VLMs are Good Teachers for Video Reasoning via Adaptive Test-Time Optimization
Pith reviewed 2026-06-30 10:35 UTC · model grok-4.3
The pith
VLMs can teach video generation models to reason by turning perception into differentiable rewards optimized at test time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
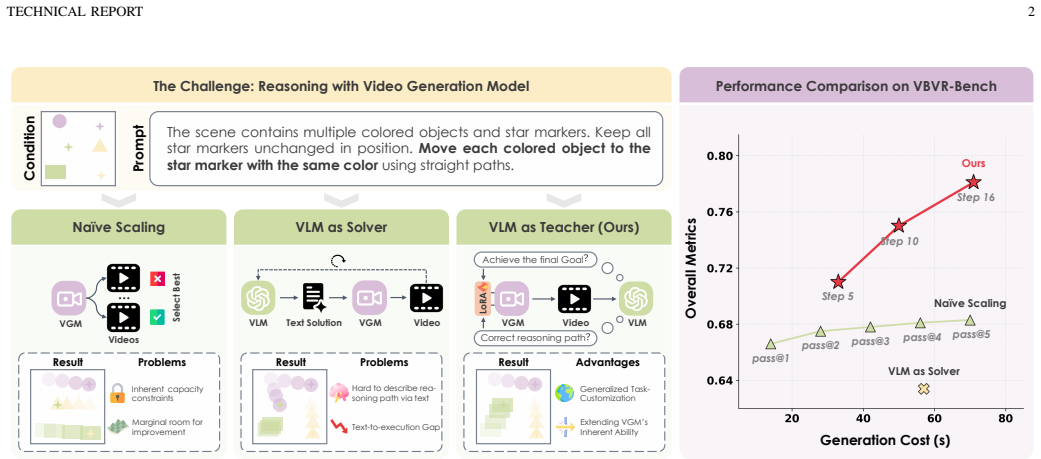
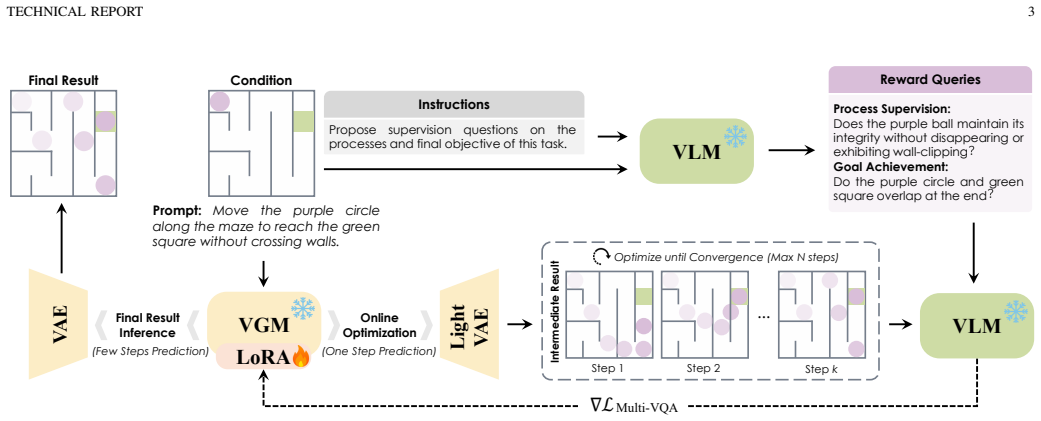
A VLM teacher extracts task-specific rules to formulate differentiable rewards, guiding a VGM Reasoner via test-time online optimization of a lightweight LoRA module. This strategy enables adaptive test-time optimization and extends the reasoning capabilities beyond the VGM's intrinsic boundaries.
What carries the argument
VLM-as-Teacher paradigm that converts perception of process constraints and goal achievement into differentiable rewards for test-time LoRA optimization of a video generation model.
If this is right
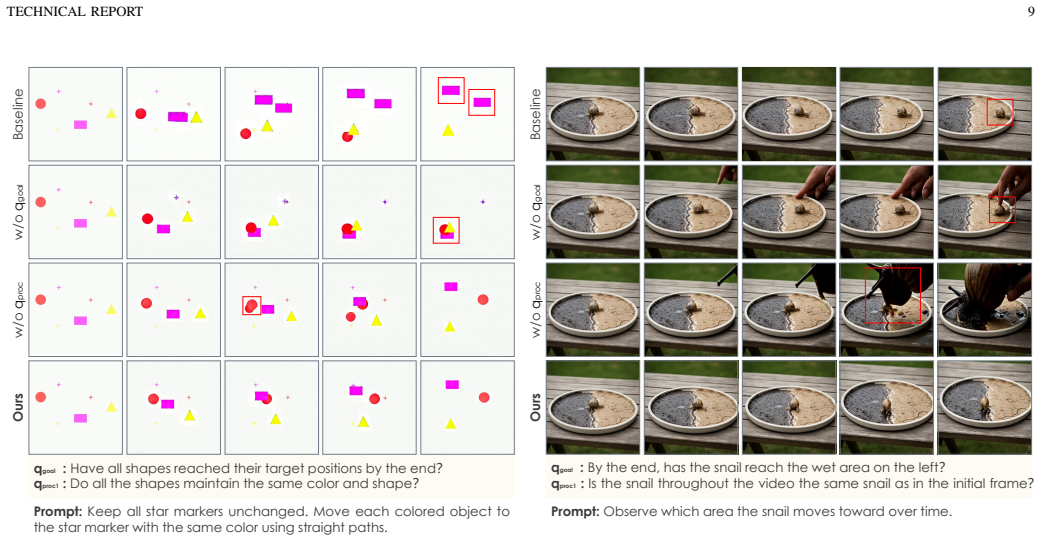
- Video reasoning performance rises by 16.7 points on average across symbolic and general-purpose benchmarks.
- The VLM-as-Teacher approach outperforms both the VLM-as-Solver baseline and Best-of-N sampling by large margins at similar test-time cost.
- Reasoning can be extended beyond a fixed VGM's training distribution through online reward-driven adaptation rather than prompt engineering alone.
- The same teacher-reward loop can be applied to other generation-based reasoning tasks where perception is easier than generation.
Where Pith is reading between the lines
- If the reward formulation generalizes across tasks, it could reduce the need for task-specific fine-tuning of large video models.
- The method suggests a broader pattern where perception models supervise generation models at inference time instead of competing with them as solvers.
- Extending the approach might allow chaining multiple VLM teachers for multi-step or hierarchical reasoning without increasing model size.
Load-bearing premise
VLMs must have accurate enough perception to correctly judge whether video generation steps satisfy task rules and reach the goal so that the resulting rewards actually steer the model toward correct solutions.
What would settle it
Running the method on a benchmark where VLM reward signals are deliberately noisy or inverted and checking whether performance still improves over the base VGM or drops below it.
Figures

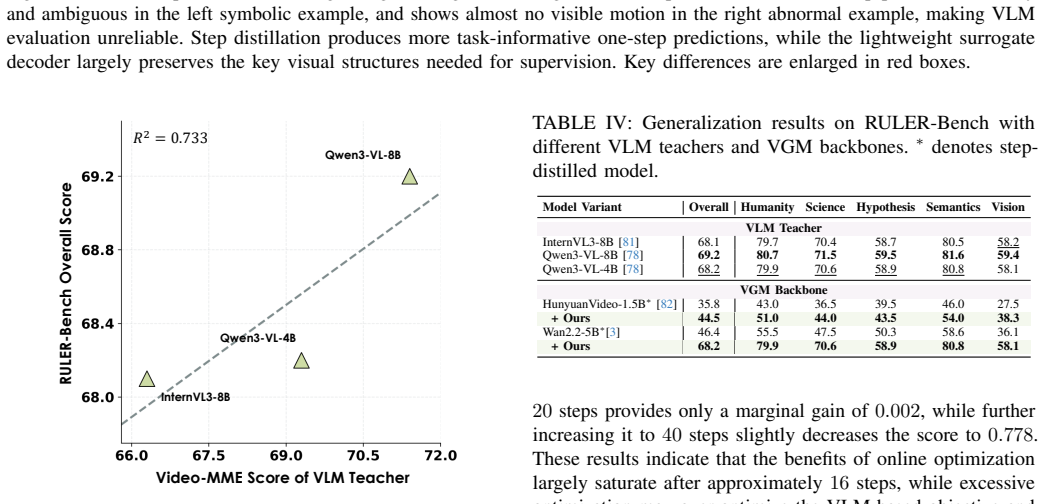
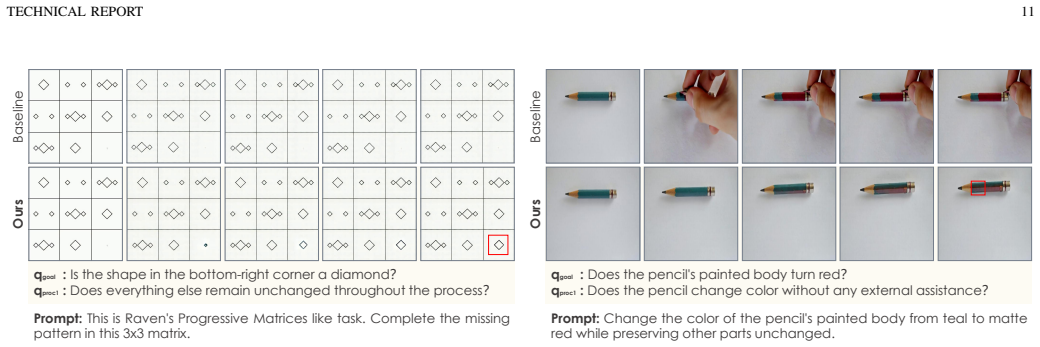
read the original abstract
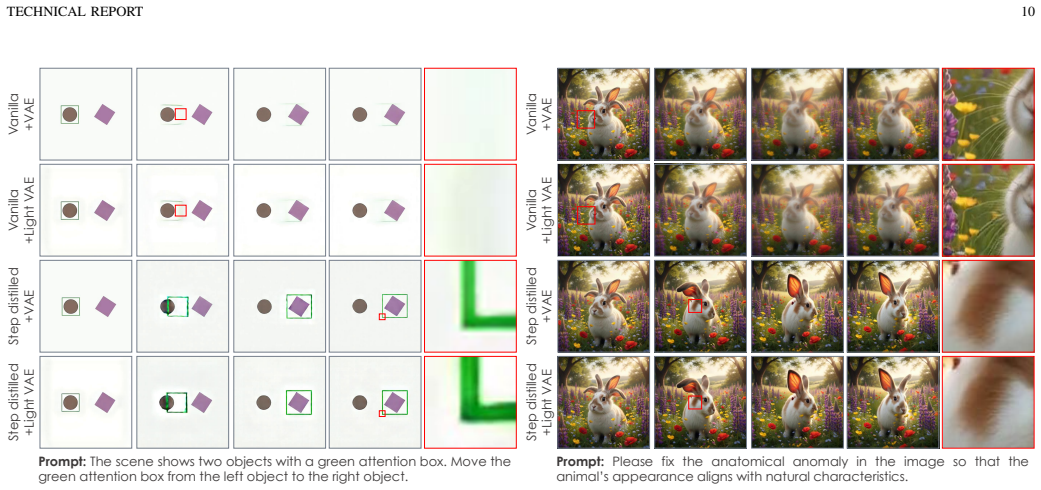
The recent "Reasoning with Video" paradigm utilizes Video Generation Models (VGMs) to generate temporally coherent visual trajectories to complete reasoning tasks. Although state-of-the-art VGMs excel at visual quality, they often struggle to understand and follow task-specific rules, leading to logical failures across diverse reasoning scenarios. Existing efforts try to utilize Vision-Language Models (VLMs) as problem pre-solvers to produce or refine textual guidance for the VGM. However, textual descriptions fail to capture intricate spatiotemporal details, and VGMs often struggle to faithfully execute fine-grained or long-tail instructions even with a valid plan. While VLMs struggle as solvers, they possess strong perception capabilities to evaluate process-constraint satisfaction and final-goal achievement. Leveraging this strength, we introduce a paradigm shift that transitions the role of VLMs to "teachers". Specifically, a VLM teacher extracts task-specific rules to formulate differentiable rewards, guiding a VGM Reasoner via test-time online optimization of a lightweight LoRA module. This strategy enables adaptive test-time optimization and extends the reasoning capabilities beyond the VGM's intrinsic boundaries. Evaluations on symbolic (VBVR-Bench) and general-purpose (RULER-Bench) video reasoning benchmarks show that the proposed method yields a 16.7-point average performance gain, outperforming the VLM-as-Solver paradigm (+0.4 points) and Best-of-N scaling (+2.2 points) by a large margin at comparable test-time cost. These findings reveal that integrating VLMs as test-time teachers offers a promising paradigm for achieving generalizable video reasoning. Project Page: https://VLM-as-Teacher.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs can serve as teachers rather than solvers for video reasoning by extracting task-specific rules to create differentiable rewards, which then guide test-time online optimization of a lightweight LoRA module on a Video Generation Model (VGM) Reasoner. This yields a reported 16.7-point average gain on symbolic (VBVR-Bench) and general-purpose (RULER-Bench) benchmarks, substantially outperforming VLM-as-Solver (+0.4) and Best-of-N scaling (+2.2) at comparable test-time cost.
Significance. If the central mechanism holds, the work would represent a meaningful paradigm shift in video reasoning by repurposing VLMs' perceptual strengths for adaptive, gradient-based test-time adaptation rather than static textual guidance. The empirical gains, if reproducible with proper controls, would demonstrate a practical way to extend VGM reasoning boundaries without retraining.
major comments (2)
- [Method / Reward Formulation] The load-bearing step—conversion of VLM outputs into end-to-end differentiable rewards that permit gradient flow to the VGM's LoRA parameters—is not specified. Standard VLMs produce discrete or non-differentiable judgments; without an explicit construction (embedding similarity, soft proxy, auxiliary head, or equivalent) that makes the reward a differentiable function of generated video latents, the claimed test-time optimization loop cannot operate as described. This must be detailed with equations or pseudocode in the method section for the teacher paradigm to be distinct from non-differentiable search.
- [Experiments] §4 (Experiments): The abstract reports a 16.7-point average gain and specific outperformance margins, yet provides no details on experimental controls, error bars, exact reward formulations, data splits, or statistical significance. These omissions prevent verification that the gains support the central claim rather than arising from uncontrolled factors.
minor comments (2)
- [Implementation Details] Clarify the precise VGM architecture, LoRA rank, optimization steps, and learning rate schedule used at test time, as these directly affect the claimed comparable test-time cost.
- [Related Work] Add missing references to prior test-time adaptation or reward-modeling work in video generation to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater clarity on the reward formulation and experimental details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Method / Reward Formulation] The load-bearing step—conversion of VLM outputs into end-to-end differentiable rewards that permit gradient flow to the VGM's LoRA parameters—is not specified. Standard VLMs produce discrete or non-differentiable judgments; without an explicit construction (embedding similarity, soft proxy, auxiliary head, or equivalent) that makes the reward a differentiable function of generated video latents, the claimed test-time optimization loop cannot operate as described. This must be detailed with equations or pseudocode in the method section for the teacher paradigm to be distinct from non-differentiable search.
Authors: We agree that the explicit construction for differentiability is essential and currently underspecified in the manuscript. The high-level description of VLM-derived rewards is present, but the precise mechanism (e.g., embedding cosine similarity or soft proxies) enabling gradient flow to LoRA parameters is not detailed with equations. In the revision we will add a dedicated subsection with equations and pseudocode in the Method section to make this construction explicit and distinguish it from non-differentiable search. revision: yes
-
Referee: [Experiments] §4 (Experiments): The abstract reports a 16.7-point average gain and specific outperformance margins, yet provides no details on experimental controls, error bars, exact reward formulations, data splits, or statistical significance. These omissions prevent verification that the gains support the central claim rather than arising from uncontrolled factors.
Authors: We acknowledge that the current manuscript lacks sufficient experimental controls and reporting details. In the revised version we will expand §4 to include error bars across multiple runs, exact reward formulations, data split specifications, and statistical significance tests to substantiate the reported gains. revision: yes
Circularity Check
No significant circularity; empirical procedure with external benchmarks
full rationale
The paper describes an empirical method that uses VLMs to extract rules and formulate rewards for test-time LoRA optimization on a VGM, evaluated via performance gains on VBVR-Bench and RULER-Bench. No equations, derivations, or self-citation chains are present in the provided text that reduce the reported gains or the reward formulation to quantities defined by the method's own fitted parameters or prior self-referential results. The central claim rests on experimental outcomes rather than a closed definitional or fitted loop, consistent with a standard empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs possess strong perception capabilities to evaluate process-constraint satisfaction and final-goal achievement
Reference graph
Works this paper leans on
-
[1]
Sora: Openai’s text-to-video model,
OpenAI, “Sora: Openai’s text-to-video model,” https://openai. com/index/sora-is-here, 2025, publicly released September 2025
2025
-
[2]
Seedance 2.0: Advancing Video Generation for World Complexity
T. Seedance, D. Chen, L. Chen, X. Chen, Y . Chen, Z. Chen, Z. Chen, F. Cheng, T. Cheng, Y . Chenget al., “Seedance 2.0: Advancing video generation for world complexity,”arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Wan: Open and Advanced Large-Scale Video Generative Models
WanTeam, “Wan: Open and advanced large-scale video generative models,”arXiv preprint arXiv:2503.20314, 2025. [Online]. Available: https://arxiv.org/abs/2503.20314
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
J. Tong, Y . Mou, H. Li, M. Li, Y . Yang, M. Zhang, Q. Chenet al., “Thinking with video: Video generation as a promising multi- modal reasoning paradigm,”arXiv preprint arXiv:2511.04570, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Are video models ready as zero-shot reasoners? an empirical study with the MME-CoF benchmark,
Z. Guo, X. Chen, R. Zhang, R. An, Y . Qi, D. Jiang, X. Li, M. Zhang, H. Li, and P.-A. Heng, “Are video models ready as zero-shot reasoners? an empirical study with the MME-CoF benchmark,”arXiv preprint arXiv:2510.26802, 2025. [Online]. Available: https://arxiv.org/abs/2510.26802
-
[7]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
C. M. Bishop and N. M. Nasrabadi,Pattern recognition and machine learning. Springer, 2006, vol. 4, no. 4
2006
-
[9]
Video models reason early: Exploiting plan commitment for maze solving,
K. Newman, T. Zhu, and O. Russakovsky, “Video models reason early: Exploiting plan commitment for maze solving,”arXiv preprint arXiv:2603.30043, 2026
-
[10]
CollabVR: Collaborative Video Reasoning with Vision-Language and Video Generation Models
J. Kim, S. Shin, J. Park, and E. Yang, “Collabvr: Collaborative video reasoning with vision-language and video generation models,”arXiv preprint arXiv:2605.08735, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Available: https://arxiv.org/abs/2511.13704
[Online]. Available: https://arxiv.org/abs/2511.13704
-
[13]
Video-as-answer: Predict and generate next video event with joint-grpo,
J. Cheng, L. Hou, X. Tao, and J. Liao, “Video-as-answer: Predict and generate next video event with joint-grpo,”arXiv preprint arXiv:2511.16669, 2025
-
[14]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models.” inInternational Conference on Learning Representations, 2022
2022
-
[15]
A very big video reasoning suite,
M. Wang, R. Wang, J. Lin, R. Ji, T. Wiedemer, Q. Gao, D. Luo, Y . Qian, L. Huang, Z. Honget al., “A very big video reasoning suite,”arXiv preprint arXiv:2602.20159, 2026
-
[17]
Available: https://arxiv.org/abs/2512.02622
[Online]. Available: https://arxiv.org/abs/2512.02622
-
[18]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 6840–6851
2020
-
[19]
Scalable diffusion models with trans- formers,
W. Peebles and S. Xie, “Scalable diffusion models with trans- formers,” inIEEE/CVF International Conference on Computer Vision, 2023, pp. 4195–4205
2023
-
[20]
Motiondiffuse: Text-driven human motion generation with diffusion model,
M. Zhang, Z. Cai, L. Pan, F. Hong, X. Guo, L. Yang, and Z. Liu, “Motiondiffuse: Text-driven human motion generation with diffusion model,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 6, pp. 4115–4128, 2024
2024
-
[21]
Movie Gen: A Cast of Media Foundation Models
A. Polyak, A. Zohar, A. Brown, A. Tjandra, A. Sinha, A. Lee, A. Vyas, B. Shi, C. Ma, C. Chuanget al., “MovieGen: A cast of media foundation models,”arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Veo 3.1,
Google DeepMind, “Veo 3.1,” Google DeepMind, Tech. Rep., 2026, released January 13, 2026. [Online]. Available: https://blog.google/innovation-and-ai/technology/ai/ veo-3-1-ingredients-to-video/
2026
-
[23]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Y . Gao, H. Guo, T. Hoang, W. Huang, L. Jiang, F. Kong, H. Li, J. Li, L. Li, X. Liet al., “Seedance 1.0: Exploring the boundaries of video generation models,”arXiv preprint arXiv:2506.09113, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
T. Seedance, H. Chen, S. Chen, X. Chen, Y . Chen, Y . Chen, Z. Chen, F. Cheng, T. Cheng, X. Chenget al., “Seedance 1.5 pro: A native audio-visual joint generation foundation model,” arXiv preprint arXiv:2512.13507, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Fenget al., “CogVideoX: Text-to-video diffusion models with an expert transformer,”arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhanget al., “HunyuanVideo: A systematic framework for large video generative models,”arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Open-Sora: Democratizing Efficient Video Production for All
Z. Zheng, X. Peng, T. Yang, C. Shen, S. Li, H. Liu, Y . Zhou, T. Li, and Y . You, “Open-SORA: Democratizing efficient video production for all,”arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
VBench++: Comprehen- sive and versatile benchmark suite for video generative models,
Z. Huang, F. Zhang, X. Xu, Y . He, J. Yu, Z. Dong, Q. Ma, N. Chanpaisit, C. Si, Y . Jiang, Y . Wang, X. Chen, Y . Chen, L. Wang, D. Lin, Y . Qiao, and Z. Liu, “VBench++: Comprehen- sive and versatile benchmark suite for video generative models,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 3, pp. 3268–3285, 2026
2026
-
[29]
Cosmos World Foundation Model Platform for Physical AI
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Dinget al., “Cosmos world foundation model platform for physical ai,”arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
X. Zhang, J. Liao, S. Zhang, F. Meng, X. Wan, J. Yan, and Y . Cheng, “Videorepa: Learning physics for video generation through relational alignment with foundation models,”arXiv preprint arXiv:2505.23656, 2025
-
[31]
J. Wang, A. Ma, K. Cao, J. Zheng, Z. Zhang, J. Feng, S. Liu, Y . Ma, B. Cheng, D. Lenget al., “Wisa: World simulator assistant for physics-aware text-to-video generation,”arXiv preprint arXiv:2503.08153, 2025
-
[32]
Towards physical understanding in video generation: A 3d point regularization approach,
Y . Chen, J. Cao, A. Kag, V . Goel, S. Korolev, C. Jiang, S. Tulyakov, and J. Ren, “Towards physical understanding in video generation: A 3d point regularization approach,”arXiv preprint arXiv:2502.03639, 2025
-
[33]
Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video gen- TECHNICAL REPORT 13 eration,
Q. Xue, X. Yin, B. Yang, and W. Gao, “Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video gen- TECHNICAL REPORT 13 eration,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[34]
Physdreamer: Physics-based interaction with 3d objects via video generation,
T. Zhang, H.-X. Yu, R. Wu, B. Y . Feng, C. Zheng, N. Snavely, J. Wu, and W. T. Freeman, “Physdreamer: Physics-based interaction with 3d objects via video generation,” inEuropean Conference on Computer Vision, 2024
2024
-
[35]
Physgen: Rigid- body physics-grounded image-to-video generation,
S. Liu, Z. Ren, S. Gupta, and S. Wang, “Physgen: Rigid- body physics-grounded image-to-video generation,” inEuropean Conference on Computer Vision, 2024
2024
-
[36]
Flip: Flow- centric generative planning as general-purpose manipulation world model,
C. Gao, H. Zhang, Z. Xu, Z. Cai, and L. Shao, “Flip: Flow- centric generative planning as general-purpose manipulation world model,”arXiv preprint arXiv:2412.08261, 2024
-
[37]
Physanimator: Physics- guided generative cartoon animation,
T. Xie, Y . Zhao, Y . Jiang, and C. Jiang, “Physanimator: Physics- guided generative cartoon animation,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[38]
Motioncraft: Physics-based zero-shot video genera- tion,
A. Montanaro, L. Savant Aira, E. Aiello, D. Valsesia, and E. Magli, “Motioncraft: Physics-based zero-shot video genera- tion,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[39]
ProPhy: Progressive Physical Alignment for Dynamic World Simulation
Z. Wang, P. Hu, J. Wang, T. J. Zhang, Y . Cheng, L. Chen, Y . Yan, Z. Jiang, H. Li, and X. Liang, “Prophy: Progressive physical alignment for dynamic world simulation,”arXiv preprint arXiv:2512.05564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
MagicTime: Time-lapse video generation models as metamorphic simulators,
S. Yuan, J. Huang, Y . Shi, Y . Xu, R. Zhu, B. Lin, X. Cheng, L. Yuan, and J. Luo, “MagicTime: Time-lapse video generation models as metamorphic simulators,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 9, pp. 7340–7351, 2025
2025
-
[41]
Can world simulators reason? Gen-ViRe: A generative visual reasoning benchmark,
X. Liu, Z. Xu, M. Li, K. Wang, Y . J. Lee, and Y . Shang, “Can world simulators reason? Gen-ViRe: A generative visual reasoning benchmark,”arXiv preprint arXiv:2511.13853, 2025. [Online]. Available: https://arxiv.org/abs/2511.13853
-
[42]
Video models are zero-shot learners and reasoners
T. Wiedemer, Y . Li, P. Vicol, S. S. Gu, N. Matarese, K. Swersky, B. Kim, P. Jaini, and R. Geirhos, “Video models are zero-shot learners and reasoners,”arXiv preprint arXiv:2509.20328, 2025. [Online]. Available: https://arxiv.org/abs/2509.20328
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 24 824–24 837
2022
-
[44]
Mme-cof-pro: Evaluating reasoning coherence in video generative models with text and visual hints,
Y . Qi, X. Xu, Z. Guo, S. Ma, R. Zhang, X. Chen, R. An, R. Xing, J. Zhang, H. Huanget al., “Mme-cof-pro: Evaluating reasoning coherence in video generative models with text and visual hints,” arXiv preprint arXiv:2603.20194, 2026
-
[45]
R. Wang, Z. Cai, F. Pu, J. Xu, W. Yinet al., “Demystifying video reasoning,”arXiv preprint arXiv:2603.16870, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
C. Yang, H. Wan, Y . Peng, X. Cheng, Z. Yu, J. Zhang, J. Yu, X. Yu, X. Zheng, D. Zhou, and C. Wu, “Reasoning via video: The first evaluation of video models’ reasoning abilities through maze-solving tasks,”arXiv preprint arXiv:2511.15065, 2025. [Online]. Available: https://arxiv.org/abs/2511.15065
-
[47]
MMGR: Multi-modal generative reasoning,
Z. Cai, H. Qiu, T. Ma, H. Zhao, G. Zhou, K.-H. Huang, P. Kordjamshidi, M. Zhang, W. Xiao, J. Gu, N. Peng, and J. Hu, “MMGR: Multi-modal generative reasoning,” arXiv preprint arXiv:2512.14691, 2025. [Online]. Available: https://arxiv.org/abs/2512.14691
-
[48]
V-reasonbench: Toward unified reasoning benchmark suite for video generation models,
Y . Luo, X. Zhao, B. Lin, L. Zhu, L. Tang, Y . Liu, Y .-C. Chen, S. Qian, X. Wang, and Y . You, “V-reasonbench: Toward unified reasoning benchmark suite for video generation models,” arXiv preprint arXiv:2511.16668, 2025. [Online]. Available: https://arxiv.org/abs/2511.16668
-
[49]
Ui2v-bench: An understanding- based image-to-video generation benchmark,
A. Zhang, L. Lei, D. Kong, Z. Wang, J. Xu, F. Song, C.-L. Guo, C. Liu, F. Li, and J. Chen, “Ui2v-bench: An understanding- based image-to-video generation benchmark,”arXiv preprint arXiv:2509.24427, 2025
-
[50]
How Far Are Video Models from True Multimodal Reasoning?
X. Zhang, J. Wei, Y . Wang, J. Tan, Y . Li, Y . Zhang, Z. Chen, D. Zhang, D. Yu, W. Xuet al., “How far are video models from true multimodal reasoning?”arXiv preprint arXiv:2604.19193, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling LLM test-time compute optimally can be more effective than scaling model parameters,”arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
B. Brown, J. Juravsky, R. Ehrlich, R. Clark, Q. V . Le, C. R´e, and A. Mirhoseini, “Large language monkeys: Scaling inference com- pute with repeated sampling,”arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Inference-time scaling for diffusion models beyond scaling denoising steps,
N. Ma, S. Tong, H. Jia, H. Hu, Y .-C. Su, M. Zhang, X. Yang, Y . Li, T. Jaakkola, X. Jia, and S. Xie, “Inference-time scaling for diffusion models beyond scaling denoising steps,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[54]
Video-t1: Test-time scaling for video generation,
F. Liu, H. Wang, Y . Cai, K. Zhang, X. Zhan, and Y . Duan, “Video-t1: Test-time scaling for video generation,” inIEEE/CVF International Conference on Computer Vision, 2025
2025
-
[55]
Scaling image and video generation via test-time evolutionary search,
H. He, J. Liang, X. Wang, P. Wan, D. Zhang, K. Gai, and L. Pan, “Scaling image and video generation via test-time evolutionary search,”arXiv preprint arXiv:2505.17618, 2025
-
[56]
Can test-time scaling improve world foundation model?
W. Cong, H. Zhu, P. Wang, B. Liu, D. Xu, K. Wang, D. Z. Pan, Y . Wang, Z. Fan, and Z. Wang, “Can test-time scaling improve world foundation model?” inConference on Language Modeling, 2025
2025
-
[57]
Thinking in frames: How visual context and test-time scaling empower video reasoning,
C. Li, Z. Wang, J. Li, Y . Xu, H. Zhouet al., “Thinking in frames: How visual context and test-time scaling empower video reasoning,”arXiv preprint arXiv:2601.21037, 2026
-
[58]
S. Jang, T. Ki, J. Jo, S. Xie, J. Yoon, and S. J. Hwang, “Self- refining video sampling,”arXiv preprint arXiv:2601.18577, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
Vision-language models for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5625– 5644, 2024
2024
-
[60]
Otter: A multi-modal model with in-context instruction tuning,
B. Li, Y . Zhang, L. Chen, J. Wang, F. Pu, J. A. Cahyono, J. Yang, C. Li, and Z. Liu, “Otter: A multi-modal model with in-context instruction tuning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 9, pp. 7543–7557, 2025
2025
-
[61]
Cross-modal causal relational reasoning for event-level visual question answering,
Y . Liu, G. Li, and L. Lin, “Cross-modal causal relational reasoning for event-level visual question answering,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 10, pp. 11 624–11 641, 2023
2023
-
[62]
Language-aware spatial-temporal collaboration for referring video segmentation,
T. Hui, S. Liu, Z. Ding, S. Huang, G. Li, W. Wang, L. Liu, and J. Han, “Language-aware spatial-temporal collaboration for referring video segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 7, pp. 8646–8659, 2023
2023
-
[63]
Video-Holmes: Can MLLM Think Like Holmes for Complex Video Reasoning?
J. Cheng, Y . Ge, T. Wang, Y . Ge, J. Liao, and Y . Shan, “Video-holmes: Can mllm think like holmes for complex video reasoning?”arXiv preprint arXiv:2505.21374, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Grpo-care: Consistency-aware reinforcement learning for multimodal reasoning,
Y . Chen, Y . Ge, R. Wang, Y . Ge, J. Cheng, Y . Shan, and X. Liu, “Grpo-care: Consistency-aware reinforcement learning for multimodal reasoning,”arXiv preprint arXiv:2506.16141, 2025
-
[65]
Self-correcting llm-controlled diffusion models,
T.-H. Wu, L. Lian, J. E. Gonzalez, B. Li, and T. Darrell, “Self-correcting llm-controlled diffusion models,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[66]
Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms,
L. Yang, Z. Yu, C. Meng, M. Xu, S. Ermon, and B. Cui, “Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms,” inInternational Conference on Machine Learning, 2024
2024
-
[67]
Mindomni: Unleashing reasoning generation in vision language models with rgpo,
Y . Xiao, L. Song, Y . Chen, Y . Luo, Y . Chen, Y . Gan, W. Huang, X. Li, X. Qi, and Y . Shan, “Mindomni: Unleashing reasoning generation in vision language models with rgpo,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[68]
Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning,
H. Lin, A. Zala, J. Cho, and M. Bansal, “Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning,” inConference on Language Modeling, 2024
2024
-
[69]
Vlipp: Towards physically plausible video generation with vision and language informed physical prior,
X. Yang, B. Li, Y . Zhang, Z. Yin, L. Bai, L. Ma, Z. Wang, J. Cai, T.-T. Wong, H. Lu, and X. Jia, “Vlipp: Towards physically plausible video generation with vision and language informed physical prior,” inIEEE/CVF International Conference on Computer Vision, 2025, pp. 12 360–12 370. TECHNICAL REPORT 14
2025
-
[70]
Videoagent: Long-form video understanding with large language model as agent,
X. Wang, Y . Zhang, O. Zohar, and S. Yeung-Levy, “Videoagent: Long-form video understanding with large language model as agent,” inEuropean Conference on Computer Vision, 2024
2024
-
[71]
VChain: Chain-of-Visual-Thought for Reasoning in Video Generation
Z. Huang, N. Yu, G. Chenet al., “VChain: Chain-of-visual- thought for reasoning in video generation,”arXiv preprint arXiv:2510.05094, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Video Models Can Reason with Verifiable Rewards
T. Zhu, S. Zhang, J. Y . Huang, S. Song, X. Wen, Y . Li, H. Poon, and M. Chen, “Video models can reason with verifiable rewards,” arXiv preprint arXiv:2605.15458, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[73]
Dual-process image generation,
G. Luo, J. Granskog, A. Holynski, and T. Darrell, “Dual-process image generation,” inIEEE/CVF International Conference on Computer Vision, 2025, pp. 17 972–17 983
2025
-
[74]
Learning an Image Editing Model without Image Editing Pairs
N. Kumari, S.-Y . Wang, N. Zhao, Y . Nitzan, Y . Li, K. K. Singh, R. Zhang, E. Shechtman, J.-Y . Zhu, and X. Huang, “Learning an image editing model without image editing pairs,”arXiv preprint arXiv:2510.14978, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Diffusion-drf: Differentiable reward flow for video diffusion fine-tuning,
Y . Wang, Y . Li, S. Tulyakov, Y . Fu, and A. Kag, “Diffusion-drf: Differentiable reward flow for video diffusion fine-tuning,”arXiv preprint arXiv:2601.04153, 2026
-
[76]
Lightx2v: Light video generation inference framework,
L. Contributors, “Lightx2v: Light video generation inference framework,” https://github.com/ModelTC/lightx2v, 2025
2025
-
[77]
Improved distribution matching distillation for fast image synthesis,
T. Yin, M. Gharbi, T. Park, R. Zhang, E. Shechtman, F. Durand, and W. T. Freeman, “Improved distribution matching distillation for fast image synthesis,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[78]
Openai o3 and o4-mini system card,
OpenAI, “Openai o3 and o4-mini system card,” OpenAI, Tech. Rep., Apr. 2025
2025
-
[79]
Kling AI launches video 2.6 model with “simultaneous audio-visual generation
Kuaishou Technology, “Kling AI launches video 2.6 model with “simultaneous audio-visual generation” capability, redefining AI video creation workflow,” Press Release, Kuaishou Technology, Dec. 2025, model released December 3, 2025. Press release published December 5, 2025
2025
-
[80]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Geet al., “Qwen3-vl technical report,” arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[81]
Flow-grpo: Training flow matching models via online rl,
J. Liu, G. Liu, J. Liang, Y . Li, J. Liu, X. Wang, P. Wan, D. Zhang, and W. Ouyang, “Flow-grpo: Training flow matching models via online rl,” inAdvances in Neural Information Processing Systems, 2025
2025
-
[82]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis,
C. Fu, Y . Dai, Y . Luo, L. Li, S. Ren, R. Zhang, Z. Wang, C. Zhou, Y . Shen, M. Zhanget al., “Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 24 108–24 118
2025
-
[83]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
J. Zhu, W. Wang, Z. Chen, Z. Liu, S. Ye, L. Gu, H. Tian, Y . Duan, W. Su, J. Shaoet al., “Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models,”arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.