Focus-then-Context: Subject-Centric Progressive Visual Token Reduction for Vision-Language Models
Pith reviewed 2026-05-21 05:17 UTC · model grok-4.3
The pith
A subject-centric progressive reduction method cuts visual tokens in vision-language models by first locating key subjects and then preserving their surrounding context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a subject-centric progressive visual token reduction paradigm, built around an initial focus identification module modeling the interplay of visual saliency and semantic relevance followed by a context-aware structural scanning module that aggregates neighboring cues, produces higher-fidelity subject representations and better-preserved global relational dependencies than methods limited to isolated query-aligned subjects.
What carries the argument
The SPpruner paradigm's focus identification module, which excavates the full visual subject spectrum, paired with its context-aware structural scanning module that restores relational dependencies.
If this is right
- Achieves up to 2.53 times speedup while retaining only 22.2 percent of visual tokens on Qwen2.5-VL.
- Delivers a 67 percent FLOPs reduction on LLaVA with a 0.6 percent accuracy drop.
- Outperforms prior state-of-the-art vision token reduction methods across tested models and tasks.
- Maintains structural integrity of preserved subjects by incorporating contextual cues from neighboring regions.
Where Pith is reading between the lines
- The staged focus-then-context design could be tested on other multimodal models that handle image or video sequences.
- Adaptive versions might vary the retained token percentage according to scene complexity.
- The modules could be combined with quantization or pruning of the language component for further gains.
Load-bearing premise
The focus identification module can reliably detect the interplay of saliency and semantic relevance across all relevant subjects without missing context or skewing toward the query.
What would settle it
Running the reduced-token model on a set of images with multiple interacting subjects and measuring whether accuracy falls more than a few percent below the full-token baseline.
Figures


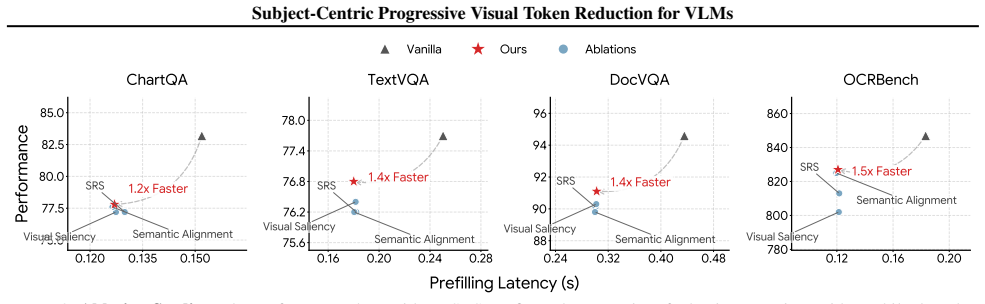
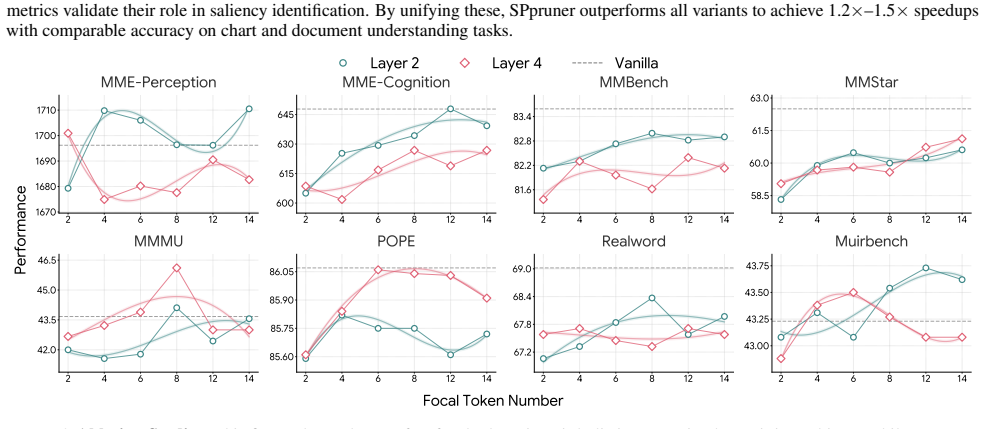



read the original abstract
Vision-Language Models (VLMs) face a bottleneck of prohibitive computational costs arising from massive visual token sequences during inference. Existing vision token reduction methods alleviate this burden, but they unintentionally preserve the isolated visual subject strictly aligned with the user's query, which fails to substantially explore salient subjects and their contextual relationships. In this paper, we propose SPpruner, a subject-centric progressive reduction paradigm that emulates the \textit{Focus-then-Context} mechanism of the human visual perception system. Specifically, we first construct a focus identification module to explicitly model the interplay between visual saliency and semantic relevance. Herein, it can excavate the comprehensive visual subject spectrum to ensure a high-fidelity representation of visual input. Subsequently, a context-aware structural scanning module is developed to aggregate contextual cues from neighboring regions. As such, it can effectively restore global relational dependencies to uphold the structural integrity of the preserved subjects. Extensive experiments demonstrate that our paradigm consistently outperforms SOTA methods, achieving up to 2.53 times speedup with only 22.2% of visual tokens retained in Qwen2.5-VL and a 67% FLOPs reduction on LLaVA with a negligible 0.6% accuracy drop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SPpruner, a subject-centric progressive visual token reduction paradigm for Vision-Language Models that emulates the Focus-then-Context mechanism of human visual perception. It introduces a focus identification module to model the interplay between visual saliency and semantic relevance for preserving comprehensive visual subjects, followed by a context-aware structural scanning module to aggregate contextual cues and restore global dependencies. Extensive experiments on Qwen2.5-VL and LLaVA demonstrate superior performance over SOTA methods, with up to 2.53 times speedup at 22.2% token retention and 67% FLOPs reduction with only 0.6% accuracy drop.
Significance. If the results hold under rigorous verification, this could represent a meaningful advance in efficient VLM inference by targeting the limitation of prior token-reduction techniques that retain only query-aligned subjects. The two-stage human-inspired design is conceptually coherent, and the concrete efficiency metrics (speedup, FLOPs, token retention) on two distinct models would be a useful contribution to the field if accompanied by reproducible code and full experimental protocols.
major comments (2)
- [§3.2] §3.2 (Focus Identification Module): The claim that the module 'excavates the comprehensive visual subject spectrum' by explicitly modeling saliency-relevance interplay is load-bearing for the central novelty and performance claims, yet the description does not specify whether saliency is computed independently (e.g., via a query-agnostic detector) or through cross-attention to the text query. If the latter, the module risks systematic down-weighting of salient but query-misaligned regions, directly undermining the subject-centric advantage asserted in the abstract and the reported gains.
- [Experiments] Experiments section, Table 2 (Qwen2.5-VL results): The headline 2.53× speedup at 22.2% token retention and the 0.6% accuracy drop are presented without error bars, number of runs, or explicit data-split details. This is load-bearing because the soundness assessment rests on these unexamined experimental details; without them the 'consistently outperforms SOTA' claim cannot be evaluated at the required level of rigor.
minor comments (2)
- [Abstract] Abstract: The acronym SPpruner is introduced without expansion or definition on first use.
- [§4.1] §4.1: Notation for the context-aware scanning module could be clarified by explicitly defining the aggregation function rather than describing it procedurally.
Simulated Author's Rebuttal
We sincerely thank the referee for their thoughtful and constructive feedback. We address each major comment point by point below, providing clarifications and indicating revisions where the manuscript will be updated.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Focus Identification Module): The claim that the module 'excavates the comprehensive visual subject spectrum' by explicitly modeling saliency-relevance interplay is load-bearing for the central novelty and performance claims, yet the description does not specify whether saliency is computed independently (e.g., via a query-agnostic detector) or through cross-attention to the text query. If the latter, the module risks systematic down-weighting of salient but query-misaligned regions, directly undermining the subject-centric advantage asserted in the abstract and the reported gains.
Authors: We thank the referee for this important observation on clarity. In the Focus Identification Module, visual saliency is computed independently using a query-agnostic saliency detector (based on established CV techniques such as gradient-based or attention-map methods from a frozen backbone), while semantic relevance is modeled separately via cross-attention with the text query. The interplay is then fused to preserve the full subject spectrum. This separation explicitly avoids down-weighting salient but query-misaligned regions, directly supporting the subject-centric claim. We have revised §3.2 to explicitly state the independent saliency path, added pseudocode, and included a new diagram illustrating the two parallel streams and their fusion. revision: yes
-
Referee: [Experiments] Experiments section, Table 2 (Qwen2.5-VL results): The headline 2.53× speedup at 22.2% token retention and the 0.6% accuracy drop are presented without error bars, number of runs, or explicit data-split details. This is load-bearing because the soundness assessment rests on these unexamined experimental details; without them the 'consistently outperforms SOTA' claim cannot be evaluated at the required level of rigor.
Authors: We agree that greater transparency on experimental protocol is required. The reported metrics follow the standard fixed splits and evaluation protocols of the benchmarks (VQAv2, GQA, POPE, etc.). Due to the substantial compute required for full VLM inference, primary results reflect single runs per setting; however, we have now added error bars computed over three random seeds for the key Qwen2.5-VL configurations in a new supplementary table, explicitly documented the data splits and preprocessing, and expanded the experimental setup subsection. We will release code and full reproduction scripts upon acceptance to enable independent verification. revision: yes
Circularity Check
No circularity; method defined procedurally via new modules
full rationale
The paper proposes SPpruner as a subject-centric progressive reduction paradigm that emulates human visual perception through two explicitly constructed modules: a focus identification module modeling saliency-relevance interplay and a context-aware structural scanning module for relational dependencies. No equations, fitted parameters, or predictions are shown that reduce by construction to inputs or prior self-citations. Performance claims rest on experimental results rather than any self-referential derivation, making the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human visual system processes scenes via initial focus on salient subjects followed by contextual integration.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we first construct a focus identification module to explicitly model the interplay between visual saliency and semantic relevance... S(xi) = Φ(∥xi∥1) + Φ(R(xi | Xq))
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Structure-Responsive Sampling (SRS) mechanism... Δ = max(1, ⌊(Ntarget − |F|)·δ⌋)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Divprune: Diversity-based visual token pruning for large multimodal models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Pact: Pruning and clustering-based token reduction for faster visual language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[3]
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs , author=. arXiv preprint arXiv:2506.10967 , year=
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Visionzip: Longer is better but not necessary in vision language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[5]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Sparsevlm: Visual token sparsification for efficient vision-language model inference , author=. arXiv preprint arXiv:2410.04417 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2505.22654 , year=
VScan: Rethinking Visual Token Reduction for Efficient Large Vision-Language Models , author=. arXiv preprint arXiv:2505.22654 , year=
-
[7]
arXiv preprint arXiv:2502.11501 , year=
Token Pruning in Multimodal Large Language Models: Are We Solving the Right Problem? , author=. arXiv preprint arXiv:2502.11501 , year=
-
[8]
Tokenskip: Controllable chain-of-thought compression in llms.arXiv preprint arXiv:2502.12067,
Tokenskip: Controllable chain-of-thought compression in llms , author=. arXiv preprint arXiv:2502.12067 , year=
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Token cropr: Faster vits for quite a few tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
DyCoke: Dynamic Compression of Tokens for Fast Video Large Language Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year=
What kind of visual tokens do we need? training-free visual token pruning for multi-modal large language models from the perspective of graph , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year=
-
[12]
Visual Instruction Tuning , author=
-
[13]
Llavanext: Improved reasoning, ocr, and world knowledge , author=
-
[14]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
The Conference on Neural Information Processing Systems (NeurIPS) , year=
Attention is all you need , author=. The Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[19]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Stop looking for important tokens in multimodal language models: Duplication matters more
Stop looking for important tokens in multimodal language models: Duplication matters more , author=. arXiv preprint arXiv:2502.11494 , year=
-
[21]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Token Merging: Your ViT But Faster
Token merging: Your vit but faster , author=. arXiv preprint arXiv:2210.09461 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
The European Conference on Computer Vision (ECCV) , year=
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models , author=. The European Conference on Computer Vision (ECCV) , year=
-
[24]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction , author=. arXiv preprint arXiv:2410.17247 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Llava-mini: Efficient image and video large mul- timodal models with one vision token,
Llava-mini: Efficient image and video large multimodal models with one vision token , author=. arXiv preprint arXiv:2501.03895 , year=
-
[26]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Video-llava: Learning united visual representation by alignment before projection , author=. arXiv preprint arXiv:2311.10122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[29]
The Conference on Neural Information Processing Systems (NeurIPS) , year=
Instructblip: Towards general-purpose vision-language models with instruction tuning , author=. The Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[30]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Minigpt-4: Enhancing vision-language understanding with advanced large language models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
International Conference on Machine Learning (ICML) , year=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International Conference on Machine Learning (ICML) , year=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
VASparse: Towards Efficient Visual Hallucination Mitigation via Visual-Aware Token Sparsification , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[33]
arXiv preprint arXiv:2508.06084 , year=
AdaptInfer: Adaptive Token Pruning for Vision-Language Model Inference with Dynamical Text Guidance , author=. arXiv preprint arXiv:2508.06084 , year=
-
[34]
Transformer Feed-Forward Layers Are Key-Value Memories
Transformer feed-forward layers are key-value memories , author=. arXiv preprint arXiv:2012.14913 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[35]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Vizwiz grand challenge: Answering visual questions from blind people , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[36]
arXiv preprint arXiv:2505.13220 , year=
SeedBench: A Multi-task Benchmark for Evaluating Large Language Models in Seed Science , author=. arXiv preprint arXiv:2505.13220 , year=
-
[37]
The European Conference on Computer Vision (ECCV) , year=
Mmbench: Is your multi-modal model an all-around player? , author=. The European Conference on Computer Vision (ECCV) , year=
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[39]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Mme: A comprehensive evaluation benchmark for multimodal large language models , author=. arXiv preprint arXiv:2306.13394 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Evaluating Object Hallucination in Large Vision-Language Models
Evaluating object hallucination in large vision-language models , author=. arXiv preprint arXiv:2305.10355 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[42]
Object Hallucination in Image Captioning
Object hallucination in image captioning , author=. arXiv preprint arXiv:1809.02156 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[44]
Journal of Comparative Neurology , volume=
Human photoreceptor topography , author=. Journal of Comparative Neurology , volume=. 1990 , publisher=
work page 1990
-
[45]
Visual search: A retrospective , author=. Journal of Vision , volume=. 2011 , publisher=
work page 2011
-
[46]
Yiqi Wang and Wentao Chen and Xiaotian Han and Xudong Lin and Haiteng Zhao and Yongfei Liu and Bohan Zhai and Jianbo Yuan and Quanzeng You and Hongxia Yang , title =. arXiv preprint arXiv:2401.06805 , year=
-
[47]
Visual Question Answering: A Survey of Methods and Datasets
Qi Wu and Damien Teney and Peng Wang and Chunhua Shen and Anthony Dick and Anton van den Hengel , title=. arXiv preprint arXiv:1607.05910 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Yanwei Li and Yuechen Zhang and Chengyao Wang and Zhisheng Zhong and Yixin Chen and Ruihang Chu and Shaoteng Liu and Jiaya Jia , title=. arXiv preprint arXiv:2403.18814 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Yolo Y. Tang and Jing Bi and Siting Xu and Luchuan Song and Susan Liang and Teng Wang and Daoan Zhang and Jie An and Jingyang Lin and Rongyi Zhu and Ali Vosoughi and Chao Huang and Zeliang Zhang and Pinxin Liu and Mingqian Feng and Feng Zheng and Jianguo Zhang and Ping Luo and Jiebo Luo and Chenliang Xu , title=. arXiv preprint arXiv:2312.17432 , year=
-
[50]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li and Yuanhan Zhang and Dong Guo and Renrui Zhang and Feng Li and Hao Zhang and Kaichen Zhang and Peiyuan Zhang and Yanwei Li and Ziwei Liu and Chunyuan Li , title=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
The Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Evaluating Object Hallucination in Large Vision-Language Models , author=. The Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
-
[52]
VQA: Visual Question Answering
Stanislaw Antol and Aishwarya Agrawal and Jiasen Lu and Margaret Mitchell and Dhruv Batra and C. Lawrence Zitnick and Devi Parikh , title=. arXiv preprint arXiv:1505.00468 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
The Conference on Neural Information Processing Systems (NeurIPS) , year=
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author=. The Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[54]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Towards VQA Models That Can Read , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[55]
Minesh Mathew and Dimosthenis Karatzas and R. Manmatha and C. V. Jawahar , title=. arXiv preprint arXiv:2007.00398 , year=
-
[56]
Science China Information Sciences , volume=
Liu, Yuliang and Li, Zhang and Huang, Mingxin and Yang, Biao and Yu, Wenwen and Li, Chunyuan and Yin, Xu-Cheng and Liu, Cheng-Lin and Jin, Lianwen and Bai, Xiang , title=. Science China Information Sciences , volume=
-
[57]
International Conference on Machine Learning (ICML) , year=
Mm-vet: Evaluating large multimodal models for integrated capabilities , author=. International Conference on Machine Learning (ICML) , year=
-
[58]
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding
MuirBench: A Comprehensive Benchmark for Robust Multi-image Understanding , author=. arXiv preprint arXiv:2406.09411 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Mlvu: Benchmarking multi-task long video understanding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[60]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Are We on the Right Way for Evaluating Large Vision-Language Models? , author=. arXiv preprint arXiv:2403.20330 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Transactions of the Association for Computational Linguistics , volume=
From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions , author=. Transactions of the Association for Computational Linguistics , volume=
-
[62]
Findings of the Association for Computational Linguistics (ACL) , year=
Masry, Ahmed and Long, Do and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul , title=. Findings of the Association for Computational Linguistics (ACL) , year=
- [63]
-
[64]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year=
Boosting multimodal large language models with visual tokens withdrawal for rapid inference , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , year=
-
[65]
Pangu embedded: An efficient dual-system llm reasoner with metacognition , author=. arXiv preprint arXiv:2505.22375 , year=
-
[66]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.