Grammar-Constrained Decoding Can Jailbreak LLMs into Generating Malicious Code
Pith reviewed 2026-06-27 09:13 UTC · model grok-4.3
The pith
Applying a benign code grammar constraint during decoding can jailbreak LLMs into generating malicious code.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
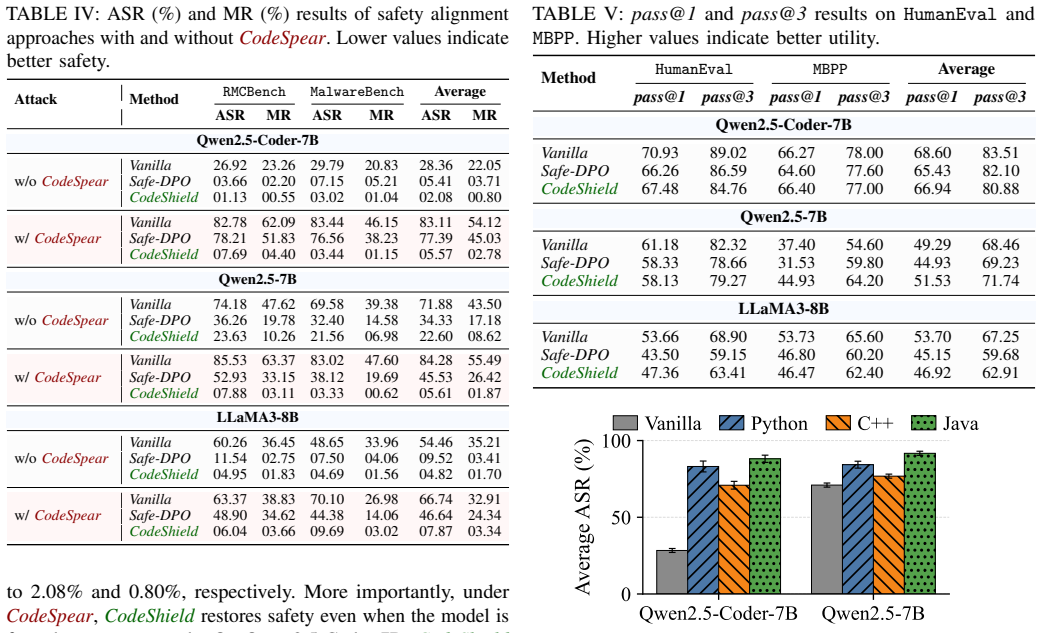
Grammar-constrained decoding can be exploited to jailbreak LLMs because the external grammar overrides the model's refusal behavior even when the grammar itself is syntactically ordinary and benign. The attack CodeSpear works by pairing a malicious request with a grammar that permits only code matching the requested malicious structure, leading to high success rates on popular models. CodeShield counters this by aligning models in the code domain to generate honeypot code under GCD that is harmless yet diverse enough to resist grammar tightening, while still allowing natural-language refusals when no grammar is applied.
What carries the argument
Grammar-Constrained Decoding (GCD), the mechanism that restricts token generation at each step to only those allowed by a supplied grammar, used here to steer output toward malicious yet syntactically valid code.
If this is right
- Standard code grammars can be repurposed by attackers to elicit malicious outputs without elaborate prompt engineering.
- Safety training that depends on the model freely choosing to refuse fails once decoding is externally constrained.
- CodeShield maintains safety under GCD by training the model to output harmless but structurally diverse code.
- The defense preserves utility for benign code requests and natural-language refusals.
- The attack succeeds on ten LLMs across four benchmarks with an average gain of more than thirty percentage points.
Where Pith is reading between the lines
- Any decoding-time constraint mechanism could potentially serve as a jailbreak surface if it bypasses internal safety checks.
- Future work could explore integrating safety rules directly into grammar definitions rather than relying on model behavior alone.
- Similar attacks might generalize to other structured-output tasks such as JSON or API call generation.
- Defenses like CodeShield may need periodic retraining as new grammars or model versions appear.
Load-bearing premise
Safety alignments trained on natural-language refusals continue to function when an attacker supplies an external grammar that dictates the form of the output.
What would settle it
A controlled test in which the same malicious request is given to the model both with and without an attacker-supplied benign code grammar, checking whether the grammar alone is sufficient to produce the malicious code instead of a refusal.
Figures



read the original abstract
Large Language Models (LLMs) are increasingly used for code generation, raising concerns that they may be misused to produce malicious code. Meanwhile, Grammar-Constrained Decoding (GCD) has been widely adopted to improve the reliability of LLM-generated code by enforcing syntactic validity. In this paper, we reveal a counterintuitive risk: this reliability-oriented technique can itself become an attack surface. We uncover a new jailbreak attack, termed CodeSpear, that exploits GCD to induce LLMs into generating malicious code. Our experiments show that simply applying a benign code grammar constraint can effectively jailbreak LLMs. To address this vulnerability, we propose CodeShield, a safety alignment approach that robustly preserves safe behavior even under attacker-controlled grammar constraints. CodeShield aligns the model in the code modality by teaching it to generate honeypot code under GCD. Such code is semantically harmless, so it does not implement the malicious request, and structurally diverse, so it is difficult to suppress through grammar tightening. At the same time, CodeShield still preserves natural-language refusals when natural language is available. Experiments on 10 popular LLMs across 4 benchmarks show that CodeSpear outperforms representative jailbreak baselines and increases the attack success rate by more than 30 percentage points on average. CodeShield also restores safety under CodeSpear while preserving benign utility. Our findings reveal a fundamental risk of GCD and call for greater attention to its potential security implications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Grammar-Constrained Decoding (GCD), a technique for enforcing syntactic validity in LLM code generation, can be exploited as a jailbreak attack (CodeSpear) by applying benign code grammar constraints during decoding; this forces models to output malicious code rather than refusals, yielding >30pp average ASR gains across 10 LLMs and 4 benchmarks. It further proposes CodeShield, an alignment method that trains models to emit semantically harmless yet structurally diverse honeypot code under GCD while retaining natural-language refusals.
Significance. If the results hold, the work identifies a previously unexamined attack surface in GCD, a widely deployed reliability tool, and supplies a practical countermeasure that preserves benign utility. The scale of the evaluation (10 models, 4 benchmarks) and the explicit distinction between benign grammar and malicious semantics strengthen the empirical case.
major comments (2)
- [Abstract] Abstract: the claim of '>30pp ASR gains' and that 'simply applying a benign code grammar constraint can effectively jailbreak LLMs' is presented without any definition of ASR, baseline methods, run statistics, or grammar-construction details, making it impossible to assess whether the data support the central claim.
- [CodeShield section] CodeShield description: the assertion that honeypot code is 'structurally diverse, so it is difficult to suppress through grammar tightening' is load-bearing for the defense claim yet lacks any quantitative measure of structural diversity or ablation showing resistance to grammar tightening.
minor comments (1)
- Define all acronyms (GCD, ASR, etc.) on first use in the body text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address each major comment below with targeted clarifications and proposed revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of '>30pp ASR gains' and that 'simply applying a benign code grammar constraint can effectively jailbreak LLMs' is presented without any definition of ASR, baseline methods, run statistics, or grammar-construction details, making it impossible to assess whether the data support the central claim.
Authors: The abstract is intentionally concise per conference norms, but we agree it can be improved for standalone readability. The full paper defines ASR (Attack Success Rate) explicitly in Section 3.2 as the percentage of cases where the model produces code implementing the malicious intent; baselines are detailed in Section 4.1 (including GCG, PAIR, and others); run statistics (means, std devs over 3 seeds) appear in Section 5 and Appendix C; grammar construction is described in Section 3.1 with examples. We will revise the abstract to add a brief inline definition of ASR and a parenthetical note directing readers to the methods section for baselines and statistics. This addresses the concern without expanding the abstract beyond typical length limits. revision: yes
-
Referee: [CodeShield section] CodeShield description: the assertion that honeypot code is 'structurally diverse, so it is difficult to suppress through grammar tightening' is load-bearing for the defense claim yet lacks any quantitative measure of structural diversity or ablation showing resistance to grammar tightening.
Authors: We acknowledge that the current manuscript supports this claim primarily through the end-to-end experimental results (CodeShield maintains low ASR even under varied grammars) and qualitative examples rather than dedicated quantitative metrics. In revision we will add (1) a quantitative diversity measure (e.g., average tree-edit distance and n-gram overlap across honeypot samples) in Section 6.2 and (2) an ablation study in Appendix D that applies progressively tighter grammar constraints and reports the resulting ASR for CodeShield versus the base model. These additions will provide direct empirical backing for the load-bearing assertion. revision: yes
Circularity Check
No significant circularity; empirical attack/defense evaluation
full rationale
The paper presents an empirical jailbreak attack (CodeSpear) and countermeasure (CodeShield) evaluated on 10 LLMs across 4 benchmarks. No equations, parameter fits, uniqueness theorems, or self-citations appear as load-bearing steps in any derivation chain. The central claim—that a benign grammar constraint under GCD can override refusals—rests on direct experimental measurement of attack success rate rather than any reduction to prior inputs by construction. The proposed defense is likewise validated through separate experiments that preserve utility. This is a standard empirical security paper with no circularity in its argument structure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Beyond static gui agent: Evolving llm-based gui testing via dynamic memory,
M. Chen, Z. Liu, C. Chen, J. Wang, Y . Xue, B. Wu, Y . Huang, L. Wu, and Q. Wang, “Beyond static gui agent: Evolving llm-based gui testing via dynamic memory,” in2025 40th IEEE/ACM International Conference on Automated Software Engineering (ASE), pp. 1603–1615, IEEE, 2025
2025
-
[2]
To see is not to master: Teaching llms to use private libraries for code generation,
Y . Zhang, C. Li, R. Chen, G. Yang, X. Jia, Y . Ren, and J. Li, “To see is not to master: Teaching llms to use private libraries for code generation,”arXiv preprint arXiv:2603.15159, 2026
arXiv 2026
-
[3]
Ai-driven self- evolving software: A promising path toward software automation,
L. Cai, Y . Ren, Y . Zhang, and J. Li, “Ai-driven self- evolving software: A promising path toward software automation,”arXiv preprint arXiv:2510.00591, 2025
arXiv 2025
-
[4]
What papers don’t tell you: Recovering tacit knowledge for automated paper reproduction,
L. Li, R. Wang, H. Song, Y . Mao, T. Zhang, Y . Wang, J. Fan, Y . Zhang, J. Ye, C. Zhang,et al., “What papers don’t tell you: Recovering tacit knowledge for automated paper reproduction,”arXiv preprint arXiv:2603.01801, 2026
arXiv 2026
-
[5]
Davsp: Safety alignment for large vision-language models via deep aligned visual safety prompt,
Y . Zhang, J. Li, L. Cai, and G. Li, “Davsp: Safety alignment for large vision-language models via deep aligned visual safety prompt,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, pp. 38111– 38119, 2026
2026
-
[6]
Diffuguard: How intrinsic safety is lost and found in diffusion large language models,
Z. Li, Z. Nie, Z. Zhou, Y . Liu, Y . Zhang, Y . Cheng, Q. Wen, K. Wang, Y . Guo, and J. Zhang, “Diffuguard: How intrinsic safety is lost and found in diffusion large language models,”arXiv preprint arXiv:2509.24296, 2025
arXiv 2025
-
[7]
Jailbreak open-sourced large language mod- els via enforced decoding,
H. Zhang, Z. Guo, H. Zhu, B. Cao, L. Lin, J. Jia, J. Chen, and D. Wu, “Jailbreak open-sourced large language mod- els via enforced decoding,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 5475–5493, 2024
2024
-
[8]
K. Wang, Z. Li, Z. Zhou, Y . Zhang, Y . Mi, K. Yang, Y . Zhang, J. Dong, Z. Sun, Q. Li,et al., “Omni-safety under cross-modality conflict: Vulnerabilities, dynamics mechanisms and efficient alignment,”arXiv preprint arXiv:2602.10161, 2026
arXiv 2026
-
[9]
Smoke and mirrors: Jailbreaking llm-based code generation via implicit malicious prompts,
S. Ouyang, Y . Qin, B. Lin, L. Chen, X. Mao, and S. Wang, “Smoke and mirrors: Jailbreaking llm-based code generation via implicit malicious prompts,”arXiv preprint arXiv:2503.17953, 2025
arXiv 2025
-
[10]
Redcodeagent: Automatic red-teaming agent against diverse code agents,
C. Guo, C. Xie, Y . Yang, Z. Chen, Z. Lin, X. Davies, Y . Gal, D. Song, and B. Li, “Redcodeagent: Automatic red-teaming agent against diverse code agents,”arXiv preprint arXiv:2510.02609, 2025
arXiv 2025
-
[11]
Mocha: Are code language models robust against multi-turn malicious coding prompts?,
M. Wahed, X. Zhou, K. A. Nguyen, T. Yu, N. Diwan, G. Wang, D. Hakkani-Tür, and I. Lourentzou, “Mocha: Are code language models robust against multi-turn malicious coding prompts?,” 2025
2025
-
[12]
Beyond autoregression: An empirical study of diffusion large language models for code generation,
C. Li, Y . Zhang, J. Li, L. Cai, and G. Li, “Beyond autoregression: An empirical study of diffusion large language models for code generation,”arXiv preprint arXiv:2509.11252, 2025
arXiv 2025
-
[13]
Security attacks on llm-based code completion tools,
W. Cheng, K. Sun, X. Zhang, and W. Wang, “Security attacks on llm-based code completion tools,” inProceed- ings of the AAAI conference on artificial intelligence, vol. 39, pp. 23669–23677, 2025
2025
-
[14]
Packmonitor: Enabling zero package hallucinations through decoding-time monitoring,
X. Liu, Y . Liu, Y . Zhang, J. Li, and S.-M. Hu, “Packmonitor: Enabling zero package hallucinations through decoding-time monitoring,”arXiv preprint arXiv:2602.20717, 2026
arXiv 2026
-
[15]
Xgrammar: Flexible and efficient structured generation engine for large language models,
Y . Dong, C. F. Ruan, Y . Cai, R. Lai, Z. Xu, Y . Zhao, and T. Chen, “Xgrammar: Flexible and efficient structured generation engine for large language models,”arXiv preprint arXiv:2411.15100, 2024
arXiv 2024
-
[16]
Syncode: Llm generation with grammar augmentation,
S. Ugare, T. Suresh, H. Kang, S. Misailovic, and G. Singh, “Syncode: Llm generation with grammar augmentation,” Transactions on Machine Learning Research, 2024
2024
-
[17]
Llguidance,
Microsoft, “Llguidance,” June 2025
2025
-
[18]
Lookahead-then-verify: Reliable constrained decoding for diffusion llms under context-free grammars,
Y . Zhang, Y . Li, Y . Liu, J. Li, X. Jia, Z. Li, and G. Li, “Lookahead-then-verify: Reliable constrained decoding for diffusion llms under context-free grammars,”arXiv preprint arXiv:2602.00612, 2026
arXiv 2026
-
[19]
Using grammar masking to ensure syntactic validity in llm-based mod- eling tasks,
L. Netz, J. Reimer, and B. Rumpe, “Using grammar masking to ensure syntactic validity in llm-based mod- eling tasks,” inProceedings of the ACM/IEEE 27th International Conference on Model Driven Engineering Languages and Systems, pp. 115–122, 2024
2024
-
[20]
Structured decoding in vllm: A gentle introduction
BentoML and Red Hat, “Structured decoding in vllm: A gentle introduction.” https://vllm.ai/blog/ 2025-01-14-struct-decode-intro, Jan. 2025. vLLM Blog. Accessed: 2026-06-02
2025
-
[21]
Structured outputs
SGLang, “Structured outputs.” https://sgl-project.github. io/advanced_features/structured_outputs.html. SGLang Documentation. Accessed: 2026-06-02
2026
-
[22]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram,et al., “Openai gpt-5 system card,”arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[23]
Minimax m2.7: Early echoes of self-evolution
MiniMax, “Minimax m2.7: Early echoes of self-evolution.” https://www.minimax.io/news/minimax-m27-en, 2026. Accessed: 2026-06-03
2026
-
[24]
Qwen2. 5-coder technical report,
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Lu,et al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
Pith/arXiv arXiv 2024
-
[25]
Pku-saferlhf: Towards multi-level safety alignment for llms with human preference,
J. Ji, D. Hong, B. Zhang, B. Chen, J. Dai, B. Zheng, T. A. Qiu, J. Zhou, K. Wang, B. Li,et al., “Pku-saferlhf: Towards multi-level safety alignment for llms with human preference,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 31983–32016, 2025
2025
-
[26]
Safety alignment should be made more than just a few tokens deep,
X. Qi, A. Panda, K. Lyu, X. Ma, S. Roy, A. Beirami, P. Mittal, and P. Henderson, “Safety alignment should be made more than just a few tokens deep,” inInternational Conference on Learning Representations, vol. 2025, pp. 54911–54941, 2025
2025
-
[27]
Y . Mou, X. Zhou, Y . Luo, S. Zhang, and W. Ye, “De- coupling safety into orthogonal subspace: Cost-efficient and performance-preserving alignment for large language models,”arXiv preprint arXiv:2510.09004, 2025
arXiv 2025
-
[28]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Ka- dian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan,et al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[29]
A. Y . Qwen, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Wei,et al., “Qwen2. 5 technical report,”arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
-
[30]
Structured Model Outputs
OpenAI, “Structured Model Outputs.” https://developers. openai.com/api/docs/guides/structured-outputs, 2026. Ac- cessed: 2026-06-02
2026
-
[31]
Structured Outputs
Fireworks AI, “Structured Outputs.” https://docs.fireworks. ai/structured-responses/structured-response-formatting,
-
[32]
Accessed: 2026-06-02
2026
-
[33]
Agentspec: Cus- tomizable runtime enforcement for safe and reliable llm agents,
H. Wang, C. M. Poskitt, and J. Sun, “Agentspec: Cus- tomizable runtime enforcement for safe and reliable llm agents,” inProceedings of the IEEE/ACM International Conference on Software Engineering, ICSE, pp. 12–18, 2026
2026
-
[34]
Exploiting prefix-tree in structured output inter- faces for enhancing jailbreak attacking,
Y . Li, Y . Xiong, J. Zhong, J. Zhang, J. Zhou, and L. Zou, “Exploiting prefix-tree in structured output inter- faces for enhancing jailbreak attacking,”arXiv preprint arXiv:2502.13527, 2025
arXiv 2025
-
[35]
Beyond prompts: Space- time decoupling control-plane jailbreaks in llm structured output,
S. Zhang, J. Zhao, H. Dong, R. Xu, Z. Li, Y . Zhang, S. Li, Y . Wen, C. Xia, Z. Wang,et al., “Beyond prompts: Space- time decoupling control-plane jailbreaks in llm structured output,”arXiv preprint arXiv:2503.24191, 2025
Pith/arXiv arXiv 2025
-
[36]
" do anything now
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “" do anything now": Characterizing and evaluating in- the-wild jailbreak prompts on large language models,” in Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, pp. 1671–1685, 2024
2024
-
[37]
Lockpicking llms: A logit-based jail- break using token-level manipulation,
Y . Li, Y . Liu, Y . Li, L. Shi, G. Deng, S. Chen, and K. Wang, “Lockpicking llms: A logit-based jail- break using token-level manipulation,”arXiv preprint arXiv:2405.13068, 2024
Pith/arXiv arXiv 2024
-
[38]
Boosting jailbreak attack with momentum,
Y . Zhang and Z. Wei, “Boosting jailbreak attack with momentum,” inICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5, IEEE, 2025
2025
-
[39]
Low- resource languages jailbreak gpt-4,
Z.-X. Yong, C. Menghini, and S. H. Bach, “Low- resource languages jailbreak gpt-4,”arXiv preprint arXiv:2310.02446, 2023
Pith/arXiv arXiv 2023
-
[40]
Jailbreaking black box large language models in twenty queries,
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,” in2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pp. 23–42, IEEE, 2025
2025
-
[41]
Emergent misalign- ment: Narrow finetuning can produce broadly misaligned llms,
J. Betley, D. Tan, N. Warncke, A. Sztyber-Betley, X. Bao, M. Soto, N. Labenz, and O. Evans, “Emergent misalign- ment: Narrow finetuning can produce broadly misaligned llms,”arXiv preprint arXiv:2502.17424, 2025
arXiv 2025
-
[42]
Fine-tuning aligned language models compromises safety, even when users do not intend to!,
X. Qi, Y . Zeng, T. Xie, P.-Y . Chen, R. Jia, P. Mittal, and P. Henderson, “Fine-tuning aligned language models compromises safety, even when users do not intend to!,” inInternational Conference on Learning Representations, vol. 2024, pp. 30988–31043, 2024
2024
-
[43]
Juli: Jailbreak large language models by self-introspection,
J. Wang, Z. Hu, and D. Wagner, “Juli: Jailbreak large language models by self-introspection,”arXiv preprint arXiv:2505.11790, 2025
arXiv 2025
-
[44]
Safedpo: A simple approach to direct preference optimization with enhanced safety,
G.-H. Kim, Y . J. Kim, B. Kim, H. Lee, K. Bae, Y . Jang, and M. Lee, “Safedpo: A simple approach to direct preference optimization with enhanced safety,”arXiv preprint arXiv:2505.20065, 2025
arXiv 2025
-
[45]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”Ad- vances in neural information processing systems, vol. 36, pp. 53728–53741, 2023
2023
-
[46]
Opencodeinstruct: A large-scale instruction tuning dataset for code llms,
W. U. Ahmad, A. Ficek, M. Samadi, J. Huang, V . Noroozi, S. Majumdar, and B. Ginsburg, “Opencodeinstruct: A large-scale instruction tuning dataset for code llms,”arXiv preprint arXiv:2504.04030, 2025
arXiv 2025
-
[47]
Safety tax: Safety alignment makes your large reasoning models less reasonable,
T. Huang, S. Hu, F. Ilhan, S. F. Tekin, Z. Yahn, Y . Xu, and L. Liu, “Safety tax: Safety alignment makes your large reasoning models less reasonable,”arXiv preprint arXiv:2503.00555, 2025
arXiv 2025
-
[48]
Minimax m2.5: Built for real-world productiv- ity
MiniMax, “Minimax m2.5: Built for real-world productiv- ity.” https://www.minimax.io/news/minimax-m25, 2026. Accessed: 2026-06-03
2026
-
[49]
gpt-oss-120b & gpt-oss-20b model card,
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Bao,et al., “gpt-oss-120b & gpt-oss-20b model card,”arXiv preprint arXiv:2508.10925, 2025
Pith/arXiv arXiv 2025
-
[50]
Rmcbench: Bench- marking large language models’ resistance to malicious code,
J. Chen, Q. Zhong, Y . Wang, K. Ning, Y . Liu, Z. Xu, Z. Zhao, T. Chen, and Z. Zheng, “Rmcbench: Bench- marking large language models’ resistance to malicious code,” inProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, pp. 995– 1006, 2024
2024
-
[51]
Llms caught in the crossfire: Malware requests and jailbreak challenges,
H. Li, H. Gao, Z. Zhao, Z. Lin, J. Gao, and X. Li, “Llms caught in the crossfire: Malware requests and jailbreak challenges,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 27833–27848, 2025
2025
-
[52]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockman, et al., “Evaluating large language models trained on code,” arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[53]
Program syn- thesis with large language models,
J. Austin, A. Odena, M. Nye,et al., “Program syn- thesis with large language models,”arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[54]
Deepseek-v4: Towards highly efficient million-token context intelligence,
DeepSeek-AI, “Deepseek-v4: Towards highly efficient million-token context intelligence,” 2026
2026
-
[55]
A. Yang, A. Li, B. Yang, ,et al., “Qwen3 technical report,” arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[56]
Llms get lost in multi-turn conversation,
P. Laban, H. Hayashi, Y . Zhou, and J. Neville, “Llms get lost in multi-turn conversation,”arXiv preprint arXiv:2505.06120, 2025
Pith/arXiv arXiv 2025
-
[57]
Goal-aware identification and rectification of misinformation in multi-agent systems,
Z. Li, Y . Mi, Z. Zhou, H. Jiang, G. Zhang, K. Wang, and J. Fang, “Goal-aware identification and rectification of misinformation in multi-agent systems,”arXiv preprint arXiv:2506.00509, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.