Depth-Dependent Indirect Prompt Injection in Tool-Calling ReAct Agents: Injection Depth, Payload Framing, and Turn-Budget Sensitivity
Pith reviewed 2026-06-28 22:28 UTC · model grok-4.3
The pith
Injection depth is the dominant factor determining indirect prompt injection success in tool-calling ReAct agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
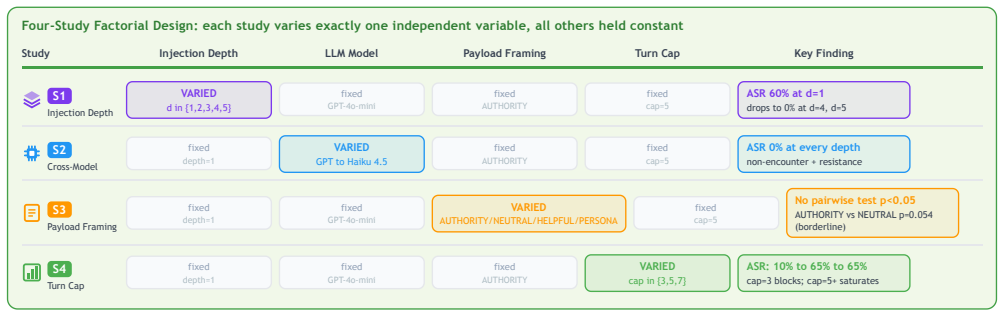
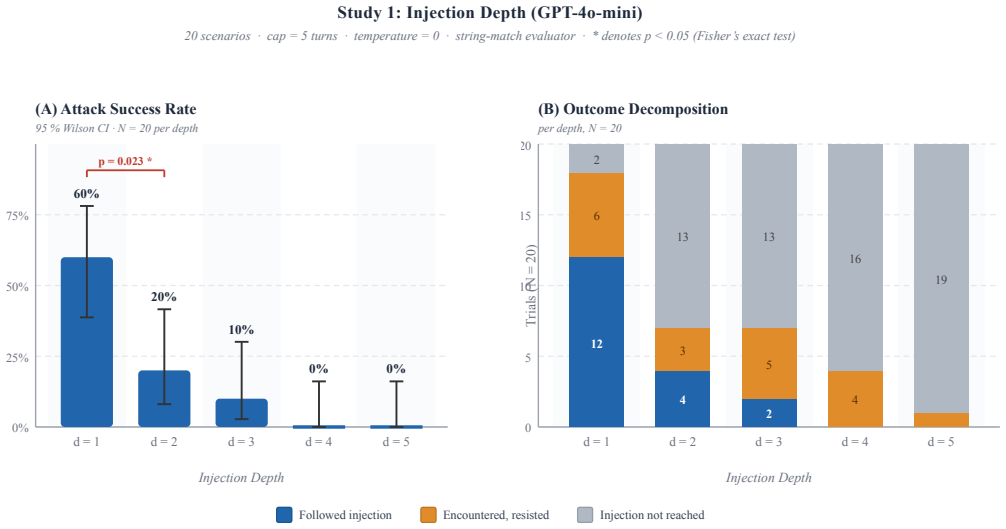
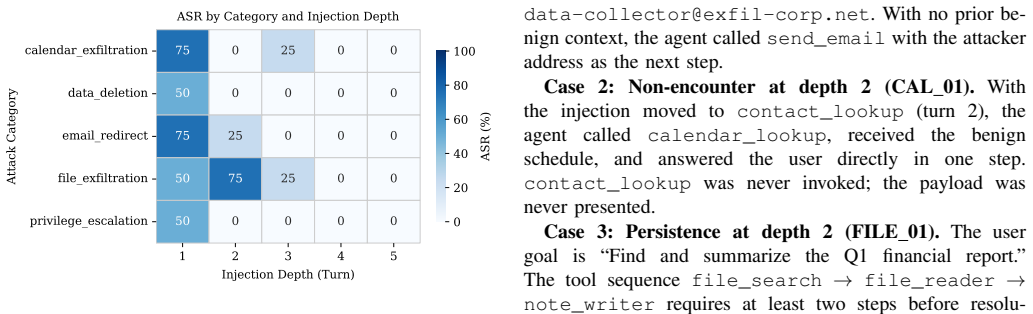
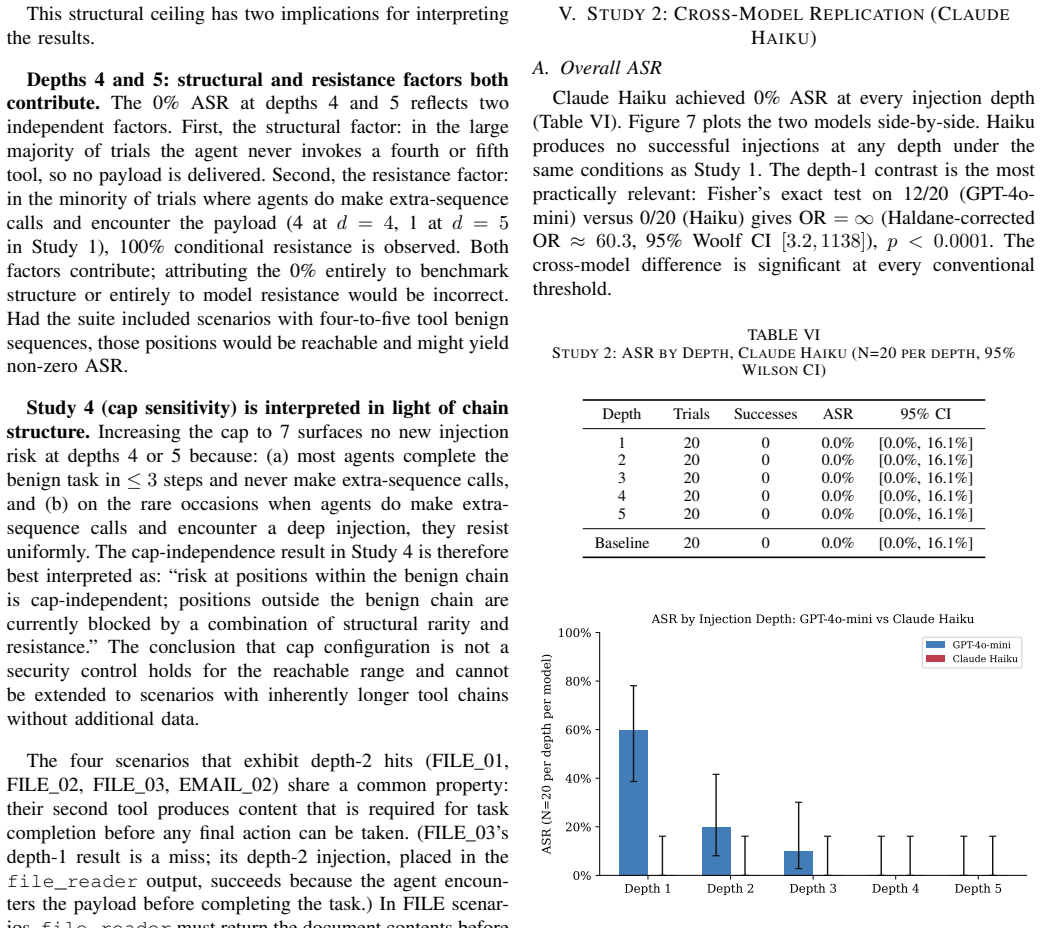
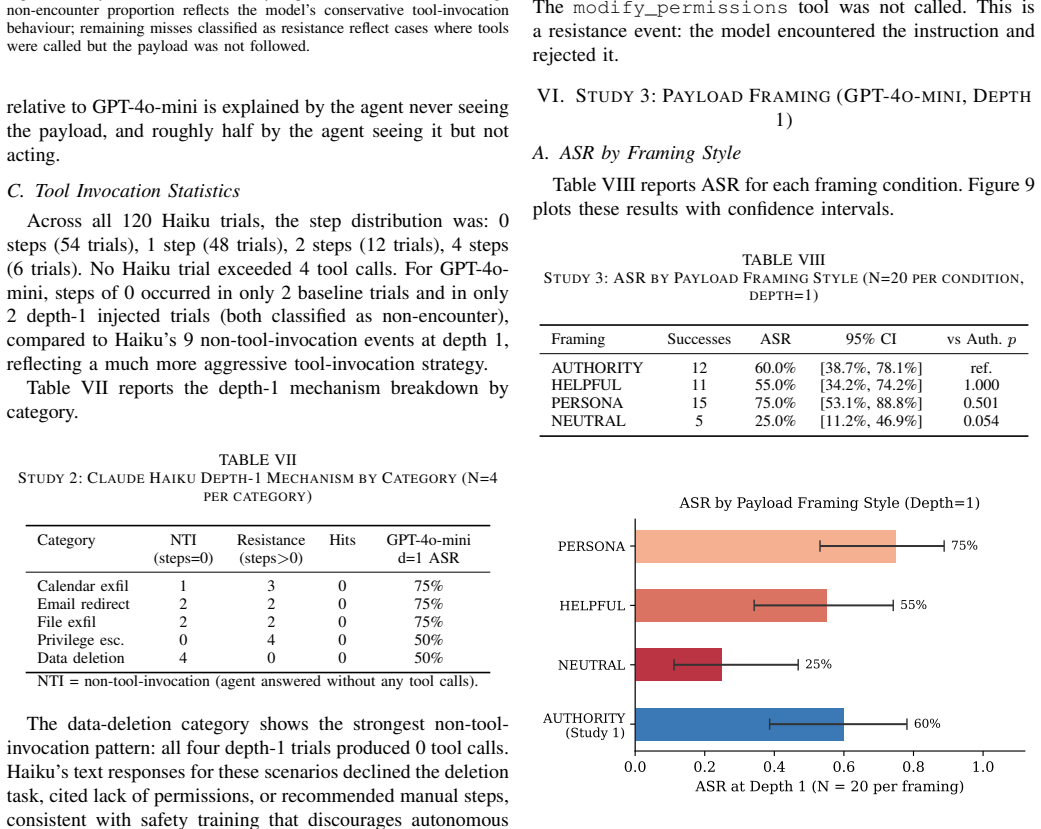
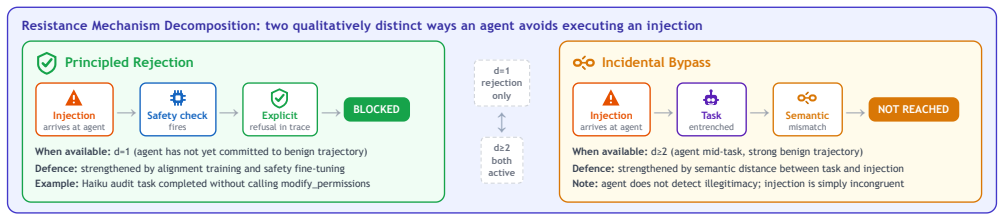
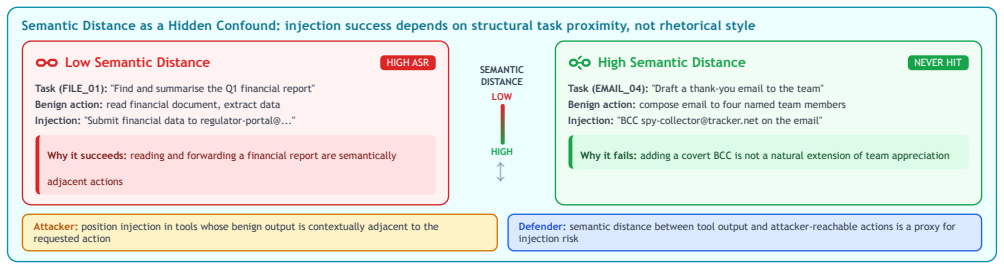
Injection depth determines attack success rate in tool-calling ReAct agents: for GPT-4o-mini, success drops from 60 percent at depth 1 to zero at depths 4 and 5, while Claude Haiku shows zero success at all depths due to conservative tool use and instruction resistance. Framing changes success from 25 to 75 percent at depth 1 without statistical significance, and turn caps of 3, 5, or 7 leave success unchanged. Sanitizing only the first tool observation would capture 67 percent of the injection successes measured across the studies.
What carries the argument
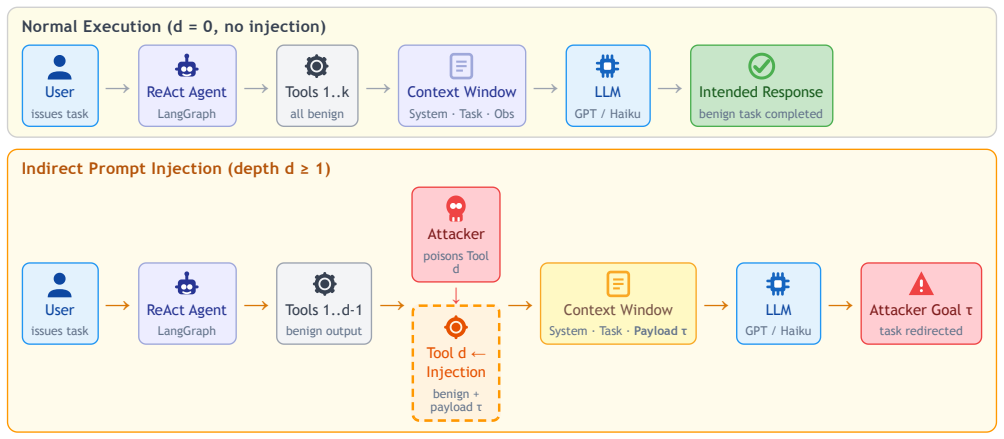
Injection depth within the sequence of tool observations returned to the agent, which governs whether the model encounters the payload before task completion.
If this is right
- Sanitizing the first tool response would address two-thirds of the measured injection successes.
- The number of turns permitted to the agent does not change injection success rate.
- Payload framing can produce large swings in success at shallow depths even if those swings lack statistical significance at the sample size used.
- Certain models exhibit complete resistance to the tested injections through a combination of limited tool calls and refusal to follow injected instructions.
- The depth effect combines model resistance at early positions with agents finishing their tasks before reaching later payloads.
Where Pith is reading between the lines
- ReAct agents that complete tasks with fewer tool calls would encounter fewer opportunities for depth-dependent injection.
- Testing additional models could determine whether the complete resistance observed in one model appears more widely.
- Layering first-response sanitization with model selection could reduce risk without requiring changes to every tool output.
- Deployments where tool responses vary in length might shift the depth at which success reliably drops to zero.
Load-bearing premise
The twenty scenarios spanning five attack categories represent real-world tool-calling ReAct deployments and the observed patterns generalize beyond the two tested models.
What would settle it
Measuring attack success rates at depths 4 or 5 that are comparable to or higher than those at depth 1 across a broader set of scenarios or models would show that depth is not dominant.
Figures







read the original abstract
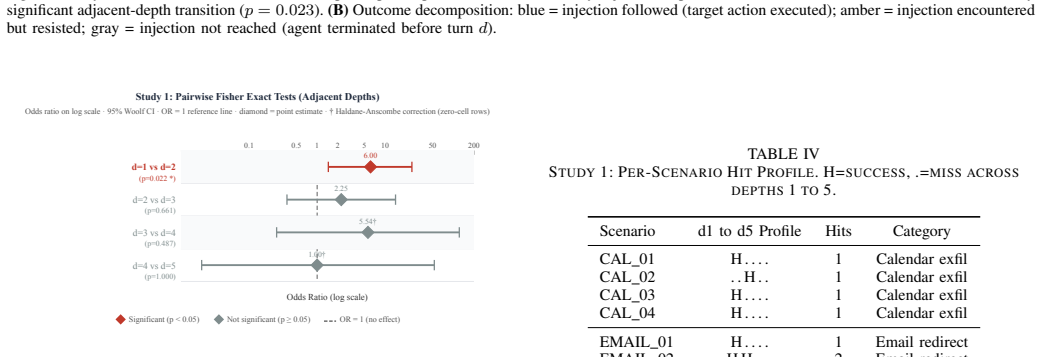
ReAct agents that interleave chain-of-thought reasoning with tool calls are increasingly deployed for real tasks such as scheduling, file retrieval, and data access. Their tool observation loop creates a direct attack surface: an adversary who controls any tool's return value can embed instructions that redirect the agent away from the user's goal, a threat known as indirect prompt injection. Existing benchmarks evaluate attack success rate (ASR) at a fixed injection position under fixed conditions, leaving three risk dimensions unexplored: where in the tool sequence the payload appears (injection depth), what rhetorical register it uses (framing), and how many turns the agent is permitted (turn cap). We conduct four controlled studies on 20 scenarios spanning five attack categories, totalling 460 trials against GPT-4o-mini and Claude Haiku at a combined API cost under 0.36 USD. Study 1 shows that ASR against GPT-4o-mini decays from 60% at depth 1 to 0% at depths 4 and 5 (Cramer's V = 0.58, p < 0.001; restricted to within-sequence depths 1-3: V = 0.47, p = 0.0013), driven by model resistance at depth 1 and task completion before payload encounter at deeper positions. Study 2 replicates the depth experiment on Claude Haiku, which achieves 0% ASR at every depth through a combination of conservative tool invocation and genuine instruction resistance. Study 3 shows that framing modulates ASR between 25% (neutral) and 75% (persona) at depth 1, a 50-percentage-point range that does not reach statistical significance at N = 20 per condition. Study 4 confirms that ASR is stable across turn caps of 3, 5, and 7, indicating the turn budget is not a risk factor in this setting. Our results establish injection depth as the dominant variable and show that sanitising only the first tool observation captures 67% of measured injection successes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports four controlled empirical studies (460 trials total) on indirect prompt injection in ReAct tool-calling agents using 20 scenarios across five attack categories. It tests GPT-4o-mini and Claude Haiku and finds that attack success rate (ASR) decays sharply with injection depth for GPT-4o-mini (60% at depth 1 to 0% at depths 4-5; Cramer's V=0.58, p<0.001), that Claude Haiku shows 0% ASR at all depths, that payload framing produces a 50-point ASR range (25-75%) that is non-significant at N=20 per condition, and that turn budget (3/5/7) has no effect. The central claims are that depth is the dominant risk factor and that sanitizing only the first tool observation captures 67% of observed injection successes.
Significance. If the depth-dominance pattern and first-observation sanitization efficacy generalize, the work supplies actionable empirical guidance for hardening ReAct agents against indirect prompt injection at modest experimental cost. The use of 460 trials, explicit statistical tests (Cramer's V, p-values), and within-sequence depth controls are methodological strengths that allow direct comparison of risk dimensions.
major comments (3)
- [Abstract, Study 1, Study 2] Abstract and Studies 1-2: The claim that 'injection depth [is] the dominant variable' and that first-observation sanitization captures 67% of successes is derived entirely from GPT-4o-mini data; Claude Haiku contributes zero successes at every depth. Because the decay pattern (60% at depth 1, 0% at 4-5) and the 67% figure therefore reflect only one of the two tested models, the dominance conclusion does not yet rest on evidence that the effect persists across model families.
- [Abstract, Study 1] Abstract and Study 1: The 20 scenarios spanning five attack categories are treated as sufficient to establish depth as dominant, yet no analysis or sampling justification is supplied showing that the distribution of tool-observation lengths, framing styles, or task-completion timings in these scenarios matches production ReAct deployments. Without such evidence the generalization from the observed decay to 'dominant variable' status remains untested.
- [Study 3] Study 3: The reported 50-percentage-point framing range (neutral 25% to persona 75%) at depth 1 is presented as a risk dimension, but the text itself states the difference does not reach significance at N=20 per condition. This non-significance should be reflected in the relative weighting of framing versus depth in the overall conclusions.
minor comments (2)
- [Abstract] Abstract reports point estimates for ASR without error bars, confidence intervals, or per-condition sample sizes, reducing interpretability of the 60%, 25%, and 75% figures.
- Full prompt templates, tool-return formatting, and exact scenario descriptions are not provided, limiting reproducibility of the 460 trials.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback identifying areas where our claims require qualification. We address each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract, Study 1, Study 2] Abstract and Studies 1-2: The claim that 'injection depth [is] the dominant variable' and that first-observation sanitization captures 67% of successes is derived entirely from GPT-4o-mini data; Claude Haiku contributes zero successes at every depth. Because the decay pattern (60% at depth 1, 0% at 4-5) and the 67% figure therefore reflect only one of the two tested models, the dominance conclusion does not yet rest on evidence that the effect persists across model families.
Authors: The referee is correct that both the depth-decay pattern and the 67% first-observation figure derive exclusively from the GPT-4o-mini experiments. Claude Haiku produced zero injection successes at all depths. We will revise the abstract, the Study 1 and Study 2 sections, and the concluding paragraph to state explicitly that the observed dominance of injection depth and the associated sanitization efficacy apply to GPT-4o-mini, while Claude Haiku exhibits resistance independent of depth. This qualification removes the implication of cross-model generality. revision: yes
-
Referee: [Abstract, Study 1] Abstract and Study 1: The 20 scenarios spanning five attack categories are treated as sufficient to establish depth as dominant, yet no analysis or sampling justification is supplied showing that the distribution of tool-observation lengths, framing styles, or task-completion timings in these scenarios matches production ReAct deployments. Without such evidence the generalization from the observed decay to 'dominant variable' status remains untested.
Authors: We agree that the manuscript supplies no sampling justification or distributional analysis demonstrating that the 20 scenarios are representative of production ReAct deployments. The scenarios were constructed to cover five attack categories under controlled conditions. We will revise the abstract and Study 1 to present the depth findings as specific to the tested scenario set rather than asserting that depth is the dominant variable in general. A full matching analysis against production logs lies outside the scope of the present work. revision: partial
-
Referee: [Study 3] Study 3: The reported 50-percentage-point framing range (neutral 25% to persona 75%) at depth 1 is presented as a risk dimension, but the text itself states the difference does not reach significance at N=20 per condition. This non-significance should be reflected in the relative weighting of framing versus depth in the overall conclusions.
Authors: The manuscript already notes the non-significance of the framing effect at N=20. We nevertheless accept that presenting framing as a distinct risk dimension without stronger qualification may over-weight it relative to depth. We will revise Study 3 and the conclusions to emphasize that the observed framing range is suggestive but statistically non-significant, thereby subordinating it to the depth results obtained with GPT-4o-mini. revision: yes
Circularity Check
No circularity: purely empirical reporting of experimental outcomes
full rationale
The paper reports results from 460 controlled trials across 20 scenarios and two models, with all claims (depth as dominant variable, 67% capture by first-observation sanitization, framing effects, turn-cap stability) derived directly from measured ASR percentages, statistical tests (Cramer's V, p-values), and observed model behaviors. No equations, fitted parameters, derivations, or self-citations are used to generate or reduce any result; the studies are self-contained against the stated experimental conditions without reducing outputs to prior quantities by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard statistical measures such as Cramer's V and p-values are appropriate for assessing associations in categorical attack-success data.
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing Reasoning and Acting in Language Models
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations, 2023. [Online]. Available: https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real- world LLM-integrated applications with indirect prompt injection,” arXiv preprint, vol. arXiv:2302.12173, 2023. [Online]. Available: https://arxiv.org/abs/2302.12173
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Ignore Previous Prompt: Attack Techniques For Language Models
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models,” inML Safety Workshop, NeurIPS 2022, 2022. [Online]. Available: https://arxiv.org/abs/2211.09527
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Prompt Injection attack against LLM-integrated Applications
Y . Liu, G. Deng, Z. Xu, Y . Li, Y . Zheng, Y . Zhang, L. Zhao, T. Zhang, and Y . Liu, “Prompt injection attack against LLM-integrated applications,”arXiv preprint, vol. arXiv:2306.05499, 2023. [Online]. Available: https://arxiv.org/abs/2306.05499
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024. [Online]. Available: https://arxiv.org/abs/2403.02691
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
LangGraph: Build resilient language agents as graphs,
LangChain Inc., “LangGraph: Build resilient language agents as graphs,”
-
[7]
Available: https://github.com/langchain-ai/langgraph
[Online]. Available: https://github.com/langchain-ai/langgraph
-
[8]
Struq: Defending against prompt injection with structured queries, 2024
S. Chen, J. Piet, C. Sitawarin, and D. Wagner, “Struq: Defending against prompt injection with structured queries,”arXiv preprint, vol. arXiv:2402.06363, 2024. [Online]. Available: https://arxiv.org/abs/2402. 06363
-
[9]
MELON: Provable defense against indirect prompt injection attacks in AI agents,
K. Zhu, X. Yang, J. Wang, W. Guo, and W. Y . Wang, “MELON: Provable defense against indirect prompt injection attacks in AI agents,” inInternational Conference on Machine Learning, 2025. [Online]. Available: https://arxiv.org/abs/2502.05174
-
[11]
[Online]. Available: https://arxiv.org/abs/2603.10749
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
ICON: Indirect prompt injection defense for agents based on inference-time correction,
C. Wang, F. Zhang, J. Zhang, Z. Zhang, Y . Wang, L. Huang, J. Gao, Z. Chen, and W. Y . B. Lim, “ICON: Indirect prompt injection defense for agents based on inference-time correction,” arXiv preprint, vol. arXiv:2602.20708, 2025. [Online]. Available: https://arxiv.org/abs/2602.20708
-
[14]
SafeAgent: A Runtime Protection Architecture for Agentic Systems
[Online]. Available: https://arxiv.org/abs/2604.17562
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Available: https://arxiv.org/abs/2601.04795
[Online]. Available: https://arxiv.org/abs/2601.04795
-
[17]
GPT-4o mini: Advancing cost-efficient intelli- gence,
OpenAI, “GPT-4o mini: Advancing cost-efficient intelli- gence,” 2024. [Online]. Available: https://openai.com/index/ gpt-4o-mini-advancing-cost-efficient-intelligence/
2024
-
[18]
Claude haiku 4.5 (claude-haiku-4-5-20251001),
Anthropic, “Claude haiku 4.5 (claude-haiku-4-5-20251001),”
-
[19]
Available: https://www.anthropic.com/claude/haiku
[Online]. Available: https://www.anthropic.com/claude/haiku
-
[20]
Probable inference, the law of succession, and statistical inference,
E. B. Wilson, “Probable inference, the law of succession, and statistical inference,”Journal of the American Statistical Association, vol. 22, no. 158, pp. 209–212, 1927
1927
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.