attribution in natural language generation models.Computational Linguistics, 49(4):777–840, 2023
Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, and Michael Collins. Measuring attribution in natural language generation models.Computational Linguistics, 49(4):777–840, 2023
2023
-
[24]
why should I trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “why should I trust you?”: Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135–1144, 2016
2016
-
[25]
Investigating gender bias in language models using causal mediation analysis
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. Investigating gender bias in language models using causal mediation analysis. InAdvances in Neural Information Processing Systems (NeurIPS), volume 33, pages 12388–12401, 2020
2020
-
[26]
Cambridge University Press, 2nd edition, 2009
Judea Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2nd edition, 2009
2009
-
[27]
ContextCite: Attributing model generation to context.arXiv preprint arXiv:2409.00729, 2024
Benjamin Cohen-Wang, Harshay Shah, Kristian Georgiev, and Aleksander Madry. ContextCite: Attributing model generation to context.arXiv preprint arXiv:2409.00729, 2024
-
[28]
Yung-Sung Chuang, Benjamin Cohen-Wang, Shannon Zejiang Shen, Zhaofeng Wu, and Hu Xu. SelfCite: Self-supervised alignment for context attribution in large language models.arXiv preprint arXiv:2502.09604, 2025. 12
-
[29]
Alharthi
Dalal N. Alharthi. Secure cloud migration strategy (SCMS): A safe journey to the cloud. InProceedings of the International Conference on Cyber Warfare and Security (ICCWS), pages 1–6. Academic Conferences International, 2023
2023
-
[30]
Why and where: A characterization of data provenance
Peter Buneman, Sanjeev Khanna, and Wang-Chiew Tan. Why and where: A characterization of data provenance. InProceedings of the 8th International Conference on Database Theory (ICDT), pages 316–330, 2001
2001
-
[31]
Provenance in databases: Why, how, and where
James Cheney, Laura Chiticariu, and Wang-Chiew Tan. Provenance in databases: Why, how, and where. Foundations and Trends in Databases, 1(4):379–474, 2009
2009
-
[32]
Introduction to the Model Context Protocol
Model Context Protocol Documentation. Introduction to the Model Context Protocol. https:// modelcontextprotocol.io/docs/getting-started/intro, 2026. Accessed: 2026-05-07
2026
-
[33]
A call to action for a secure-by-design generative AI paradigm.arXiv preprint arXiv:2510.00451, 2025
Dalal Alharthi and Ivan Roberto Kawaminami Garcia. A call to action for a secure-by-design generative AI paradigm.arXiv preprint arXiv:2510.00451, 2025
-
[34]
Automating Cloud Security and Forensics Through a Secure-by-Design Generative AI Framework
Dalal Alharthi and Ivan Roberto Kawaminami Garcia. Automating cloud security and forensics through a secure-by-design generative AI framework.arXiv preprint arXiv:2604.03912, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Alharthi and Montasir Abbas
Dalal N. Alharthi and Montasir Abbas. A zero-trust reinforcement learning policy for mitigating cyberattacks on emergency vehicle preemption systems. InProceedings of the 2024 Winter Simulation Conference (WSC). IEEE, 2024
2024
-
[36]
Cloud incident response framework and AI-based forensics using reinforcement learning and graph neural networks
Dalal Alharthi. Cloud incident response framework and AI-based forensics using reinforcement learning and graph neural networks. In2024 IEEE 15th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), pages 164–170. IEEE, 2024
2024
-
[37]
Alharthi and Amelia C
Dalal N. Alharthi and Amelia C. Regan. A literature survey and analysis on social engineering defense mechanisms and InfoSec policies.International Journal of Network Security & Its Applications, 13(2): 41–61, 2021. A Proof of Proposition 1 We restate the setting briefly. Let pt,p ′ t be the next-token distributions under the full and ablated contexts at ...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.