AnnotateAnything: Automatic Annotation of 3D Assets for Robot Manipulation
Pith reviewed 2026-06-27 01:13 UTC · model grok-4.3
The pith
AnnotateAnything converts raw 3D assets into manipulation-ready objects by pairing vision-language reasoning with physics-based action generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
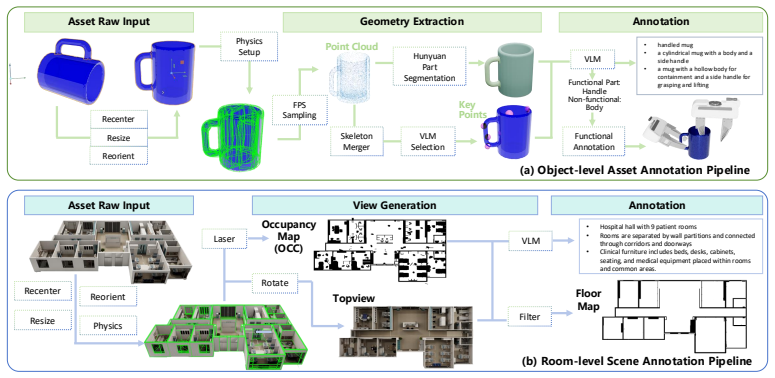
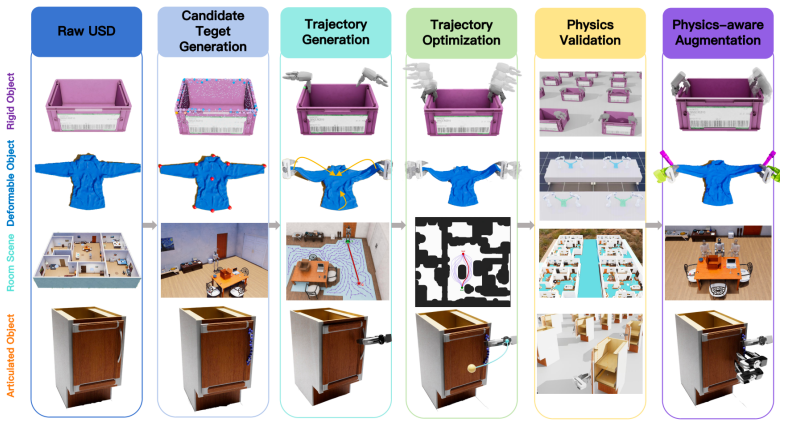
AnnotateAnything turns passive 3D assets into manipulation-ready assets with structured, diverse, and executable manipulation labels. It does so via a unified visual-language annotation pipeline that uses vision-language reasoning to infer object semantics, interaction constraints, and 3D-grounded cues, followed by a fully automatic and massively parallel physics annotation pipeline that grounds these priors through candidate generation, geometry optimization, and trajectory generation to produce grasp poses, dexterous contacts, articulation waypoints, insertion directions, hanging affordances, and navigation targets.
What carries the argument
Two complementary pipelines: a visual-language reasoning stage that supplies human-prior guidance on interaction regions and a physics stage that performs candidate generation, geometry optimization, and trajectory generation to produce executable labels.
If this is right
- Annotation efficiency exceeds that of existing manual and automatic pipelines.
- Data-collection efficiency increases through asynchronous parallel simulation across objects, tasks, and robot embodiments.
- Task success rates rise on manipulation benchmarks relative to prior data-generation methods.
- Generated labels directly support downstream applications including affordance detection, robotic visual question answering, and visual instruction finetuning.
Where Pith is reading between the lines
- Public repositories of 3D models could become immediate sources of robot training data once the annotation step is removed from the critical path.
- The same pipelines might be applied to scanned real-world objects if the physics stage is extended to tolerate sensor noise.
- Task instructions for visual finetuning could be derived automatically from the same semantic and constraint outputs without separate human authoring.
Load-bearing premise
The vision-language reasoning pipeline produces accurate human-prior guidance on interaction regions and constraints that the physics pipeline can ground into executable actions without systematic errors or the need for manual fixes.
What would settle it
Measure task success rates of robot policies trained on annotations produced by AnnotateAnything versus policies trained on the same assets with manual or alternative automatic annotations; rates below the manual baseline on held-out tasks would falsify the central efficiency and quality claim.
Figures














read the original abstract
Simulation enables scalable robot data collection, but raw 3D assets provide only geometry, lacking the semantic, interactive, and physical knowledge needed to specify where and how robots should act. In this work, we present AnnotateAnything, a general automatic annotation framework that converts passive 3D assets into manipulation-ready assets with structured, diverse, and executable manipulation labels. AnnotateAnything is built around two complementary pipelines. First, a unified visual-language annotation pipeline using vision-language reasoning to infer object semantics, interaction constraints, and 3D-grounded cues, providing human-prior guidance for identifying meaningful interaction regions. Second, a fully automatic and massively parallel physics annotation pipeline grounds these priors in each asset's geometry and physical constraints through candidate generation, geometry optimization and trajectory generation. This pipeline produces diverse and executable action annotations, including grasp poses, dexterous contacts, articulation waypoints, insertion directions, hanging affordances, and navigation targets. Using the generated annotations, we further build an asynchronous parallel simulation data-collection system across diverse objects, tasks, and robot embodiments. Experiments demonstrate that AnnotateAnything achieves superior annotation efficiency, data-collection efficiency, and task success rates over existing annotation and data-generation pipelines, while also supporting downstream tasks such as affordance detection, robotic VQA, and visual instruction finetuning. We provide project materials on the project page and plan to release the full code, annotations, and benchmark to facilitate future research. Videos, code, demo assets, and annotations are provided in supplementary materials Project page: https://tourmaline-caramel-169490.netlify.app.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AnnotateAnything, an automatic annotation framework for 3D assets that combines a vision-language reasoning pipeline (to infer semantics, interaction constraints, and 3D-grounded cues) with a parallel physics pipeline (for candidate generation, geometry optimization, and trajectory generation). This produces structured manipulation labels such as grasp poses, dexterous contacts, articulation waypoints, and affordances. The annotations enable an asynchronous parallel simulation data-collection system, with claims of superior annotation efficiency, data-collection efficiency, and downstream task success rates compared to existing pipelines, plus support for affordance detection, robotic VQA, and visual instruction finetuning. The authors plan to release code, annotations, and benchmarks.
Significance. If the performance claims hold with rigorous evidence, the work could substantially reduce the manual effort required to prepare 3D assets for robot manipulation learning, enabling scalable data generation across diverse objects and embodiments. The explicit plan to release full code, annotations, and a benchmark is a clear strength that would support reproducibility and follow-on research.
major comments (3)
- [Abstract] Abstract: the central claim of superior annotation efficiency, data-collection efficiency, and task success rates is asserted without any quantitative metrics, error bars, dataset sizes, comparison baselines, or statistical tests, preventing evaluation of whether the VLM-plus-physics pipeline actually outperforms existing methods.
- [Method (VLM pipeline)] VLM pipeline description: the load-bearing assumption that vision-language reasoning produces accurate human-prior guidance on interaction regions and constraints (without systematic semantic errors) is untested; no VLM error rates, inter-annotator agreement scores, or ablation isolating VLM contribution versus physics grounding are reported, so it is unclear whether downstream trajectories remain semantically valid when VLM outputs contain mistakes.
- [Experiments] Experiments section: the reported task success rates and efficiency gains lack details on the number of objects, robot embodiments, task categories, or statistical significance, making it impossible to assess whether the asynchronous parallel data-collection system delivers the claimed improvements over prior annotation pipelines.
minor comments (2)
- [Abstract] The abstract and method sections use terms such as 'human-prior guidance' and 'executable action annotations' without a precise definition or example of the output label format.
- [Conclusion] Project page and supplementary materials are referenced but no explicit list of released assets (e.g., number of annotated objects, annotation schema) is provided in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that add the requested quantitative details, analyses, and clarifications without altering the core claims or methodology.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of superior annotation efficiency, data-collection efficiency, and task success rates is asserted without any quantitative metrics, error bars, dataset sizes, comparison baselines, or statistical tests, preventing evaluation of whether the VLM-plus-physics pipeline actually outperforms existing methods.
Authors: We agree that the abstract would be strengthened by including concrete metrics. In the revised version we will add specific quantitative results drawn from the experiments section (e.g., annotation-time reductions, data-collection throughput, and task success rates with error bars, dataset sizes, and baseline comparisons) while preserving the high-level summary. revision: yes
-
Referee: [Method (VLM pipeline)] VLM pipeline description: the load-bearing assumption that vision-language reasoning produces accurate human-prior guidance on interaction regions and constraints (without systematic semantic errors) is untested; no VLM error rates, inter-annotator agreement scores, or ablation isolating VLM contribution versus physics grounding are reported, so it is unclear whether downstream trajectories remain semantically valid when VLM outputs contain mistakes.
Authors: The physics pipeline is designed to ground and correct VLM outputs through geometry optimization and constraint checking. We acknowledge that an explicit error analysis and ablation would improve transparency. In revision we will add VLM output accuracy metrics on a held-out subset and an ablation comparing full pipeline performance with and without VLM priors. revision: yes
-
Referee: [Experiments] Experiments section: the reported task success rates and efficiency gains lack details on the number of objects, robot embodiments, task categories, or statistical significance, making it impossible to assess whether the asynchronous parallel data-collection system delivers the claimed improvements over prior annotation pipelines.
Authors: We will expand the experiments section to report the exact numbers of objects, embodiments, and task categories used, together with statistical significance tests (e.g., paired t-tests or Wilcoxon tests) and confidence intervals for all efficiency and success-rate comparisons. revision: yes
Circularity Check
No circularity: pipeline claims rest on independent experimental evaluation
full rationale
The paper presents AnnotateAnything as a two-stage annotation system (VLM reasoning followed by physics grounding) that generates labels for downstream robot tasks. No mathematical derivations, fitted parameters renamed as predictions, or self-referential definitions appear in the provided text. Performance claims are supported by comparisons to existing pipelines on efficiency and task success metrics, which are external to the method's internal definitions. No load-bearing self-citations or uniqueness theorems are invoked. The central assumption about VLM reliability is an empirical claim open to falsification rather than a definitional reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pi-0.7: A steerable generalist robotic foundation model with emergent capabilities
Physical Intelligence. Pi-0.7: A steerable generalist robotic foundation model with emergent capabilities. arXiv preprint, 2026. CorpusID: 287607456
2026
-
[2]
Gr00t n1: An open foundation model for generalist humanoid robots
NVIDIA. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[3]
Gen-0: Embodied foundation models that scale with physical interaction
Generalist AI Team. Gen-0: Embodied foundation models that scale with physical interaction. Generalist AI Blog, 2025. November 4, 2025
2025
-
[4]
World action models are zero-shot policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, and Joel Jang. World action models are zero-shot policies. arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[5]
Egoscale: Scaling dexterous manipulation with diverse egocentric human data
Ruijie Zheng, Dantong Niu, Yuqi Xie, and Linxi Jim Fan. Egoscale: Scaling dexterous manipulation with diverse egocentric human data. arXiv:2602.16710, 2026
arXiv 2026
-
[6]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
Pith/arXiv arXiv 2025
-
[7]
Learning part-aware dense 3d feature field for generalizable articulated object manipulation, 2026
Yue Chen, Muqing Jiang, Kaifeng Zheng, Jiaqi Liang, Chenrui Tie, Haoran Lu, Ruihai Wu, and Hao Dong. Learning part-aware dense 3d feature field for generalizable articulated object manipulation, 2026. URLhttps://arxiv.org/abs/2602.14193
arXiv 2026
-
[8]
Ruihai Wu, Haozhe Chen, Mingtong Zhang, Haoran Lu, Yitong Li, and Yunzhu Li. Neural dynamics augmented diffusion policy. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 13234–13241, 2025. doi: 10.1109/ICRA55743.2025.11128651
-
[9]
Yan Shen, Ruihai Wu, Yubin Ke, Xinyuan Song, Zeyi Li, Xiaoqi Li, Hongwei Fan, Haoran Lu, and Hao Dong. Biassemble: Learning collaborative affordance for bimanual geometric assembly.ArXiv, abs/2506.06221, 2025. URL https://api.semanticscholar.org/ CorpusID:279244917
arXiv 2025
-
[10]
Broadcasting support relations recursively from local dynamics for object retrieval in clutters
Yitong Li, Ruihai Wu, Haoran Lu, Chuanruo Ning, Yan Shen, Guanqi Zhan, and Hao Dong. Broadcasting support relations recursively from local dynamics for object retrieval in clutters. ArXiv, abs/2406.02283, 2024. URL https://api.semanticscholar.org/CorpusID: 270226492
arXiv 2024
-
[11]
Garmentpile++: Affordance-driven cluttered garments retrieval with vision-language reasoning
Mingleyang Li, Yuran Wang, Yue Chen, Tianxing Chen, Jiaqi Liang, Zishun Shen, Haoran Lu, Ruihai Wu, and Hao Dong. Garmentpile++: Affordance-driven cluttered garments retrieval with vision-language reasoning. Preprint, 2026. CorpusID: 286238271
2026
-
[12]
Unigarmentmanip: A unified framework for category-level garment manipulation via dense visual correspondence
Ruihai Wu, Haoran Lu, Yiyan Wang, Yubo Wang, and Hao Dong. Unigarmentmanip: A unified framework for category-level garment manipulation via dense visual correspondence. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16340–16350, 2024. URL https://api.semanticscholar.org/CorpusID:269757227
2024
-
[13]
Learning to feel the future: Dreamtacvla for contact-rich manipulation.ArXiv, abs/2512.23864, 2025
Guo Ye, Zexi Zhang, Xu Zhao, Shang Wu, Haoran Lu, Shihan Lu, and Han Liu. Learning to feel the future: Dreamtacvla for contact-rich manipulation.ArXiv, abs/2512.23864, 2025. URLhttps://api.semanticscholar.org/CorpusID:284350273. 11
Pith/arXiv arXiv 2025
-
[14]
Haoran Geng, Feishi Wang, Songlin Wei, Yuyang Li, Bangjun Wang, Boshi An, Char- lie Tianyue Cheng, Haozhe Lou, Peihao Li, Yen-Jen Wang, Yutong Liang, Dylan Goetting, Chaoyi Xu, Haozhe Chen, Yuxi Qian, Yiran Geng, Jiageng Mao, Weikang Wan, Mingtong Zhang, Jiangran Lyu, Siheng Zhao, Jiazhao Zhang, Jialiang Zhang, Chengyang Zhao, Haoran Lu, Yufei Ding, Ran G...
arXiv 2025
-
[15]
Unigarment: A unified simulation and benchmark for garment manipulation
Haoran Lu, Yitong Li, Ruihai Wu, Chuanruo Ning, Yan Shen, and Hao Dong. Unigarment: A unified simulation and benchmark for garment manipulation. Preprint, 2024. CorpusID: 275782214
2024
-
[16]
Garmentlab: A unified simulation and benchmark for garment manipulation.ArXiv, abs/2411.01200, 2024
Haoran Lu, Ruihai Wu, Yitong Li, Sijie Li, Ziyu Zhu, Chuanruo Ning, Yan Shen, Longzan Luo, Yuanpei Chen, and Hao Dong. Garmentlab: A unified simulation and benchmark for garment manipulation.ArXiv, abs/2411.01200, 2024. URL https://api.semanticscholar.org/ CorpusID:273811186
arXiv 2024
-
[17]
Lightwheel kitchen: 3d kitchen asset collection for nvidia isaac sim
Lightwheel. Lightwheel kitchen: 3d kitchen asset collection for nvidia isaac sim. GitHub repos- itory, 2025. URL https://github.com/LightwheelAI/Lightwheel_Kitchen. Open- source 3D assets under CC BY-NC 4.0
2025
-
[18]
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Munoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[19]
Lw-benchhub: Lightwheel’s end-to-end embodied ai simulation platform
Lightwheel Team. Lw-benchhub: Lightwheel’s end-to-end embodied ai simulation platform. GitHub repository, 2025. URLhttps://github.com/lightwheel-ai/lw_benchhub
2025
-
[20]
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín- Martín, Chen Wang, Gabrael Levine, Wensi Ai, Benjamin Jose Martinez, Hang Yin, Michael Lingelbach, Minjune Hwang, Ayano Hiranaka, Sujay Garlanka, Arman Aydin, Sharon Lee, Jiankai Sun, Mona Anvari, Manasi Sharma, Dhruva Bansal, Samuel Hunter, Kyu-Young Kim, Alan Lou, Ca...
Pith/arXiv arXiv 2024
-
[21]
Mind to hand: Purposeful robotic control via embodied reasoning, 2025
Peijun Tang, Shangjin Xie, Binyan Sun, Baifu Huang, Kuncheng Luo, Haotian Yang, Weiqi Jin, and Jianan Wang. Mind to hand: Purposeful robotic control via embodied reasoning, 2025. URLhttps://arxiv.org/abs/2512.08580
arXiv 2025
-
[22]
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yani Ding, Zhigang Wang, Jiayuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. Spatialvla: Exploring spatial representations for visual-language-action model.ArXiv, abs/2501.15830, 2025. URL https://api.semanticscholar.org/CorpusID:275921131
Pith/arXiv arXiv 2025
-
[23]
Scalable trajectory generation for whole-body mobile manipulation
Yida Niu, Xinhai Chang, Xin Liu, Ziyuan Jiao, and Yixin Zhu. Scalable trajectory generation for whole-body mobile manipulation. InCVPR, 2026
2026
-
[24]
Molmob0t: Large-scale simulation enables zero-shot manipulation
Abhay Deshpande, Maya Guru, Rose Hendrix, Snehal Jauhri, Haoquan Fang, Wilbert Pumacay, Yejin Kim, Quinn Pfeifer, Ying-Chun Lee, Piper Wolters, Omar Rayyan, Mingtong Zhang, Karen Farley, Winson Han, Eli Vanderbilt, Dieter Fox, Ali Farhadi, Georgia Chalvatzaki, Dhruv Shah, and Ranjay Krishna. Molmob0t: Large-scale simulation enables zero-shot manipulation....
2026
-
[25]
Manitwin: Scaling data-generation-ready digital object dataset to 100k
Kaixuan Wang, Tianxing Chen, Jiawei Liu, Honghao Su, Shaolong Zhu, Minxuan Wang, Zixuan Li, Yue Chen, Huan-ang Gao, Yusen Qin, Jiawei Wang, Qixuan Zhang, Lan Xu, Jingyi Yu, Yao Mu, and Ping Luo. Manitwin: Scaling data-generation-ready digital object dataset to 100k. Preprint, 2026. CorpusID: 286583937. 12
2026
-
[26]
Baijun Chen, Weijie Wan, Tianxing Chen, Xianda Guo, Congsheng Xu, Yuanyang Qi, Haojie Zhang, Longyan Wu, Tianling Xu, Zixuan Li, et al. Univtac: A unified simulation platform for visuo-tactile manipulation data generation, learning, and benchmarking.arXiv preprint arXiv:2602.10093, 2026
arXiv 2026
-
[27]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Qiwei Liang, Zixuan Li, XianLian Lin, Yiheng Ge, Zhenyu Gu, Weiliang Deng, Yubin Guo, Tian Nian, Xuanbing Xie, Qiangyu Chen, Kailun Su, Tianling Xu, Guodong Liu, Mengkang Hu, Huan ang Gao, Kaixuan Wang, Zhixuan Liang, Yusen Qin, Xiaokang Yang, Ping Luo, and Yao Mu. Robotwin 2.0: A scalable da...
Pith/arXiv arXiv 2025
-
[28]
Tianxing Chen, Yuran Wang, Mingleyang Li, Yanjiao Qin, Haochen Shi, Zixuan Li, Yifan Hu, Yingsheng J Zhang, Kaixuan Wang, Yue Chen, Hongchen Wang, Renjing Xu, Ruihai Wu, Yao Mu, Yaodong Yang, Hao Dong, and Ping Luo. Rmbench: Memory-dependent robotic manipulation benchmark with insights into policy design.ArXiv, abs/2603.01229, 2026. URL https://api.semant...
arXiv 2026
-
[29]
Yang Tian, Yuyin Yang, Yiman Xie, Zetao Cai, Xu Shi, Ning Gao, Hangxu Liu, Xuekun Jiang, Zherui Qiu, Feng Yuan, Yaping Li, Ping Wang, Junhao Cai, Jia Zeng, Hao Dong, and Jiangmiao Pang. Interndata-a1: Pioneering high-fidelity synthetic data for pre-training generalist policy.ArXiv, abs/2511.16651, 2025. URL https://api.semanticscholar. org/CorpusID:283110021
arXiv 2025
-
[30]
Robogen: Towards unleashing infinite data for automated robot learning via generative simulation, 2023
Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, and Chuang Gan. Robogen: Towards unleashing infinite data for automated robot learning via generative simulation, 2023
2023
-
[31]
Mobilemanibench: Simplifying model verification for mobile manipulation
Wenbo Wang, Fangyun Wei, QiXiu Li, Xi Chen, Yaobo Liang, Chang Xu, Jiaolong Yang, and Baining Guo. Mobilemanibench: Simplifying model verification for mobile manipulation. arXiv preprint arXiv:2602.05233, 2026
arXiv 2026
-
[32]
Qingwei Ben, Feiyu Jia, Jia Zeng, Junting Dong, Dahua Lin, and Jiangmiao Pang. Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit.arXiv preprint arXiv:2502.13013, 2025
arXiv 2025
-
[33]
Zhengyi Luo, Ye Yuan, Tingwu Wang, Chenran Li, Sirui Chen, Fernando Castañeda, Zi-Ang Cao, Jiefeng Li, David Minor, Qingwei Ben, Xingye Da, Runyu Ding, Cyrus Hogg, Lina Song, Edy Lim, Eugene Jeong, Tairan He, Haoru Xue, Wenli Xiao, Zi Wang, Simon Yuen, Jan Kautz, Yan Chang, Umar Iqbal, Linxi Fan, and Yuke Zhu. Sonic: Supersizing motion tracking for natura...
Pith/arXiv arXiv 2025
-
[34]
curobov2: Dynamics- aware motion generation with depth-fused distance fields for high-dof robots, 2026
Balakumar Sundaralingam, Adithyavairavan Murali, and Stan Birchfield. curobov2: Dynamics- aware motion generation with depth-fused distance fields for high-dof robots, 2026
2026
-
[35]
Key-grid: Unsupervised 3d keypoints detection using grid heatmap features, 2024
Chengkai Hou, Zhengrong Xue, Bingyang Zhou, Jinghan Ke, Lin Shao, and Huazhe Xu. Key-grid: Unsupervised 3d keypoints detection using grid heatmap features, 2024. URL https://arxiv.org/abs/2410.02237
arXiv 2024
-
[36]
Skeleton merger: an unsupervised aligned keypoint detector
Ruoxi Shi, Zhengrong Xue, Yang You, and Cewu Lu. Skeleton merger: an unsupervised aligned keypoint detector. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 43–52, 2021
2021
-
[37]
Where2explore: Few-shot affordance learning for unseen novel categories of articulated objects
Chuanruo Ning, Ruihai Wu, Haoran Lu, Kaichun Mo, and Hao Dong. Where2explore: Few-shot affordance learning for unseen novel categories of articulated objects. ArXiv, abs/2309.07473, 2023. URL https://api.semanticscholar.org/CorpusID: 261823492
arXiv 2023
-
[38]
Genmanip: Llm-driven simulation for generalizable instruction-following manipulation
Ning Gao, Yilun Chen, Shuai Yang, Xinyi Chen, Yang Tian, Hao Li, Haifeng Huang, Hanqing Wang, Tai Wang, and Jiangmiao Pang. Genmanip: Llm-driven simulation for generalizable instruction-following manipulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12187–12198, 2025. 13
2025
-
[39]
Genie sim 3.0 : A high-fidelity comprehensive simulation platform for humanoid robot, 2026
Chenghao Yin, Da Huang, Di Yang, Jichao Wang, Nanshu Zhao, Chen Xu, Wenjun Sun, Linjie Hou, Zhijun Li, Junhui Wu, Zhaobo Liu, Zhen Xiao, Sheng Zhang, Lei Bao, Rui Feng, Zhenquan Pang, Jiayu Li, Qian Wang, and Maoqing Yao. Genie sim 3.0 : A high-fidelity comprehensive simulation platform for humanoid robot, 2026. URL https://arxiv.org/ abs/2601.02078
Pith/arXiv arXiv 2026
-
[40]
Robotwin: Dual-arm robot benchmark with generative digital twins
Yao Mu, Tianxing Chen, Zanxin Chen, Shijia Peng, Zhiqian Lan, Zeyu Gao, Zhixuan Liang, Qiaojun Yu, Yude Zou, Mingkun Xu, Lunkai Lin, Zhiqiang Xie, Mingyu Ding, and Ping Luo. Robotwin: Dual-arm robot benchmark with generative digital twins. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 27649–27660, June 2025
2025
-
[41]
Ultradexgrasp: Learning universal dexterous grasping for bimanual robots with synthetic data,
Sizhe Yang, Yiman Xie, Zhixuan Liang, Yang Tian, Jia Zeng, Dahua Lin, and Jiangmiao Pang. Ultradexgrasp: Learning universal dexterous grasping for bimanual robots with synthetic data,
-
[42]
URLhttps://arxiv.org/abs/2603.05312
-
[43]
Unidexgrasp++: Improving dexterous grasping policy learning via geometry-aware curriculum and iterative generalist-specialist learning
Weikang Wan, Haoran Geng, Yun Liu, Zikang Shan, Yaodong Yang, Li Yi, and He Wang. Unidexgrasp++: Improving dexterous grasping policy learning via geometry-aware curriculum and iterative generalist-specialist learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3891–3902, 2023
2023
-
[44]
Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation
Ruicheng Wang, Jialiang Zhang, Jiayi Chen, Yinzhen Xu, Puhao Li, Tengyu Liu, and He Wang. Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 11359–11366. IEEE, 2023. URLhttps://arxiv.org/abs/2210.02697
arXiv 2023
-
[45]
Dexart: Benchmarking generalizable dexterous manipulation with articulated objects
Chen Bao, Helin Xu, Yuzhe Qin, and Xiaolong Wang. Dexart: Benchmarking generalizable dexterous manipulation with articulated objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21190–21200, 2023
2023
-
[46]
Bodex: Scalable and efficient robotic dexterous grasp synthesis using bilevel optimization, 2025
Jiayi Chen, Yubin Ke, and He Wang. Bodex: Scalable and efficient robotic dexterous grasp synthesis using bilevel optimization, 2025. URLhttps://arxiv.org/abs/2412.16490
arXiv 2025
-
[47]
Bidexgrasp: Coordinated bimanual dexterous grasps across object geometries and sizes, 2026
Mu Lin, Yi-Lin Wei, Jiaxuan Chen, Yuhao Lin, Shuoyu Chen, Jiangran Lyu, Jiayi Chen, Yansong Tang, He Wang, and Wei-Shi Zheng. Bidexgrasp: Coordinated bimanual dexterous grasps across object geometries and sizes, 2026. URL https://arxiv.org/abs/2604. 06589
2026
-
[48]
Yufei Wang, Ziyu Wang, Mino Nakura, Pratik Bhowal, Chia-Liang Kuo, Yi-Ting Chen, Zackory Erickson, and David Held. Articubot: Learning universal articulated object ma- nipulation policy via large scale simulation.ArXiv, abs/2503.03045, 2025. URL https: //api.semanticscholar.org/CorpusID:276781877
arXiv 2025
-
[49]
Qwen3.5-omni technical report, 2026
Qwen Team. Qwen3.5-omni technical report, 2026. URL https://arxiv.org/abs/2604. 15804
2026
-
[50]
P3-sam: Native 3d part segmentation.arXiv preprint arXiv:2509.06784, 2025
Changfeng Ma, Yang Li, Xinhao Yan, Jiachen Xu, Yunhan Yang, Chunshi Wang, Zibo Zhao, Yanwen Guo, Zhuo Chen, and Chunchao Guo. P3-sam: Native 3d part segmentation.arXiv preprint arXiv:2509.06784, 2025
arXiv 2025
-
[51]
Xinhao Yan, Jiachen Xu, Yang Li, Changfeng Ma, Yunhan Yang, Chunshi Wang, Zibo Zhao, Zeqiang Lai, Yunfei Zhao, Zhuo Chen, et al. X-part: High fidelity and structure coherent shape decomposition.arXiv preprint arXiv:2509.08643, 2025
arXiv 2025
-
[52]
curobo: Parallelized collision-free minimum-jerk robot motion generation, 2023
Balakumar Sundaralingam, Siva Kumar Sastry Hari, Adam Fishman, Caelan Garrett, Karl Van Wyk, Valts Blukis, Alexander Millane, Helen Oleynikova, Ankur Handa, Fabio Ramos, Nathan Ratliff, and Dieter Fox. curobo: Parallelized collision-free minimum-jerk robot motion generation, 2023. URLhttps://arxiv.org/abs/2310.17274
arXiv 2023
-
[53]
PA3FF: Learning part-aware dense 3d feature field for generalizable articulated object manipulation
Yue Chen, Muqing Jiang, Kaifeng Zheng, Jiaqi Liang, Chenrui Tie, Haoran Lu, Ruihai Wu, and Hao Dong. PA3FF: Learning part-aware dense 3d feature field for generalizable articulated object manipulation. InThe Fourteenth International Conference on Learning Representations, 2026. doi: 10.48550/arXiv.2602.14193. URL https://openreview.net/ forum?id=qXfRXfAHO...
-
[54]
Ruihai Wu, Haoran Lu, Yiyan Wang, Yubo Wang, and Hao Dong. UniGarmentManip: A unified framework for category-level garment manipulation via dense visual correspondence. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16340–16350, 2024. doi: 10.1109/CVPR52733.2024.01546. URL https: //openaccess.thecvf.com/c...
-
[55]
Where2Explore: Few- shot affordance learning for unseen novel categories of articulated objects
Chuanruo Ning, Ruihai Wu, Haoran Lu, Kaichun Mo, and Hao Dong. Where2Explore: Few- shot affordance learning for unseen novel categories of articulated objects. InAdvances in Neural Information Processing Systems, 2023. URL https://openreview.net/forum? id=QLllDwizVd
2023
-
[56]
Xiaoqi Li, Yanzi Wang, Yan Shen, Iaroslav Ponomarenko, Haoran Lu, Qianxu Wang, Boshi An, Jiaming Liu, and Hao Dong. ImageManip: Image-based robotic manipulation with affordance-guided next view selection.arXiv preprint arXiv:2310.09069, 2023. doi: 10.48550/ arXiv.2310.09069. URLhttps://arxiv.org/abs/2310.09069
arXiv 2023
-
[57]
SPACENUM: Revisiting Spatial Numerical Understanding in VLMs
Jianshu Zhang, Yijiang Li, Huifeixin Chen, Haoran Lu, Letian Xue, Bingyang Wang, and Han Liu. SPACENUM: Revisiting spatial numerical understanding in VLMs.arXiv preprint arXiv:2605.23898, 2026. doi: 10.48550/arXiv.2605.23898. URL https://arxiv.org/abs/ 2605.23898
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.23898 2026
-
[58]
PROGRESSLM: Towards Progress Reasoning in Vision-Language Models
Jianshu Zhang, Chengxuan Qian, Haosen Sun, Haoran Lu, Dingcheng Wang, Letian Xue, and Han Liu. ProgressLM: Towards progress reasoning in vision-language models.arXiv preprint arXiv:2601.15224, 2026. doi: 10.48550/arXiv.2601.15224. URL https://arxiv. org/abs/2601.15224. ACL 2026 Main Conference Oral; ICLR 2026 Workshop on World Models
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.15224 2026
-
[59]
arXiv:2510.01586 [cs.AI] doi:10.48550/arXiv.2510.01586
Zhenyu Pan, Yiting Zhang, Zhuo Liu, Yolo Yunlong Tang, Zeliang Zhang, Haozheng Luo, Yuwei Han, Jianshu Zhang, Dennis Wu, Hong-Yu Chen, Haoran Lu, Haoyang Fang, Manling Li, Chenliang Xu, Philip S. Yu, and Han Liu. AdvEvo-MARL: Shaping in- ternalized safety through adversarial co-evolution in multi-agent reinforcement learning. arXiv preprint arXiv:2510.015...
-
[60]
Chang, Li Yi, Subarna Tripathi, Leonidas J
Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, and Hao Su. Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 909–918, 2019. URL https://openaccess.thecvf.com/content_ CVPR_201...
2019
-
[61]
Penghao Wang, Yiyang He, Xin Lv, Yukai Zhou, Lan Xu, Jingyi Yu, and Jiayuan Gu. Partnext: A next-generation dataset for fine-grained and hierarchical 3d part understanding.arXiv preprint arXiv:2510.20155, 2025
arXiv 2025
-
[62]
Yang You, Yujing Lou, Chengkun Li, Zhoujun Cheng, Liangwei Li, Lizhuang Ma, Cewu Lu, and Weiming Wang. Keypointnet: A large-scale 3d keypoint dataset aggregated from numerous human annotations.arXiv preprint arXiv:2002.12687, 2020
arXiv 2002
-
[63]
Laso: Language-guided affordance segmentation on 3d object
Yuandong Liu, Yan Wei, Yue Jiang, et al. Laso: Language-guided affordance segmentation on 3d object. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[64]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. Rlbench: The robot learning benchmark & learning environment.arXiv preprint arXiv:1909.12271, 2019. URLhttps://arxiv.org/abs/1909.12271
arXiv 1909
-
[65]
Mimicgen: A data generation system for scalable robot learning using human demonstrations
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 1820–1864. PMLR, 2023. URLhttps:/...
2023
-
[66]
Robogen: Towards unleashing infinite data for automated robot learning via generative simulation
Yufei Wang, Zhou Xian, Feng Chen, Tsun-Hsuan Wang, Yian Wang, Katerina Fragkiadaki, Zackory Erickson, David Held, and Chuang Gan. Robogen: Towards unleashing infinite data for automated robot learning via generative simulation. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pa...
2024
-
[67]
Gensim: Generating robotic simulation tasks via large language models
Lirui Wang, Yiyang Ling, Zhecheng Yuan, Mohit Shridhar, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, and Xiaolong Wang. Gensim: Generating robotic simulation tasks via large language models. InThe Twelfth International Conference on Learning Representations,
-
[68]
URLhttps://openreview.net/forum?id=OI3RoHoWAN
-
[69]
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Avnish Narayan, Hayden Shiv- ely, Adithya Bellathur, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning.arXiv preprint arXiv:1910.10897, 2019. URLhttps://arxiv.org/abs/1910.10897
arXiv 1910
-
[70]
Isaac gym: High performance gpu-based physics simulation for robot learning
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac gym: High performance gpu-based physics simulation for robot learning. InThirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021. URLht...
Pith/arXiv arXiv 2021
-
[71]
Learning dexterous in-hand manipulation.arXiv preprint arXiv:1808.00177, 2018
OpenAI, Marcin Andrychowicz, Bowen Baker, Maciek Chociej, Rafal Józefowicz, Bob McGrew, Jakub Pachocki, Arthur Petron, Matthias Plappert, Glenn Powell, Alex Ray, Jonas Schneider, Szymon Sidor, Josh Tobin, Peter Welinder, Lilian Weng, and Wojciech Zaremba. Learning dexterous in-hand manipulation.arXiv preprint arXiv:1808.00177, 2018. URL https://arxiv.org/...
Pith/arXiv arXiv 2018
-
[72]
Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics
Jeffrey Mahler, Jacky Liang, Sherdil Niyaz, Michael Laskey, Richard Doan, Xinyu Liu, Juan Aparicio Ojea, and Ken Goldberg. Dex-net 2.0: Deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics. InRobotics: Science and Systems, 2017. URLhttps://www.roboticsproceedings.org/rss13/p58.pdf
2017
-
[73]
Acronym: A large-scale grasp dataset based on simulation
Clemens Eppner, Arsalan Mousavian, and Dieter Fox. Acronym: A large-scale grasp dataset based on simulation. In2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021. URL https://research.nvidia.com/publication/2021-05_ acronym-large-scale-grasp-dataset-based-simulation
2021
-
[74]
6-dof graspnet: Variational grasp generation for object manipulation
Arsalan Mousavian, Clemens Eppner, and Dieter Fox. 6-dof graspnet: Variational grasp generation for object manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2901–2910, 2019. URL https://openaccess.thecvf. com/content_ICCV_2019/html/Mousavian_6-DOF_GraspNet_Variational_Grasp_ Generation_for_Object_Manipulation_I...
2019
-
[75]
Martin Sundermeyer, Arsalan Mousavian, Rudolph Triebel, and Dieter Fox. Contact-graspnet: Efficient 6-dof grasp generation in cluttered scenes.arXiv preprint arXiv:2103.14127, 2021. URLhttps://arxiv.org/abs/2103.14127
arXiv 2021
-
[76]
Bimanual grasp synthesis for dexterous robot hands.arXiv preprint arXiv:2411.15903, 2024
Yanming Shao and Chenxi Xiao. Bimanual grasp synthesis for dexterous robot hands.arXiv preprint arXiv:2411.15903, 2024. URLhttps://arxiv.org/abs/2411.15903
arXiv 2024
-
[78]
URLhttps://arxiv.org/abs/2101.02692
-
[79]
Vat-mart: Learning visual action trajectory pro- posals for manipulating 3d articulated objects
Ruihai Wu, Yan Zhao, Kaichun Mo, Zizheng Guo, Yian Wang, Tianhao Wu, Qingnan Fan, Xuelin Chen, Leonidas Guibas, and Hao Dong. Vat-mart: Learning visual action trajectory pro- posals for manipulating 3d articulated objects. InThe Tenth International Conference on Learn- ing Representations, 2022. URLhttps://openreview.net/forum?id=iEx3PiooLy. 16
2022
-
[80]
Gapartnet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts
Haoran Geng, Helin Xu, Chengyang Zhao, Chao Xu, Li Yi, Siyuan Huang, and He Wang. Gapartnet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7081– 7091, 2023. URL https://openaccess.thecvf.com/content/CV...
2023
-
[81]
O2o-afford: Annotation- free large-scale object-object affordance learning
Kaichun Mo, Yuzhe Qin, Fanbo Xiang, Hao Su, and Leonidas Guibas. O2o-afford: Annotation- free large-scale object-object affordance learning. InConference on Robot Learning, 2021. URLhttps://openreview.net/forum?id=EougVeukEH9
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.