Fixed External Cameras as Common Prior Maps for Active 3D Scene Graph Generation
Pith reviewed 2026-05-20 09:53 UTC · model grok-4.3
The pith
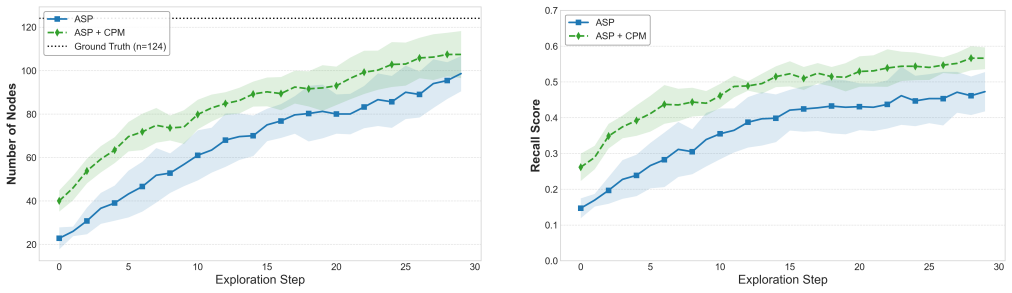
Fixed external cameras initialize 3D scene graphs with up to 79% higher initial object recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Observations from fixed external RGB cameras are treated as Common Prior Maps that initialize a semantic and geometric scene prior. The system fuses these with onboard camera observations using a feed-forward 3D reconstruction model in a hardware-agnostic pipeline. A graph-based active semantic exploration framework then leverages the partial scene graph to guide the robot toward regions of high semantic uncertainty, progressively completing the map and yielding up to 79% higher initial object recall together with improved exploration efficiency.
What carries the argument
Common Prior Maps (CPMs) from fixed external cameras, which supply wide-field views that initialize the semantic and geometric scene prior before any robot motion.
If this is right
- Even a single external camera raises initial object recall by up to 79%.
- The richer prior context reduces the number of steps required for subsequent active exploration.
- All cameras, external or onboard, are handled identically with no added calibration.
- The partial scene graph directly supplies uncertainty signals that steer exploration.
Where Pith is reading between the lines
- The same fusion pipeline could incorporate other common priors such as BIM models or floor plans mentioned in the introduction.
- Environments already equipped with security cameras could adopt the method to shorten mapping time without extra hardware.
- Varying the number and placement of external cameras would allow measurement of the point of diminishing returns on recall gains.
Load-bearing premise
A feed-forward 3D reconstruction model can process and fuse RGB observations from both onboard robot cameras and fixed external cameras identically without hardware-specific calibration or modifications.
What would settle it
Run the full active exploration pipeline in the same test environments once with a single external camera and once without any external camera, then compare initial object recall and total steps needed to reach a target completeness level; no measurable gain would falsify the central claim.
Figures

read the original abstract
Commonly available prior information, such as BIM models, floor plans, and remote sensing images, can provide valuable geometric and semantic context for autonomous robotic systems. In this paper, we treat observations from fixed external RGB cameras as Common Prior Maps (CPMs): wide-field views of the environment that initialize a semantic and geometric scene prior before any robot motion begins. We present an RGB-only framework for active, incremental 3D scene graph (3DSG) generation that seamlessly fuses observations from both onboard robot cameras and fixed external cameras within a single hardware-agnostic pipeline. By relying solely on RGB observations processed by a feed-forward 3D reconstruction model, the system treats all cameras - onboard or external - identically, requiring no hardware modifications. A graph-based active semantic exploration framework then directly leverages the partial scene graph to guide the robot toward regions of high semantic uncertainty, progressively completing and refining the prior. Experiments demonstrate that bootstrapping the scene graph with even a single external camera increases initial object recall by up to +79%, and that the richer context of the prior significantly improves the efficiency of subsequent active exploration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes treating observations from fixed external RGB cameras as Common Prior Maps (CPMs) to initialize semantic and geometric scene priors for robots before motion begins. It introduces an RGB-only framework for active incremental 3D scene graph generation that fuses onboard robot camera and external camera observations identically via a feed-forward 3D reconstruction model in a claimed hardware-agnostic pipeline requiring no modifications or calibration. A graph-based active semantic exploration module then uses the partial scene graph to direct the robot toward high-uncertainty regions. The central experimental claim is that bootstrapping with even a single external camera increases initial object recall by up to +79% and improves subsequent exploration efficiency.
Significance. If the fusion mechanism and quantitative gains are rigorously validated, the work could offer a practical method for leveraging ubiquitous fixed cameras or remote sensing data to accelerate robotic scene understanding and reduce exploration effort. The concept of CPMs as priors for active 3DSG generation is a reasonable extension of prior-informed mapping and could have impact in structured environments like buildings or warehouses. The hardware-agnostic framing, if substantiated, would be a notable strength for real-world deployment.
major comments (2)
- Abstract: The central quantitative claim of up to +79% increase in initial object recall (and improved exploration efficiency) from a single external camera is presented without any description of experimental setup, baselines, number of trials, error bars, statistical tests, or datasets. This absence makes the primary empirical support for the contribution unverifiable and load-bearing for the paper's claims.
- Abstract: The hardware-agnostic pipeline is asserted to process RGB observations from fixed external cameras and onboard robot cameras identically using a single feed-forward 3D reconstruction model with no hardware modifications or calibration. However, feed-forward models are typically sensitive to differences in intrinsics (focal length, principal point, distortion), extrinsics, and scale; no mechanism is described for on-the-fly normalization, pose estimation, or invariance that would prevent misalignment or scale errors in the fused scene graph, which would directly impact object recall and semantic uncertainty used for active exploration.
minor comments (1)
- Abstract: The acronym CPM is introduced but the precise definition and scope (e.g., whether it includes only geometric or also semantic priors) could be stated more explicitly for immediate clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below in detail and have updated the manuscript to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: Abstract: The central quantitative claim of up to +79% increase in initial object recall (and improved exploration efficiency) from a single external camera is presented without any description of experimental setup, baselines, number of trials, error bars, statistical tests, or datasets. This absence makes the primary empirical support for the contribution unverifiable and load-bearing for the paper's claims.
Authors: The abstract is intended as a concise summary of the primary results. Full details on the experimental setup, including the datasets (e.g., simulation environments and real-world sequences), baselines, number of trials, error bars, and statistical tests, are provided in Section 4 (Experiments) of the manuscript. To address the concern about verifiability at the abstract level, we have revised the abstract to include a brief reference to the evaluation protocol and key metrics used. revision: yes
-
Referee: Abstract: The hardware-agnostic pipeline is asserted to process RGB observations from fixed external cameras and onboard robot cameras identically using a single feed-forward 3D reconstruction model with no hardware modifications or calibration. However, feed-forward models are typically sensitive to differences in intrinsics (focal length, principal point, distortion), extrinsics, and scale; no mechanism is described for on-the-fly normalization, pose estimation, or invariance that would prevent misalignment or scale errors in the fused scene graph, which would directly impact object recall and semantic uncertainty used for active exploration.
Authors: The framework processes all RGB inputs through the same feed-forward 3D reconstruction model, which recovers consistent geometry and semantics across views without explicit per-camera calibration. Pose estimation and scale alignment emerge from the multi-view reconstruction process itself, and the model was selected for its robustness to typical variations in consumer RGB cameras. We acknowledge that further elaboration improves clarity and have expanded the Methods section with additional details on the reconstruction pipeline's invariance properties and how misalignment is mitigated in practice. revision: yes
Circularity Check
No circularity; experimental results and pipeline design are independent of inputs
full rationale
The paper presents an RGB-only active 3D scene graph framework that treats fixed external cameras as Common Prior Maps and fuses them with onboard observations via a feed-forward reconstruction model. Central claims rest on experimental measurements of object recall (+79%) and exploration efficiency gains. No equations, fitted parameters, or self-citations are shown that would reduce any prediction or first-principles result to the inputs by construction. The hardware-agnostic fusion is stated as an explicit design choice rather than derived circularly. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Common Prior Maps (CPMs)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By relying solely on RGB observations processed by a feed-forward 3D reconstruction model, the system treats all cameras - onboard or external - identically, requiring no hardware modifications.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments demonstrate that bootstrapping the scene graph with even a single external camera increases initial object recall by up to +79%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Deep learning- based scene understanding for autonomous robots: A survey,
J. Ni, Y . Chen, G. Tang, J. Shi, W. Cao, and P. Shi, “Deep learning- based scene understanding for autonomous robots: A survey,”Intelli- gence & Robotics, vol. 3, no. 3, pp. 374–401, 2023
work page 2023
-
[2]
Scene graph generation by iterative message passing,
D. Xu, Y . Zhu, C. B. Choy, and L. Fei-Fei, “Scene graph generation by iterative message passing,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 5410–5419
work page 2017
-
[3]
Scene graph generation: A comprehensive survey,
H. Li, G. Zhu, L. Zhang, Y . Jiang, Y . Dang, H. Hou, P. Shen, X. Zhao, S. A. A. Shah, and M. Bennamoun, “Scene graph generation: A comprehensive survey,”Neurocomputing, vol. 566, p. 127052, 2024
work page 2024
-
[4]
A survey on 3d scene graphs: Definition, generation and application,
J. Bae, D. Shin, K. Ko, J. Lee, and U.-H. Kim, “A survey on 3d scene graphs: Definition, generation and application,” inInternational Con- ference on Robot Intelligence Technology and Applications. Springer, 2022, pp. 136–147
work page 2022
-
[5]
SayPlan: Grounding large language models using 3d scene graphs for scalable robot task planning,
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Suenderhauf, “Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning,”arXiv preprint arXiv:2307.06135, 2023
-
[6]
Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,
A. Werby, C. Huang, M. B ¨uchner, A. Valada, and W. Burgard, “Hierarchical open-vocabulary 3d scene graphs for language-grounded robot navigation,” inFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024, 2024
work page 2024
-
[7]
Roboexp: Action-conditioned scene graph via interactive ex- ploration for robotic manipulation,
H. Jiang, B. Huang, R. Wu, Z. Li, S. Garg, H. Nayyeri, S. Wang, and Y . Li, “Roboexp: Action-conditioned scene graph via interactive ex- ploration for robotic manipulation,”arXiv preprint arXiv:2402.15487, 2024
-
[8]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keetha, N. M ¨uller, J. Sch ¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antuneset al., “Mapany- thing: Universal feed-forward metric 3d reconstruction,”arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
3d scene graphs in robotics: A unified represen- tation bridging geometry, semantics, and action,
I. Catalano, C. C. Zumaya, J. A. Placed, J. Civera, W. M. Bessa, and J. Pe ˜na-Queralta, “3d scene graphs in robotics: A unified represen- tation bridging geometry, semantics, and action,”Authorea Preprints, 2025
work page 2025
- [10]
-
[11]
Scenegraph- fusion: Incremental 3d scene graph prediction from rgb-d sequences,
S.-C. Wu, J. Wald, K. Tateno, N. Navab, and F. Tombari, “Scenegraph- fusion: Incremental 3d scene graph prediction from rgb-d sequences,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7515–7525
work page 2021
-
[12]
Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappaet al., “Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5021–5028
work page 2024
-
[13]
Revisiting active per- ception,
R. Bajcsy, Y . Aloimonos, and J. K. Tsotsos, “Revisiting active per- ception,”Autonomous Robots, vol. 42, no. 2, pp. 177–196, 2018
work page 2018
-
[14]
A frontier-based approach for autonomous exploration,
B. Yamauchi, “A frontier-based approach for autonomous exploration,” inProceedings 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation CIRA’97. ’Towards New Com- putational Principles for Robotics and Automation’. IEEE, 1997, pp. 146–151
work page 1997
-
[15]
The surface edge explorer (see): A measurement-direct approach to next best view planning,
R. Border and J. D. Gammell, “The surface edge explorer (see): A measurement-direct approach to next best view planning,”The International Journal of Robotics Research, vol. 43, no. 10, pp. 1506– 1532, 2024
work page 2024
-
[16]
Sea: Semantic map prediction for active exploration of uncertain areas,
H. Ding, X. Liang, Y . Fang, Y . Wu, J. Shi, J. Huo, W. Li, J. Wu, Y .-K. Lai, and Y . Gao, “Sea: Semantic map prediction for active exploration of uncertain areas,”arXiv preprint arXiv:2510.19766, 2025
-
[17]
Understanding while exploring: Semantics-driven active mapping,
L. Chen, H. Zhan, H. Yin, Y . Xu, and P. Mordohai, “Understanding while exploring: Semantics-driven active mapping,”arXiv preprint arXiv:2506.00225, 2025
-
[18]
H. Tang and P. Chaudhari, “Active semantic perception,”arXiv preprint arXiv:2510.05430, 2025
-
[19]
Robot-relay: Building-wide, calibration-less visual servoing with learned sensor handover networks,
L. Robinson, M. Gadd, P. Newman, and D. D. Martini, “Robot-relay: Building-wide, calibration-less visual servoing with learned sensor handover networks,”Autonomous Robots, vol. 50, no. 1, p. 3, 2026
work page 2026
-
[20]
Select2plan: Training-free icl-based planning through vqa and memory retrieval,
D. Buoso, L. Robinson, G. Averta, P. Torr, T. Franzmeyer, and D. De Martini, “Select2plan: Training-free icl-based planning through vqa and memory retrieval,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[21]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
work page 2023
-
[22]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[23]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 conference on empirical methods in natural language processing and the 9th in- ternational joint conference on natural language processing (EMNLP- IJCNLP), 2019, pp. 3982–3992
work page 2019
-
[24]
The Replica Dataset: A Digital Replica of Indoor Spaces
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Vermaet al., “The replica dataset: A digital replica of indoor spaces,”arXiv preprint arXiv:1906.05797, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[25]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Maliket al., “Habitat: A platform for embodied ai research,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9339–9347
work page 2019
-
[26]
Habitat 2.0: Training home assistants to rearrange their habitat,
A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y . Zhao, J. Turner, N. Maestre, M. Mukadam, D. S. Chaplot, O. Maksymetset al., “Habitat 2.0: Training home assistants to rearrange their habitat,” Advances in neural information processing systems, vol. 34, pp. 251– 266, 2021
work page 2021
-
[27]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayrac, J. Yu, R. Soricut, J. Schalkwyk, A. M. Dai, A. Hauth, K. Millicanet al., “Gem- ini: a family of highly capable multimodal models,”arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.