FlowR2A: Learning Reward-to-Action Distribution for Multimodal Driving Planning
Pith reviewed 2026-06-26 00:16 UTC · model grok-4.3
The pith
FlowR2A learns reward-conditioned action distributions with a flow-matching decoder to unify dense supervision and dynamic proposal generation for multimodal driving planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
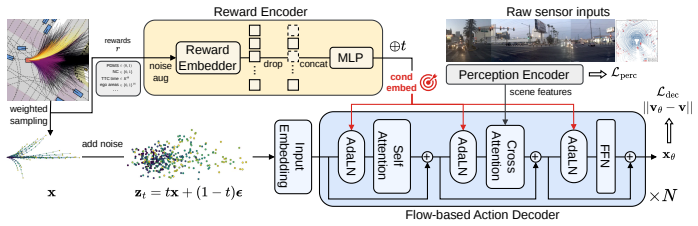
By learning the reward-conditioned action distribution from dense trajectory-reward pairs with a flow-matching decoder, FlowR2A unifies the dense supervision of scoring-based methods with the proposal generation of anchor-based methods in a single generative model, forcing the model to internalize the correlation between an action and its outcomes in safety, progress, comfort, and rule compliance.
What carries the argument
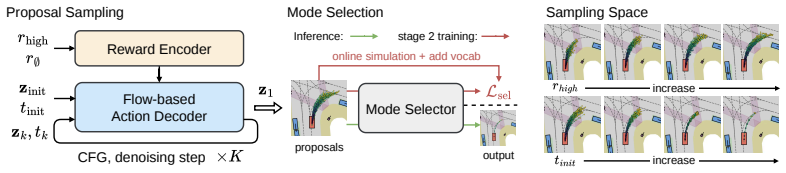
A flow-matching decoder that learns the full reward-to-action distribution from dense trajectory-reward pairs and supports controllable sampling via per-timestep reward conditioning.
If this is right
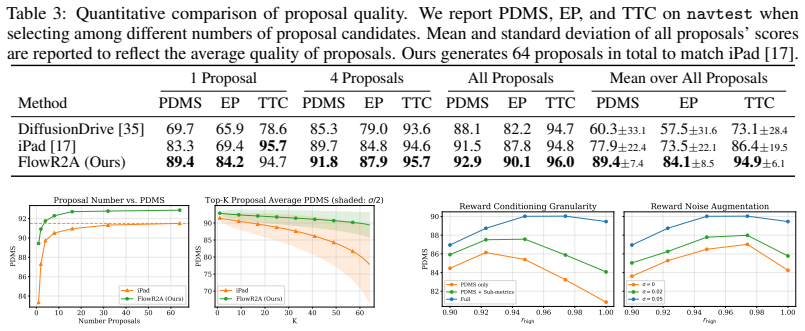
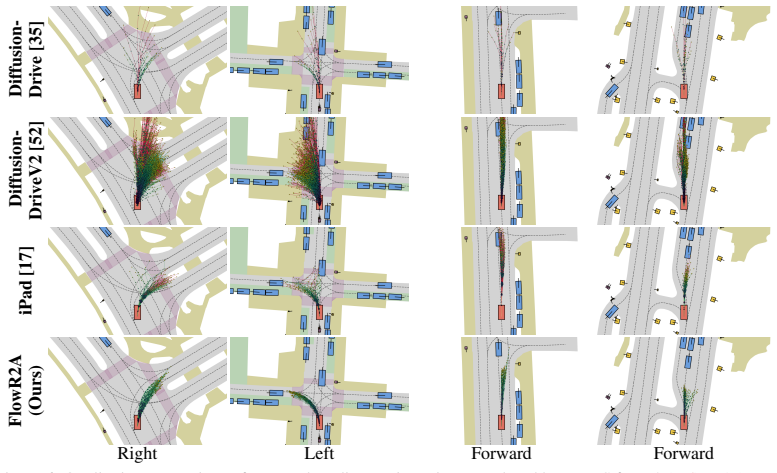
- The generative model produces multimodal proposals of higher quality than prior scoring or anchor baselines on NAVSIM v1 and v2.
- Reward guidance and anchored sampling at test time allow controllable trade-offs between safety and progress without retraining.
- Action-outcome correlations in safety, progress, comfort, and rules are internalized inside one decoder rather than split across separate modules.
- The approach removes the need for a fixed action vocabulary while retaining dense reward supervision.
Where Pith is reading between the lines
- The same reward-to-action formulation could be tested on other robotics tasks that already produce dense trajectory evaluations.
- If the internalized correlations prove stable, separate safety filters or post-processing steps might become unnecessary in deployed planners.
- Distribution-shift experiments on real sensor data would reveal whether the learned mapping transfers beyond simulation rewards.
- Closing the loop by feeding the generated proposals back into reward computation could create an iterative refinement process.
Load-bearing premise
Fine-grained per-timestep reward conditioning together with reward noise augmentation suffices to balance hard safety constraints against soft progress objectives while letting the decoder internalize action-outcome correlations.
What would settle it
A controlled test on NAVSIM scenarios where strong safety penalties directly oppose progress rewards, checking whether the generated proposals remain collision-free at the claimed rate or degrade when noise augmentation is removed.
Figures





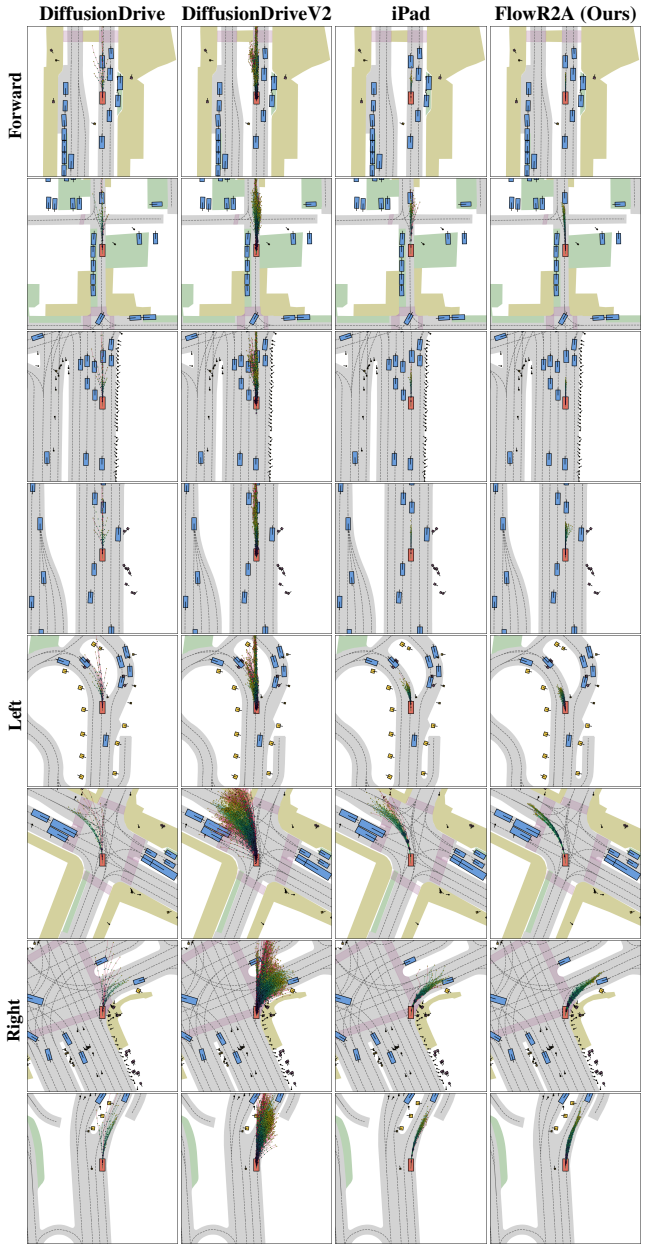
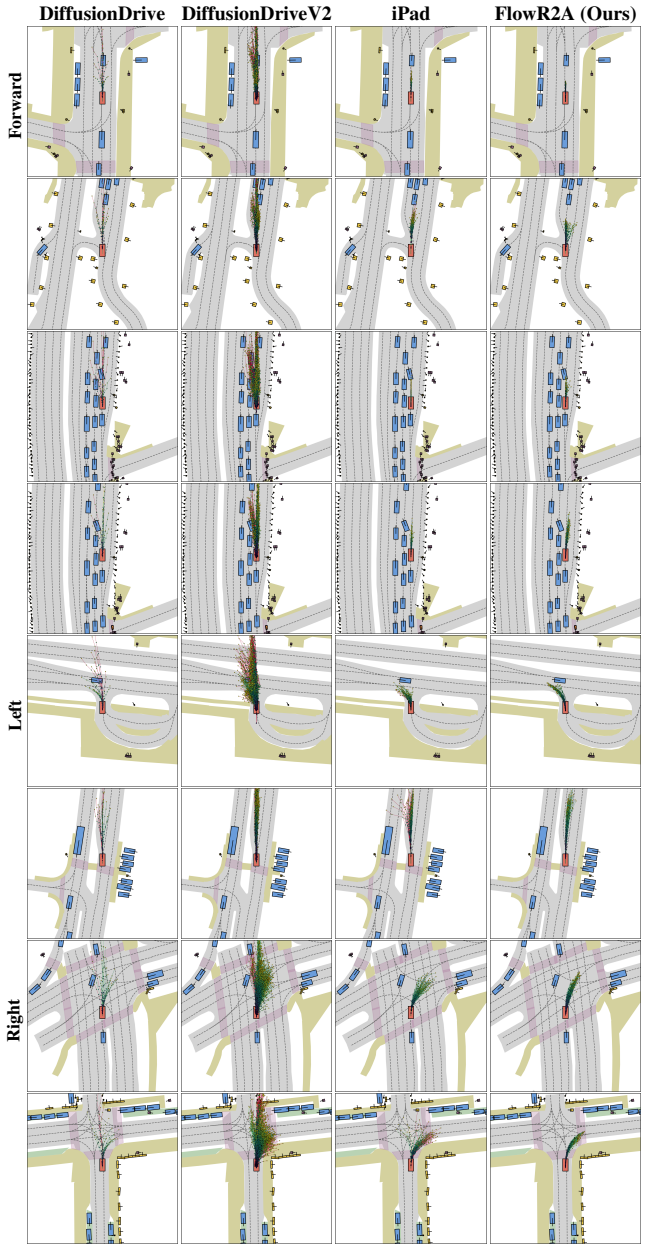
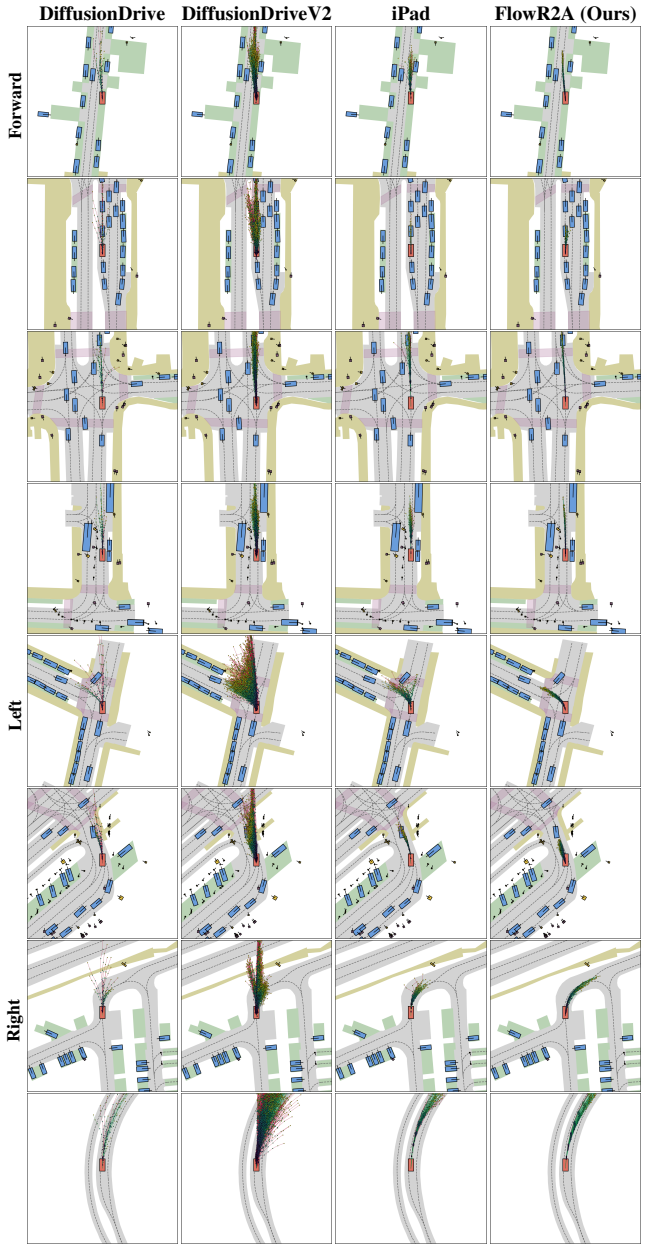
read the original abstract
Multimodal driving planning faces a long-standing tension between two paradigms: scoring-based methods benefit from dense reward supervision but are confined to a fixed action vocabulary, while anchor-based methods generate proposals dynamically yet suffer from sparse supervision constrained to a single ground-truth trajectory. In this work, we propose FlowR2A, which resolves this tension by reframing simulation-based rewards from discriminative targets into generative conditions. By learning the reward-conditioned action distribution from dense trajectory-reward pairs with a flow-matching decoder, FlowR2A unifies the dense supervision of scoring-based methods with the proposal generation of anchor-based methods in a single generative model, forcing the model to internalize the correlation between an action and its outcomes in safety, progress, comfort, and rule compliance. To balance hard safety constraints against soft progress objectives, we introduce fine-grained per-timestep reward conditioning and reward noise augmentation. The generative formulation naturally supports controllable test-time sampling via reward guidance and anchored sampling, producing high-quality proposals. FlowR2A achieves state-of-the-art results on the NAVSIM v1 and v2 benchmarks, with multimodal proposals of substantially higher quality than prior methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FlowR2A, a generative model that reframes simulation-based rewards as conditions for a flow-matching decoder trained on dense trajectory-reward pairs. This is claimed to unify the dense supervision of scoring-based planning methods with the dynamic proposal generation of anchor-based methods in a single model for multimodal driving planning. The approach introduces per-timestep reward conditioning and reward noise augmentation to balance hard safety constraints against soft progress objectives, supports controllable test-time sampling, and reports state-of-the-art results on the NAVSIM v1 and v2 benchmarks.
Significance. If the empirical claims and unification hold under full technical scrutiny, the work could meaningfully advance multimodal planning by enabling generative models to internalize action-outcome correlations across safety, progress, comfort, and compliance. The flow-matching formulation with reward guidance offers a coherent mechanism for controllable sampling that prior paradigms lack, potentially influencing reward-conditioned generative approaches in robotics and autonomous systems.
major comments (2)
- [Abstract] Abstract: the central unification claim—that the flow-matching decoder trained on dense pairs internalizes action-outcome correlations while balancing hard vs. soft objectives via per-timestep conditioning and noise augmentation—cannot be evaluated because the abstract supplies no equations, training objective, or derivation showing how the generative formulation avoids reducing to a fitted quantity or self-referential definition.
- [Abstract] Abstract: the SOTA benchmark assertion is presented without reference to ablations, error analysis, or comparison tables; this makes it impossible to assess whether the reported gains are load-bearing for the unification thesis or attributable to implementation details.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the flow-matching loss or conditioning mechanism to allow readers to trace the claimed unification.
Simulated Author's Rebuttal
We thank the referee for their comments. We address each major comment below, clarifying that the abstract provides a high-level summary while the technical details and empirical support appear in the manuscript body.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central unification claim—that the flow-matching decoder trained on dense pairs internalizes action-outcome correlations while balancing hard vs. soft objectives via per-timestep conditioning and noise augmentation—cannot be evaluated because the abstract supplies no equations, training objective, or derivation showing how the generative formulation avoids reducing to a fitted quantity or self-referential definition.
Authors: The abstract is written as a concise overview and does not contain equations, consistent with standard practice for accessibility. The full derivation of the flow-matching decoder, the training objective on dense trajectory-reward pairs, per-timestep reward conditioning, and reward noise augmentation appear in Sections 3.1–3.2. These sections specify the conditional distribution learned by the generative model and show how it internalizes action-outcome correlations across safety, progress, comfort, and compliance without reducing to a fitted scorer. revision: no
-
Referee: [Abstract] Abstract: the SOTA benchmark assertion is presented without reference to ablations, error analysis, or comparison tables; this makes it impossible to assess whether the reported gains are load-bearing for the unification thesis or attributable to implementation details.
Authors: The abstract summarizes the outcome of state-of-the-art results on NAVSIM v1 and v2. The supporting comparison tables, ablations, error analysis, and attribution of gains to the proposed components are provided in Section 4 (Tables 1–4 and Figures 3–5). These elements allow evaluation of whether the empirical results substantiate the unification claim. revision: no
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces FlowR2A as a flow-matching decoder trained on dense trajectory-reward pairs to learn a reward-conditioned action distribution. This is presented as a generative modeling approach that unifies scoring-based and anchor-based paradigms via per-timestep conditioning and noise augmentation. The central claims rest on the standard training of a conditional generative model and empirical SOTA results on NAVSIM benchmarks, without any equations or steps that reduce predictions to fitted inputs by construction, self-definitional mappings, or load-bearing self-citations. The derivation chain is independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Building normalizing flows with stochastic inter- polants
Michael Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic inter- polants. InICLR, 2023
2023
-
[2]
NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles
Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. NuPlan: A closed-loop ML-based planning benchmark for autonomous vehicles. InCVPR workshop, 2021
2021
-
[3]
Pseudo-simulation for autonomous driving
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, et al. Pseudo-simulation for autonomous driving. InCoRL, 2025
2025
-
[4]
Decision Transformer: Reinforcement learning via sequence modeling.NeurIPS, 2021
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision Transformer: Reinforcement learning via sequence modeling.NeurIPS, 2021
2021
-
[5]
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. V ADv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243, 2024
Pith/arXiv arXiv 2024
-
[6]
PPAD: Iterative interactions of prediction and planning for end-to-end autonomous driving
Zhili Chen, Maosheng Ye, Shuangjie Xu, Tongyi Cao, and Qifeng Chen. PPAD: Iterative interactions of prediction and planning for end-to-end autonomous driving. InECCV, 2024
2024
-
[7]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
2022
-
[8]
OpenScene: The largest up-to-date 3D occupancy prediction bench- mark in autonomous driving.https://github.com/OpenDriveLab/OpenScene, 2023
OpenScene Contributors. OpenScene: The largest up-to-date 3D occupancy prediction bench- mark in autonomous driving.https://github.com/OpenDriveLab/OpenScene, 2023
2023
-
[9]
Parting with miscon- ceptions about learning-based vehicle motion planning
Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with miscon- ceptions about learning-based vehicle motion planning. InCoRL, 2023
2023
-
[10]
NA VSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking.NeurIPS, 2024
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. NA VSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking.NeurIPS, 2024
2024
-
[11]
RvS: What is essential for offline RL via supervised learning? InICLR, 2022
Scott Emmons, Benjamin Eysenbach, Ilya Kostrikov, and Sergey Levine. RvS: What is essential for offline RL via supervised learning? InICLR, 2022
2022
-
[12]
Scaling rectified flow transform- ers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis. InICML, 2024
2024
-
[13]
impensis Academiae imperialis scientiarum, 1792
Leonhard Euler.Institutiones calculi integralis. impensis Academiae imperialis scientiarum, 1792
-
[14]
ARTEMIS: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving.IEEE Robotics and Automation Letters, 2025
Renju Feng, Ning Xi, Duanfeng Chu, Rukang Wang, Zejian Deng, Anzheng Wang, Liping Lu, Jinxiang Wang, and Yanjun Huang. ARTEMIS: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving.IEEE Robotics and Automation Letters, 2025
2025
-
[15]
Kevin Frans, Seohong Park, Pieter Abbeel, and Sergey Levine. Diffusion guidance is a controllable policy improvement operator.arXiv preprint arXiv:2505.23458, 2025
arXiv 2025
-
[16]
Learning to reach goals via iterated supervised learning
Dibya Ghosh, Abhishek Gupta, Ashwin Reddy, Justin Fu, Coline Devin, Benjamin Eysenbach, and Sergey Levine. Learning to reach goals via iterated supervised learning. InICLR, 2021
2021
-
[17]
iPad: Iterative proposal-centric end-to-end autonomous driving.arXiv preprint arXiv:2505.15111, 2025
Ke Guo, Haochen Liu, Xiaojun Wu, Jia Pan, and Chen Lv. iPad: Iterative proposal-centric end-to-end autonomous driving.arXiv preprint arXiv:2505.15111, 2025
arXiv 2025
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InCVPR, 2016. 10
2016
-
[19]
Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
Pith/arXiv arXiv 2022
-
[20]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InCVPR, 2023
2023
-
[21]
Planning with diffusion for flexible behavior synthesis
Michael Janner, Yilun Du, Joshua Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. InICML, 2022
2022
-
[22]
V AD: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. V AD: Vectorized scene representation for efficient autonomous driving. InICCV, 2023
2023
-
[23]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InCVPR, 2019
2019
-
[24]
Driving on registers
Ellington Kirby, Alexandre Boulch, Yihong Xu, Yuan Yin, Gilles Puy, Éloi Zablocki, Andrei Bursuc, Spyros Gidaris, Renaud Marlet, Florent Bartoccioni, et al. Driving on registers. In CVPR, 2026
2026
-
[25]
Reward-conditioned policies.arXiv preprint arXiv:1912.13465, 2019
Aviral Kumar, Xue Bin Peng, and Sergey Levine. Reward-conditioned policies.arXiv preprint arXiv:1912.13465, 2019
arXiv 1912
-
[26]
An energy and GPU-computation efficient backbone network for real-time object detection
Youngwan Lee, Joong-won Hwang, Sangrok Lee, Yuseok Bae, and Jongyoul Park. An energy and GPU-computation efficient backbone network for real-time object detection. InCVPR workshop, 2019
2019
-
[27]
Jingyu Li, Junjie Wu, Dongnan Hu, Xiangkai Huang, Bin Sun, Zhihui Hao, Xianpeng Lang, Xiatian Zhu, and Li Zhang. Sgdrive: Scene-to-goal hierarchical world cognition for autonomous driving.arXiv preprint arXiv:2601.05640, 2026
arXiv 2026
-
[28]
Kailin Li, Zhenxin Li, Shiyi Lan, Yuan Xie, Zhizhong Zhang, Jiayi Liu, Zuxuan Wu, Zhiding Yu, and Jose M Alvarez. Hydra-MDP++: Advancing end-to-end driving via expert-guided hydra-distillation.arXiv preprint arXiv:2503.12820, 2025
arXiv 2025
-
[29]
Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
Pith/arXiv arXiv 2025
-
[30]
Enhancing end-to-end autonomous driving with latent world model
Yingyan Li, Lue Fan, Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang, and Tieniu Tan. Enhancing end-to-end autonomous driving with latent world model. InICLR, 2025
2025
-
[31]
End-to-end driving with online trajectory evaluation via BEV world model
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via BEV world model. InICCV, 2025
2025
-
[32]
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-MDP: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
Pith/arXiv arXiv 2024
-
[33]
Zhenxin Li, Wenhao Yao, Zi Wang, Xinglong Sun, Joshua Chen, Nadine Chang, Maying Shen, Zuxuan Wu, Shiyi Lan, and Jose M Alvarez. Generalized trajectory scoring for end-to-end multimodal planning.arXiv preprint arXiv:2506.06664, 2025
arXiv 2025
-
[34]
Is ego status all you need for open-loop end-to-end autonomous driving? InCVPR, 2024
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? InCVPR, 2024
2024
-
[35]
DiffusionDrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. DiffusionDrive: Truncated diffusion model for end-to-end autonomous driving. InCVPR, 2025
2025
-
[36]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[37]
Lin Liu, Guanyi Yu, Ziying Song, Junqiao Li, Caiyan Jia, Feiyang Jia, Peiliang Wu, and Yandan Luo. Beyond imitation: Constraint-aware trajectory generation with flow matching for end-to-end autonomous driving.arXiv preprint arXiv:2510.26292, 2025. 11
arXiv 2025
-
[38]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023
2023
-
[39]
Zhe Liu, Jinghua Hou, Xiaoqing Ye, Jingdong Wang, Hengshuang Zhao, and Xiang Bai. Unilion: Towards unified autonomous driving model with linear group rnns.arXiv preprint arXiv:2511.01768, 2025
arXiv 2025
-
[40]
Drivepi: Spatial-aware 4d mllm for unified autonomous driving understanding, perception, prediction and planning
Zhe Liu, Runhui Huang, Rui Yang, Siming Yan, Zining Wang, Lu Hou, Di Lin, Xiang Bai, and Hengshuang Zhao. Drivepi: Spatial-aware 4d mllm for unified autonomous driving understanding, perception, prediction and planning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3688–3698, 2026
2026
-
[41]
SDEdit: Guided image synthesis and editing with stochastic differential equations
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. SDEdit: Guided image synthesis and editing with stochastic differential equations. In ICLR, 2022
2022
-
[42]
Reward-conditioned reinforcement learning
Michal Nauman, Marek Cygan, and Pieter Abbeel. Reward-conditioned reinforcement learning. arXiv preprint arXiv:2603.05066, 2026
Pith/arXiv arXiv 2026
-
[43]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[44]
FiLM: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. FiLM: Visual reasoning with a general conditioning layer. InAAAI, 2018
2018
-
[45]
Juergen Schmidhuber. Reinforcement learning upside down: Don’t predict rewards–just map them to actions.arXiv preprint arXiv:1912.02875, 2019
arXiv 1912
-
[46]
SparseDrive: End-to-end autonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. SparseDrive: End-to-end autonomous driving via sparse scene representation. InICRA, 2025
2025
-
[47]
PARA-Drive: Parallelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. PARA-Drive: Parallelized architecture for real-time autonomous driving. InCVPR, 2024
2024
-
[48]
GoalFlow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. GoalFlow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InCVPR, 2025
2025
-
[49]
DriveSuprim: Towards precise trajectory selection for end-to-end planning
Wenhao Yao, Zhenxin Li, Shiyi Lan, Zi Wang, Xinglong Sun, Jose M Alvarez, and Zuxuan Wu. DriveSuprim: Towards precise trajectory selection for end-to-end planning. InAAAI, 2026
2026
-
[50]
Chengran Yuan, Zhanqi Zhang, Jiawei Sun, Shuo Sun, Zefan Huang, Christina Dao Wen Lee, Dongen Li, Yuhang Han, Anthony Wong, Keng Peng Tee, et al. DRAMA: An efficient end-to- end motion planner for autonomous driving with Mamba.arXiv preprint arXiv:2408.03601, 2024
arXiv 2024
-
[51]
GenAD: Generative end-to-end autonomous driving
Wenzhao Zheng, Ruiqi Song, Xianda Guo, Chenming Zhang, and Long Chen. GenAD: Generative end-to-end autonomous driving. InECCV, 2024
2024
-
[52]
Jialv Zou, Shaoyu Chen, Bencheng Liao, Zhiyu Zheng, Yuehao Song, Lefei Zhang, Qian Zhang, Wenyu Liu, and Xinggang Wang. DiffusionDriveV2: Reinforcement learning-constrained trun- cated diffusion modeling in end-to-end autonomous driving.arXiv preprint arXiv:2512.07745, 2025. 12 A Limitations and Future Directions Limitations.The quality of the reward-cond...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.