Beyond Encoder Accumulation: Measuring Encoder Roles in Multi-Encoder VLMs
Pith reviewed 2026-06-28 11:06 UTC · model grok-4.3
The pith
Retraining all subsets of five vision encoders reveals that pairing a high-capacity anchor with an adaptive complement matches full-model performance while the two highest solo performers do not.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
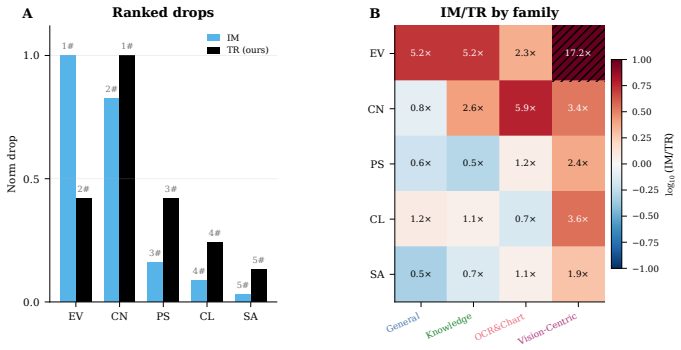
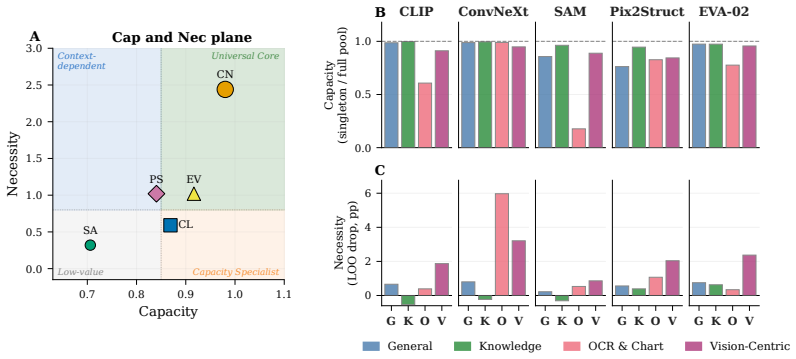
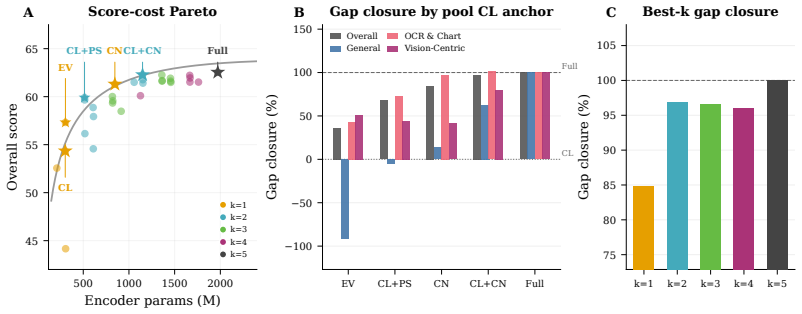
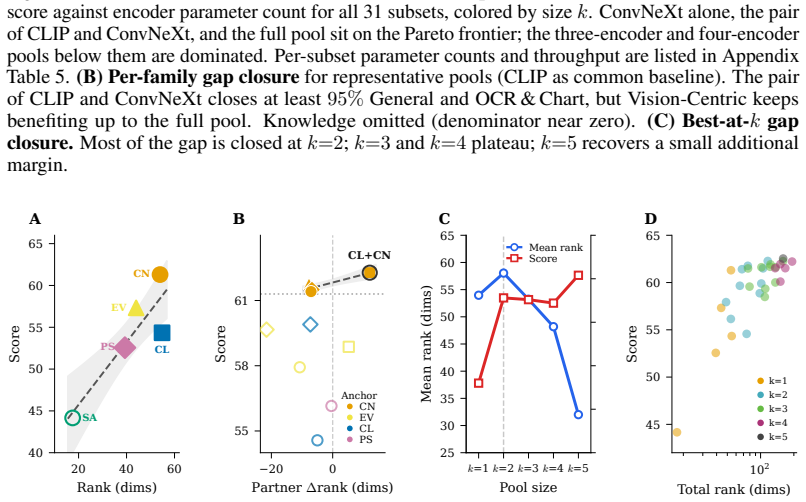
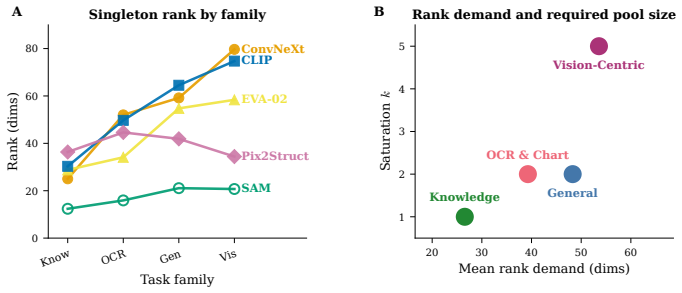
By retraining all 31 subsets from scratch, the authors establish that encoder contributions separate along two non-interchangeable axes: Capacity, the performance an encoder achieves on its own, and Necessity, the performance loss when that encoder is removed from the full set. Pairing the two encoders with highest Capacity is suboptimal. In contrast, pairing a high-Capacity anchor with an adaptive complement reaches the performance of the full five-encoder model. Adding encoders beyond this pair produces only marginal gains. At fixed parameter budgets, per-encoder pre-projector effective rank accounts for remaining score variation, with the strongest pairs being those in which the anchor ma
What carries the argument
The Capacity-Necessity decomposition, which separates an encoder's standalone score from its marginal contribution when removed from the joint pool, together with pre-projector effective rank measured at fixed parameter count.
If this is right
- Encoder selection for multi-encoder VLMs should favor complementary adaptation under joint training rather than ranking by solo performance.
- Performance saturates after the best anchor-complement pair, so adding more encoders yields diminishing returns.
- Pre-projector effective rank at fixed parameter count serves as an observable predictor of which pairs will perform well.
- Masking-based rankings on a fixed checkpoint do not reliably predict retrained subset rankings.
Where Pith is reading between the lines
- The same retraining protocol could be used to compare encoder pools drawn from different pre-training regimes without assuming the current five-encoder set is optimal.
- If pre-projector rank is the operative mechanism, then architectural changes that preserve rank at the encoder-projector interface might substitute for adding more encoders.
- The Capacity-Necessity split offers a concrete way to decide when to stop scaling the number of encoders in future foundation-model designs.
Load-bearing premise
That the encoder rankings and contribution measures obtained by retraining every subset from scratch in one unified pipeline on Cambrian-1 generalize beyond the specific training recipe, data mixture, and hyperparameters of the experiment.
What would settle it
Retraining the identical encoder subsets on a different benchmark suite or with an altered training recipe and finding that the Capacity-Necessity ordering and the identity of the optimal pair both change.
Figures

read the original abstract
As foundation models scale toward fusing more heterogeneous visual streams, understanding how diverse encoders interact under joint training becomes a prerequisite for principled design. Yet large vision-language models (LVLMs) currently lack the tools to do so, and parameter-efficient encoder configurations remain hard to identify before training. To re-examine encoder roles under joint training, on the 16-benchmark Cambrian-1 suite we retrain and evaluate all 31 non-empty subsets of five common vision encoders under a unified pipeline (~20k GPU-hours total), and report three findings. First, retraining each subset from scratch reveals encoder rankings that differ from those obtained by masking encoders on a fixed checkpoint, including which encoder ranks first overall. Second, we decompose each encoder's contribution into two axes, Capacity, the score an encoder reaches on its own, and Necessity, the drop when it is removed from the full pool. The two axes are not interchangeable. Pairing the two highest-Capacity encoders is suboptimal, while pairing a high-Capacity anchor with an adaptive complement matches the full five-encoder model. Adding further encoders beyond this pair yields only marginal gains. Third, at fixed parameter count, per-encoder pre-projector effective rank explains the residual score variation. The strongest pairs combine an anchor whose rank survives joint training with a complement whose rank expands under it, suggesting that higher-rank, less-collapsed projector inputs correspond to a more favorable optimization regime at the encoder-projector interface. Together, the Capacity-Necessity decomposition and the pre-projector rank analysis, along with comprehensive evaluation through retraining, expose a methodological gap in multi-encoder LVLM design, and offer concrete primitives for closing it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper retrains all 31 non-empty subsets of five common vision encoders from scratch inside a single unified VLM pipeline on the 16-benchmark Cambrian-1 suite (~20k GPU-hours), reporting that (i) subset rankings differ from those obtained by masking on a fixed checkpoint, (ii) encoder contributions decompose into two non-interchangeable axes—Capacity (solo performance) and Necessity (performance drop when removed from the full pool)—such that pairing the two highest-Capacity encoders is suboptimal while a high-Capacity anchor paired with an adaptive complement matches the five-encoder model and further encoders add only marginal gains, and (iii) at fixed parameter count, per-encoder pre-projector effective rank explains residual score variation, with strongest pairs combining an anchor whose rank survives joint training and a complement whose rank expands under it.
Significance. If the empirical patterns hold, the work supplies concrete primitives (Capacity-Necessity decomposition and pre-projector rank analysis) for principled multi-encoder VLM design and documents a methodological gap between masking-based and retraining-based evaluation; the large-scale, exhaustive subset retraining and the explicit non-interchangeability result are strengths that would be cited if replicated.
major comments (2)
- [Abstract / §4] Abstract and §4 (results on pairings): the central claim that a high-Capacity anchor plus adaptive complement matches the five-encoder model while two highest-Capacity encoders are suboptimal rests entirely on retraining inside one fixed pipeline (optimizer, data mixture, hyperparameters). No ablation varies these factors, so the reported ranking differences, axis non-interchangeability, and marginal-gains observation could be artifacts of that specific optimization regime rather than intrinsic encoder properties.
- [Abstract] Abstract: the statement that 'per-encoder pre-projector effective rank explains the residual score variation' at fixed parameter count is load-bearing for the third finding, yet the manuscript supplies neither the precise definition of effective rank nor any statistical test or confidence interval on the reported correlation.
minor comments (2)
- [Abstract] The abstract refers to the '16-benchmark Cambrian-1 suite' without listing the benchmarks or citing the original Cambrian-1 paper; a table or reference in §2 would improve reproducibility.
- [§3] Notation for Capacity and Necessity is introduced in the abstract but never given an explicit equation; adding a short definitional equation in §3 would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, acknowledging where the manuscript requires clarification or additional discussion of limitations.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (results on pairings): the central claim that a high-Capacity anchor plus adaptive complement matches the five-encoder model while two highest-Capacity encoders are suboptimal rests entirely on retraining inside one fixed pipeline (optimizer, data mixture, hyperparameters). No ablation varies these factors, so the reported ranking differences, axis non-interchangeability, and marginal-gains observation could be artifacts of that specific optimization regime rather than intrinsic encoder properties.
Authors: We agree that all experiments were performed inside one fixed training pipeline. This choice was deliberate to hold optimizer, data mixture, and hyperparameters constant while varying only the encoder subsets, thereby isolating the effects of encoder combinations. However, we acknowledge that the observed Capacity-Necessity decomposition, non-interchangeability of axes, and marginal gains could be specific to this regime. In revision we will add an explicit limitations paragraph in the conclusions noting this scope and recommending future validation across alternative pipelines. This is a partial revision consisting of added discussion rather than new experiments. revision: partial
-
Referee: [Abstract] Abstract: the statement that 'per-encoder pre-projector effective rank explains the residual score variation' at fixed parameter count is load-bearing for the third finding, yet the manuscript supplies neither the precise definition of effective rank nor any statistical test or confidence interval on the reported correlation.
Authors: We apologize for the missing details. Effective rank is defined as the number of singular values of the per-encoder pre-projector feature matrix that exceed 1% of the largest singular value. We will insert the exact definition, computation procedure, and the Pearson correlation with its 95% confidence interval and p-value into §4 and the abstract in the revised manuscript. This constitutes a full revision to address the omission. revision: yes
Circularity Check
No circularity: empirical ablation with explicit retraining of all subsets
full rationale
The paper's central claims derive from retraining all 31 non-empty subsets of five encoders from scratch under one unified pipeline on Cambrian-1, then measuring solo performance (Capacity) and removal drop (Necessity) directly on the resulting checkpoints. These quantities are computed outputs of the experiments rather than inputs that are fitted and then renamed as predictions. No equations, ansatzes, or uniqueness theorems are invoked; the Capacity-Necessity decomposition and pre-projector rank analysis are post-hoc descriptions of the observed scores. No self-citations appear as load-bearing premises. The study is therefore self-contained against its own experimental protocol, yielding a normal non-finding of circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Cambrian-1 16-benchmark suite and the single unified training pipeline produce comparable and unbiased performance numbers across all 31 encoder subsets.
invented entities (2)
-
Capacity
no independent evidence
-
Necessity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mahmoud Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, et al. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
MoVE-KD: Knowledge distillation for VLMs with mixture of visual encoders
Jiajun Cao, Yuan Zhang, Tao Huang, Ming Lu, Qizhe Zhang, Ruichuan An, Ningning Ma, and Shanghang Zhang. MoVE-KD: Knowledge distillation for VLMs with mixture of visual encoders. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
-
[3]
Batch normalization provably avoids rank collapse for randomly initialised deep networks
Hadi Daneshmand, Jonas Kohler, Francis Bach, Thomas Hofmann, and Aurelien Lucchi. Batch normalization provably avoids rank collapse for randomly initialised deep networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[4]
MouSi: Poly-visual-expert vision-language models, 2024
Xiaoran Fan, Tao Ji, Changhao Jiang, Shuo Li, Senjie Jin, Sirui Song, Junke Wang, Boyang Hong, Lu Chen, Guodong Zheng, et al. MouSi: Poly-visual-expert vision-language models, 2024
2024
-
[5]
EV A-02: A visual representation for neon genesis.Image and Vision Computing, 149:105171, 2024
Yuxin Fang, Quan Sun, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. EV A-02: A visual representation for neon genesis.Image and Vision Computing, 149:105171, 2024. arXiv:2303.11331
-
[6]
Rank diminishing in deep neural networks
Ruili Feng, Kecheng Zheng, Yukun Huang, Deli Zhao, Michael Jordan, and Zheng-Jun Zha. Rank diminishing in deep neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[7]
How to use and interpret activation patching, 2024
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching, 2024
2024
-
[8]
Radiov2.5: Improved baselines for agglomerative vision foundation models, 2025
Greg Heinrich, Mike Ranzinger, Hongxu, Yin, Yao Lu, Jan Kautz, Andrew Tao, Bryan Catan- zaro, and Pavlo Molchanov. Radiov2.5: Improved baselines for agglomerative vision foundation models, 2025. URLhttps://arxiv.org/abs/2412.07679
-
[9]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis. InInternational Conference on Machine Learning (ICML), 2024. arXiv:2405.07987
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
From CLIP to DINO: Visual encoders shout in multi-modal large language models, 2024
Dongsheng Jiang, Yuchen Liu, Songlin Liu, Jin’e Zhao, Hao Zhang, Zhen Gao, Xiaopeng Zhang, Jin Li, and Hongkai Xiong. From CLIP to DINO: Visual encoders shout in multi-modal large language models, 2024
2024
-
[11]
Muon: An optimizer for hidden layers in neural networks
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks. https://kell erjordan.github.io/posts/muon/, 2024
2024
-
[12]
BRA VE: Broadening the visual encoding of vision-language models
O˘guzhan Fatih Kar, Alessio Tonioni, Petra Poklukar, Achin Kulshrestha, Amir Zamir, and Federico Tombari. BRA VE: Broadening the visual encoding of vision-language models. In European Conference on Computer Vision (ECCV), 2024. Oral; arXiv:2404.07204
-
[13]
Prismatic vlms: Investigating the design space of visually-conditioned language models, 2024
Siddharth Karamcheti, Suraj Nair, Ashwin Balakrishna, Percy Liang, Thomas Kollar, and Dorsa Sadigh. Prismatic VLMs: Investigating the design space of visually-conditioned language models. InInternational Conference on Machine Learning (ICML), 2024. arXiv:2402.07865
-
[14]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. InIEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, 2023
2023
-
[16]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning (ICML),
-
[17]
MoAI: Mixture of all intelligence for large language and vision models
Byung-Kwan Lee, Beomchan Park, Chae Won Kim, and Yong Man Ro. MoAI: Mixture of all intelligence for large language and vision models. InEuropean Conference on Computer Vision (ECCV), 2024. arXiv:2403.07508. 11
-
[18]
Pix2Struct: screenshot parsing as pretraining for visual language understanding
Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. Pix2Struct: Screenshot parsing as pretraining for visual language understanding. InInternational Conference on Machine Learning (ICML), 2023. arXiv:2210.03347
-
[19]
Mini-Gemini: Mining the potential of multi-modality vision language models, 2024
Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-Gemini: Mining the potential of multi-modality vision language models, 2024
2024
-
[20]
Sphinx: A mixer of weights, visual embeddings and image scales for multi- modal large language models
Ziyi Lin, Dongyang Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Wenqi Shao, Keqin Chen, Jiaming Han, Siyuan Huang, Yichi Zhang, Xuming He, Yu Qiao, and Hongsheng Li. Sphinx: A mixer of weights, visual embeddings and image scales for multi- modal large language models. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten ...
2024
-
[21]
ISBN 978-3-031-73033-7
Springer Nature Switzerland. ISBN 978-3-031-73033-7
-
[22]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[23]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, et al. Muon is scalable for LLM training.arXiv preprint arXiv:2502.16982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
A ConvNet for the 2020s
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A ConvNet for the 2020s. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11976–11986, 2022
2022
-
[25]
A Unified Approach to Interpreting Model Predictions
Scott M. Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems (NeurIPS), 2017. arXiv:1705.07874
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
arXiv preprint arXiv:2403.03003 , year=
Gen Luo, Yiyi Zhou, Yuxin Zhang, Xiawu Zheng, Xiaoshuai Sun, and Rongrong Ji. Feast your eyes: Mixture-of-resolution adaptation for multimodal large language models. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2403.03003
-
[27]
Cosmos World Foundation Model Platform for Physical AI
NVIDIA. Cosmos world foundation model platform for physical AI.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInterna- tional Conference on Machine Learning (ICML), pages 8748–8763, 2021
2021
-
[29]
AM-RADIO: Agglomerative vision foundation model – reduce all domains into one
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. AM-RADIO: Agglomerative vision foundation model – reduce all domains into one. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12490–12500, 2024. arXiv:2312.06709
-
[30]
The effective rank: A measure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. In European Signal Processing Conference (EUSIPCO), pages 606–610, 2007
2007
-
[31]
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, Yilin Zhao, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, Bryan Catanzaro, Andrew Tao, Jan Kautz, Zhiding Yu, and Guilin Liu. Eagle: Exploring the design space for multimodal LLMs with mixture of encoders. InInternational Conference on Learning Representations (IC...
-
[32]
Axiomatic Attribution for Deep Networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International Conference on Machine Learning (ICML), 2017. arXiv:1703.01365
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai C Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024
2024
-
[34]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: A circuit for indirect object identification in GPT-2 small. In International Conference on Learning Representations (ICLR), 2023. arXiv:2211.00593
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
HAWAII: Hierarchical visual knowledge transfer for efficient vision-language models
Yimu Wang, Mozhgan Nasr Azadani, Sean Sedwards, and Krzysztof Czarnecki. HAWAII: Hierarchical visual knowledge transfer for efficient vision-language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. arXiv:2506.19072. 12
-
[36]
Investigating redundancy in multimodal large language models with multiple vision encoders
Yizhou Wang, Song Mao, Yang Chen, Yufan Shen, Pinlong Cai, Ding Wang, Guohang Yan, Zhi Yu, Yinqiao Yan, Xuming Hu, and Botian Shi. Investigating redundancy in multimodal large language models with multiple vision encoders. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2507.03262
-
[37]
SCOPE: Selective cross-modal orchestration of visual perception experts, 2025
Tianyu Zhang, Suyuchen Wang, Chao Wang, Juan Rodriguez, Ahmed Masry, Xiangru Jian, Yoshua Bengio, and Perouz Taslakian. SCOPE: Selective cross-modal orchestration of visual perception experts, 2025
2025
-
[38]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-Bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023
2023
-
[39]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
MoV A: Adapting mixture of vision experts to multimodal context
Zhuofan Zong, Bingqi Ma, Dazhong Shen, Guanglu Song, Hao Shao, Dongzhi Jiang, Hongsheng Li, and Yu Liu. MoV A: Adapting mixture of vision experts to multimodal context. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2404.13046. 13 A Additional Results A.1 Detailed experimental setup Encoders.The five vision encoders in Eagle-X5...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.