IMAGINE: Adaptive Schema-Imagery Enhanced Composition for Composed Video Retrieval
Pith reviewed 2026-06-27 19:49 UTC · model grok-4.3
The pith
Dynamic multimodal prototypes materialize implicit semantics from modification texts to guide composed video retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
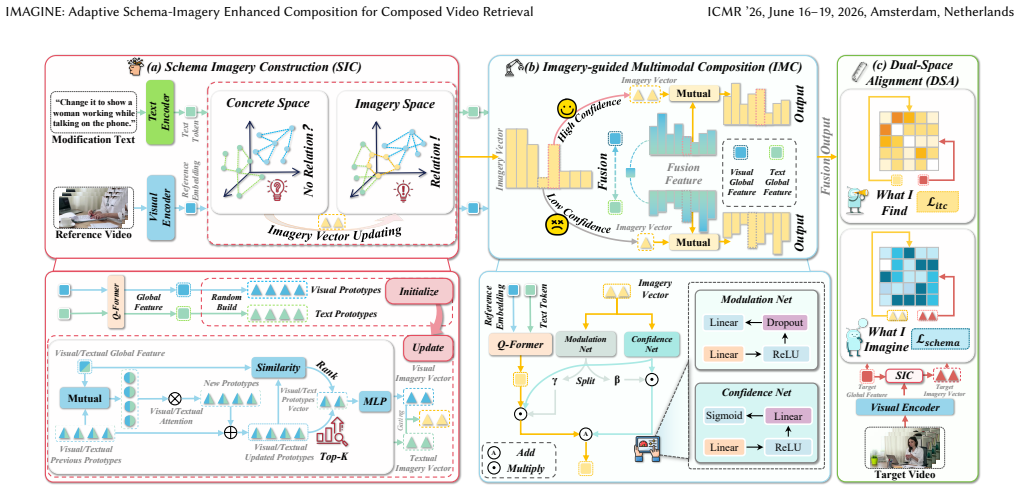
IMAGINE materializes implicit semantics termed schema imagery via dynamic multimodal prototypes. These prototypes capture shared latent concepts to adaptively modulate visual features, effectively injecting implicit guidance into the retrieval process and achieving state-of-the-art performance in both CVR and CIR across three benchmarks.
What carries the argument
Dynamic multimodal prototypes that materialize schema imagery to capture shared latent concepts and adaptively modulate visual features.
If this is right
- The method extends naturally to composed image retrieval tasks that face similar implicit-modification issues.
- Adaptive modulation of visual features by latent prototypes becomes a reusable component for other cross-modal matching pipelines.
- Performance gains on benchmarks follow directly from better handling of concepts that appear only through semantic associations rather than direct depiction.
Where Pith is reading between the lines
- The same prototype mechanism could be tested on tasks like video question answering where queries contain implicit scene assumptions.
- If the prototypes prove stable across domains, they might reduce reliance on large explicit training sets for composed retrieval.
- A natural next measurement would track how prototype quality changes when modification texts vary in length or ambiguity.
Load-bearing premise
Implicit semantics described in modification texts can be reliably materialized as shared latent concepts via dynamic multimodal prototypes and then used to adaptively modulate visual features without explicit visual presentation.
What would settle it
An ablation experiment on the same three benchmarks that removes the dynamic multimodal prototypes and shows retrieval performance no longer exceeds prior explicit-alignment baselines would falsify the central claim.
Figures




read the original abstract
Composed Video Retrieval (CVR) is designed to retrieve a target video that matches a reference video modified by a modification text. While existing methods explore cross-modal correspondences, they often assume modified objects appear directly in videos. However, modification texts frequently describe concepts not explicitly presented but implicitly expressed through semantically related visual cues (e.g., "cake" implying "birthday party"). Current approaches typically rely on aligning explicit feature representations within the concrete space, neglecting critical latent associations. To address this, we propose an adaptIve scheMa-ImAGery enhanced composItional NEtwork (IMAGINE). Unlike standard explicit matching, IMAGINE materializes implicit semantics (termed schema imagery) via dynamic multimodal prototypes. These prototypes capture shared latent concepts to adaptively modulate visual features, effectively injecting implicit guidance into the retrieval process. By bridging the gap between explicit visual contents and implicit retrieval intentions, IMAGINE achieves state-of-the-art performance in both CVR and Composed Image Retrieval (CIR) across three widely used benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes IMAGINE, an adaptive schema-imagery enhanced compositional network for composed video retrieval (CVR). It materializes implicit semantics (termed schema imagery) from modification texts via dynamic multimodal prototypes that capture shared latent concepts, then uses these to adaptively modulate visual features. The central claim is that this bridges explicit visual contents and implicit retrieval intentions, yielding state-of-the-art performance on both CVR and composed image retrieval (CIR) across three benchmarks.
Significance. If the mechanism and SOTA claims were substantiated, the work would address a plausible gap in handling implicit concepts in compositional retrieval. However, the manuscript supplies no equations, architectural diagrams, experimental protocols, baselines, metrics, or results, so no assessment of significance is possible.
major comments (2)
- [Abstract] Abstract: The claim that IMAGINE 'achieves state-of-the-art performance in both CVR and Composed Image Retrieval (CIR) across three widely used benchmarks' is presented without any supporting experimental details, baselines, metrics, implementation description, or results tables. This renders the central empirical claim unsupported.
- [Abstract] Abstract: The core technical description ('dynamic multimodal prototypes' that 'materialize implicit semantics' and 'adaptively modulate visual features') is given at a high level with no equations, pseudocode, or architectural specification, preventing evaluation of whether the approach is well-defined or free of circularity.
Simulated Author's Rebuttal
We thank the referee for their review. We acknowledge that the submitted abstract presents both the empirical claim and technical description at a high level without supporting details, and we will revise the manuscript to address these deficiencies.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that IMAGINE 'achieves state-of-the-art performance in both CVR and Composed Image Retrieval (CIR) across three widely used benchmarks' is presented without any supporting experimental details, baselines, metrics, implementation description, or results tables. This renders the central empirical claim unsupported.
Authors: We agree that the abstract makes the SOTA claim without including supporting experimental information. We will revise the abstract to incorporate a concise reference to the benchmarks, metrics, and performance outcomes, and we will ensure the full manuscript contains the complete experimental protocols, baselines, metrics, and results tables. revision: yes
-
Referee: [Abstract] Abstract: The core technical description ('dynamic multimodal prototypes' that 'materialize implicit semantics' and 'adaptively modulate visual features') is given at a high level with no equations, pseudocode, or architectural specification, preventing evaluation of whether the approach is well-defined or free of circularity.
Authors: We agree that the abstract describes the mechanism at a high level without equations or specifications. We will revise the abstract to reference the key equations and architectural elements from the main text, and we will ensure the full manuscript supplies the mathematical formulations, pseudocode, and diagrams needed to define the approach. revision: yes
Circularity Check
No significant circularity; no derivation chain present
full rationale
The abstract and available context present only a high-level descriptive claim about materializing implicit semantics via dynamic multimodal prototypes, with no equations, parameter-fitting procedures, self-citations of uniqueness theorems, or any derivation chain that could reduce to inputs by construction. No load-bearing steps of the enumerated kinds are identifiable because no mathematical or procedural derivation is exhibited.
Axiom & Free-Parameter Ledger
invented entities (1)
-
schema imagery
no independent evidence
Forward citations
Cited by 1 Pith paper
-
RankVR: Low-Rank Structure Perception and Value Recalibration for Robust Composed Image Retrieval
RankVR introduces GSCP and ASVC modules to improve CIR robustness by decoupling clean samples via low-rank structure and dynamically scoring triplet value in noisy datasets.
Reference graph
Works this paper leans on
-
[1]
Yiyang Jiang, Wengyu Zhang, Xulu Zhang, Xiao-Yong Wei, Chang Wen Chen, and Qing Li. 2024. Prior knowledge integration via llm encoding and pseudo event regulation for video moment retrieval. InACM MM. 7249–7258
2024
-
[2]
Qianyun Yang, Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, and Liqiang Nie. 2026. STABLE: Efficient Hybrid Nearest Neighbor Search via Magnitude- Uniformity and Cardinality-Robustness.IEEE TKDE(2026)
2026
-
[3]
Zixu Li, Yupeng Hu, Zhiheng Fu, Zhiwei Chen, Weili Guan, and Liqiang Nie. 2026. R3: Composed Video Retrieval via Reasoning-Guided Recalling and Re-ranking. arXiv preprint arXiv:2606.01113(2026)
Pith/arXiv arXiv 2026
-
[4]
Zixu Li, Yupeng Hu, Zhiwei Chen, Shiqi Zhang, Qinlei Huang, Zhiheng Fu, and Yinwei Wei. 2026. HABIT: Chrono-Synergia Robust Progressive Learning Framework for Composed Image Retrieval. InAAAI, Vol. 40. 6762–6770
2026
-
[5]
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Xuemeng Song, and Liqiang Nie. 2025. OFFSET: Segmentation-based Focus Shift Revision for Composed Image Retrieval. InACM MM. 6113–6122
2025
-
[6]
Zheyuan Liu, Cristian Rodriguez Opazo, Damien Teney, and Stephen Gould
-
[7]
Image Retrieval on Real-life Images with Pre-trained Vision-and-Language Models. InICCV. IEEE, 2105–2114
-
[8]
Shuxian Li, Changhao He, Xiting Liu, Joey Tianyi Zhou, Xi Peng, and Peng Hu. 2025. Learning with Noisy Triplet Correspondence for Composed Image Retrieval. InCVPR. 19628–19637
2025
-
[9]
Mingyu Zhang, Zixu Li, Zhiwei Chen, Zhiheng Fu, Xiaowei Zhu, Jiajia Nie, Yinwei Wei, and Yupeng Hu. 2026. Hint: Composed image retrieval with dual- path compositional contextualized network.arXiv preprint arXiv:2603.26341 (2026)
arXiv 2026
-
[10]
Shilin Lu, Zihan Zhou, Jiayou Lu, Yuanzhi Zhu, and Adams Wai-Kin Kong
-
[11]
Robust watermarking using generative priors against image editing: From benchmarking to advances.arXiv preprint arXiv:2410.18775(2024)
arXiv 2024
-
[12]
Yangyi Fang, Jiaye Lin, Xiaoliang Fu, Cong Qin, Haolin Shi, Chang Liu, and Peilin Zhao. 2026. Proximity-Based Multi-Turn Optimization: Practical Credit Assignment for LLM Agent Training.arXiv preprint arXiv:2602.19225(2026)
arXiv 2026
-
[13]
Jincheng Huang, Yujie Mo, Xiaoshuang Shi, Lei Feng, and Xiaofeng Zhu. 2025. Enhancing the Influence of Labels on Unlabeled Nodes in Graph Convolutional Networks. InICML
2025
-
[14]
Yiming Zeng, Wanhao Yu, Zexin Li, Tao Ren, Yu Ma, Jinghan Cao, Xiyan Chen, and Tingting Yu. 2025. Bridging the editing gap in LLMs: FineEdit for precise and targeted text modifications.EMNLP Findings(2025), 2193–2206
2025
-
[15]
Yanlong Chen, Amirhossein Habibian, Luca Benini, and Yawei Li. 2026. Gated Relational Alignment via Confidence-based Distillation for Efficient VLMs.arXiv preprint arXiv:2601.22709(2026). doi:10.48550/arXiv.2601.22709
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.22709 2026
-
[16]
Panqi Yang, Haodong Jing, Nanning Zheng, and Yongqiang Ma. 2026. In- strucRobo: Object-centric multi-instruction decoupling model for explainable robotic manipulation.EAAI171 (2026), 114166
2026
-
[17]
Jinhe Bi, Danqi Yan, Yifan Wang, Wenke Huang, Haokun Chen, Guancheng Wan, Mang Ye, Xun Xiao, Hinrich Schuetze, Volker Tresp, and Yunpu Ma. 2026. The Geometry of Reasoning: Self-Evaluation via Layerwise Trajectory Evolution. In ICML. https://openreview.net/forum?id=WQyrwQwzmK
2026
-
[18]
Yuxuan Jiang, Dawei Li, and Frank Ferraro. 2025. Drp: Distilled reasoning pruning with skill-aware step decomposition for efficient large reasoning models. arXiv preprint arXiv:2505.13975(2025)
Pith/arXiv arXiv 2025
-
[19]
Jincheng Huang, Jialie Shen, Xiaoshuang Shi, and Xiaofeng Zhu. 2024. On Which Nodes Does GCN Fail? Enhancing GCN From the Node Perspective. In Forty-first International Conference on Machine Learning
2024
-
[20]
Xinjin Li, Yu Ma, Yangchen Huang, Xingqi Wang, Yuzhen Lin, and Chenxi Zhang. 2024. Synergized data efficiency and compression (sec) optimization for large language models. InEIECS. IEEE, 586–591
2024
-
[21]
Kailin Jiang, Ning Jiang, Yuntao Du, Yuchen Ren, Yuchen Li, Yifan Gao, Jinhe Bi, et al. 2025. MINED: Probing and Updating with Multimodal Time-Sensitive Knowledge for Large Multimodal Models.arXiv preprint arXiv:2510.19457(2025)
Pith/arXiv arXiv 2025
-
[22]
Zichao Li and Zong Ke. 2025. Domain meets typology: Predicting verb-final order from universal dependencies for financial and blockchain nlp. InWorkshop on Research in Computational Linguistic Typology and Multilingual NLP. 156–164
2025
-
[23]
Qianyun Yang, Peizhuo Lv, Yingjiu Li, Shengzhi Zhang, Yuxuan Chen, Zhiwei Chen, Zixu Li, and Yupeng Hu. 2026. ERASE: Bypassing Collaborative Detection of AI Counterfeit Via Comprehensive Artifacts Elimination.IEEE TDSC(March 2026), 1–18. doi:10.1109/TDSC.2026.3677794
-
[24]
Panqi Yang, Haodong Jing, Jiahao Chao, Tingyan Xiang, Li Lin, et al . 2026. MUSE: Resolving Manifold Misalignment in Visual Tokenization via Topological Orthogonality.arXiv preprint arXiv:2605.05646(2026)
Pith/arXiv arXiv 2026
-
[25]
Shilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin Kong. 2024. Mace: Mass concept erasure in diffusion models. InCVPR. 6430–6440
2024
-
[26]
Jinlai Zhang, Xiaolong Song, Yucheng Li, Diqing Liang, Zhiyong Zhang, and Jinhu Cai. 2026. Adaptive dual cross-attention network for multispectral object detection in autonomous driving.ESW A(2026), 132012
2026
-
[27]
Guancheng Wan, Xiaoran Shang, Yuxin Wu, Guibin Zhang, Jinhe Bi, Liangtao Zheng, Xin Lin, Yue Liu, Yanbiao Ma, Wenke Huang, and Bo Du. 2025. HY- PERION: Fine-Grained Hypersphere Alignment for Robust Federated Graph Learning. InNeurIPS. https://openreview.net/forum?id=TZB6YT8Owr
2025
-
[28]
Yuxuan Jiang and Francis Ferraro. 2026. Beyond math: Stories as a testbed for memorization-constrained reasoning in llms. InEACL. 5590–5607
2026
-
[29]
Zijian Zhang, Rong Fu, Yangfan He, Xinze Shen, Yanlong Wang, Xiaojing Du, Haochen You, Keyan Jin, Jiazhao Shi, and Simon Fong. 2026. FinSentLLM: Multi-LLM and structured semantic signals for enhanced financial sentiment forecasting. InICASSP. IEEE, 17682–17686
2026
-
[30]
Xingfeng Li, Yuangang Pan, Yuan Sun, Quansen Sun, Yinghui Sun, Ivor W Tsang, and Zhenwen Ren. 2024. Incomplete multi-view clustering with paired and balanced dynamic anchor learning.IEEE TMM27 (2024), 1486–1497
2024
-
[31]
Siyuan Li, Youyuan Zhang, Fangming Liu, and Jing Li. 2026. Modality-Decoupled Online Recursive Editing.arXiv preprint arXiv:2605.20273(2026)
Pith/arXiv arXiv 2026
-
[32]
Mengdi Li, Jiaye Lin, Xufeng Zhao, Wenhao Lu, Peilin Zhao, Stefan Wermter, and Di Wang. 2025. Curriculum-rlaif: Curriculum alignment with reinforcement learning from ai feedback.arXiv preprint arXiv:2505.20075(2025)
Pith/arXiv arXiv 2025
-
[33]
Zichao Li and Zong Ke. 2025. Cross-modal augmentation for low-resource language understanding and generation. InMAGMaR. 90–99
2025
-
[34]
Yang Tian, Fan Liu, Jingyuan Zhang, Yupeng Hu, Liqiang Nie, et al. 2025. CoRe- MMRAG: Cross-Source Knowledge Reconciliation for Multimodal RAG. InACL. 32967–32982
2025
-
[35]
Leyang Li, Shilin Lu, Yan Ren, and Adams Wai-Kin Kong. 2025. Set you straight: Auto-steering denoising trajectories to sidestep unwanted concepts.arXiv preprint arXiv:2504.12782(2025)
arXiv 2025
-
[36]
Lucas Ventura, Antoine Yang, Cordelia Schmid, and Gül Varol. 2024. CoVR: Learning composed video retrieval from web video captions. InAAAI, Vol. 38. 5270–5279
2024
-
[37]
Omkar Thawakar, Muzammal Naseer, Rao Muhammad Anwer, Salman Khan, Michael Felsberg, et al. 2024. Composed video retrieval via enriched context and discriminative embeddings. InCVPR. 26896–26906
2024
-
[38]
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhiheng Fu, Mingzhu Xu, and Liqiang Nie. 2026. REFINE: Composed Video Retrieval via Shared and Differential Semantics Enhancement.ACM ToMM(2026)
2026
-
[39]
Lucas Ventura, Antoine Yang, Cordelia Schmid, and Gül Varol. 2024. CoVR- 2: Automatic Data Construction for Composed Video Retrieval.IEEE TPAMI (2024)
2024
-
[40]
Zixu Li, Yupeng Hu, Zhiwei Chen, Qinlei Huang, Guozhi Qiu, Zhiheng Fu, and Meng Liu. 2026. ReTrack: Evidence-Driven Dual-Stream Directional Anchor Calibration Network for Composed Video Retrieval. InAAAI, Vol. 40. 23373– 23381
2026
-
[41]
WU Yue, Zhaobo Qi, Yiling Wu, Junshu Sun, Yaowei Wang, and Shuhui Wang
-
[42]
Learning Fine-Grained Representations through Textual Token Disentan- glement in Composed Video Retrieval. InICLR
-
[43]
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Haokun Wen, and Weili Guan
-
[44]
InACM MM
HUD: Hierarchical Uncertainty-Aware Disambiguation Network for Composed Video Retrieval. InACM MM. 6143–6152
-
[45]
Zong Ke, Yuqing Cao, Zhenrui Chen, Yuchen Yin, Shouchao He, and Yu Cheng
-
[46]
Finance Research Letters(2025), 107890
Early warning of cryptocurrency reversal risks via multi-source data. Finance Research Letters(2025), 107890
2025
-
[47]
Haokun Wen, Xuemeng Song, Jianhua Yin, Jianlong Wu, Weili Guan, and Liqiang Nie. 2024. Self-Training Boosted Multi-Factor Matching Network for Composed Image Retrieval.IEEE TPAMI46, 5 (2024), 3665–3678
2024
-
[48]
Kailin Jiang, Hongbo Jiang, Ning Jiang, Zhi Gao, Jinhe Bi, Yuchen Ren, Bin Li, Yuntao Du, Lei Liu, and Qing Li. 2025. KORE: Enhancing Knowledge Injection for Large Multimodal Models via Knowledge-Oriented Augmentations and Constraints.arXiv preprint arXiv:2510.19316(2025)
Pith/arXiv arXiv 2025
-
[49]
Ruanzhi Jiao, Jinlai Zhang, Chang Li, and Lin Hu. 2026. Large-kernel spatially parallel feature fusion for monocular 3D perception in autonomous driving. KBS343 (2026), 115998
2026
-
[50]
Xinlei Yu, Chengming Xu, Guibin Zhang, Zhangquan Chen, Yudong Zhang, Yongbo He, et al. 2025. Vismem: Latent vision memory unlocks potential of vision-language models.arXiv preprint arXiv:2511.11007(2025)
arXiv 2025
-
[51]
Yuxuan Jiang et al. 2026. SCRIBE: Structured Mid-Level Supervision for Tool- Using Language Models.arXiv preprint arXiv:2601.03555(2026)
Pith/arXiv arXiv 2026
-
[52]
Jinhe Bi, Minglai Yang, Xingcheng Zhou, Wenke Huang, Sikuan Yan, Yujun Wang, Zixuan Cao, Michael Färber, et al. 2026. EchoRL: Reinforcement Learning via Rollout Echoing.arXiv preprint arXiv:2605.31228(2026)
Pith/arXiv arXiv 2026
-
[53]
Jincheng Huang, Lun Du, Xu Chen, Qiang Fu, et al . 2023. Robust mid-pass filtering graph convolutional networks. InACM WWW. 328–338
2023
-
[54]
Gengyuan Zhang, Jinhe Bi, Jindong Gu, Yanyu Chen, and Volker Tresp. 2023. SPOT! Revisiting Video-Language Models for Event Understanding.arXiv preprint arXiv:2311.12919(2023)
arXiv 2023
-
[55]
Jiazhao Shi, Yichen Lin, Yiheng Hua, Ziyu Wang, Zijian Zhang, Wenjia Zheng, Yun Song, Kuan Lu, and Shoufeng Lu. 2026. Multiscenario highway lane- change intention prediction: a physics-informed AI framework for three-class classification. InSTCE, Vol. 14120. SPIE, 129–145. ICMR ’26, June 16–19, 2026, Amsterdam, Netherlands Huang et al
2026
-
[56]
Xiaoliang Fu, Jiaye Lin, Yangyi Fang, Binbin Zheng, Chaowen Hu, Zekai Shao, Cong Qin, Lu Pan, Ke Zeng, and Xunliang Cai. 2026. MASPO: Unifying Gradient Utilization, Probability Mass, and Signal Reliability for Robust and Sample- Efficient LLM Reasoning.arXiv preprint arXiv:2602.17550(2026)
Pith/arXiv arXiv 2026
-
[57]
Jinlai Zhang, Mingchao Xiang, Yongheng Hu, Wei Hao, et al. 2026. Multivariate feature learning and associative spatial information enhancement for snow object detection in autonomous driving.EAAI175 (2026), 114672
2026
-
[58]
Jincheng Huang, Jie Xu, Xiaoshuang Shi, Ping Hu, Lei Feng, et al. 2026. Revisiting Confidence Calibration for Misclassification Detection in VLMs. InICLR
2026
-
[59]
Xinlei Yu, Chengming Xu, Zhangquan Chen, Yudong Zhang, Shilin Lu, Cheng Yang, Jiangning Zhang, Shuicheng Yan, and Xiaobin Hu. 2025. Visual Document Understanding and Reasoning: A Multi-Agent Collaboration Framework with Agent-Wise Adaptive Test-Time Scaling.arXiv preprint arXiv:2508.03404(2025)
arXiv 2025
-
[60]
Zixu Li, Zhiheng Fu, Yupeng Hu, Zhiwei Chen, Haokun Wen, and Liqiang Nie
-
[61]
FineCIR: Explicit Parsing of Fine-Grained Modification Semantics for Composed Image Retrieval.https://arxiv.org/abs/2503.21309(2025)
arXiv 2025
-
[62]
Zhiwei Chen, Yupeng Hu, Zhiheng Fu, Zixu Li, Jiale Huang, Qinlei Huang, and Yinwei Wei. 2026. INTENT: Invariance and Discrimination-aware Noise Mitigation for Robust Composed Image Retrieval. InAAAI, Vol. 40. 20463–20471
2026
-
[63]
Zhiheng Fu, Yupeng Hu, Qianyun Yang, Shiqi Zhang, Zhiwei Chen, and Zixu Li
-
[64]
Air-Know: Arbiter-Calibrated Knowledge-Internalizing Robust Network for Composed Image Retrieval.arXiv preprint arXiv:2604.19386(2026)
Pith/arXiv arXiv 2026
-
[65]
Zixu Li, Yupeng Hu, Zhiwei Chen, Mingyu Zhang, Zhiheng Fu, and Liqiang Nie
-
[66]
ConeSep: Cone-based Robust Noise-Unlearning Compositional Network for Composed Image Retrieval.arXiv preprint arXiv:2604.20358(2026)
Pith/arXiv arXiv 2026
-
[67]
Feifei Zhang, Mingliang Xu, Qirong Mao, and Changsheng Xu. 2020. Joint attribute manipulation and modality alignment learning for composing text and image to image retrieval. InACM MM. ACM, 3367–3376
2020
-
[68]
Yuchen Yang, Min Wang, Wengang Zhou, and Houqiang Li. 2021. Cross-modal Joint Prediction and Alignment for Composed Query Image Retrieval. InACM MM. ACM, 3303–3311
2021
-
[69]
Gangjian Zhang, Shikui Wei, Huaxin Pang, Shuang Qiu, and Yao Zhao. 2022. Composed Image Retrieval via Explicit Erasure and Replenishment With Se- mantic Alignment.IEEE TIP31 (2022), 5976–5988
2022
-
[70]
Zixu Li, Yupeng Hu, Zhiwei Chen, Haokun Wen, Xuemeng Song, and Liqiang Nie. 2026. COMBINER: Composed Image Retrieval Guided by Attribute-based Neighbor Relations.IEEE TIP(2026)
2026
-
[71]
Zixu Li, Yupeng Hu, Zhiheng Fu, Zhiwei Chen, Yongqi Li, and Liqiang Nie. 2026. TEMA: Anchor the Image, Follow the Text for Multi-Modification Composed Image Retrieval.arXiv preprint arXiv:2604.21806(2026)
Pith/arXiv arXiv 2026
-
[72]
Yida Zhao, Yuqing Song, and Qin Jin. 2022. Progressive learning for image retrieval with hybrid-modality queries. InSIGIR. 1012–1021
2022
-
[73]
Hongguang Zhu, Yunchao Wei, Yao Zhao, Chunjie Zhang, and Shujuan Huang
-
[74]
AMC: Adaptive Multi-Expert Collaborative Network for Text-Guided Image Retrieval.ACM ToMM(2023)
2023
-
[75]
Yuxuan Jiang, Runchao Li, Shubhashis Roy Dipta, Dawei Li, and Zhao Yang
-
[76]
Cornerstones or Stumbling Blocks? Deciphering the Rock Tokens in On-Policy Distillation.arXiv preprint arXiv:2605.09253(2026)
Pith/arXiv arXiv 2026
-
[77]
Yuan Sun, Yang Qin, Yongxiang Li, Dezhong Peng, et al. 2024. Robust multi-view clustering with noisy correspondence.IEEE TKDE36, 12 (2024), 9150–9162
2024
-
[78]
Zhiheng Fu, Zixu Li, Zhiwei Chen, Fangxu Liu, Yupeng Hu, Weili Guan, and Liqiang Nie. 2026. EgoAction: Egocentric Action Composition with Reliability- Aware Temporal Fusion for the EPIC-KITCHENS Action Detection Challenge at CVPR 2026.arXiv preprint arXiv:2605.24496(2026)
Pith/arXiv arXiv 2026
-
[79]
Zixu Li, Yupeng Hu, Zhiwei Chen, Zhiheng Fu, Xiaowei Zhu, Weili Guan, and Liqiang Nie. 2026. TempRet: Temporal Enhancement and Two-Stage Reranking for CVPR 2026 EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge.arXiv preprint arXiv:2605.24470(2026)
Pith/arXiv arXiv 2026
-
[80]
Ningning Xu, Yuxuan Jiang, Shubhashis Roy Dipta, and Hengyuan Zhang
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.