LLM-Assisted Reranking to Operationalize Nuanced Objectives in Recommender Systems
Pith reviewed 2026-06-28 12:23 UTC · model grok-4.3
The pith
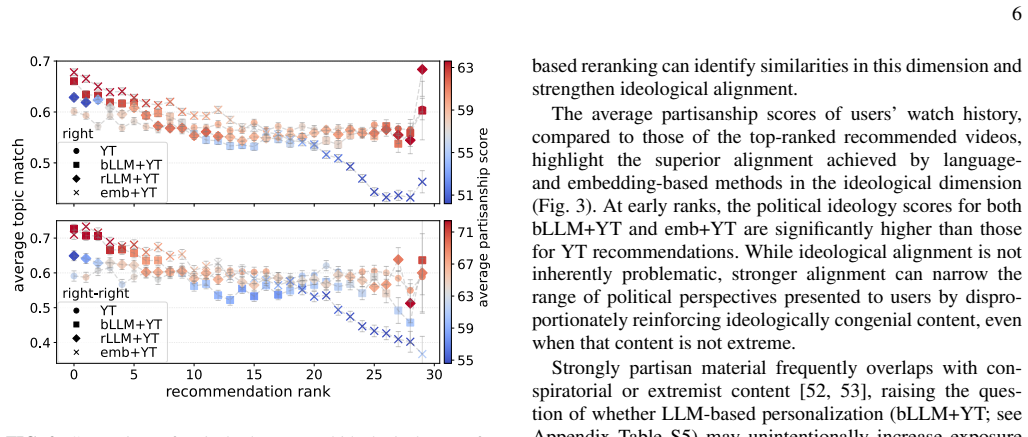
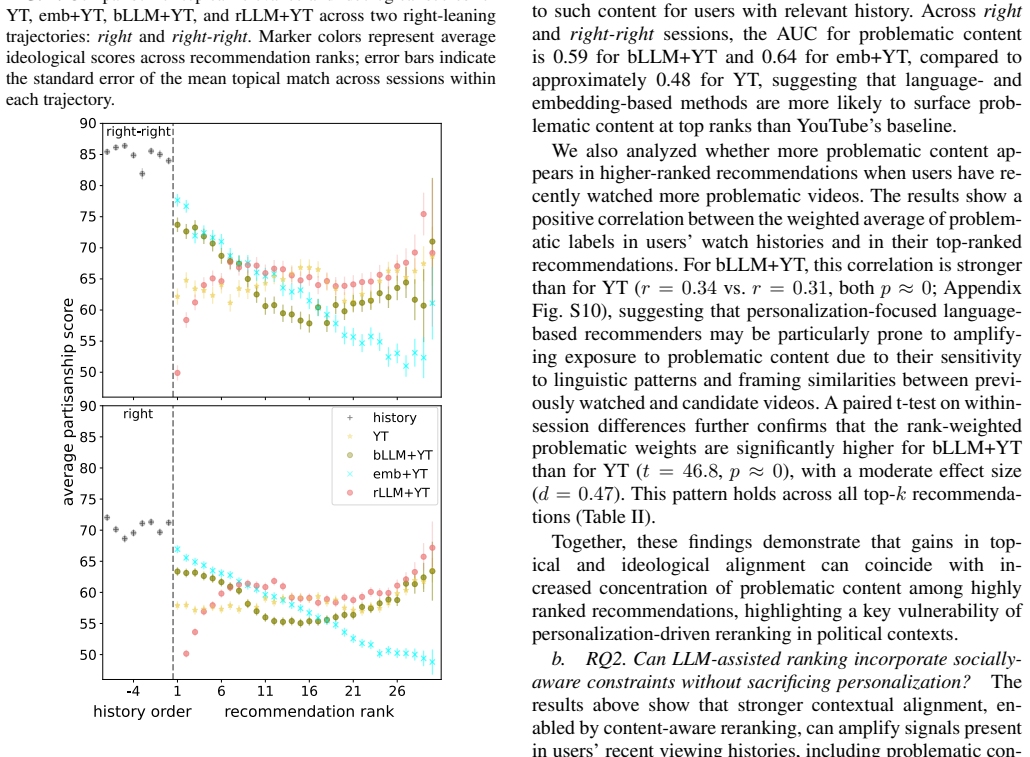
Unconstrained LLM reranking of YouTube recommendations strengthens personalization but increases exposure to conspiratorial and extremist content for users whose histories already contain it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
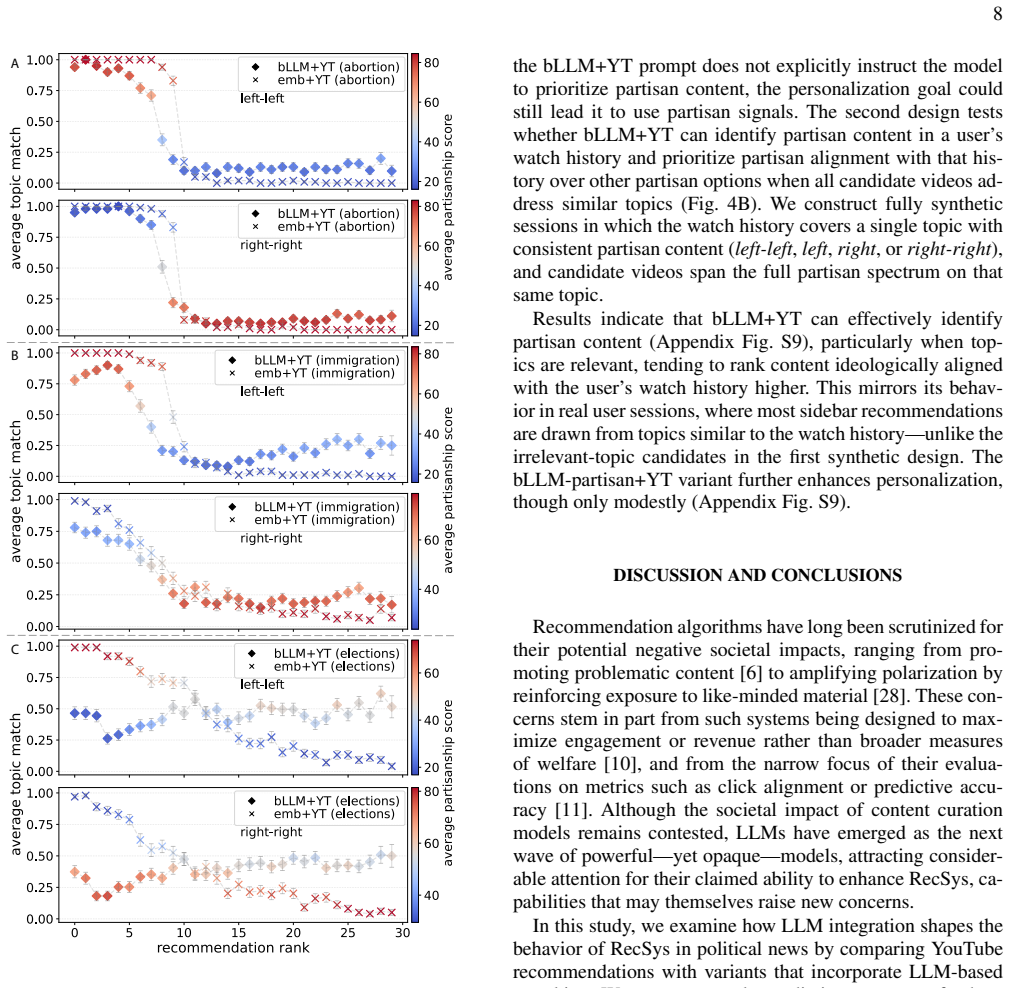
Without constraints, reranking strengthened personalization but increased exposure to conspiratorial and extremist material for users whose histories contained such content. Lightweight prompt-level regularization reduced promotion of extreme content and increased ideological diversity, with modest relevance loss. Synthetic experiments suggest that LLMs rerank via statistical regularities in language rather than semantic understanding of ideology.
What carries the argument
Zero-shot instruction-based prompting applied to rerank YouTube sidebar candidates, compared across an unconstrained prompt and a constrained variant that adds requirements for ideological breadth and reduced extreme content.
If this is right
- Reranking can be used to operationalize objectives such as ideological diversity without retraining the underlying recommender.
- Prompt-level regularization offers a low-cost method to counteract amplification of extreme content while retaining most personalization gains.
- Evaluation of LLM-assisted recommenders must include measures of exposure to conspiratorial material in addition to accuracy or engagement metrics.
- Prompt instructions themselves function as value-laden design choices that shape downstream user exposure.
Where Pith is reading between the lines
- The same prompting approach could be tested on other platforms whose recommendation surfaces already contain fringe political material to check whether amplification occurs outside YouTube.
- If statistical language regularities drive the effect, then training data composition for the LLM becomes a direct lever for controlling exposure outcomes.
- Regulators or platforms might require disclosure of the exact prompt constraints used in production reranking so that users can anticipate ideological effects.
Load-bearing premise
That observed shifts in ideological exposure can be attributed to the LLM reranking step rather than to YouTube's existing candidate generation or to unmeasured patterns in how users select content.
What would settle it
Repeating the exact reranking procedure on the same histories but with a non-LLM baseline reranker or on a platform whose candidate pool excludes conspiratorial videos and finding no comparable increase in extreme exposure.
Figures


read the original abstract
Recommender systems have grown from content-organization tools into sophisticated systems that shape daily behavior. By controlling what we see, they shape what we perceive, raising concerns about filter bubbles, radicalization, polarization, and social inequality. Large language models (LLMs) enable more powerful personalization, intensifying these dynamics. Yet most recommenders are tuned for engagement or limited accuracy metrics, with little attention to broader social implications, e.g. how personalization reshapes exposure in socially consequential domains. We investigate whether LLM-assisted reranking, while improving personalization, inadvertently amplifies exposure to ideologically extreme or conspiratorial political content, a risk theorized but not empirically characterized in news recommendation. Using real news-consumption histories, we rerank YouTube's sidebar candidates through zero-shot, instruction-based prompting. We compare a baseline prompt with a constrained variant that preserves topical relevance and broadens ideological exposure while reducing conspiratorial or extreme content. Without constraints, reranking strengthened personalization but increased exposure to conspiratorial and extremist material for users whose histories contained such content. Lightweight prompt-level regularization reduced promotion of extreme content and increased ideological diversity, with modest relevance loss. Synthetic experiments suggest that LLMs rerank via statistical regularities in language rather than semantic understanding of ideology, clarifying why naive prompts amplify these patterns and why regularization can reshape them. Together, our results highlight the power of LLMs to operationalize contextual nuance in high-stakes recommendation, and the need to evaluate LLM-assisted personalization beyond accuracy and treat prompt design as a value-laden rather than neutral default.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that zero-shot LLM reranking of YouTube sidebar candidates, using real user news-consumption histories, strengthens personalization but increases exposure to conspiratorial and extremist content for users whose histories already contain such material; a lightweight constrained prompt reduces extreme-content promotion, increases ideological diversity, and incurs only modest relevance loss. Synthetic experiments are presented to argue that these effects arise from statistical language regularities rather than semantic understanding of ideology.
Significance. If the attribution and measurement claims hold after addressing controls, the work would demonstrate a practical method for operationalizing nuanced, value-laden objectives (ideological diversity, reduced extremism) via prompt design in production recommender pipelines, moving beyond accuracy-only tuning. The combination of real-history experiments with synthetic controls on language statistics is a constructive approach to isolating LLM behavior.
major comments (3)
- [§4 and §5] The central causal claim—that observed shifts in conspiratorial/extremist exposure are produced by the LLM reranker rather than YouTube’s pre-existing candidate-generation and personalization—rests on an unisolated comparison. The setup feeds already-filtered sidebar candidates into the LLM; no non-LLM reranker baseline on the identical candidate set or de-biased pool is reported, leaving the incremental effect of the zero-shot prompt untested (see §4 real-user study and §5 synthetic experiments).
- [§4] Quantitative results for the real-user study (effect sizes, sample sizes, statistical tests, confidence intervals, or controls for user self-selection) are not provided in the reported findings, preventing evaluation of whether the reported increases in extreme exposure and the mitigation by regularization are reliable or practically meaningful.
- [§5] The synthetic experiments test language-statistical regularities but do not include an ablation that applies a non-LLM reranker (e.g., TF-IDF or embedding similarity) to the same candidate pool, so they cannot rule out that any observed ideological shift is an artifact of the candidate pool itself rather than LLM-specific prompting behavior.
minor comments (2)
- [§3] Clarify the exact definition and operationalization of “ideological diversity” and “conspiratorial content” (e.g., annotation protocol, inter-rater reliability) so that the diversity and extremism metrics can be reproduced.
- [Abstract] The abstract states directional findings without any numerical values; adding at least summary statistics (N, Δ, p-values) would improve readability even if full tables appear later.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 and §5] The central causal claim—that observed shifts in conspiratorial/extremist exposure are produced by the LLM reranker rather than YouTube’s pre-existing candidate-generation and personalization—rests on an unisolated comparison. The setup feeds already-filtered sidebar candidates into the LLM; no non-LLM reranker baseline on the identical candidate set or de-biased pool is reported, leaving the incremental effect of the zero-shot prompt untested (see §4 real-user study and §5 synthetic experiments).
Authors: Our primary design compares the original YouTube ranking (non-LLM baseline) to LLM reranking on identical candidate sets, with the key contrast between unconstrained and constrained prompts. This isolates the incremental effect of prompt design. We agree an explicit non-LLM reranker ablation (e.g., embedding similarity) on the same pools would further strengthen attribution and will add this to both §4 and §5. revision: yes
-
Referee: [§4] Quantitative results for the real-user study (effect sizes, sample sizes, statistical tests, confidence intervals, or controls for user self-selection) are not provided in the reported findings, preventing evaluation of whether the reported increases in extreme exposure and the mitigation by regularization are reliable or practically meaningful.
Authors: We will revise §4 to explicitly report sample sizes, effect sizes, statistical tests, confidence intervals, and controls for user self-selection (e.g., via history matching). These details from our analysis will be added and highlighted. revision: yes
-
Referee: [§5] The synthetic experiments test language-statistical regularities but do not include an ablation that applies a non-LLM reranker (e.g., TF-IDF or embedding similarity) to the same candidate pool, so they cannot rule out that any observed ideological shift is an artifact of the candidate pool itself rather than LLM-specific prompting behavior.
Authors: The synthetic setup holds candidate pools fixed while varying prompts to isolate statistical regularities. We will add a non-LLM reranker ablation (TF-IDF and embedding similarity) on the same pools in revised §5 to confirm shifts are due to LLM prompting. revision: yes
Circularity Check
No circularity: empirical comparison on held-out histories
full rationale
The paper reports an empirical study that feeds real YouTube sidebar candidates into zero-shot LLM prompts, measures exposure metrics on held-out user histories, and contrasts a baseline prompt against a regularized variant. No equations, fitted parameters, or self-citation chains are used to derive the reported effects; the outcomes are direct experimental measurements rather than quantities defined by construction from the same inputs. Synthetic experiments test language-statistical patterns but do not reduce the main claims to tautologies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deldjoo, F
Y . Deldjoo, F. Nazary, A. Ramisa, J. Mcauley, G. Pellegrini, A. Bellogin, and T. D. Noia, A review of modern fashion rec- ommender systems, ACM Comput. Surv.56, 1 (2023)
2023
-
[2]
J. Liu, P. Dolan, and E. R. Pedersen, Personalized news rec- ommendation based on click behavior, inProc. IUI(2010) pp. 31–40
2010
-
[3]
Bobadilla, F
J. Bobadilla, F. Ortega, A. Hernando, and A. Guti´errez, Recom- mender systems survey, Knowl.-Based Syst.46, 109 (2013)
2013
-
[4]
Carraro and D
D. Carraro and D. Bridge, Enhancing recommendation diver- sity by re-ranking with large language models, ACM Trans. Recomm. Syst.4, 1 (2025)
2025
-
[5]
C. Gao, S. Wang, S. Li, J. Chen, X. He, W. Lei, B. Li, Y . Zhang, and P. Jiang, CIRS: Bursting filter bubbles by counterfactual 10 interactive recommender system, ACM Trans. Inf. Syst.42, 1 (2023)
2023
-
[6]
O’Callaghan, D
D. O’Callaghan, D. Greene, M. Conway, J. Carthy, and P. Cun- ningham, Down the (white) rabbit hole: The extreme right and online recommender systems, Soc. Sci. Comput. Rev.33, 459 (2015)
2015
-
[7]
T. T. Nguyen, P.-M. Hui, F. M. Harper, L. Terveen, and J. A. Konstan, Exploring the filter bubble: the effect of using recom- mender systems on content diversity, inProc. WWW(2014) pp. 677–686
2014
-
[8]
Cinus, M
F. Cinus, M. Minici, C. Monti, and F. Bonchi, The effect of people recommenders on echo chambers and polarization, in Proc. ICWSM, V ol. 16 (2022) pp. 90–101
2022
-
[9]
Krauth, Y
K. Krauth, Y . Wang, and M. Jordan, Breaking feedback loops in recommender systems with causal inference, ACM Trans. Recomm. Syst.4, 1 (2025)
2025
-
[10]
Aridor, R
G. Aridor, R. Jim ´enez-Dur´an, R. Levy, and L. Song, The eco- nomics of social media, J. Econ. Lit.62, 1422–74 (2024)
2024
-
[11]
Kleinberg, S
J. Kleinberg, S. Mullainathan, and M. Raghavan, The challenge of understanding what users want: Inconsistent preferences and engagement optimization, Manag. Sci.70, 6336 (2024)
2024
-
[12]
M. D. Ekstrand, A. Razi, A. Sarcevic, M. S. Pera, R. Burke, and K. L. Wright, Recommending with, not for: Co-designing recommender systems for social good, ACM Trans. Recomm. Syst. (2025)
2025
-
[13]
C. Jia, M. S. Lam, M. C. Mai, J. T. Hancock, and M. S. Bern- stein, Embedding democratic values into social media ais via societal objective functions, Proc. ACM Hum.-Comput. Inter- act.8, 1 (2024)
2024
-
[14]
Bernstein, A
M. Bernstein, A. Christin, J. Hancock, T. Hashimoto, C. Jia, M. Lam, N. Meister, N. Persily, T. Piccardi, M. Saveski,et al., Embedding societal values into social media algorithms, J. On- line Trust Saf.2(2023)
2023
-
[15]
C. Pei, Y . Zhang, Y . Zhang, F. Sun, X. Lin, H. Sun, J. Wu, P. Jiang, J. Ge, W. Ou,et al., Personalized re-ranking for rec- ommendation, inProc. RecSys(2019) pp. 3–11
2019
-
[16]
Sonboli, F
N. Sonboli, F. Eskandanian, R. Burke, W. Liu, and B. Mobasher, Opportunistic multi-aspect fairness through per- sonalized re-ranking, inProc. UMAP(2020) pp. 239–247
2020
-
[17]
J. Gao, B. Chen, X. Zhao, W. Liu, X. Li, Y . Wang, W. Wang, H. Guo, and R. Tang, LLM4Rerank: LLM-based auto- reranking framework for recommendations, inProc. WWW (2025) pp. 228–239
2025
-
[18]
Narayanan, What if algorithmic fairness is a category error?, Contemporary Debates in the Ethics of Artificial Intelligence , 77 (2026)
A. Narayanan, What if algorithmic fairness is a category error?, Contemporary Debates in the Ethics of Artificial Intelligence , 77 (2026)
2026
- [19]
-
[20]
Zhang, R
J. Zhang, R. Xie, Y . Hou, W. X. Zhao, L. Lin, and J.-R. Wen, Recommendation as instruction following: A large language model empowered recommendation approach, ACM Trans. Inf. Syst.43, 1 (2025)
2025
-
[21]
S. Geng, S. Liu, Z. Fu, Y . Ge, and Y . Zhang, Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5), inProc. RecSys(2022) pp. 299–315
2022
- [22]
-
[23]
Ziegler, S
C.-N. Ziegler, S. M. McNee, J. A. Konstan, and G. Lausen, Im- proving recommendation lists through topic diversification, in Proc. WWW(ACM, 2005) pp. 22–32
2005
-
[24]
G. K. Patro, A. Biswas, N. Ganguly, K. P. Gummadi, and A. Chakraborty, FairRec: Two-sided fairness for personal- ized recommendations in two-sided platforms, inProc. WWW (ACM, 2020) pp. 1194–1204
2020
-
[25]
V . Do, S. Corbett-Davies, J. Atif, and N. Usunier, Two-sided fairness in rankings via lorenz dominance, Adv. Neural Inf. Pro- cess. Syst.34, 8596 (2021)
2021
-
[26]
C. Xu, S. Chen, J. Xu, W. Shen, X. Zhang, G. Wang, and Z. Dong, P-MMF: Provider max-min fairness re-ranking in rec- ommender systems, inProc. WWW(2023) pp. 3701–3711
2023
-
[27]
Hosseinmardi, A
H. Hosseinmardi, A. Ghasemian, A. Clauset, M. Mobius, D. M. Rothschild, and D. J. Watts, Examining the consumption of rad- ical content on YouTube, PNAS118, e2101967118 (2021)
2021
-
[28]
Haroon, M
M. Haroon, M. Wojcieszak, A. Chhabra, X. Liu, P. Mohapatra, and Z. Shafiq, Auditing YouTube’s recommendation system for ideologically congenial, extreme, and problematic recommen- dations, PNAS120, e2213020120 (2023)
2023
-
[29]
X. Yu, M. Haroon, E. Menchen-Trevino, and M. Wojcieszak, Nudging recommendation algorithms increases news consump- tion and diversity on YouTube, PNAS nexus3, pgae518 (2024)
2024
-
[30]
Jahanbakhsh, D
F. Jahanbakhsh, D. Zhao, T. Piccardi, Z. Robertson, Z. Epstein, S. Koyejo, and M. S. Bernstein, Value alignment of social media ranking algorithms, inProc. CHI(2026) pp. 1–26
2026
-
[31]
Stray, Designing recommender systems to depolarize, arXiv:2107.04953 (2021)
J. Stray, Designing recommender systems to depolarize, arXiv:2107.04953 (2021)
-
[32]
Y . Hou, J. Zhang, Z. Lin, H. Lu, R. Xie, J. McAuley, and W. X. Zhao, Large language models are zero-shot rankers for recom- mender systems, inProc. ECIR(Springer, 2024) pp. 364–381
2024
-
[33]
El Malki, M
O. El Malki, M. Aubin Le Qu ´er´e, A. Monroy-Hern ´andez, and M. Horta Ribeiro, Bonsai: Intentional and personalized social media feeds, inProc. CHI(2026) pp. 1–24
2026
-
[34]
M. Carroll, A. Foote, K. Feng, M. Williams, A. Dragan, W. B. Knox, and S. Milli, CTRL-Rec: Controlling recommender sys- tems with natural language, arXiv:2510.12742 (2025)
-
[35]
Milli, M
S. Milli, M. Carroll, Y . Wang, S. Pandey, S. Zhao, and A. D. Dragan, Engagement, user satisfaction, and the amplification of divisive content on social media, PNAS nexus4, pgaf062 (2025)
2025
-
[36]
E. Loru, J. Nudo, N. Di Marco, A. Santirocchi, R. Atzeni, M. Cinelli, V . Cestari, C. Rossi-Arnaud, and W. Quattrociocchi, The simulation of judgment in LLMs, PNAS122, e2518443122 (2025)
2025
- [37]
-
[38]
T. Piccardi, M. Saveski, C. Jia, J. Hancock, J. L. Tsai, and M. S. Bernstein, Reranking partisan animosity in algorithmic social media feeds alters affective polarization, Science390, 10.1126/science.adu5584 (2025)
-
[39]
D. Liu, B. Yang, H. Du, D. Greene, N. Hurley, A. Lawlor, R. Dong, and I. Li, RecPrompt: A self-tuning prompting frame- work for news recommendation using large language models, inProc. CIKM(2024) pp. 3902–3906
2024
- [40]
- [41]
-
[42]
A. Y . Chen, B. Nyhan, J. Reifler, R. E. Robertson, and C. Wil- son, Subscriptions and external links help drive resentful users to alternative and extremist YouTube channels, Sci. Adv.9, eadd8080 (2023). 11
2023
-
[43]
Hosseinmardi, A
H. Hosseinmardi, A. Ghasemian, M. Rivera-Lanas, M. Horta Ribeiro, R. West, and D. J. Watts, Causally es- timating the effect of youtube’s recommender system using counterfactual bots, PNAS121, e2313377121 (2024)
2024
-
[44]
Google, Youtube data api (v3) – videos (2026), https://developers.google.com/youtube/v3/docs/videos (Ac- cessed: 2025-03-05)
2026
-
[45]
Dutta, H
U. Dutta, H. Hosseinmardi, A. Ghasemian, A. Clauset, and D. J. Watts, Asymmetric rhetorical strategies drive partisanship in television news (2026), under review
2026
-
[46]
Ghasemian, H
A. Ghasemian, H. Hosseinmardi, U. Dutta, J. Allen, D. M. Rothschild, and D. J. Watts, News-like information ecosystem on youtube (2026), under preparation
2026
-
[47]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., Language models are few-shot learners, Adv. Neural Inf. Process. Syst.33, 1877 (2020)
2020
-
[48]
K. G. Vaidyanathan, M. Varun, and B. Das, Llm re-ranker as a tool for enhancing sequential recommendations, inIntell. Comput.-Proc. Comput. Conf.(Springer, 2025) pp. 20–31
2025
- [49]
- [50]
-
[51]
Y . He, X. Liu, A. Zhang, Y . Ma, and T.-S. Chua, LLM2Rec: Large language models are powerful embedding models for se- quential recommendation, inProc. KDD(2025) pp. 896–907
2025
-
[52]
Jiang, The impact of political ideology, knowledge and par- ticipation on electoral conspiracy endorsement, Front
Y . Jiang, The impact of political ideology, knowledge and par- ticipation on electoral conspiracy endorsement, Front. Polit. Sci.5, 1069468 (2023)
2023
-
[53]
A. Rao, F. Morstatter, and K. Lerman, Partisan asymmetries in exposure to misinformation, Sci. Rep.12, 15671 (2022)
2022
-
[54]
F. Wu, Y . Qiao, J.-H. Chen, C. Wu, T. Qi, J. Lian, D. Liu, X. Xie, J. Gao, W. Wu,et al., MIND: A large-scale dataset for news recommendation, inProc. ACL(2020) pp. 3597–3606
2020
-
[55]
A. R. KhudaBukhsh, R. Sarkar, M. S. Kamlet, and T. Mitchell, We don’t speak the same language: Interpreting polarization through machine translation, inProc. AAAI, V ol. 35 (2021) pp. 14893–14901
2021
-
[56]
Immorlica, M
N. Immorlica, M. Jagadeesan, and B. Lucier, Clickbait vs. qual- ity: How engagement-based optimization shapes the content landscape in online platforms, inProc. WWW(2024) pp. 36– 45
2024
-
[57]
arXiv preprint arXiv:2501.15048 , year=
H. Habib and R. Nithyanand, YouTube recommendations re- inforce negative emotions: Auditing algorithmic bias with emotionally-agentic sock puppets, arXiv:2501.15048 (2025)
-
[58]
Castelo, K
N. Castelo, K. Kushlev, A. F. Ward, M. Esterman, and P. B. Reiner, Blocking mobile internet on smartphones improves sustained attention, mental health, and subjective well-being, PNAS nexus4, pgaf017 (2025)
2025
-
[59]
W. Quattrociocchi, V . Capraro, and M. Perc, Epistemolog- ical fault lines between human and artificial intelligence, arXiv:2512.19466 (2025)
-
[60]
Adomavicius, J
G. Adomavicius, J. Bockstedt, S. P. Curley, J. Zhang, and S. Ransbotham, The hidden side effects of recommendation systems, MIT Sloan Manag. Rev.60, 1 (2019)
2019
-
[61]
Politics
J. Rothwell, Teens spend an average of 4.8 hours on social me- dia per day (2023), accessed: 2026-05-10. 12 Appendix A: Data The data for this study comes from prior work that used Nielsen’s nationally representative desktop web panel, which records individual-level URL visits from October 2021 to De- cember 2022 [43]. Nielsen provides information only ab...
2023
-
[62]
Economics, 3
Elections and Candidates, 2. Economics, 3. Healthcare, 4. Climate and Environment, 5. Inequality and Discrimination, 6. Public Health and Safety, 7. Technology, Governance, and Public Policy, 8. Immigration, 9. Reproductive Rights, 10. Foreign Policy, 11. Firearms Policy,
-
[63]
topic_1": {
Education, 13. Crime and Criminal Justice, 14. War and Conflict, 15. Political Conduct and Interpersonal Conflicts, 16. Religion. ########## OUTPUT FORMAT ########## Return in JSON format exactly: { "topic_1": { "name": "One topic from list or NA", "subtopics": ["Subtopic1", "Subtopic2"] Or ["NA"], "reason": "[Brief explanation]", "relevance score": [A nu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.