AIvaluateXR: An Evaluation Framework for on-Device AI in XR with Benchmarking Results
Pith reviewed 2026-05-23 03:16 UTC · model grok-4.3
The pith
AIvaluateXR applies 3D Pareto optimality to rank optimal LLM and XR device pairs from quality and speed objectives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
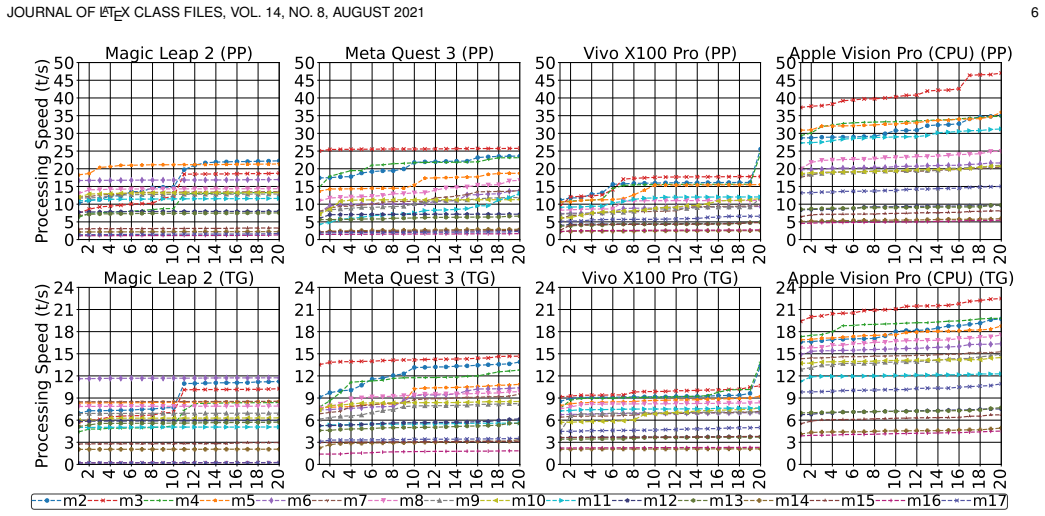
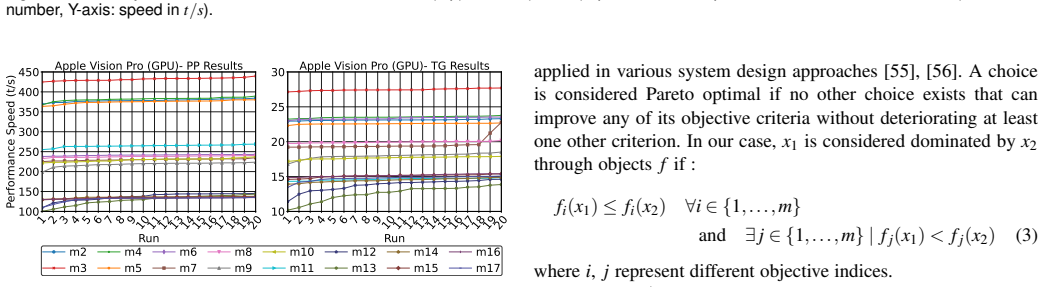
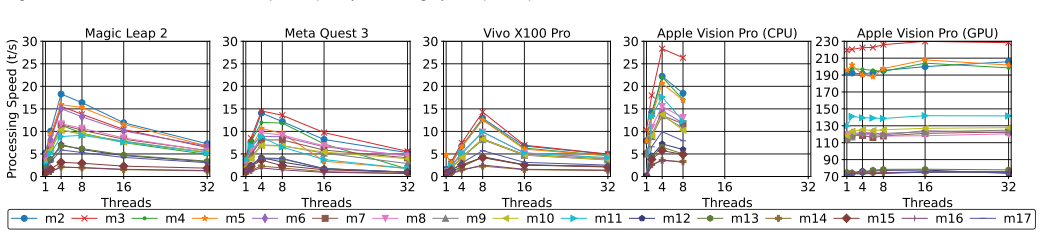
We propose a unified evaluation method based on the 3D Pareto Optimality theory to select the optimal device-model pairs from quality and speed objectives. The framework measures four metrics for each of the 68 model-device pairs and analyzes trade-offs for real-time XR applications, while also comparing on-device performance to client-server and cloud setups and evaluating accuracy on interactive tasks.
What carries the argument
3D Pareto Optimality theory applied to the four metrics of performance consistency, processing speed, memory usage, and battery consumption to rank model-device pairs.
If this is right
- Optimal device-model pairs can be selected for real-time XR applications from the 68 combinations.
- Efficiency of on-device LLMs can be directly compared against client-server and cloud-based setups.
- Accuracy of the models can be assessed on two interactive tasks using the same evaluation setup.
- The method can serve as standard groundwork for further research on LLM deployment on XR devices.
Where Pith is reading between the lines
- The same four-metric approach could be applied to evaluate non-LLM AI models on XR hardware.
- Hardware vendors might use the ranked pairs to target improvements in battery or memory for AI workloads.
- Application developers could adopt the framework to decide when on-device inference meets their latency needs versus offloading.
Load-bearing premise
The four measured metrics are assumed to be sufficient to determine suitability for real-time XR applications.
What would settle it
A test showing that a pair ranked highest by the 3D Pareto method delivers unacceptable latency or instability during live interactive XR use outside the measured conditions.
Figures







read the original abstract
The deployment of large language models (LLMs) on extended reality (XR) devices has great potential to advance the field of human-AI interaction. In the case of direct, on-device model inference, selecting the appropriate model and device for specific tasks remains challenging. In this paper, we present AIvaluateXR, a comprehensive evaluation framework for benchmarking LLMs running on XR devices. To demonstrate the framework, we deploy 17 selected LLMs across four XR platforms: Magic Leap 2, Meta Quest 3, Vivo X100s Pro, and Apple Vision Pro, and conduct an extensive evaluation. Our experimental setup measures four key metrics: performance consistency, processing speed, memory usage, and battery consumption. For each of the 68 model-device pairs, we assess performance under varying string lengths, batch sizes, and thread counts, analyzing the trade-offs for real-time XR applications. We propose a unified evaluation method based on the 3D Pareto Optimality theory to select the optimal device-model pairs from quality and speed objectives. Additionally, we compare the efficiency of on-device LLMs with client-server and cloud-based setups, and evaluate their accuracy on two interactive tasks. We believe our findings offer valuable insight to guide future optimization efforts for LLM deployment on XR devices. Our evaluation method can be used as standard groundwork for further research and development in this emerging field. The source code and supplementary materials are available at: www.nanovis.org/AIvaluateXR.html
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AIvaluateXR, a benchmarking framework for on-device LLMs in XR. It evaluates 17 models across four platforms (Magic Leap 2, Meta Quest 3, Vivo X100s Pro, Apple Vision Pro) using four metrics—performance consistency, processing speed, memory usage, and battery consumption—under varying string lengths, batch sizes, and thread counts. The authors propose a 3D Pareto Optimality method to select optimal device-model pairs from quality and speed objectives, compare on-device inference to client-server and cloud setups, and report accuracy on two interactive tasks. Source code is made available.
Significance. If the 3D Pareto selection method and benchmarking results are robust, the work supplies a practical, open-source framework for identifying suitable on-device LLM configurations for real-time XR, addressing a gap in human-AI interaction tooling. The explicit comparison to non-on-device baselines and the release of code and materials add reproducibility value.
major comments (1)
- [Abstract] Abstract: The central claim of a 'unified evaluation method based on the 3D Pareto Optimality theory to select the optimal device-model pairs from quality and speed objectives' is load-bearing, yet the four reported metrics are exclusively efficiency-oriented while accuracy on the two interactive tasks is described separately. If the Pareto surface is constructed only from the efficiency quartet, the quality objective is not demonstrably represented in the three-dimensional optimality criterion.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of a 'unified evaluation method based on the 3D Pareto Optimality theory to select the optimal device-model pairs from quality and speed objectives' is load-bearing, yet the four reported metrics are exclusively efficiency-oriented while accuracy on the two interactive tasks is described separately. If the Pareto surface is constructed only from the efficiency quartet, the quality objective is not demonstrably represented in the three-dimensional optimality criterion.
Authors: We agree that the abstract phrasing is imprecise and creates the impression that accuracy (task-level quality) is integrated into the 3D Pareto criterion. In the manuscript the Pareto surface is in fact constructed from three efficiency metrics (processing speed, memory usage, battery consumption), with performance consistency used only as a post-filter for stable runs; the two interactive-task accuracy results are reported separately and are not part of the optimality selection. We will revise the abstract (and the corresponding sentence in Section 4) to state that the method selects pairs according to efficiency objectives, while accuracy is evaluated independently. The revision will be incorporated in the next version. revision: yes
Circularity Check
No circularity: empirical benchmarking applies standard Pareto to measured data
full rationale
The paper is an empirical benchmarking study that measures four efficiency metrics across 68 model-device pairs under varying conditions and then applies the established 3D Pareto Optimality concept (a known external mathematical framework) to select pairs based on the observed trade-offs. No equations, fitted parameters, or derivations are presented that reduce any claimed result to its own inputs by construction. Accuracy on interactive tasks is evaluated separately and not folded into any self-referential optimality surface. No self-citations are load-bearing for the central method, and the work remains self-contained against external benchmarks without renaming known results or smuggling ansatzes. This matches the default non-circular outcome for straightforward empirical papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four key metrics (performance consistency, processing speed, memory usage, battery consumption) sufficiently capture trade-offs for real-time XR applications.
Forward citations
Cited by 1 Pith paper
-
ClickAIXR: On-Device Multimodal Vision-Language Interaction with Real-World Objects in Extended Reality
ClickAIXR combines controller-based object selection in XR with on-device VLM inference to enable private, precise multimodal queries about real objects.
Reference graph
Works this paper leans on
-
[1]
When XR and AI meet - a scoping review on extended reality and artificial intelligence,
T. Hirzle, F. M ¨uller, F. Draxler, M. Schmitz, P. Knierim, and K. Hornbæk, “When XR and AI meet - a scoping review on extended reality and artificial intelligence,” in Proc. of the 2023 CHI Conference on Human Factors in Computing Systems, ser. CHI ’23. New York, NY , USA: Association for Computing Machinery, 2023. [Online]. Available: https://doi.org/10...
-
[2]
A review on edge large language models: Design, execution, and applications,
Y . Zheng, Y . Chen, B. Qian, X. Shi, Y . Shu, and J. Chen, “A review on edge large language models: Design, execution, and applications,” ACM Comput. Surv. , vol. 57, no. 8, Mar. 2025. [Online]. Available: https://doi.org/10.1145/3719664
-
[3]
Y . Tang, J. Situ, A. Y . Cui, M. Wu, and Y . Huang, “LLM integration in extended reality: A comprehensive review of current trends, challenges, and future perspectives,” in Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems , ser. CHI ’25. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https:...
-
[4]
Augmented reality and artificial intelligence in industry: Trends, tools, and future challenges,
J. S. Devagiri, S. Paheding, Q. Niyaz, X. Yang, and S. Smith, “Augmented reality and artificial intelligence in industry: Trends, tools, and future challenges,” Expert Systems with Applications , vol. 207, p. 118002, 2022. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0957417422012246
work page 2022
-
[5]
E. Bozkir, S. ¨Ozdel, K. H. C. Lau, M. Wang, H. Gao, and E. Kasneci, “Embedding large language models into extended reality: Opportunities and challenges for inclusion, engagement, and privacy,” in ACM Conference on Conversational User Interfaces , ser. CUI ’24. New York, NY , USA: ACM, 2024. [Online]. Available: https://doi.org/10.1145/3640794.3665563
-
[6]
Everyday AR through AI-in-the-loop,
R. Suzuki, M. Gonzalez-Franco, M. Sra, and D. Lindlbauer, “Everyday AR through AI-in-the-loop,” in Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , ser. CHI EA ’25. New York, NY , USA: Association for Computing Machinery,
-
[7]
Available: https://doi.org/10.1145/3706599.3706741
[Online]. Available: https://doi.org/10.1145/3706599.3706741
-
[8]
A brief overview of ChatGPT: The history, status quo and potential future development,
T. Wu, S. He, J. Liu, S. Sun, K. Liu, Q.-L. Han, and Y . Tang, “A brief overview of ChatGPT: The history, status quo and potential future development,” IEEE/CAA Journal of Automatica Sinica , vol. 10, no. 5, pp. 1122–1136, 2023
work page 2023
-
[9]
A comparison of grammatical error correction models in english writ- ing,
K. Eker, M. K. Pehlivano ˘glu, A. G. Eker, M. A. Syakura, and N. Duru, “A comparison of grammatical error correction models in english writ- ing,” in 2023 8th International Conference on Computer Science and Engineering (UBMK), 2023, pp. 218–223
work page 2023
-
[10]
I. Adeshola and A. P. Adepoju, “The opportunities and challenges of ChatGPT in education,” Interactive Learning Environments , vol. 0, no. 0, pp. 1–14, 2023. [Online]. Available: https: //doi.org/10.1080/10494820.2023.2253858
-
[11]
Investigating code generation performance of ChatGPT with crowd- sourcing social data,
Y . Feng, S. Vanam, M. Cherukupally, W. Zheng, M. Qiu, and H. Chen, “Investigating code generation performance of ChatGPT with crowd- sourcing social data,” in 2023 IEEE 47th Annual Computers, Software, and Applications Conference (COMPSAC), 2023, pp. 876–885
work page 2023
-
[12]
S. Koch, N. Vaskevicius, M. Colosi, P. Hermosilla, and T. Ropinski, “Open3DSG: Open-vocabulary 3D scene graphs from point clouds with queryable objects and open-set relationships,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 14 183–14 193
work page 2024
-
[13]
VOICE: Visual oracle for interac- tion, conversation, and explanation,
D. Jia, A. Irger, L. Besanc ¸on, O. Strnad, D. Luo, J. Bj ¨orklund, A. Kouy- oumdjian, A. Ynnerman, and I. Viola, “VOICE: Visual oracle for interac- tion, conversation, and explanation,” IEEE Transactions on Visualization and Computer Graphics, pp. 1–18, 2025
work page 2025
-
[14]
Chat modeling: Natural language-based procedural modeling of biological structures without training,
D. Jia, Y . Wang, and I. Viola, “Chat modeling: Natural language-based procedural modeling of biological structures without training,” 2024
work page 2024
-
[15]
XaiR: An XR platform that integrates large language models with the physical world,
S. Srinidhi, E. Lu, and A. Rowe, “XaiR: An XR platform that integrates large language models with the physical world,” in IEEE Int. Symposium on Mixed and Augmented Reality (ISMAR) , 2024, pp. 759–767
work page 2024
-
[16]
Mo- bileLLM: Optimizing sub-billion parameter language models for on- device use cases,
Z. Liu, C. Zhao, F. Iandola, C. Lai, Y . Tian, I. Fedorov, Y . Xiong, E. Chang, Y . Shi, R. Krishnamoorthi, L. Lai, and V . Chandra, “Mo- bileLLM: Optimizing sub-billion parameter language models for on- device use cases,” in Proceedings of ICML, 2024, pp. 32 431–32 454
work page 2024
-
[17]
Immersive tailoring of embodied agents using large language models,
A. Bellucci, G. Jacucci, K. D. Trung, P. K. Das, S. V . Smirnov, I. Ahmed, and J.-L. Lugrin, “Immersive tailoring of embodied agents using large language models,” in2025 IEEE Conference Virtual Reality and 3D User Interfaces (VR), 2025, pp. 392–400
work page 2025
-
[18]
J. Chen, X. Wu, T. Lan, and B. Li, “LLMER: Crafting interactive extended reality worlds with json data generated by large language models,” IEEE Transactions on Visualization and Computer Graphics , vol. 31, no. 5, p. 2715–2724, Mar. 2025. [Online]. Available: https://doi.org/10.1109/TVCG.2025.3549549
-
[19]
Next generation XR systems—large language models meet augmented and virtual reality,
M. Z. Afzal, S. A. Ali, D. Stricker, P. Eisert, A. Hilsmann, D. Perez- Marcos, M. Bianchi, S. Crottaz-Herbette, R. De Ioris, E. Mangina, M. Sanguineti, A. Salaberria, O. L. de Lacalle, A. Garc ´ıa-Pablos, and M. Cuadros, “Next generation XR systems—large language models meet augmented and virtual reality,” IEEE Computer Graphics and Applications, vol. 45,...
work page 2025
-
[20]
Teachers’ vocal expressions and student engagement in asynchronous video learning,
H. Gao, Y . Xie, and E. K. and, “PerVRML: ChatGPT-driven personalized VR environments for machine learning education,”International Journal of Human–Computer Interaction, vol. 0, no. 0, pp. 1–15, 2025. [Online]. Available: https://doi.org/10.1080/10447318.2025.2504188
-
[21]
Building llm-based AI agents in social virtual reality,
H. Wan, J. Zhang, A. A. Suria, B. Yao, D. Wang, Y . Coady, and M. Prpa, “Building llm-based AI agents in social virtual reality,” in Extended Abstracts of the CHI Conference on Human Factors in Computing Systems , ser. CHI EA ’24. New York, NY , USA: Association for Computing Machinery, 2024. [Online]. Available: https://doi.org/10.1145/3613905.3651026
-
[22]
Z. Li, H. Zhang, C. Peng, and R. Peiris, “Exploring large language model- driven agents for environment-aware spatial interactions and conversa- tions in virtual reality role-play scenarios,” in 2025 IEEE Conference Virtual Reality and 3D User Interfaces (VR), 2025, pp. 1–11
work page 2025
-
[23]
Z. Li, P. P. Babar, and R. L. Peiris, “Generative role-play communication training in virtual reality for autistic individuals: A study on job coach experiences in vocational training programs,” in Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, ser. CHI ’25. New York, NY , USA: Association for Computing Machinery, 2025. [Onl...
-
[24]
Interactive augmented reality storytelling guided by scene semantics,
C. Li, W. Li, H. Huang, and L.-F. Yu, “Interactive augmented reality storytelling guided by scene semantics,” ACM Trans. Graph., vol. 41, no. 4, Jul. 2022. [Online]. Available: https: //doi.org/10.1145/3528223.3530061
-
[25]
Object-driven narrative in AR: A scenario-metaphor framework with VLM integration,
Y . Sun, H. Guan, leith Kin Yep Chan, and Y . H. Kuo, “Object-driven narrative in AR: A scenario-metaphor framework with VLM integration,”
-
[26]
Available: https://arxiv.org/abs/2504.13119
[Online]. Available: https://arxiv.org/abs/2504.13119
-
[27]
A large model’s ability to identify 3d objects as a function of viewing angle,
J. Rubinstein, F. Ferraro, C. Matuszek, and D. Engel, “A large model’s ability to identify 3d objects as a function of viewing angle,” in 2024 IEEE International Conference on Artificial Intelligence and eXtended and Virtual Reality (AIxVR), 2024, pp. 281–288
work page 2024
-
[28]
LLMR: Real-time prompting of interactive worlds using large language models,
F. De La Torre, C. M. Fang, H. Huang, A. Banburski-Fahey, J. Amores Fernandez, and J. Lanier, “LLMR: Real-time prompting of interactive worlds using large language models,” in Proc. of the CHI Conference on Human Factors in Computing Systems, 2024, pp. 1–22
work page 2024
-
[29]
R. Kurai, T. Hiraki, Y . Hiroi, Y . Hirao, M. Perusqu ´ıa-Hern´andez, H. Uchiyama, and K. Kiyokawa, “MagicItem: Dynamic behavior design of virtual objects with large language models in a commercial metaverse platform,” IEEE Access, vol. 13, pp. 19 132–19 143, 2025
work page 2025
-
[30]
Odoragent: Generate odor sequences for movies based on large language model,
Y . Zhang, P. Gao, F. Kang, J. Li, J. Liu, Q. Lu, and Y . Xu, “Odoragent: Generate odor sequences for movies based on large language model,” in 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR) . IEEE, 2024, pp. 105–114
work page 2024
-
[31]
Z. Yin, Y . Wang, T. Papatheodorou, and P. Hui, “Text2vrscene: Exploring the framework of automated text-driven generation system for vr experi- ence,” in 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR). IEEE, 2024, pp. 701–711
work page 2024
-
[32]
Supporting text entry in virtual reality with large language models,
L. Chen, Y . Cai, R. Wang, S. Ding, Y . Tang, P. Hansen, and L. Sun, “Supporting text entry in virtual reality with large language models,” in 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR) . IEEE, 2024, pp. 524–534
work page 2024
-
[33]
D. Giunchi, N. Numan, E. Gatti, and A. Steed, “Dreamcodevr: Towards democratizing behavior design in virtual reality with speech-driven programming,” in 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR). IEEE, 2024, pp. 579–589
work page 2024
-
[34]
Building llm-based ai agents in social virtual reality,
H. Wan, J. Zhang, A. A. Suria, B. Yao, D. Wang, Y . Coady, and M. Prpa, “Building llm-based ai agents in social virtual reality,” in Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, 2024, pp. 1–7
work page 2024
-
[35]
M. S. Kawka, A. Nikopoulos, P. Bikiris, I. Kalisperakis, and C. Sten- toumis, “A web application with multi-input capabilities for AI-driven 3D object generation, designed for XR applications,” in 2025 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), 2025, pp. 447–454
work page 2025
-
[36]
Character animation pipeline based on latent diffusion and large language models,
A. Clocchiatti, N. Fumer `o, and A. M. Soccini, “Character animation pipeline based on latent diffusion and large language models,” in 2024 IEEE International Conference on Artificial Intelligence and eXtended and Virtual Reality (AIxVR), 2024, pp. 398–405
work page 2024
-
[37]
Instant3D: Instant text-to-3d generation,
M. Li, P. Zhou, J.-W. Liu, J. Keppo, M. Lin, S. Yan, and X. Xu, “Instant3D: Instant text-to-3d generation,” Int. J. Comput. Vision , JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14 vol. 132, no. 10, p. 4456–4472, May 2024. [Online]. Available: https://doi.org/10.1007/s11263-024-02097-5
-
[38]
Dream mesh: A speech- to-3D model generative pipeline in mixed reality,
S. C.-C. Weng, Y .-M. Chiou, and E. Y .-L. Do, “Dream mesh: A speech- to-3D model generative pipeline in mixed reality,” in 2024 IEEE Inter- national Conference on Artificial Intelligence and eXtended and Virtual Reality (AIxVR), 2024, pp. 345–349
work page 2024
-
[39]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
R. Liu, R. Wu, B. Van Hoorick, P. Tokmakov, S. Zakharov, and C. V ondrick, “ Zero-1-to-3: Zero-shot One Image to 3D Object ,” in 2023 IEEE/CVF International Conference on Computer Vision (ICCV) . Los Alamitos, CA, USA: IEEE Computer Society, Oct. 2023, pp. 9264–9275. [Online]. Available: https://doi.ieeecomputersociety.org/10. 1109/ICCV51070.2023.00853
-
[40]
MDD: masked deconstructed diffusion for 3D human motion generation from text,
J. Chen, F. Liu, and Y . Wang, “MDD: masked deconstructed diffusion for 3D human motion generation from text,” in 2025 IEEE International Conference on Artificial Intelligence and eXtended and Virtual Reality (AIxVR), 2025, pp. 61–72
work page 2025
-
[41]
M. Behravan, K. Matkovi ´c, and D. Gra ˇcanin, “Generative ai for context- aware 3D object creation using vision-language models in augmented reality,” in2025 IEEE International Conference on Artificial Intelligence and eXtended and Virtual Reality (AIxVR), 2025, pp. 73–81
work page 2025
-
[42]
Mobile edge intelligence for large language models: A contemporary survey,
G. Qu, Q. Chen, W. Wei, Z. Lin, X. Chen, and K. Huang, “Mobile edge intelligence for large language models: A contemporary survey,” arXiv preprint arXiv:2407.18921, 2024
-
[43]
Opti- mize weight rounding via signed gradient descent for the quantization of llms,
W. Cheng, W. Zhang, H. Shen, Y . Cai, X. He, K. Lv, and Y . Liu, “Opti- mize weight rounding via signed gradient descent for the quantization of llms,” arXiv preprint arXiv:2309.05516, 2023
-
[44]
Llm-pruner: On the structural pruning of large language models,
X. Ma, G. Fang, and X. Wang, “Llm-pruner: On the structural pruning of large language models,” Advances in neural information processing systems, vol. 36, pp. 21 702–21 720, 2023
work page 2023
-
[45]
Minillm: Knowledge distillation of large language models,
Y . Gu, L. Dong, F. Wei, and M. Huang, “Minillm: Knowledge distillation of large language models,” in The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[46]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V . Braverman, B. Chen, and X. Hu, “Kivi: A tuning-free asymmetric 2bit quantization for kv cache,” arXiv preprint arXiv:2402.02750, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Mobilellm: Optimizing sub-billion parameter language models for on-device use cases,
Z. Liu, C. Zhao, F. Iandola, C. Lai, Y . Tian, I. Fedorov, Y . Xiong, E. Chang, Y . Shi, R. Krishnamoorthi et al. , “Mobilellm: Optimizing sub-billion parameter language models for on-device use cases,” arXiv preprint arXiv:2402.14905, 2024
-
[48]
Introducing llama: A foundational, 65-billion-parameter large language model,
AI-Meta, “Introducing llama: A foundational, 65-billion-parameter large language model,” Meta AI, 2023
work page 2023
-
[49]
Hugging Face: The AI community building the future. www. huggingface.co,
H. Face, “Hugging Face: The AI community building the future. www. huggingface.co,” 2024, (Accessed: Sep. 10, 2024)
work page 2024
-
[50]
HellaSwag: Can a Machine Really Finish Your Sentence?
R. Zellers, A. Holtzman, Y . Bisk, A. Farhadi, and Y . Choi, “Hellaswag: Can a machine really finish your sentence?” 2019. [Online]. Available: https://arxiv.org/abs/1905.07830
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[51]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, “Measuring massive multitask language understanding,” arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[52]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? try arc, the ai2 reasoning challenge,” 2018. [Online]. Available: https://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[53]
Truthfulqa: Measuring how models mimic human falsehoods,
S. Lin, J. Hilton, and O. Evans, “Truthfulqa: Measuring how models mimic human falsehoods,” 2021
work page 2021
-
[54]
Winogrande: an adversarial winograd schema challenge at scale
K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y . Choi, “Winogrande: an adversarial winograd schema challenge at scale,” Commun. ACM, vol. 64, no. 9, p. 99–106, Aug. 2021. [Online]. Available: https://doi.org/10.1145/3474381
-
[55]
Pointer Sentinel Mixture Models
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,” arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[56]
A survey of recent developments in multiobjective optimization,
A. Chinchuluun and P. M. Pardalos, “A survey of recent developments in multiobjective optimization,” Annals of Operations Research , vol. 154, no. 1, pp. 29–50, 2007
work page 2007
-
[57]
Approaches for multi-objective optimization in the ecodesign of electric systems,
S. Brisset and F. Gillon, “Approaches for multi-objective optimization in the ecodesign of electric systems,” Eco-friendly innovation in electricity transmission and distribution networks, pp. 83–97, 2015
work page 2015
-
[58]
Design- space exploration of pareto-optimal architectures for deep learning with dvfs,
G. Santoro, M. R. Casu, V . Peluso, A. Calimera, and M. Alioto, “Design- space exploration of pareto-optimal architectures for deep learning with dvfs,” in 2018 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2018, pp. 1–5
work page 2018
-
[59]
Profiling apple silicon performance for ml training,
D. Feng, Z. Xu, R. Wang, and F. X. Lin, “Profiling apple silicon performance for ml training,” 2025. [Online]. Available: https://arxiv.org/abs/2501.14925
-
[60]
O. Mena, A. Kouyoumdjian, L. Besanc ¸on, M. Gleicher, I. Viola, and A. Ynnerman, “Augmenting a large language model with a combination of text and visual data for conversational visualization of global geospatial data,” 2025. [Online]. Available: https://arxiv.org/abs/2501. 09521
work page 2025
-
[61]
J. L. Gustafson, “Amdahl’s law,” inEncyclopedia of Parallel Computing. Springer, 2011, pp. 53–60. Dawar Khan received his Ph.D. from the NLPR, Institute of Automation, University of Chinese Academy of Sciences, Beijing, China, in 2018. He served as an Assistant Professor at the Nara Institute of Science and Technology (NAIST), Japan, from 2018 to 2020, an...
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.