E-VLA: Event-Augmented Vision-Language-Action Model for Dark and Blurred Scenes
Pith reviewed 2026-05-10 20:18 UTC · model grok-4.3
The pith
Event-augmented VLA models restore robotic manipulation success in dark and blurred scenes via direct event fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
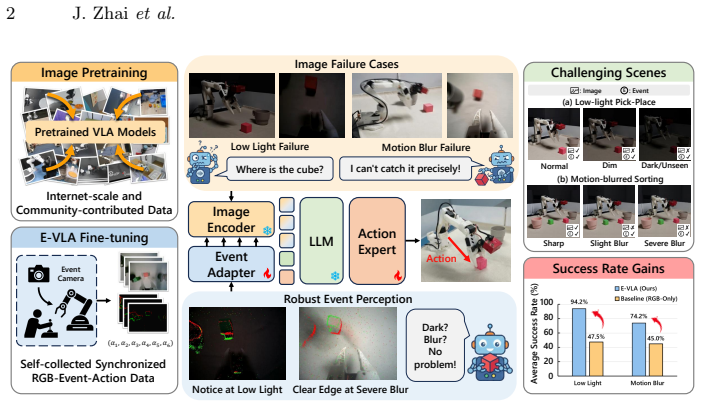
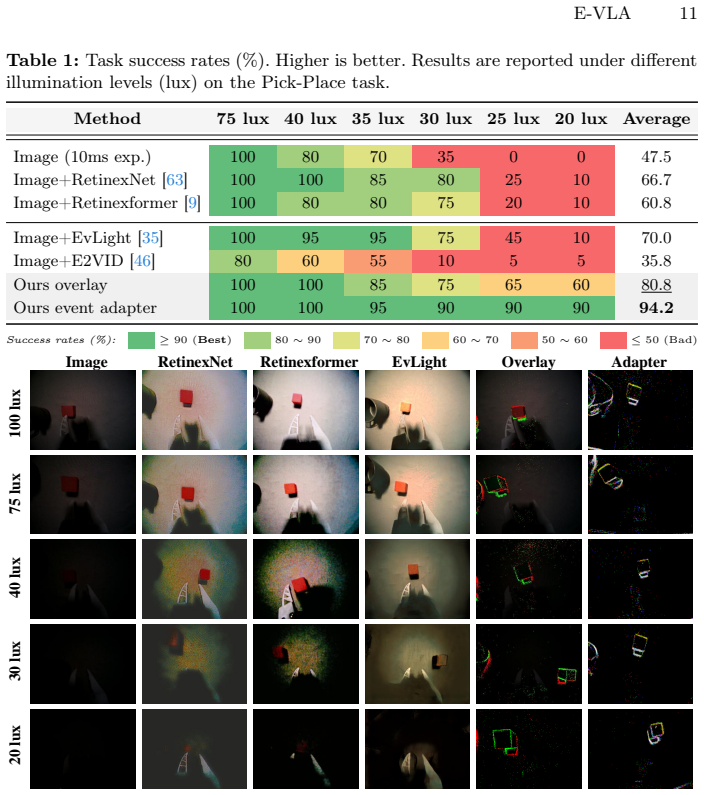
E-VLA demonstrates that directly leveraging motion and structural cues in event streams preserves semantic perception and perception-action consistency in VLA models under adverse conditions such as extreme low light and motion blur, rather than attempting to reconstruct images from events. Experiments on a collected real-world dataset demonstrate that parameter-free overlay fusion of accumulated event maps onto RGB images raises Pick-Place success from 0% to 60% at 20 lux and to 20-25% under 1000 ms blur, with further gains using an event adapter.
What carries the argument
Overlay fusion of accumulated event maps onto RGB images, along with a lightweight pretrained-compatible event adapter, which injects motion cues directly into the VLA visual input to maintain performance when conventional frames degrade.
Load-bearing premise
The real-world RGB-event-action dataset and the selected tasks plus illumination conditions are representative enough that the observed robustness gains will hold for other robots, tasks, and VLA backbones.
What would settle it
Running the Pick-Place task at 20 lux illumination on a different robot arm or unseen VLA backbone and measuring no meaningful success improvement over the image-only baseline would show the gains do not transfer.
Figures


read the original abstract
Robotic Vision-Language-Action (VLA) models generalize well for open-ended manipulation, but their perception is fragile under sensing-stage degradations such as extreme low light, motion blur, and black clipping. We present E-VLA, an event-augmented VLA framework that improves manipulation robustness when conventional frame-based vision becomes unreliable. Instead of reconstructing images from events, E-VLA directly leverages motion and structural cues in event streams to preserve semantic perception and perception-action consistency under adverse conditions. We build an open-source teleoperation platform with a DAVIS346 event camera and collect a real-world synchronized RGB-event-action manipulation dataset across diverse tasks and illuminations. We also propose lightweight, pretrained-compatible event integration strategies and study event windowing for stable deployment. Experiments show that even a simple parameter-free fusion, i.e., overlaying accumulated event maps onto RGB images, could substantially improve robustness in dark and heavy-blur scenes: on Pick-Place at 20 lux, success increases from 0% (image-only) to 60% with overlay fusion and to 90% with our event adapter; under severe motion blur (1000 ms-exposure proxy), Pick-Place improves from 0% to 20-25%, and Sorting from 5% to 32.5%. Overall, E-VLA provides systematic evidence that event-driven perception can be effectively integrated into VLA models, pointing toward robust embodied intelligence beyond conventional frame-based imaging. Code and dataset will be available at https://github.com/JJayzee/E-VLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces E-VLA, a framework augmenting Vision-Language-Action (VLA) models with event-camera streams to improve robotic manipulation robustness under low illumination and motion blur. It describes collection of a synchronized real-world RGB-event-action dataset using a DAVIS346 camera across diverse tasks and lighting, proposes lightweight pretrained-compatible integration methods (parameter-free event-map overlay and a learned event adapter), and reports empirical success-rate gains on tasks such as Pick-Place and Sorting (e.g., 0% to 60% at 20 lux with overlay, 0% to 90% with adapter; 0% to 20-25% under 1000 ms blur).
Significance. If the reported gains prove reproducible, the work supplies concrete evidence that event-based motion cues can be fused into existing VLA pipelines to recover performance where RGB perception collapses, without requiring full image reconstruction. The open release of the dataset and code is a clear strength that supports reproducibility and follow-on research. The significance is limited by the narrow scope of tested conditions and backbones.
major comments (3)
- [§4.2] §4.2 (Event Integration Strategies): The abstract and methods describe the overlay fusion as 'parameter-free,' yet the event accumulation window must be selected and is not ablated across the reported conditions; this choice directly affects the input to the VLA and therefore the measured gains (e.g., the 60% success figure on Pick-Place at 20 lux).
- [Experiments section] Experiments section (Tables 1-2 and associated text): Success rates are given as single point estimates (0%, 60%, 90%, etc.) without trial counts, standard deviations, or statistical significance tests, preventing assessment of whether the claimed improvements over the image-only baseline are reliable.
- [§5] §5 (Discussion and Conclusion): The broader claim that E-VLA provides 'systematic evidence' for robust embodied intelligence rests on a single custom dataset and one VLA backbone; no cross-backbone evaluation or external benchmark results are presented, leaving the generalization premise untested.
minor comments (2)
- [Figure 2] Figure 2: The event-map overlay examples would be clearer if the accumulation window and polarity rendering parameters were stated in the caption.
- [Related Work] Related Work: Several recent papers on event-based robotic perception (e.g., event-driven SLAM or low-light tracking) are not cited; adding them would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Event Integration Strategies): The abstract and methods describe the overlay fusion as 'parameter-free,' yet the event accumulation window must be selected and is not ablated across the reported conditions; this choice directly affects the input to the VLA and therefore the measured gains (e.g., the 60% success figure on Pick-Place at 20 lux).
Authors: We thank the referee for this observation. The descriptor 'parameter-free' specifically denotes that the overlay fusion introduces no trainable parameters (in contrast to the learned event adapter). The accumulation window is a fixed hyperparameter; while the manuscript states that event windowing was studied, we did not include a dedicated ablation table quantifying its effect on the reported success rates. In the revision we will add an ablation study across multiple window sizes for the low-light and motion-blur conditions to show sensitivity of the gains. revision: yes
-
Referee: [Experiments section] Experiments section (Tables 1-2 and associated text): Success rates are given as single point estimates (0%, 60%, 90%, etc.) without trial counts, standard deviations, or statistical significance tests, preventing assessment of whether the claimed improvements over the image-only baseline are reliable.
Authors: We agree that single-point estimates limit reliability assessment. Each reported success rate was computed from 20 independent trials per condition. We will revise Tables 1–2 and the accompanying text to report trial counts, mean success rates with standard deviations, and paired statistical significance tests against the image-only baseline. revision: yes
-
Referee: [§5] §5 (Discussion and Conclusion): The broader claim that E-VLA provides 'systematic evidence' for robust embodied intelligence rests on a single custom dataset and one VLA backbone; no cross-backbone evaluation or external benchmark results are presented, leaving the generalization premise untested.
Authors: We acknowledge the scope limitation. The custom dataset was collected because no public synchronized RGB-event-action manipulation dataset existed at the time, and evaluation was performed on a representative VLA backbone to demonstrate integration feasibility. We will revise the discussion and conclusion to moderate the language, explicitly stating that the results supply evidence for the proposed integration methods under the tested conditions and backbone while noting the value of future cross-backbone and benchmark studies. No additional backbone experiments will be added in this revision. revision: partial
Circularity Check
No circularity: empirical gains measured directly on collected dataset
full rationale
The paper's central claims consist of measured success-rate improvements (0% to 60-90% on Pick-Place at 20 lux, 0% to 20-25% under 1000 ms blur) obtained by running standard VLA models plus simple fusion or adapter on a newly collected teleoperated RGB-event-action dataset. No equations, fitted parameters, or self-citations are invoked to derive these numbers; the results are direct experimental outputs. The work contains no self-definitional loops, no predictions that reduce to fitted inputs by construction, and no load-bearing uniqueness theorems imported from prior author work. The derivation chain is therefore self-contained empirical reporting rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- event accumulation window
axioms (1)
- domain assumption Event streams provide reliable motion and structural cues under low light and motion blur where frame-based RGB fails.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
even a simple parameter-free fusion, i.e., overlaying accumulated event maps onto RGB images... on Pick-Place at 20 lux, success increases from 0% to 60%
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose lightweight, pretrained-compatible event integration strategies and study event windowing and fusion
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
SA-VLA: State-aware tokenizer for improving Vision-Language-Action Models' performance
SA-VLA adds state conditioning to VQ-based action tokenization in VLA policies, expanding each discrete token's effective support to state-dependent actions and raising average success rates from 0.29 to 0.56 on 12 si...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.