Can Aerial VLA Models Cooperate? Evaluating Closed-Loop Air-Ground Coordination with CARLA-Air
Pith reviewed 2026-06-28 22:20 UTC · model grok-4.3
The pith
Aerial VLA models can track ground partners but fail to turn that into stable cooperative behavior in closed-loop tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
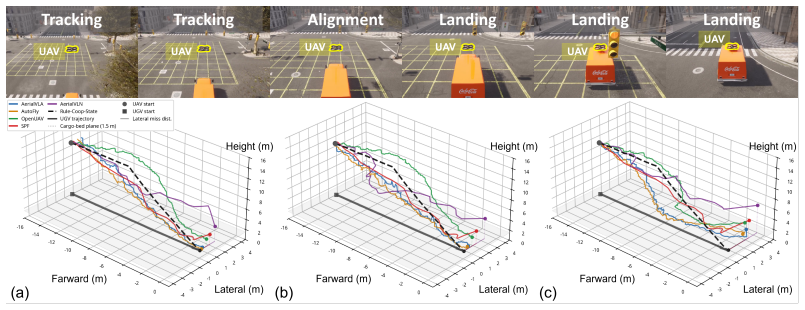
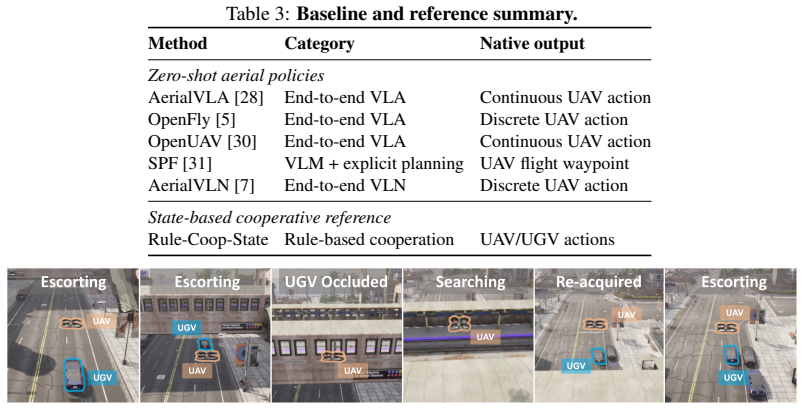
Current aerial VLA models can often track or follow a ground partner, but struggle to convert this single-agent competence into stable cooperative behavior. State prompting provides limited benefit, and naive bidirectional interaction fails to consistently improve performance and can amplify errors for most baselines. These findings suggest that, under the tested text-based cue interfaces, zero-shot cooperative air-ground VLA requires three components beyond the current paradigm: explicit partner-state grounding, low-latency action coordination, and team-level objective alignment.
What carries the argument
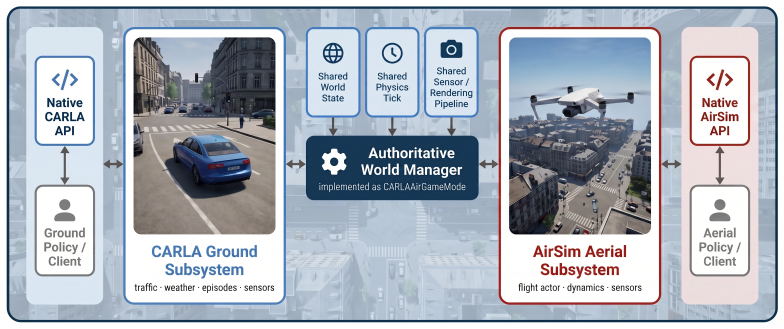
CARLA-Air, a single-process environment that unifies CARLA and AirSim to share world state, physics tick, and sensing pipeline for consistent UAV-UGV interaction and precise latency measurement.
If this is right
- Single-agent tracking skills do not automatically produce stable joint air-ground behavior.
- Text-based state prompting yields only marginal gains in coordination tasks.
- Naive bidirectional text interaction can increase error rates rather than reduce them.
- Zero-shot cooperation needs explicit partner-state grounding, low-latency coordination, and team objective alignment.
Where Pith is reading between the lines
- The same interface limitations may appear in other multi-robot settings that rely on language for coordination.
- Adding direct state sharing or visual grounding between agents could be tested as a direct extension of the current diagnostic tasks.
- Hardware experiments on physical UAV-UGV pairs would be needed to check whether the observed cooperation gaps persist outside simulation.
Load-bearing premise
The two diagnostic tasks and the text-based cue interfaces used in CARLA-Air represent the coordination challenges that would appear in real air-ground deployments or with richer interaction modalities.
What would settle it
An experiment in which the same VLA baselines, given direct partner-state access and low-latency channels instead of text cues, achieve stable success on both the landing and escort tasks would falsify the claim that the current paradigm is insufficient.
Figures



read the original abstract
Recent aerial vision-language-action (VLA) models show promising single-UAV capabilities, such as tracking moving objects and navigating to language-specified landmarks. However, it remains unclear whether these capabilities can transfer to air-ground cooperation, where a UAV and a UGV must act jointly in a shared, closed-loop physical world. We study this question with CARLA-Air, a single-process air-ground evaluation environment that unifies CARLA and AirSim inside one Unreal Engine runtime. By sharing the same world state, physics tick, and sensing pipeline, CARLA-Air enables physically consistent UAV--UGV interaction and precise measurement of simulation-timestamp alignment and effective coordination latency. Using CARLA-Air, we evaluate representative aerial VLA and planning baselines on two complementary diagnostic tasks: moving-platform landing and occlusion-recovery escort. The results show that current aerial VLA models can often track or follow a ground partner, but struggle to convert this single-agent competence into stable cooperative behavior. State prompting provides limited benefit, and naive bidirectional interaction fails to consistently improve performance and can amplify errors for most baselines. These findings suggest that, under the tested text-based cue interfaces, zero-shot cooperative air-ground VLA requires three components beyond the current paradigm: explicit partner-state grounding, low-latency action coordination, and team-level objective alignment. Our code is available at https://github.com/louiszengCN/CarlaAir.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CARLA-Air, a single-process simulation environment unifying CARLA and AirSim to enable physically consistent closed-loop evaluation of air-ground coordination. It evaluates representative aerial VLA and planning baselines on two diagnostic tasks—moving-platform landing and occlusion-recovery escort—finding that single-agent tracking succeeds but stable cooperative behavior does not. State prompting yields limited benefit, while naive bidirectional interaction often fails to improve performance and can amplify errors. The authors conclude that, under the tested text-based cue interfaces, zero-shot cooperative air-ground VLA requires explicit partner-state grounding, low-latency action coordination, and team-level objective alignment. The code is released at https://github.com/louiszengCN/CarlaAir.
Significance. If the empirical results hold under the stated scoping, the work is significant for providing the first unified closed-loop benchmark for aerial VLA cooperation with ground agents. The shared world state, physics tick, and sensing pipeline enable precise latency and alignment measurements, which is a clear methodological strength. The open-source release supports reproducibility. The findings identify concrete gaps in current VLA paradigms for multi-agent settings and suggest targeted requirements for future work.
minor comments (3)
- Abstract: The term 'naive bidirectional interaction' is used without a brief definition or example of the prompting format, which could reduce clarity for readers unfamiliar with the exact interface implementation.
- The manuscript should include a short paragraph in the methods or appendix summarizing the number of trials, random seeds, and variance reporting for the performance metrics to aid verification of the reported differences.
- Figure captions (e.g., those showing task trajectories or performance bars) would benefit from explicit mention of the metrics plotted and any statistical annotations used.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments appear in the provided report.
Circularity Check
No significant circularity
full rationale
This paper is an empirical evaluation study that introduces the CARLA-Air simulator and reports performance measurements of existing VLA models on two diagnostic tasks. The abstract and provided text contain no derivation chain, equations, fitted parameters presented as predictions, or load-bearing self-citations. Central claims rest on experimental results obtained in the new environment rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cooperative motion planning and control for aerial-ground autonomous systems: Methods and applications.Progress in Aerospace Sciences, 146:101005, 2024
Runqi Chai, Yunlong Guo, Zongyu Zuo, Kaiyuan Chen, Hyo-Sang Shin, and Antonios Tsour- dos. Cooperative motion planning and control for aerial-ground autonomous systems: Methods and applications.Progress in Aerospace Sciences, 146:101005, 2024
2024
-
[2]
Tianle Zeng, Jianwei Peng, Hanjing Ye, Guangcheng Chen, Senzi Luo, and Hong Zhang. Ezreal: Enhancing zero-shot outdoor robot navigation toward distant targets under varying visibility.arXiv preprint arXiv:2509.13720, 2025. 9
-
[3]
Vision-and-Language Navigation for UAVs: Progress, Challenges, and a Research Roadmap
Hanxuan Chen, Jie Zheng, Siqi Yang, Tianle Zeng, Siwei Feng, Songsheng Cheng, Ruilong Ren, Hanzhong Guo, Shuai Yuan, Xiangyue Wang, et al. Vision-and-language navigation for uavs: Progress, challenges, and a research roadmap.arXiv preprint arXiv:2604.13654, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
UAV-Track VLA: Embodied Aerial Tracking via Vision-Language-Action Models
Qiyao Zhang, Shuhua Zheng, Jianli Sun, Chengxiang Li, Xianke Wu, Zihan Song, Zhiyong Cui, Yisheng Lv, and Yonglin Tian. Uav-track vla: Embodied aerial tracking via vision- language-action models.arXiv preprint arXiv:2604.02241, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Yunpeng Gao, Chenhui Li, Zhongrui You, Junli Liu, Zhen Li, Pengan Chen, Qizhi Chen, Zhonghan Tang, Liansheng Wang, Penghui Yang, et al. Openfly: A comprehensive platform for aerial vision-language navigation.arXiv preprint arXiv:2502.18041, 2025
-
[6]
Uav-vla: Vision-language-action system for large scale aerial mission generation
Oleg Sautenkov, Yasheerah Yaqoot, Artem Lykov, Muhammad Ahsan Mustafa, Grik Tade- vosyan, Aibek Akhmetkazy, Miguel Altamirano Cabrera, Mikhail Martynov, Sausar Karaf, and Dzmitry Tsetserukou. Uav-vla: Vision-language-action system for large scale aerial mission generation. In2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pag...
2025
-
[7]
Aeri- alvln: Vision-and-language navigation for uavs
Shubo Liu, Hongsheng Zhang, Yuankai Qi, Peng Wang, Yanning Zhang, and Qi Wu. Aeri- alvln: Vision-and-language navigation for uavs. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15384–15394, 2023
2023
-
[8]
Uav3d: A large-scale 3d perception bench- mark for unmanned aerial vehicles.Advances in Neural Information Processing Systems, 37: 55425–55442, 2024
Hui Ye, Rajshekhar Sunderraman, and Shihao Ji. Uav3d: A large-scale 3d perception bench- mark for unmanned aerial vehicles.Advances in Neural Information Processing Systems, 37: 55425–55442, 2024
2024
-
[9]
Transimhub: A unified air-ground simulation platform for multi-modal perception and decision-making,
Maonan Wang, Yirong Chen, Yuxin Cai, Aoyu Pang, Yuejiao Xie, Zian Ma, Chengcheng Xu, Kemou Jiang, Ding Wang, Laurent Roullet, et al. Transimhub: A unified air-ground simulation platform for multi-modal perception and decision-making.arXiv preprint arXiv:2510.15365, 2025
-
[10]
Yangjie Cui, Xin Dong, Boyang Gao, Jinwu Xiang, Daochun Li, and Zhan Tu. Airsimag: A high-fidelity simulation platform for air-ground collaborative robotics.arXiv preprint arXiv:2603.23079, 2026
-
[11]
Tianle Zeng, Yanci Wen, and Hong Zhang. Carla-air: Fly drones inside a carla world–a unified infrastructure for air-ground embodied intelligence.arXiv preprint arXiv:2603.28032, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Yan Zhuang, Jiawei Ren, Xiaokang Ye, Jianzhi Shen, Ruixuan Zhang, Tianai Yue, Muhammad Faayez, Xuhong He, Ziqiao Ma, Lianhui Qin, et al. Simworld-robotics: Synthesizing photo- realistic and dynamic urban environments for multimodal robot navigation and collaboration. arXiv preprint arXiv:2512.10046, 2025
-
[13]
Unrealzoo: Enriching photo-realistic virtual worlds for embodied ai
Fangwei Zhong, Kui Wu, Churan Wang, Hao Chen, Hai Ci, Zhoujun Li, and Yizhou Wang. Unrealzoo: Enriching photo-realistic virtual worlds for embodied ai. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5769–5779, 2025
2025
-
[14]
Omnidrones: An ef- ficient and flexible platform for reinforcement learning in drone control.IEEE Robotics and Automation Letters, 9(3):2838–2844, 2024
Botian Xu, Feng Gao, Chao Yu, Ruize Zhang, Yi Wu, and Yu Wang. Omnidrones: An ef- ficient and flexible platform for reinforcement learning in drone control.IEEE Robotics and Automation Letters, 9(3):2838–2844, 2024
2024
-
[15]
Learning to fly—a gym environment with pybullet physics for reinforcement learning of multi- agent quadcopter control
Jacopo Panerati, Hehui Zheng, SiQi Zhou, James Xu, Amanda Prorok, and Angela P Schoellig. Learning to fly—a gym environment with pybullet physics for reinforcement learning of multi- agent quadcopter control. In2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7512–7519. IEEE, 2021
2021
-
[16]
Rotors—a modular gazebo mav simulator framework
Fadri Furrer, Michael Burri, Markus Achtelik, and Roland Siegwart. Rotors—a modular gazebo mav simulator framework. InRobot Operating System (ROS) The Complete Refer- ence (Volume 1), pages 595–625. Springer, 2016
2016
-
[17]
Griffin: Aerial-ground cooperative detection and tracking dataset and benchmark
Jiahao Wang, Xiangyu Cao, Jiaru Zhong, Yuner Zhang, Zeyu Han, Haibao Yu, Chuang Zhang, Lei He, Shaobing Xu, and Jianqiang Wang. Griffin: Aerial-ground cooperative detection and tracking dataset and benchmark. InProceedings of the AAAI Conference on Artificial Intelli- gence, volume 40, pages 9867–9875, 2026. 10
2026
-
[18]
Xiangyu Wang, Donglin Yang, Yue Liao, Wenhao Zheng, Wenjun Wu, Bin Dai, Hongsheng Li, and Si Liu. Uav-flow colosseo: A real-world benchmark for flying-on-a-word uav imitation learning.arXiv preprint arXiv:2505.15725, 2025
-
[19]
Multi-robot scene comple- tion: Towards task-agnostic collaborative perception
Yiming Li, Juexiao Zhang, Dekun Ma, Yue Wang, and Chen Feng. Multi-robot scene comple- tion: Towards task-agnostic collaborative perception. InConference on Robot Learning, pages 2062–2072. PMLR, 2023
2062
-
[20]
Xiangbo Gao, Yuheng Wu, Fengze Yang, Xuewen Luo, Keshu Wu, Xinghao Chen, Yuping Wang, Chenxi Liu, Yang Zhou, and Zhengzhong Tu. Airv2x: Unified air-ground vehicle-to- everything collaboration.arXiv preprint arXiv:2506.19283, 2025
-
[21]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InProceedings of the 1st Conference on Robot Learning (CoRL), pages 1–16. PMLR, 2017
2017
-
[22]
AirSim: High-fidelity visual and physical simulation for autonomous vehicles
Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. AirSim: High-fidelity visual and physical simulation for autonomous vehicles. InField and Service Robotics (FSR), pages 621–635. Springer, 2018
2018
-
[23]
Air-ground collabora- tion for language-specified missions in unknown environments.IEEE Transactions on Field Robotics, 2025
Fernando Cladera, Zachary Ravichandran, Jason Hughes, Varun Murali, Carlos Nieto-Granda, M Ani Hsieh, George J Pappas, Camillo J Taylor, and Vijay Kumar. Air-ground collabora- tion for language-specified missions in unknown environments.IEEE Transactions on Field Robotics, 2025
2025
-
[24]
Where2comm: Communication-efficient collaborative perception via spatial confidence maps.Advances in neural information processing systems, 35:4874–4886, 2022
Yue Hu, Shaoheng Fang, Zixing Lei, Yiqi Zhong, and Siheng Chen. Where2comm: Communication-efficient collaborative perception via spatial confidence maps.Advances in neural information processing systems, 35:4874–4886, 2022
2022
-
[25]
A bi-directional adaptive framework for agile uav landing.arXiv preprint arXiv:2601.03037, 2026
Chunhui Zhao, Xirui Kao, Yilin Lu, and Yang Lyu. A bi-directional adaptive framework for agile uav landing.arXiv preprint arXiv:2601.03037, 2026
-
[26]
GLIDE: A Coordinated Aerial-Ground Framework for Search and Rescue in Unknown Environments
Seth Farrell, Chenghao Li, Hongzhan Yu, Hesam Mojtahedi, Sicun Gao, and Henrik I Chris- tensen. Glide: A coordinated aerial-ground framework for search and rescue in unknown environments.arXiv preprint arXiv:2509.14210, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Enguang Fan, Yifan Chen, Zihan Shan, Matthew Caesar, and Jae Kim. Communication- aware multi-agent reinforcement learning for decentralized cooperative uav deployment.arXiv preprint arXiv:2603.16141, 2026
-
[28]
AerialVLA: A vision- language-action model for UA V navigation via minimalist end-to-end control,
Peng Xu, Zhengnan Deng, Jiayan Deng, Zonghua Gu, and Shaohua Wan. Aerialvla: A vision- language-action model for uav navigation via minimalist end-to-end control.arXiv preprint arXiv:2603.14363, 2026
-
[29]
Pushing the boundaries of immersion and storytelling: A technical review of unreal engine.Displays, page 103268, 2025
Oleksandra Sobchyshak, Santiago Berrezueta-Guzman, and Stefan Wagner. Pushing the boundaries of immersion and storytelling: A technical review of unreal engine.Displays, page 103268, 2025
2025
-
[30]
arXiv preprint arXiv:2410.07087 (2024)
Xiangyu Wang, Donglin Yang, Ziqin Wang, Hohin Kwan, Jinyu Chen, Wenjun Wu, Hong- sheng Li, Yue Liao, and Si Liu. Towards realistic uav vision-language navigation: Platform, benchmark, and methodology.arXiv preprint arXiv:2410.07087, 2024
-
[31]
See, point, fly: A learning-free vlm framework for universal unmanned aerial navigation
Chih Yao Hu, Yang-Sen Lin, Yuna Lee, Chih-Hai Su, Jie-Ying Lee, Shr-Ruei Tsai, Chin-Yang Lin, Kuan-Wen Chen, Tsung-Wei Ke, and Yu-Lun Liu. See, point, fly: A learning-free vlm framework for universal unmanned aerial navigation. InConference on Robot Learning, pages 4697–4708. PMLR, 2025
2025
-
[32]
Colosseum: An open-source simulator for autonomous robotics research
CodexLabsLLC. Colosseum: An open-source simulator for autonomous robotics research. https://github.com/CodexLabsLLC/Colosseum, 2024. Community fork of AirSim. 11 Appendix This appendix provides additional platform and evaluation details that support the main paper. Ap- pendix A describes the CARLA-AIRruntime design, coordinate-frame unification, sensing s...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.