FSA-GRPO: Teaching Auditory LLMs to Use Few-shot Demonstrations
Pith reviewed 2026-07-01 15:58 UTC · model grok-4.3
The pith
Training auditory LLMs only on adult speech data strengthens their few-shot adaptation across tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
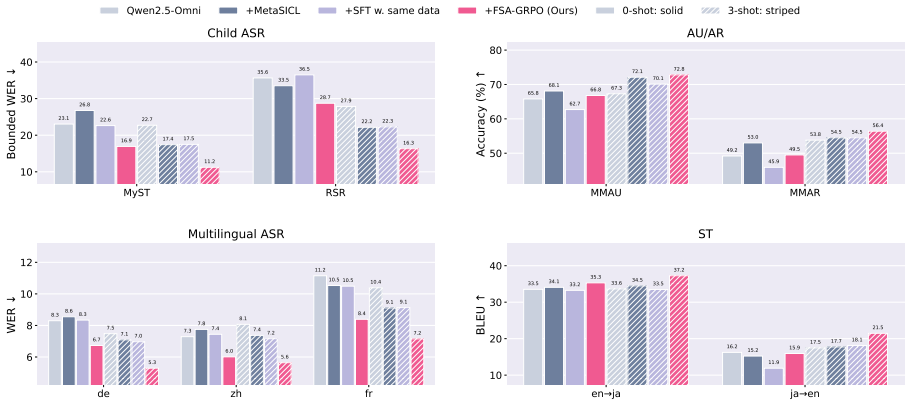
FSA-GRPO is an RL-based post-training recipe that applies a specially designed reward to encourage auditory LLMs to leverage few-shot demonstrations. Training this method exclusively on high-resource adult ASR data improves the model's general few-shot adaptation ability, producing gains in children's speech recognition, speech translation, and audio understanding. When in-domain data are unavailable, FSA-GRPO outperforms direct tuning on related out-of-domain data.
What carries the argument
FSA-GRPO, an RL post-training method that adds a reward encouraging models to condition responses on few-shot demonstrations during inference.
If this is right
- Performance on children's speech recognition improves without any child data in the training set.
- Gains transfer to speech translation and audio understanding tasks.
- FSA-GRPO beats direct tuning on out-of-domain data when in-domain data cannot be used.
- Data selection and auxiliary reward weighting affect the final effectiveness of the recipe.
Where Pith is reading between the lines
- The method may teach a general meta-skill for using demonstrations that applies beyond the specific training tasks.
- Similar reward designs could reduce the need to collect domain-specific data for adapting audio models.
- The approach might extend to other low-resource audio scenarios where demonstrations are the only available adaptation signal.
Load-bearing premise
The specially designed reward in FSA-GRPO will cause the model to leverage few-shot demonstrations during inference rather than other response patterns.
What would settle it
Compare few-shot task performance of models trained with the full FSA-GRPO reward against identical models trained with the same adult ASR data but without the demonstration-leveraging reward component; lack of difference would falsify the claim that the reward drives the gains.
Figures


read the original abstract
Few-shot prompting provides an effective way to adapt auditory large language models to low-resource tasks such as children's speech recognition. However, most auditory large language models are not explicitly trained to perform inference in this demonstration-conditioned format, limiting the extent to which they can benefit from few-shot prompting. To address this limitation, we introduce Few-Shot Aware GRPO (FSA-GRPO), an RL-based post-training recipe that uses a specially designed reward to encourage the model to leverage few-shot demonstrations, thereby strengthening its few-shot adaptation ability. Notably, training with only high-resource adult ASR data improves the model's general few-shot adaptation ability, yielding gains not only in children's speech recognition but also in speech translation and audio understanding. We further study data selection and auxiliary reward weighting to identify an effective training recipe. Our experiments show that when in-domain data are unavailable or cannot be used for training, FSA-GRPO is more effective than direct tuning on related out-of-domain data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Few-Shot Aware GRPO (FSA-GRPO), an RL-based post-training recipe for auditory LLMs. It employs a specially designed reward to encourage models to leverage few-shot demonstrations during inference. Training occurs exclusively on high-resource adult ASR data, yet the method is claimed to improve general few-shot adaptation, producing gains on children's speech recognition, speech translation, and audio understanding tasks. The approach is further claimed to outperform direct tuning on related out-of-domain data when in-domain data cannot be used for training.
Significance. If the reward mechanism is shown to specifically induce demonstration-conditioned behavior rather than generic task improvements, the result would be significant for low-resource auditory LLM adaptation, as it would allow effective few-shot gains without access to in-domain training data.
major comments (2)
- [Reward function definition (method section)] The central claim that FSA-GRPO strengthens few-shot adaptation (rather than yielding generic RL gains on ASR) rests on the reward function specifically rewarding demonstration-conditioned outputs. The manuscript must provide the exact reward formulation (including any auxiliary terms and weighting) and evidence that it enforces conditioning on provided demonstrations, for example via ablations that remove demonstrations at inference time or compare against a reward that ignores demonstration content.
- [Experiments and results] The superiority over direct tuning on out-of-domain data is a key result, but without reported metrics, baseline comparisons, or tables showing effect sizes on the downstream tasks (children's ASR, speech translation, audio understanding), it is impossible to assess whether the gains are attributable to the few-shot mechanism or other factors.
minor comments (2)
- The abstract states that data selection and auxiliary reward weighting were studied to identify an effective recipe; the corresponding analysis and any hyperparameter sensitivity results should be presented with concrete values and ablation tables.
- Notation for the reward components and GRPO variant should be defined clearly before use, and any new symbols introduced in the method should be listed in a table or appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the reward formulation and experimental reporting. We address each major comment below and will revise the manuscript to strengthen these aspects.
read point-by-point responses
-
Referee: [Reward function definition (method section)] The central claim that FSA-GRPO strengthens few-shot adaptation (rather than yielding generic RL gains on ASR) rests on the reward function specifically rewarding demonstration-conditioned outputs. The manuscript must provide the exact reward formulation (including any auxiliary terms and weighting) and evidence that it enforces conditioning on provided demonstrations, for example via ablations that remove demonstrations at inference time or compare against a reward that ignores demonstration content.
Authors: We agree that the precise reward formulation is essential to substantiate the central claim. The manuscript describes the reward at a high level but does not include the full mathematical expression with auxiliary terms and weights. In the revision we will add the exact FSA-GRPO reward definition. We will also report new ablations that evaluate performance when demonstrations are removed at inference and compare against a reward variant that ignores demonstration content, to isolate the conditioning effect. revision: yes
-
Referee: [Experiments and results] The superiority over direct tuning on out-of-domain data is a key result, but without reported metrics, baseline comparisons, or tables showing effect sizes on the downstream tasks (children's ASR, speech translation, audio understanding), it is impossible to assess whether the gains are attributable to the few-shot mechanism or other factors.
Authors: We concur that detailed quantitative results are required for proper evaluation. While the manuscript states gains on the listed tasks and superiority over out-of-domain tuning, it does not present comprehensive tables with all metrics and effect sizes. In the revision we will add tables reporting absolute and relative performance on children's ASR, speech translation, and audio understanding, including all relevant baselines and direct comparisons to out-of-domain tuning. revision: yes
Circularity Check
No circularity: empirical training recipe evaluated on held-out tasks
full rationale
The paper introduces FSA-GRPO as an RL post-training method using a designed reward on adult ASR data, then reports measured gains on children's ASR, speech translation, and audio understanding. No equations, parameters, or claims reduce by construction to the inputs; results are presented as experimental outcomes rather than tautological re-statements of the reward definition or prior self-citations. The derivation chain consists of standard RL training followed by independent downstream evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- auxiliary reward weights
axioms (1)
- domain assumption Reinforcement learning with the specially designed reward will increase the model's use of few-shot demonstrations at inference time
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
COSMIC: Data Efficient Instruction-tuning For Speech In-Context Learning , author=. 2024 , eprint=
2024
-
[2]
Proceedings of the 2022 conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Metaicl: Learning to learn in context , author=. Proceedings of the 2022 conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[3]
Haolong Zheng and Yekaterina Yegorova and Mark Hasegawa-Johnson , year=. 2509.13395 , archivePrefix=
-
[4]
2025 , organization=
Zhou, Jiaming and Zhao, Shiwan and He, Jiabei and Wang, Hui and Zeng, Wenjia and Chen, Yong and Sun, Haoqin and Kong, Aobo and Qin, Yong , booktitle=. 2025 , organization=
2025
-
[5]
2024 , organization=
Wang, Siyin and Yang, Chao-Han and Wu, Ji and Zhang, Chao , booktitle=. 2024 , organization=
2024
-
[6]
Haolong Zheng and Yekaterina Yegorova and Mark Hasegawa-Johnson , year=. 2512.18263 , archivePrefix=
-
[7]
LLM-Core-Team Xiaomi , year=
-
[8]
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and others , booktitle =
-
[9]
Huang, Shaohan and Dong, Li and Wang, Wenhui and Hao, Yaru and Singhal, Saksham and Ma, Shuming and Lv, Tengchao and Cui, Lei and Mohammed, Owais Khan and Patra, Barun and others , booktitle=
-
[10]
Keren, Gil and Kozhevnikov, Artyom and Meng, Yen and Ropers, Christophe and Setzler, Matthew and Wang, Skyler and Adebara, Ife and Auli, Michael and Balioglu, Can and others , journal=
-
[11]
2024 , organization=
Chen, Zhehuai and Huang, He and Andrusenko, Andrei and Hrinchuk, Oleksii and Puvvada, Krishna C and Li, Jason and Ghosh, Subhankar and Balam, Jagadeesh and Ginsburg, Boris , booktitle=. 2024 , organization=
2024
-
[12]
Kong, Zhifeng and Goel, Arushi and Badlani, Rohan and Ping, Wei and Valle, Rafael and Catanzaro, Bryan , booktitle=
-
[13]
2025 , volume=
Ihori, Mana and Yamane, Taiga and Kawata, Naotaka and Makishima, Naoki and Tanaka, Tomohiro and Suzuki, Satoshi and Orihashi, Shota and Masumura, Ryo , booktitle=. 2025 , volume=
2025
-
[14]
arXiv preprint arXiv:2409.10429 , year=
SMILE: speech meta in-context learning for low-resource language automatic speech recognition , author=. arXiv preprint arXiv:2409.10429 , year=
-
[15]
CoVoST 2 and Massively Multilingual Speech Translation , author =. 2021 , booktitle =. doi:10.21437/Interspeech.2021-2027 , issn =
-
[16]
and Branson, M
Ardila, R. and Branson, M. and Davis, K. and Henretty, M. and Kohler, M. and Meyer, J. and Morais, R. and Saunders, L. and Tyers, F. M. and Weber, G. , title =. Proceedings of the 12th Conference on Language Resources and Evaluation , pages =
-
[17]
Wang, Dingdong and Wu, Jincenzi and Li, Junan and Yang, Dongchao and Chen, Xueyuan and Zhang, Tianhua and Meng, Helen , journal=
-
[18]
Jin, Xu and Zhifang, Guo and Jinzheng, He and Hangrui, Hu and Ting, He and Shuai, Bai and Keqin, Chen and Jialin, Wang and Yang, Fan and Kai, Dang and Bin, Zhang and Xiong, Wang and Yunfei, Chu and Junyang, Lin , journal=
-
[19]
Xiuwen Zheng and Bornali Phukon and Jonghwan Na and Ed Cutrell and Kyu J. Han and Mark Hasegawa-Johnson and Pan-Pan Jiang and Aadhrik Kuila and Colin Lea and Bob MacDonald and Gautam Mantena and Venkatesh Ravichandran and Leda Sari and Katrin Tomanek and Chang D. Yoo and Chris Zwilling , year =. doi:10.21437/Interspeech.2025-566 , issn =
-
[20]
Pradhan, Sameer and Cole, Ronald and Ward, Wayne , booktitle=
-
[21]
2019 , publisher=
Redmond, Sean M and Ash, Andrea C and Christopulos, Tyler T and Pfaff, Theresa , journal=. 2019 , publisher=
2019
-
[22]
NeurIPS , pages=
Uniaudio 1.5: Large language model-driven audio codec is a few-shot audio task learner , author=. NeurIPS , pages=
-
[23]
arXiv preprint arXiv:2311.02248 , year=
Cosmic: Data efficient instruction-tuning for speech in-context learning , author=. arXiv preprint arXiv:2311.02248 , year=
-
[24]
EMNLP , pages=
Bayesian Example Selection Improves In-Context Learning for Speech, Text and Visual Modalities , author=. EMNLP , pages=
-
[25]
2026 , eprint=
SICL-AT: Another way to adapt Auditory LLM to low-resource task , author=. 2026 , eprint=
2026
-
[26]
2026 , eprint =
MetaSICL: Adapting Auditory LLM via Meta Speech In-Context Learning , author =. 2026 , eprint =
2026
-
[27]
Audio Flamingo Next: Next-Generation Open Audio-Language Models for Speech, Sound, and Music
Audio Flamingo Next: Next-Generation Open Audio-Language Models for Speech, Sound, and Music , author=. arXiv preprint arXiv:2604.10905 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
International Conference on Learning Representations , volume=
Mmau: A massive multi-task audio understanding and reasoning benchmark , author=. International Conference on Learning Representations , volume=
-
[29]
Advances in Neural Information Processing Systems , volume=
Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
Proceedings of the 40th International Conference on Machine Learning , pages=
Robust Speech Recognition via Large-Scale Weak Supervision , author=. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[31]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
International Conference on Learning Representations , year=
LoRA: Low-Rank Adaptation of Large Language Models , author=. International Conference on Learning Representations , year=
-
[35]
arXiv preprint arXiv:2511.01299 , year=
Towards General Auditory Intelligence: Large Multimodal Models for Machine Listening and Speaking , author=. arXiv preprint arXiv:2511.01299 , year=
-
[36]
SALMONN-omni: A Standalone Speech LLM without Codec Injection for Full-duplex Conversation , url =
Yu, Wenyi and Wang, Siyin and Yang, Xiaoyu and Chen, Xianzhao and Tian, Xiaohai and Zhang, Jun and Sun, Guangzhi and Lu, Lu and Wang, Yuxuan and Zhang, Chao , booktitle =. SALMONN-omni: A Standalone Speech LLM without Codec Injection for Full-duplex Conversation , url =
-
[37]
doi:10.21437/Interspeech.2025-764 , issn =
Seraphina Fong and Marco Matassoni and Alessio Brutti , year =. doi:10.21437/Interspeech.2025-764 , issn =
-
[38]
EURASIP Journal on Audio, Speech, and Music Processing , volume=
Exploring the effect of differences in the acoustic correlates of adults' and children's speech in the context of automatic speech recognition , author=. EURASIP Journal on Audio, Speech, and Music Processing , volume=. 2010 , publisher=
2010
-
[39]
Proceedings of the 2nd Workshop on Child, Computer and Interaction , pages=
A review of ASR technologies for children's speech , author=. Proceedings of the 2nd Workshop on Child, Computer and Interaction , pages=
-
[40]
Computer speech & language , volume=
Transfer learning from adult to children for speech recognition: Evaluation, analysis and recommendations , author=. Computer speech & language , volume=. 2020 , publisher=
2020
-
[41]
arXiv preprint arXiv:2406.10507 , year=
Benchmarking Children's ASR with Supervised and Self-supervised Speech Foundation Models , author=. arXiv preprint arXiv:2406.10507 , year=
-
[43]
arXiv preprint arXiv:2503.11197 , year=
Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering , author=. arXiv preprint arXiv:2503.11197 , year=
-
[44]
arXiv preprint arXiv:2505.09439 , year=
Omni-R1: Do You Really Need Audio to Fine-Tune Your Audio LLM? , author=. arXiv preprint arXiv:2505.09439 , year=
-
[45]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
SoundMind: RL-Incentivized Logic Reasoning for Audio-Language Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=. 2025 , publisher=
2025
-
[46]
arXiv preprint arXiv:2509.16990 , year=
Advancing Speech Understanding in Speech-Aware Language Models with GRPO , author=. arXiv preprint arXiv:2509.16990 , year=
-
[47]
arXiv preprint arXiv:2509.01939 , year=
Group Relative Policy Optimization for Speech Recognition , author=. arXiv preprint arXiv:2509.01939 , year=
-
[48]
Sentence- BERT : Sentence Embeddings using Siamese BERT -Networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using Siamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 2019. doi:10.18653/v1/D19-1410
-
[49]
doi:10.21437/Interspeech.2024-1932 , issn =
Chang, Kai-Wei and Hsu, Ming-Hao and Li, Shan-Wen and Lee, Hung-yi , year =. doi:10.21437/Interspeech.2024-1932 , issn =
-
[50]
doi:10.21437/Interspeech.2025-1467 , issn =
Agrawal, Neeraj and Ganapathy, Sriram , year =. doi:10.21437/Interspeech.2025-1467 , issn =
-
[51]
Multimodal In-context Learning for ASR of Low-resource Languages
Multimodal In-context Learning for ASR of Low-resource Languages , author=. arXiv preprint arXiv:2601.05707 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.