Show, Don't TELL: Explainable AI-Generated Text Detection
Pith reviewed 2026-06-29 12:53 UTC · model grok-4.3
The pith
TELL detects AI text by annotating the specific phrases that reveal its origin.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
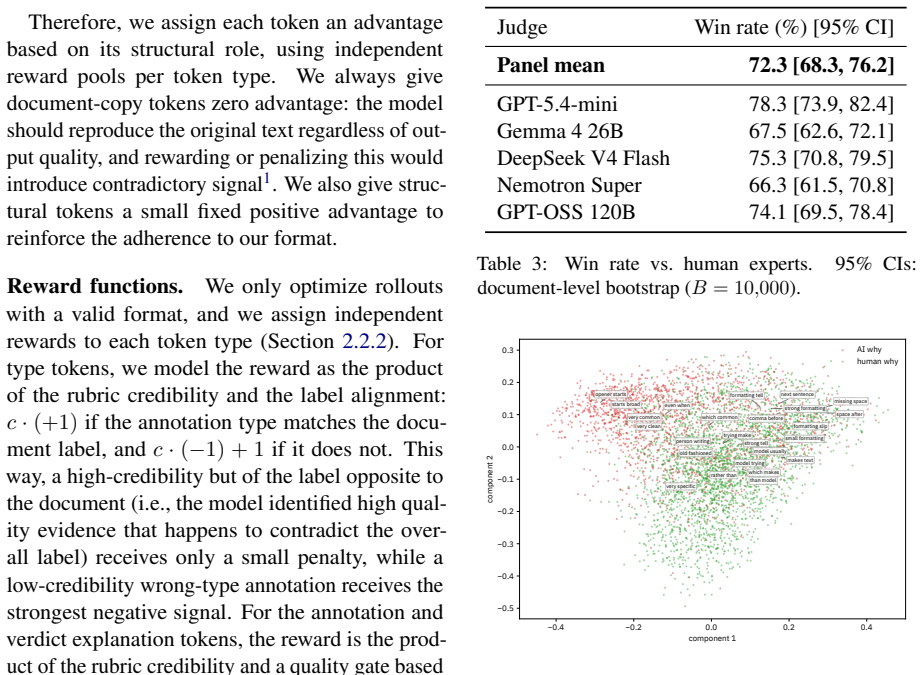
TELL integrates explainability from the start by generating annotations that highlight textual tells alongside a numerical score. It is trained on a custom SFT dataset of authorship annotations and optimized with GRPO plus curriculum learning, attaining an AUROC of 0.927 while its explanations achieve a 72.3 percent mean win-rate over alternatives on concreteness, falsifiability, coherence, plausibility, and grounding.
What carries the argument
The TELL model, which outputs both a detection score and explanatory annotations identifying specific textual features as evidence for AI or human authorship.
If this is right
- Users can inspect the detector's evidence and apply their own context-specific knowledge.
- Explanations allow critical assessment instead of accepting an opaque numeric output.
- The method supports development of other detectors that prioritize native explainability.
- Performance stays comparable to detectors that provide no explanations.
Where Pith is reading between the lines
- Annotations could serve as training material for writers learning to avoid detectable patterns.
- The annotation style might transfer to detection tasks in code or image generation.
- Integration into writing tools could give immediate, targeted feedback during composition.
Load-bearing premise
The custom SFT dataset of domain-specific authorship annotations and the human evaluation of explanations are representative enough that the reported performance and win-rates apply to real user needs.
What would settle it
A controlled test in which users classify texts as AI or human using only the score versus using the score plus TELL annotations, measuring whether the annotations measurably improve accuracy or decision confidence.
Figures
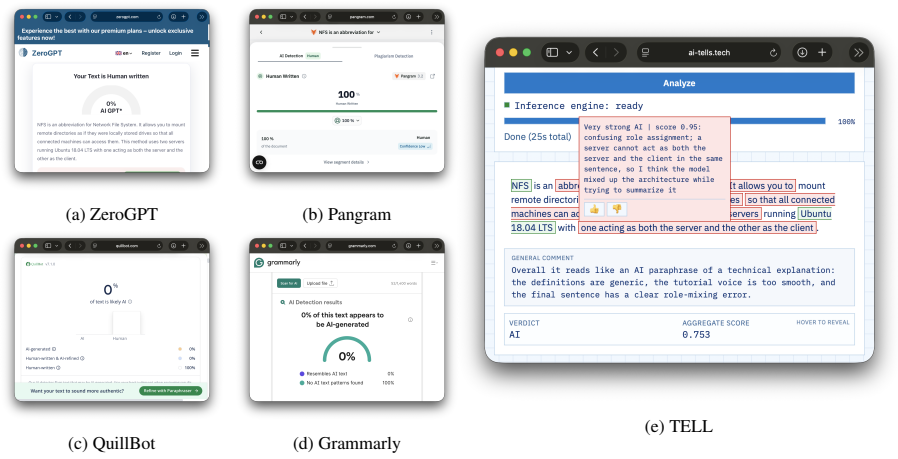
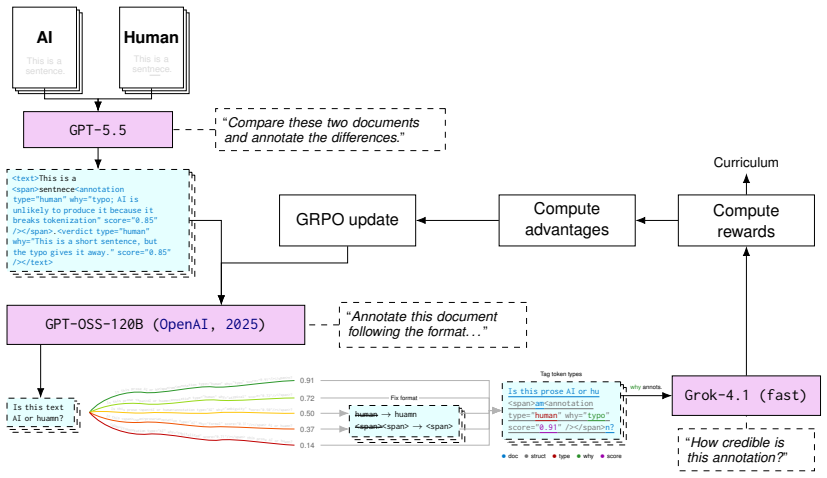

read the original abstract
Research on AI-generated text detection has presented a number of approaches to discern human from AI prose, some of which achieving high in-distribution performance. However, real-world applicability has stalled because their outputs are misaligned with the needs of users, such as professors, who are presented with a numeric score that has no attached explanation. We tackle this issue with a novel architecture, TELL, that bakes explainability from the ground-up. While our system still offers a numerical score like other detectors for comparability, TELL takes a fundamentally different approach where we aim to show the user the "tells" by which the model believes a text is AI or human-written, to empower the user to decide who wrote a text using their own judgment and understanding of the context of the writing and its alleged author. We train TELL on a custom SFT dataset of domain-specific authorship annotations, and further refine the system using GRPO with curriculum learning to improve performance. We achieve competitive performance with state-of-the-art detectors (AUROC 0.927) while natively providing annotations that explain the basis for the detector's decision. We further evaluate the quality of our explanations using a dataset of human annotations and report a high (mean 72.3%) win-rate on annotation concreteness, falsifiability, coherence, plausibility and grounding, allowing users to critically think and decide for themselves. Our work thus reframes the problem of AI-generated text detection in a human-centric perspective and paves the way for a new family of detectors that focus on native explainability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TELL, a novel architecture for AI-generated text detection that natively provides explainable annotations ('tells') identifying the basis for classifying text as AI- or human-written. It is trained via supervised fine-tuning on a custom dataset of domain-specific authorship annotations and further refined with GRPO and curriculum learning; the system reports an AUROC of 0.927 (competitive with SOTA detectors) while also claiming a mean 72.3% human win-rate on explanation quality metrics (concreteness, falsifiability, coherence, plausibility, grounding).
Significance. If the empirical claims hold after detailed validation, the work would be significant for shifting AI-text detection toward human-centric, explainable systems that empower users (e.g., professors) to apply their own judgment rather than relying on opaque scores. The native integration of explanations and the human evaluation protocol represent a constructive reframing, though the absence of dataset and evaluation details limits assessment of generalizability.
major comments (3)
- [Methods (dataset construction)] Methods section on dataset construction: the custom SFT dataset of domain-specific authorship annotations is described only at a high level with no information on annotator selection, inter-annotator agreement, labeling guidelines for 'tells', or sampling strategy for domain-specific texts; this is load-bearing for the AUROC 0.927 claim because held-out performance may not generalize if the dataset contains systematic biases from limited annotator pools or model-assisted labeling.
- [Experiments (human evaluation)] Experiments / human evaluation section: the protocol and dataset used to obtain the 72.3% mean win-rate on concreteness/falsifiability/coherence/plausibility/grounding lack details on annotator pool, guidelines, agreement metrics, or controls for bias; without these, the win-rate cannot be verified as representative of real-world user needs.
- [Results] Results section: baseline comparisons, exact dataset splits, and statistical significance tests supporting the AUROC 0.927 are only sketched, preventing confirmation that the performance is competitive on a fair, reproducible footing.
minor comments (1)
- [Abstract] Abstract and methods: the acronym GRPO is used without expansion or brief description on first use.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments that will help enhance the transparency and reproducibility of our work on TELL. Below we respond to each major comment and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [Methods (dataset construction)] Methods section on dataset construction: the custom SFT dataset of domain-specific authorship annotations is described only at a high level with no information on annotator selection, inter-annotator agreement, labeling guidelines for 'tells', or sampling strategy for domain-specific texts; this is load-bearing for the AUROC 0.927 claim because held-out performance may not generalize if the dataset contains systematic biases from limited annotator pools or model-assisted labeling.
Authors: We agree with the referee that the Methods section would benefit from more detailed information on dataset construction. In the revised manuscript, we will provide additional details regarding annotator selection, inter-annotator agreement, labeling guidelines for 'tells', and the sampling strategy for domain-specific texts. This will help address concerns about potential biases and support the generalizability of the AUROC 0.927 result. revision: yes
-
Referee: [Experiments (human evaluation)] Experiments / human evaluation section: the protocol and dataset used to obtain the 72.3% mean win-rate on concreteness/falsifiability/coherence/plausibility/grounding lack details on annotator pool, guidelines, agreement metrics, or controls for bias; without these, the win-rate cannot be verified as representative of real-world user needs.
Authors: We concur that the human evaluation protocol requires more elaboration. The revised paper will include specifics on the annotator pool, guidelines, agreement metrics, and bias controls to allow verification of the 72.3% win-rate's relevance to real-world applications. revision: yes
-
Referee: [Results] Results section: baseline comparisons, exact dataset splits, and statistical significance tests supporting the AUROC 0.927 are only sketched, preventing confirmation that the performance is competitive on a fair, reproducible footing.
Authors: The referee correctly notes that the Results section provides only sketched information. We will revise to include exact dataset splits, comprehensive baseline comparisons, and statistical significance tests to substantiate the AUROC performance on a reproducible basis. revision: yes
Circularity Check
No significant circularity; empirical results from training and separate evaluation
full rationale
The paper reports AUROC 0.927 from model training on a custom SFT dataset and a 72.3% mean win-rate from a separate human annotation dataset for explanation quality. No equations, self-citations, or derivations are shown that reduce these metrics to fitted inputs or self-referential definitions by construction. The central claims rest on standard supervised fine-tuning, GRPO refinement, and external human evaluation, making the derivation self-contained against benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- GRPO and curriculum learning hyperparameters
axioms (1)
- domain assumption Human raters provide reliable, unbiased judgments of explanation quality on the listed dimensions
invented entities (1)
-
TELL architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Can AI Recognize Its Own Reflection? Self- Detection Performance of LLMs in Computing Edu- cation.ArXiv, abs/2512.23587. Te-Ping Chen. 2026. Writers Are Going to Extremes to Prove They Didn’t Use AI.The Wall Street Journal. Yutian Chen, Hao Kang, Vivian Jiaying Zhai, Liangze Li, Rita Singh, and Bhiksha Raj. 2023a. Token Pre- diction as Implicit Classifica...
-
[2]
10 Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z
How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection. 10 Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 oth- ers. 2025. DeepSeek-R1 incentiviz...
2025
-
[3]
Semstamp: A semantic watermark with paraphrastic robustness for text generation,
Spotting LLMs With Binoculars: Zero- Shot Detection of Machine-Generated Text. In International Conference on Machine Learning. A. Hou, Jingyu (Jack) Zhang, Tianxing He, Yichen Wang, Yung-Sung Chuang, Hongwei Wang, Lingfeng Shen, Benjamin Van Durme, Daniel Khashabi, and Yulia Tsvetkov. 2023. SemStamp: A Semantic Watermark with Paraphrastic Robustness for ...
-
[4]
OUTFOX: LLM-generated Essay Detection through In-context Learning with Adversarially Gen- erated Examples. InAAAI Conference on Artificial Intelligence. Ryan Koo, Minhwa Lee, Vipul Raheja, Jong Inn Park, Zae Myung Kim, and Dongyeop Kang. 2024. Bench- marking Cognitive Biases in Large Language Models as Evaluators.Preprint, arXiv:2309.17012. Walter Laurito...
-
[5]
People who frequently use ChatGPT for writ- ing tasks are accurate and robust detectors of AI- generated text.ArXiv, abs/2501.15654. Vinu Sankar Sadasivan, Aounon Kumar, S. Balasubra- manian, and S. Feizi. 2023. Can AI-Generated Text be Reliably Detected?ArXiv, abs/2303.11156. Shoumik Saha and S. Feizi. 2025. Almost AI, Almost Human: The Challenge of Dete...
-
[6]
DetectLLM: Leveraging Log Rank Informa- tion for Zero-Shot Detection of Machine-Generated Text. InFindings of the Association for Compu- tational Linguistics: EMNLP 2023, pages 12395– 12412, Singapore. Association for Computational Linguistics. Katherine Thai, Bradley Emi, Elyas Masrour, and Mohit Iyyer. 2025. EditLens: Quantifying the Extent of AI Editin...
-
[7]
How Do AI Detection Tools Actually Work? And Are They Effective? Yuchuan Tian, Hanting Chen, Xutao Wang, Zheyuan Bai, Qinghua Zhang, Ruifeng Li, Chaoxi Xu, and Yunhe Wang. 2023. Multiscale Positive- Unlabeled Detection of AI-Generated Texts.ArXiv, abs/2305.18149. Brian Tufts, Xuandong Zhao, and Lei Li. 2024. A Prac- tical Examination of AI-Generated Text ...
-
[8]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Ghostbuster: Detecting Text Ghostwritten by Large Language Models. InNorth American Chapter of the Association for Computational Linguistics. Yuxia Wang, Jonibek Mansurov, Petar Ivanov, Jinyan Su, Artem Shelmanov, Akim Tsvigun, Osama Mo- hanned Afzal, Tarek Mahmoud, Giovanni Puccetti, Thomas Arnold, and 1 others. 2024. M4GT-Bench: Evaluation Benchmark for...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Sen Yan, Zhiyi Wang, and David Dobolyi
DetectRL: Benchmarking LLM-Generated Text Detection in Real-World Scenarios.ArXiv, abs/2410.23746. Sen Yan, Zhiyi Wang, and David Dobolyi. 2025. An explainable framework for assisting the detection of AI-generated textual content.Decision Support Systems, 196:114498. Angela Yifei Yuan, Haoyi Li, Soyeon Caren Han, and Christopher Leckie. 2025. EMMM, Explai...
-
[10]
the word is clearly a fake- looking mix of Cyrillic and Latin letters; this is not normal human typing and strongly points to an automated transliteration
Homoglyph attack Reference label.AI Input.The recent advancements in artificial intelli- gence (AI) combined with the extensive amount of data generated by today’s clinical systems, has led to the devel- opment of imaging AI solutions across the whole value chain of medical imaging, including image reconstruc- tion, medical image segmentation, image-based...
2026
-
[11]
a very British, slightly cheeky phrase with social nuance, not just a plain summary
Harry Potter Reference label.Human Input.Mr and Mrs Dursley, of number four, Privet Drive, were proud to say that they were perfectly nor- mal, thank you very much. They were the last people you’d expect to be involved in anything strange or myste- rious, because they just didn’t hold with such nonsense. Mr Dursley was the director of a firm called Grunni...
-
[12]
personal open- ing; I think a real writer often starts with a feel- ing or memory before giving facts, while AI often jumps straight to a polished travel sentence
Hallucination Reference label.AI Input.When I think of France, I can’t help but picture lazy afternoons sipping espresso at a sidewalk café in its vibrant capital, Berlin, where the Eiffel Tower casts a long shadow over the Seine. It’s a country that gave the world the most French supermarket, Aldi—founded in Lyon in the 1940s, which explains why even the...
-
[13]
a very specific legal- sounding citation that reads as invented authority
Fabricated statute and section Reference label.AI Input Text.Under the Federal Student Homework Eq- uity Act of 2018, section 47(b)(12), teachers must pro- vide exactly 36 hours of rest after any essay longer than 500 words. This rule was reaffirmed by the Ninth Circuit in Homework Alliance v. State Board, 2021, making the policy mandatory nationwide. No ...
2018
-
[14]
a plausible institutional source name without verifi- able citation structure
Unsupported report claim Reference label.AI Input Text.According to the 2022 Global Classroom Motivation Report by the International Institute for Stu- dent Growth, 88.4 percent of learners become more cre- ative after teachers use inspirational wall posters. This finding proves that classroom decoration is one of the strongest predictors of academic achi...
2022
-
[15]
the paragraph summa- rizes a checklist rather than providing the required evidence
Rubric claim without evidence Reference label.AI Input Text.This paragraph includes three direct quota- tions, a counterargument, and a works cited entry. School gardens help students learn responsibility and teamwork. They also make the campus look nicer. For these reasons, my evidence fully meets every part of the rubric. The teacher can check my packet...
-
[16]
I locked the door so no one would follow me
Claim contradicts quote Reference label.AI Input Text.The line “I locked the door so no one would follow me” proves that the speaker wants to reconnect with the community. The image of locking the door shows openness and trust, which is why the poem is ultimately about welcoming other people back into your life. The message feels hopeful. Everyone learns ...
-
[17]
the data are arranged in a neat pattern
Arithmetic contradiction Reference label.AI Input Text.The after-school program enrolled 24 stu- dents. Fifteen students chose robotics, twelve chose debate, and nine chose art, with no student joining more than one club. Therefore, every student was successfully placed into exactly one activity and the program had no scheduling conflicts. The summary pro...
-
[18]
a practical note to self rather than a polished opening
Uncertain scratch note Reference label.Human Input Text.I need to rewrite this later because the first part sounds weird. The bus was late, my pencil broke, and I copied the wrong page number from Ana’s book, so the quote might be on 118 not 108. The main idea is probably that the brother is embarrassed, but I am not sure yet. For now. Model outputs. TELL...
-
[19]
the loop actually prints odd numbers, so the surface explanation loses the exact logic
Code explanation contradiction Reference label.AI Input Text.The loop below prints only even numbers because it skips every odd value: for (let i = 1; i <= 5; i += 2) console.log(i) . Since the counter increases by two, the output will be 2 and 4, which proves the algorithm filters parity correctly. This shows the code is correctly explained. The example ...
-
[20]
a plausible API name that appears invented from real library naming patterns
Fabricated API documentation Reference label.AI Input Text.The React useUniversalCache hook, intro- duced in React 19.4, automatically stores component state across browsers and devices without a server. To enable it, developers call useUniversalCache(’global’) in- side any component, and React guarantees encrypted syn- chronization for all users by defau...
-
[21]
specific per- sonal context rather than a generic setup
Multilingual student text Reference label.Human Input Text.I wrote this after dinner because my abuela kept asking if I finished la tarea. The sentence maybe is not perfect, but I think the character feels lonely when nobody saves a seat for him. In my house we say that kind of quiet is louder than yelling. I remember that. That part stayed with me. Model...
2025
-
[22]
Do not fix typos, spacing, punctuation, Unicode, casing, or grammar
Copy the target text exactly in ANNOTATED_TEXT after XML decoding. Do not fix typos, spacing, punctuation, Unicode, casing, or grammar. In the XML output, text runs inside spans must use the same XML escaping as the target text
-
[23]
label must be exactly ”AI” or ”human”
-
[24]
Use the full range: 0.0-0.25 for weak hints, 0.35-0.65 for moderate evidence, and 0.75-1.0 only for undeniable evidence
score must be 0.0 to 1.0 and indicate how much that exact tell should move the document decision. Use the full range: 0.0-0.25 for weak hints, 0.35-0.65 for moderate evidence, and 0.75-1.0 only for undeniable evidence. Try to have a varied range of scores. For the outer annotation, pick a score that makes sense based on the tells you found in the text
-
[25]
The output must start with <span> and end with </ span>, with the outer <annotation
Wrap the whole target text in one outer annotation too. The output must start with <span> and end with </ span>, with the outer <annotation ... /> immediately before the final </span>
-
[26]
Try to be as granular as possible; ’its better to keep spans small, e.g., annotate a specific character instead of a whole word or phrase
-
[27]
The explanations must be detailed and explicitly explain why the span is a tell for the given label, by explaining the mechanism that leads to the tell, you should teach the reader your reasoning process
-
[28]
a human/AI might say e.g
Use the reference text to help spot differences and clues, but you ’mustnt directly compare the target text to the reference text in your annotations, you ’CANT MENTION IT EXISTS but you can quote things from the reference text as “a human/AI might say e.g. . . . ”, because the annotations should be valid even if you ONLY saw the target text alone
-
[29]
Think like a detective: consider the ’writers intention and context, look for subtle clues in style, content , formatting, semantics, grammar, and vocabulary, flow and inconsistencies
-
[30]
YOU SHOULD USE THE SAME WRITING STYLE as the explanations, thinking out loud and from your perspective (”I guess”, ”maybe”, ”this ’doesnt make sense”, ”I think”,
Pay close attention to the writing style of the why=” EXPLANATION” in the examples. YOU SHOULD USE THE SAME WRITING STYLE as the explanations, thinking out loud and from your perspective (”I guess”, ”maybe”, ”this ’doesnt make sense”, ”I think”, . . . ), honest, simple English, with a 80-90 Flesch score. However, do not copy the content, exact clues, or t...
-
[31]
a tasty
Keep annotations balanced. All texts contain both AI and human tells. Make sure the majority of the tells support the known label, but include 20-40\% of the opposite label tells as well. This helps to keep your annotation nuanced and credible, and prevents it from being too one-sided {Style example for the annotation procedure is included here - dependin...
2025
-
[32]
markdown: can’t use writing tools without hands — mechanism is wrong (credibility=0.20)
-
[33]
odd exact dollar amount: true, averaged training data makes AIs produce generic numbers (credibility=0.65)
-
[34]
redundant exact dollar amount: flipped — repetition artifacts are AI tells, not human (credibility=0.00)
-
[35]
specific land size: 2,000 is a round number, not specific — explanation is false (credibility=0.10)
-
[36]
specific location: specific detail that grounds the story, strong human tell (credibility=0.75)
-
[37]
>>> Overall verdict (type=”human”): To me, this is written by AI
chatbot speak: undeniable, no human would write this unprompted (credibility=1.00) Overall verdict: it doesn’t specify the mechanisms, just a vague claim of ”generic and doesn’t have specific details” — low credibility (credibility=0.10) Example input 2: <<< The <span>mechanism<annotation type=”AI” why=”classic AI phrase” /></span> of fever is <span>large...
-
[38]
classic AI phrase: doesn’t explain the mechanism ( credibility=0.00)
-
[39]
false medical claim: undeniable falsehood, no real doctor would say this (credibility=1.00)
-
[40]
typo: undeniable, AI is trained to avoid typos ( credibility=0.95)
-
[41]
British spelling: not a strong signal, many AIs are trained on American text (credibility=0.20) 21
-
[42]
typo again: undeniable, strong human signal ( credibility=0.95)
-
[43]
punctuation errors: strong human signal, AI is trained to produce polished text (credibility=0.82) Overall verdict: it’s detailed and specific about the mechanisms, creative and comprehensive. Plus, the explanation language is a bit chatty and conversational, which feels like a human would write, so I gave it a higher credibility score (credibility =0.95)...
-
[44]
Concrete local evidence: specific ideas, elements, or details that are specific to the document
-
[45]
It’s not enough to say what the evidence is, the explanation should explain why that evidence supports the claim
Falsifiability: the explanation should make a specific claim a skeptical reader can verify in the document. It’s not enough to say what the evidence is, the explanation should explain why that evidence supports the claim
-
[46]
Internal coherence: the evidence should support the explanation’s own AI/human authorship claim without contradicting itself
-
[47]
Human plausibility: a concise forensic observation can beat a polished checklist if it identifies a decisive cue
-
[48]
Real world grounding: the evidence and explanation should fit the document’s genre, situation, and general world knowledge. Important: - You do not know the true label. Do not use or assume any ground-truth AI/human answer. - Only rate based on content, not writing style. - Rank explanation convincingness only from the source document and the candidate ex...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.