CAT: Confidence-Adaptive Thinking for Efficient Reasoning of Large Reasoning Models
Pith reviewed 2026-07-02 13:20 UTC · model grok-4.3
The pith
CAT trains reasoning models to shorten their chain-of-thought on easy problems by feeding their own certainty estimates into preference optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
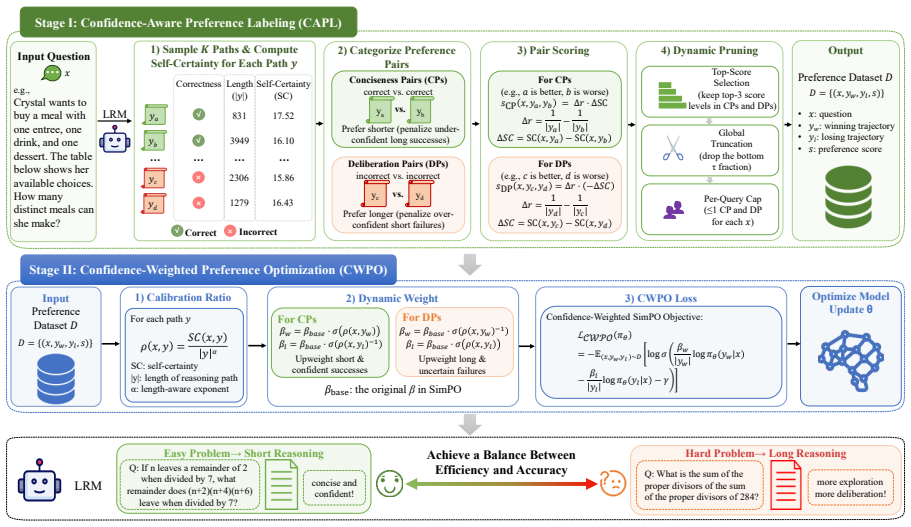
CAT incorporates the model's intrinsic self-certainty signals as confidence into the preference optimization process, which autonomously modulates reasoning lengths based on problem difficulty. Experimental results show that CAT consistently outperforms state-of-the-art baselines on reasoning accuracy across multiple benchmarks on different base models. The framework enables LRMs to effectively compress confident responses while deliberating on uncertain ones.
What carries the argument
Self-certainty signals inserted as confidence scores inside preference optimization to produce difficulty-adaptive reasoning lengths.
If this is right
- Reasoning length decreases automatically on problems where the model reports high certainty.
- Accuracy on difficult problems stays at or above the level of uncompressed models.
- The same training procedure transfers across multiple base reasoning models without task-specific tuning.
Where Pith is reading between the lines
- Production systems could route simple queries to shorter paths and reserve full computation for uncertain ones without external difficulty classifiers.
- The same certainty signal might be reused at inference time to decide early stopping rather than only during training.
- Combining CAT with token-level pruning could produce further efficiency gains on the already-shortened trajectories.
Load-bearing premise
The model's own certainty estimates reliably mark which problems are easy enough for shorter reasoning without hurting final accuracy on harder problems.
What would settle it
A controlled test on the hardest quartile of each benchmark where CAT-trained models show lower accuracy than the uncompressed baseline would falsify the central claim.
Figures

read the original abstract
Large Reasoning Models (LRMs) have achieved remarkable success on complex tasks by leveraging long chain-of-thought (CoT) trajectories, yet they frequently exhibit overthinking on simple queries, resulting in significant token overhead and reduced inference efficiency. However, existing compression methods predominantly apply uniform length reduction or rely on coarse-grained difficulty estimation, often leading to performance degradation on difficult problems. To address this limitation, we propose Confidence-Adaptive Thinking (CAT), a framework that incorporates the model's intrinsic self-certainty signals as confidence into the preference optimization process, which autonomously modulates reasoning lengths based on problem difficulty. Experimental results show that CAT consistently outperforms state-of-the-art baselines on reasoning accuracy across multiple benchmarks on different base models. Our work enables LRMs to effectively compress confident responses while deliberating on uncertain ones, offering a potentially robust solution for balancing accuracy and latency in practical industrial scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Confidence-Adaptive Thinking (CAT), a framework that incorporates a large reasoning model's intrinsic self-certainty signals into preference optimization to autonomously modulate chain-of-thought length according to estimated problem difficulty. It claims that this yields consistent accuracy gains over state-of-the-art compression baselines across multiple reasoning benchmarks and base models while reducing token overhead on easy problems.
Significance. If the self-certainty signals are shown to be calibrated and the optimization demonstrably preserves accuracy on hard cases, the method could provide a practical route to efficient inference for LRMs by avoiding both uniform over-compression and external difficulty estimators. The use of intrinsic signals is a conceptual strength relative to prior coarse-grained approaches.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the headline claim of 'consistent outperformance' is asserted without any reported accuracy deltas, token counts, baseline definitions, or statistical tests; the experiments section must supply these quantitative results (including per-benchmark tables and error analysis) for the central claim to be evaluable.
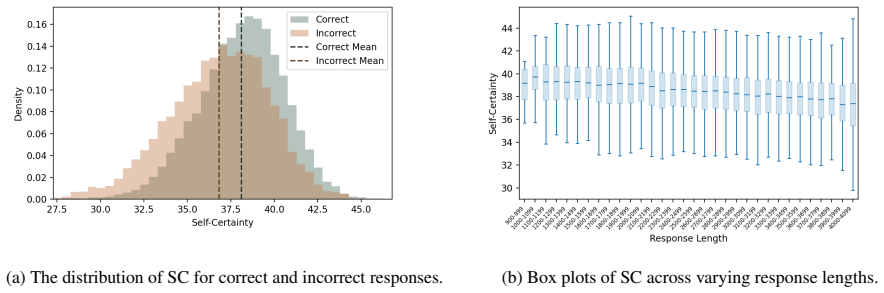
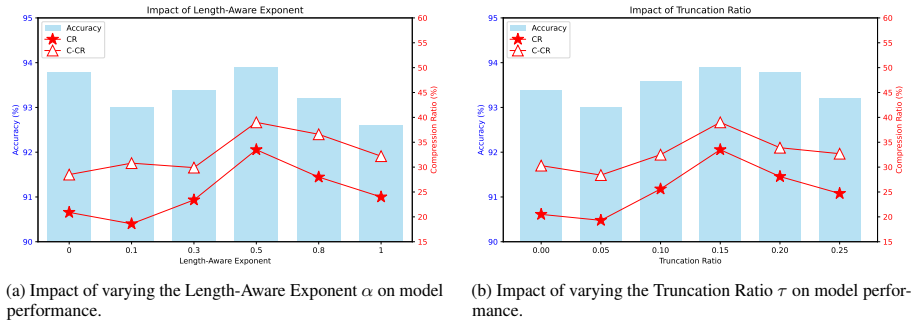
- [§3 and §4.3] §3 (Method) and §4.3 (Ablations): the framework's validity hinges on self-certainty reliably indicating difficulty and on preference optimization shortening high-certainty trajectories without degrading low-certainty performance. No calibration plots, correlation with ground-truth difficulty, or ablation that removes the confidence term from the objective are described; these checks are load-bearing for the 'no degradation on difficult problems' assertion.
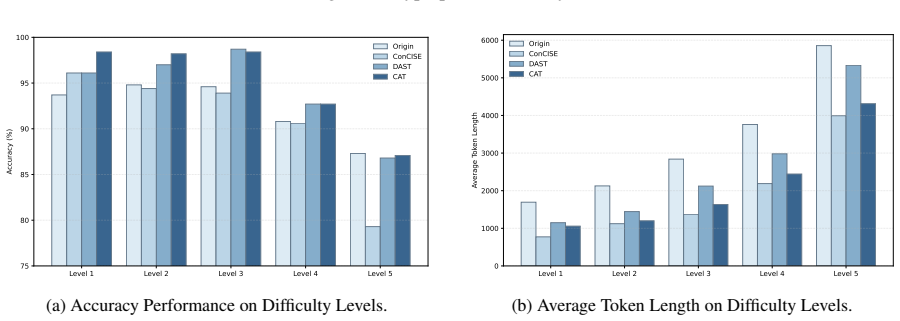
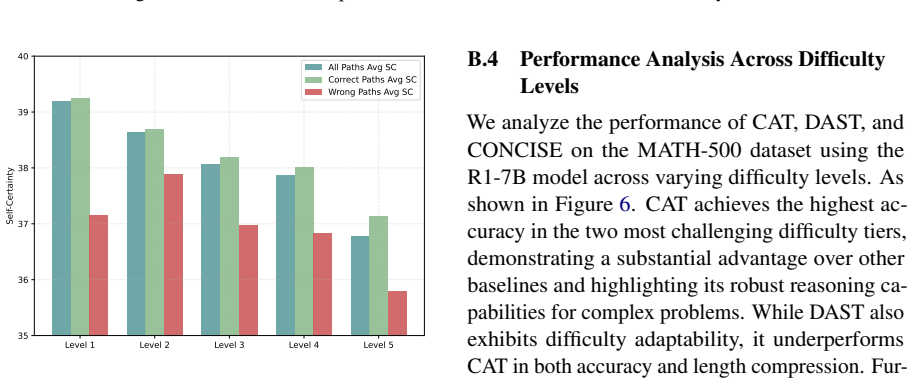
- [§4.2] §4.2 (Results): if a per-difficulty or per-certainty stratified breakdown exists, it must demonstrate that accuracy on hard/uncertain items is preserved; its absence leaves open the possibility that aggregate gains mask losses on difficult cases, directly undermining the modulation claim.
minor comments (2)
- [§3] Clarify the exact definition and computation of the self-certainty score (e.g., whether it is token-averaged log-probability, entropy, or another quantity) with an equation in the method section.
- [§5] Add a short discussion of failure modes, such as cases where self-certainty is miscalibrated on out-of-distribution problems.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the quantitative presentation and empirical validation of CAT. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the headline claim of 'consistent outperformance' is asserted without any reported accuracy deltas, token counts, baseline definitions, or statistical tests; the experiments section must supply these quantitative results (including per-benchmark tables and error analysis) for the central claim to be evaluable.
Authors: We agree that explicit quantitative details are required to substantiate the central claims. The experiments section contains comparative results, but we will revise §4 to include per-benchmark tables reporting accuracy deltas, token counts, explicit baseline definitions, and statistical significance tests, along with error analysis. The abstract will be updated to reference key quantitative improvements. revision: yes
-
Referee: [§3 and §4.3] §3 (Method) and §4.3 (Ablations): the framework's validity hinges on self-certainty reliably indicating difficulty and on preference optimization shortening high-certainty trajectories without degrading low-certainty performance. No calibration plots, correlation with ground-truth difficulty, or ablation that removes the confidence term from the objective are described; these checks are load-bearing for the 'no degradation on difficult problems' assertion.
Authors: We acknowledge that these supporting analyses are necessary. In the revision we will add calibration plots for the self-certainty signals, their correlation with ground-truth difficulty, and an ablation that removes the confidence term from the preference optimization objective. These additions will directly validate that high-certainty trajectories can be shortened without degrading performance on low-certainty cases. revision: yes
-
Referee: [§4.2] §4.2 (Results): if a per-difficulty or per-certainty stratified breakdown exists, it must demonstrate that accuracy on hard/uncertain items is preserved; its absence leaves open the possibility that aggregate gains mask losses on difficult cases, directly undermining the modulation claim.
Authors: We agree that aggregate results alone are insufficient. We will incorporate a per-difficulty and per-certainty stratified breakdown in the revised §4.2 to explicitly demonstrate that accuracy on hard or uncertain items is preserved while compression occurs on easier cases. revision: yes
Circularity Check
No circularity: framework relies on external preference optimization and empirical validation without self-referential reductions
full rationale
The paper proposes incorporating intrinsic self-certainty signals into preference optimization to modulate CoT length, with claims of accuracy gains supported by experimental results on benchmarks. No equations, fitted parameters, or derivations are presented in the provided text that reduce a claimed prediction or result back to the inputs by construction. The central mechanism is described as an autonomous modulation process rather than a mathematical identity or self-citation chain that forces the outcome. This is a standard empirical proposal whose validity rests on external benchmarks rather than definitional equivalence, qualifying for score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
OpenAI , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.16720 , eprinttype =. 2412.16720 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.16720 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2501.12948 , eprinttype =. 2501.12948 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[3]
Chi and Quoc V
Jason Wei and Xuezhi Wang and Dale Schuurmans and Maarten Bosma and Brian Ichter and Fei Xia and Ed H. Chi and Quoc V. Le and Denny Zhou , editor =. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , booktitle =. 2022 , url =
2022
-
[4]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen and Jiahao Xu and Tian Liang and Zhiwei He and Jianhui Pang and Dian Yu and Linfeng Song and Qiuzhi Liu and Mengfei Zhou and Zhuosheng Zhang and Rui Wang and Zhaopeng Tu and Haitao Mi and Dong Yu , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.21187 , eprinttype =. 2412.21187 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.21187 2024
-
[5]
Yue Liu and Jiaying Wu and Yufei He and Hongcheng Gao and Hongyu Chen and Baolong Bi and Jiaheng Zhang and Zhiqi Huang and Bryan Hooi , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.23077 , eprinttype =. 2503.23077 , timestamp =
-
[6]
Stop Overthinking:
Yang Sui and Yu. Stop Overthinking:. Trans. Mach. Learn. Res. , volume =. 2025 , url =
2025
-
[7]
Sicheng Feng and Gongfan Fang and Xinyin Ma and Xinchao Wang , title =. Trans. Mach. Learn. Res. , volume =. 2025 , url =
2025
-
[8]
Xiaoye Qu and Yafu Li and Zhaochen Su and Weigao Sun and Jianhao Yan and Dongrui Liu and Ganqu Cui and Daizong Liu and Shuxian Liang and Junxian He and Peng Li and Wei Wei and Jing Shao and Chaochao Lu and Yue Zhang and Xian. A Survey of Efficient Reasoning for Large Reasoning Models: Language, Multimodality, and Beyond , journal =. 2025 , url =. doi:10.4...
-
[9]
T oken S kip: Controllable Chain-of-Thought Compression in LLM s
Xia, Heming and Leong, Chak Tou and Wang, Wenjie and Li, Yongqi and Li, Wenjie. T oken S kip: Controllable Chain-of-Thought Compression in LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.165
-
[10]
CoT-Valve: Length-Compressible Chain-of-Thought Tuning , booktitle =
Xinyin Ma and Guangnian Wan and Runpeng Yu and Gongfan Fang and Xinchao Wang , editor =. CoT-Valve: Length-Compressible Chain-of-Thought Tuning , booktitle =. 2025 , url =
2025
-
[11]
Self-Training Elicits Concise Reasoning in Large Language Models , booktitle =
Tergel Munkhbat and Namgyu Ho and Seo Hyun Kim and Yongjin Yang and Yujin Kim and Se. Self-Training Elicits Concise Reasoning in Large Language Models , booktitle =. 2025 , url =
2025
-
[12]
Zhiyuan Zeng and Qinyuan Cheng and Zhangyue Yin and Bo Wang and Shimin Li and Yunhua Zhou and Qipeng Guo and Xuanjing Huang and Xipeng Qiu , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.14135 , eprinttype =. 2412.14135 , timestamp =
-
[13]
s1: Simple test-time scaling , booktitle =
Niklas Muennighoff and Zitong Yang and Weijia Shi and Xiang Lisa Li and Li Fei. s1: Simple test-time scaling , booktitle =. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.1025 , timestamp =
-
[14]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,
Yi Shen and Jian Zhang and Jieyun Huang and Shuming Shi and Wenjing Zhang and Jiangze Yan and Ning Wang and Kai Wang and Zhaoxiang Liu and Shiguo Lian , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. 2025 , url =
2025
-
[15]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,
Ziqing Qiao and Yongheng Deng and Jiali Zeng and Dong Wang and Lai Wei and Guanbo Wang and Fandong Meng and Jie Zhou and Ju Ren and Yaoxue Zhang , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.405 , timestamp =
-
[16]
Zhao and Kelvin Guu and Adams Wei Yu and Brian Lester and Nan Du and Andrew M
Jason Wei and Maarten Bosma and Vincent Y. Zhao and Kelvin Guu and Adams Wei Yu and Brian Lester and Nan Du and Andrew M. Dai and Quoc V. Le , title =. The Tenth International Conference on Learning Representations,. 2022 , url =
2022
-
[17]
Yu Meng and Mengzhou Xia and Danqi Chen , title =. Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024 , year =
2024
-
[18]
Scalable Best-of-N Selection for Large Language Models via Self-Certainty,
Zhewei Kang and Xuandong Zhao and Dawn Song , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.18581 , eprinttype =. 2502.18581 , timestamp =
-
[19]
Yichao Fu and Xuewei Wang and Yuandong Tian and Jiawei Zhao , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.15260 , eprinttype =. 2508.15260 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.15260 2025
-
[20]
Jiahui Geng and Fengyu Cai and Yuxia Wang and Heinz Koeppl and Preslav Nakov and Iryna Gurevych , title =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),. 2024 , url =. doi:10.18653/V1/2024.NAACL-LONG.366 , timestamp =
-
[21]
Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification
Fadeeva, Ekaterina and Rubashevskii, Aleksandr and Shelmanov, Artem and Petrakov, Sergey and Li, Haonan and Mubarak, Hamdy and Tsymbalov, Evgenii and Kuzmin, Gleb and Panchenko, Alexander and Baldwin, Timothy and Nakov, Preslav and Panov, Maxim. Fact-Checking the Output of Large Language Models via Token-Level Uncertainty Quantification. Findings of the A...
-
[22]
An Yang and Anfeng Li and Baosong Yang and Beichen Zhang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Gao and Chengen Huang and Chenxu Lv and Chujie Zheng and Dayiheng Liu and Fan Zhou and Fei Huang and Feng Hu and Hao Ge and Haoran Wei and Huan Lin and Jialong Tang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jian Yang and Jiaxi Yang and Ji...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[23]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , editor =. Measuring Mathematical Problem Solving With the. Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , year =
2021
-
[24]
The Twelfth International Conference on Learning Representations,
Hunter Lightman and Vineet Kosaraju and Yuri Burda and Harrison Edwards and Bowen Baker and Teddy Lee and Jan Leike and John Schulman and Ilya Sutskever and Karl Cobbe , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[25]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein and Betty Li Hou and Asa Cooper Stickland and Jackson Petty and Richard Yuanzhe Pang and Julien Dirani and Julian Michael and Samuel R. Bowman , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2311.12022 , eprinttype =. 2311.12022 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.12022 2023
-
[26]
Hugh Zhang and Daniel Duckworth and Daphne Ippolito and Arvind Neelakantan , title =. CoRR , volume =. 2020 , url =. 2004.10450 , timestamp =
-
[27]
Varshney , title =
Sourya Basu and Govardana Sachitanandam Ramachandran and Nitish Shirish Keskar and Lav R. Varshney , title =. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[28]
Yuyang Wu and Yifei Wang and Tianqi Du and Stefanie Jegelka and Yisen Wang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.07266 , eprinttype =. 2502.07266 , timestamp =
-
[29]
Yue Wang and Qiuzhi Liu and Jiahao Xu and Tian Liang and Xingyu Chen and Zhiwei He and Linfeng Song and Dian Yu and Juntao Li and Zhuosheng Zhang and Rui Wang and Zhaopeng Tu and Haitao Mi and Dong Yu , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2501.18585 , eprinttype =. 2501.18585 , timestamp =
-
[30]
Findings of the Association for Computational Linguistics,
Yingqian Cui and Pengfei He and Jingying Zeng and Hui Liu and Xianfeng Tang and Zhenwei Dai and Yan Han and Chen Luo and Jing Huang and Zhen Li and Suhang Wang and Yue Xing and Jiliang Tang and Qi He , title =. Findings of the Association for Computational Linguistics,. 2025 , url =
2025
-
[31]
Toward large reasoning models: A survey of reinforced reasoning with large language models , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.patter.2025.101370 , url =
-
[32]
L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
Pranjal Aggarwal and Sean Welleck , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.04697 , eprinttype =. 2503.04697 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.04697 2025
-
[33]
ArXiv , year=
O1-Pruner: Length-Harmonizing Fine-Tuning for O1-Like Reasoning Pruning , author=. ArXiv , year=
-
[34]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu and Zheng Zhang and Ruofei Zhu and Yufeng Yuan and Xiaochen Zuo and Yu Yue and Tiantian Fan and Gaohong Liu and Lingjun Liu and Xin Liu and Haibin Lin and Zhiqi Lin and Bole Ma and Guangming Sheng and Yuxuan Tong and Chi Zhang and Mofan Zhang and Wang Zhang and Hang Zhu and Jinhua Zhu and Jiaze Chen and Jiangjie Chen and Chengyi Wang and Hongli ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476 2025
-
[35]
Token-Budget-Aware
Tingxu Han and Zhenting Wang and Chunrong Fang and Shiyu Zhao and Shiqing Ma and Zhenyu Chen , editor =. Token-Budget-Aware. Findings of the Association for Computational Linguistics,. 2025 , url =
2025
-
[36]
2nd International Conference on Foundation and Large Language Models,
Matthew Renze and Erhan Guven , title =. 2nd International Conference on Foundation and Large Language Models,. 2024 , url =. doi:10.1109/FLLM63129.2024.10852493 , timestamp =
-
[37]
Concise thoughts: Impact of output length on llm reasoning and cost.arXiv preprint arXiv:2407.19825,
Sania Nayab and Giulio Rossolini and Giorgio C. Buttazzo and Nicolamaria Manes and Fabrizio Giacomelli , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.19825 , eprinttype =. 2407.19825 , timestamp =
-
[38]
Confident or Seek Stronger: Exploring Uncertainty-Based On-device
Yu. Confident or Seek Stronger: Exploring Uncertainty-Based On-device. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.04428 , eprinttype =. 2502.04428 , timestamp =
-
[39]
RouteLLM: Learning to Route LLMs from Preference Data , booktitle =
Isaac Ong and Amjad Almahairi and Vincent Wu and Wei. RouteLLM: Learning to Route LLMs from Preference Data , booktitle =. 2025 , url =
2025
-
[40]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,
Zhenyi Shen and Hanqi Yan and Linhai Zhang and Zhanghao Hu and Yali Du and Yulan He , editor =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.36 , timestamp =
-
[41]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao and Sainbayar Sukhbaatar and DiJia Su and Xian Li and Zhiting Hu and Jason Weston and Yuandong Tian , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.06769 , eprinttype =. 2412.06769 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.06769 2024
-
[42]
Bartlett and Andrea Zanette , editor =
Hanshi Sun and Momin Haider and Ruiqi Zhang and Huitao Yang and Jiahao Qiu and Ming Yin and Mengdi Wang and Peter L. Bartlett and Andrea Zanette , editor =. Fast Best-of-N Decoding via Speculative Rejection , booktitle =. 2024 , url =
2024
-
[43]
Chain of draft: Thinking faster by writing less.arXiv preprint arXiv:2502.18600, 2025a
Silei Xu and Wenhao Xie and Lingxiao Zhao and Pengcheng He , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.18600 , eprinttype =. 2502.18600 , timestamp =
-
[44]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,
Jiaxin Zhang , title =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. 2025 , url =
2025
-
[45]
American Invitational Mathematics Examination-AIME 2024 , author=
2024
-
[46]
Open R1: A fully open reproduction of DeepSeek-R1 , url =
-
[47]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =. 2022 , url =
2022
-
[48]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[49]
Publications Manual , year = "1983", publisher =
1983
-
[50]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[51]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[52]
Dan Gusfield , title =. 1997
1997
-
[53]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[54]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.