A Text-Steerable Instrument for Sketching Procedural Soundscapes via Language Models
Pith reviewed 2026-07-02 01:00 UTC · model grok-4.3
The pith
A categorical schema lets language models turn text prompts into continuously steerable procedural soundscapes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
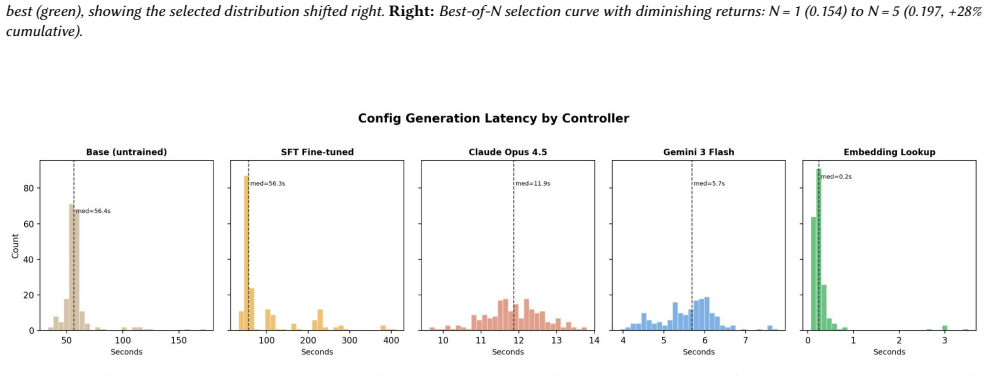
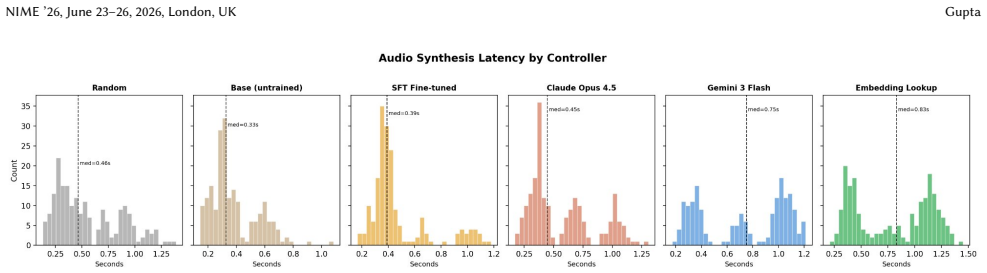
The instrument generates human-readable configurations over a categorical schema from text prompts, enabling fine-grained performer control through direct parameter adjustments that produce predictable audible shifts; three interchangeable backends emit compatible configurations in the same schema, and a live generator architecture continuously emits audio while resolving new instructions in the background with seamless crossfades.
What carries the argument
A custom categorical schema for procedural soundscape parameters that maps text prompts to coherent configurations and supports direct steering by the performer.
If this is right
- Performers can adjust brightness, rhythm style, or other parameters in real time without waiting for a new full generation.
- The same prompt can be steered across multiple sessions using different backends while maintaining schema compatibility.
- Text-to-music shifts from one-shot synthesis to an ongoing stream that remains audible during LLM response delays of several seconds.
- Semantic alignment can be measured with embedding models such as LAION-CLAP as a proxy for prompt-to-configuration quality.
Where Pith is reading between the lines
- The schema approach might transfer to other domains such as procedural visuals or lighting control where parameter coherence matters.
- Direct parameter editing could be combined with gesture or MIDI controllers for hybrid text-plus-haptic performance.
- If the schema were made public, other researchers could build alternative backends or coherence checks on top of the same parameter space.
Load-bearing premise
The custom categorical schema produces musically coherent output for most valid parameter combinations.
What would settle it
A test in which musicians rate a large random sample of valid schema configurations for musical coherence and find that a substantial fraction sound incoherent or unpleasant.
Figures

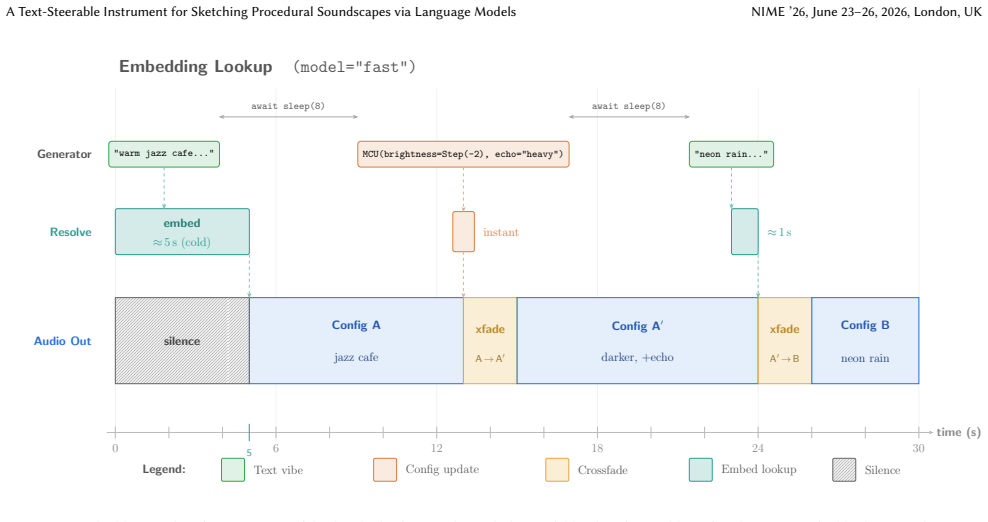
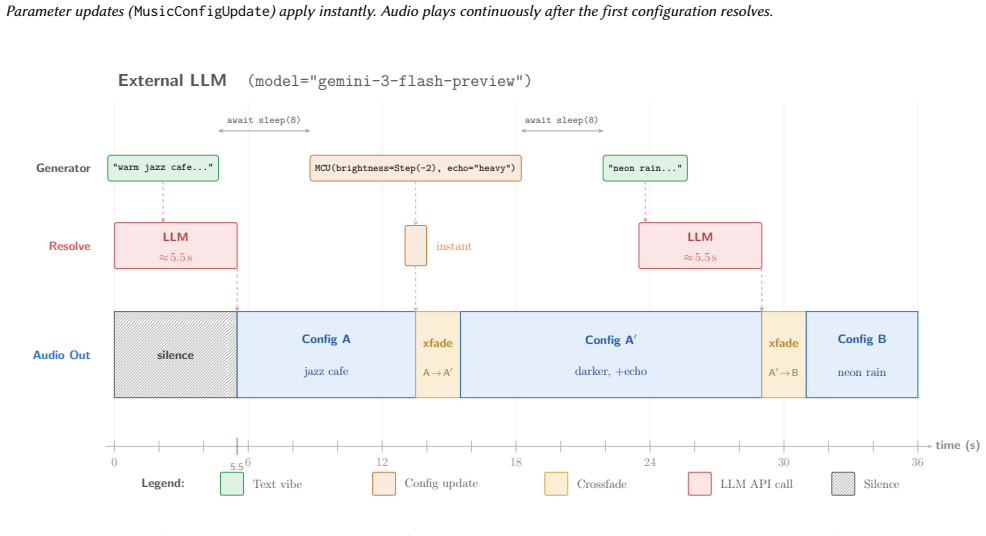
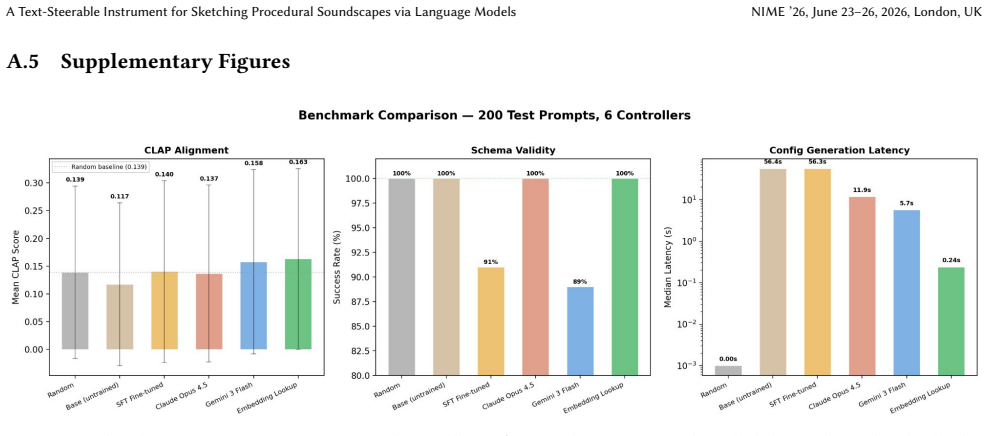
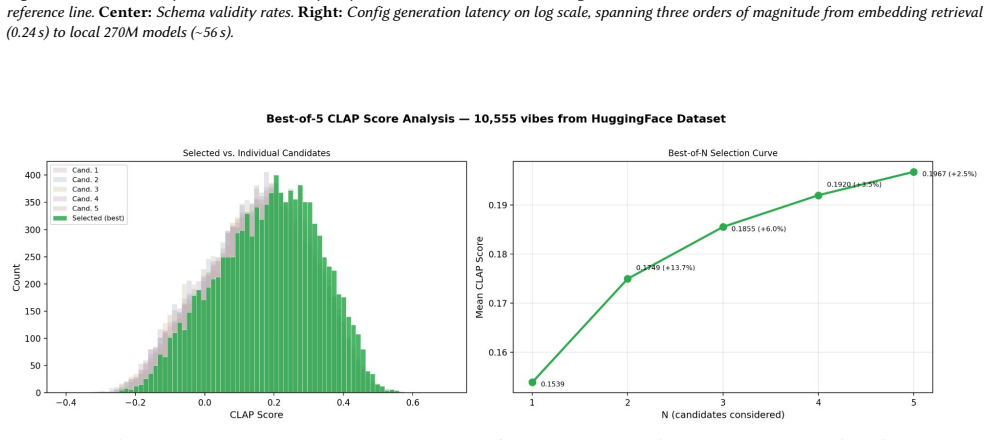
read the original abstract
We present a real-time musical interface that converts natural-language scene descriptions into evolving procedural soundscapes. A performer types a prompt such as "warm jazz cafe at midnight" and steers it through direct parameter adjustments - stepping brightness down, switching a rhythm style - each producing a predictable, audible shift without re-prompting. Where GPU-bound text-to-audio systems synthesize monolithic waveforms, our instrument generates human-readable configurations over a categorical schema, enabling fine-grained performer control; most valid combinations are designed to sound musically coherent. Three interchangeable backends - embedding retrieval for sub-second CPU-only use, hosted LLMs via API, and a fine-tuned 270M local model - all emit the same schema. A live generator architecture continuously emits audio while resolving new instructions in the background, crossfading seamlessly when ready; even when an LLM takes 5-12 seconds to respond, the audience hears uninterrupted sound - reframing text-to-music as an ongoing performable stream rather than a one-shot generation. We evaluate text-audio semantic alignment using LAION-CLAP on held-out prompts as a technical proxy, finding that retrieval-based configuration outperforms random valid configurations on this metric, while noting that LAION-CLAP also informed retrieval-map construction. We report performance observations, informal listener feedback, and release materials for the SDK, dataset artifacts, model, and audiovisual performance interface.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a real-time musical interface converting natural-language scene descriptions into evolving procedural soundscapes via a categorical schema for human-readable audio configurations. Performers can steer parameters directly (e.g., brightness, rhythm style) for predictable shifts without re-prompting. Three interchangeable backends (embedding retrieval for CPU use, hosted LLMs, fine-tuned 270M local model) all output the same schema. A live generator architecture emits continuous audio while resolving instructions in the background with seamless crossfades. Evaluation uses LAION-CLAP on held-out prompts as a proxy for text-audio alignment, reporting that retrieval outperforms random valid configurations (while noting LAION-CLAP informed the retrieval map). The work releases SDK, dataset artifacts, model, and interface, reframing text-to-music as an ongoing performable stream.
Significance. If the central claims hold, the work offers a practical steerable alternative to monolithic text-to-audio synthesis by prioritizing fine-grained performer control through readable parameters and uninterrupted real-time output. The multi-backend design and explicit release of materials (SDK, model, artifacts) are clear strengths that support reproducibility and adoption in computer music and HCI. The live generator architecture effectively addresses latency, enabling the performable-stream paradigm.
major comments (2)
- [Abstract] Abstract: the claim that retrieval-based configurations outperform random valid ones on LAION-CLAP (as a proxy for semantic alignment) is presented alongside the explicit note that LAION-CLAP informed retrieval-map construction. This circularity means the metric is not independent, directly weakening support for the assertion that the categorical schema produces musically coherent outputs aligned with text prompts.
- [Evaluation section] Evaluation section: the central claim that 'most valid combinations are designed to sound musically coherent' and enable fine-grained control rests on the LAION-CLAP proxy without an independent validation step (e.g., listener study or alternative metric) described to confirm coherence separate from the map-construction process.
minor comments (1)
- The description of the categorical schema would benefit from additional concrete examples of valid parameter combinations and their intended audio properties to clarify the 'human-readable' and 'musically coherent' properties.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on the evaluation methodology. We address each point below and will make revisions to clarify the limitations of our proxy metric.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that retrieval-based configurations outperform random valid ones on LAION-CLAP (as a proxy for semantic alignment) is presented alongside the explicit note that LAION-CLAP informed retrieval-map construction. This circularity means the metric is not independent, directly weakening support for the assertion that the categorical schema produces musically coherent outputs aligned with text prompts.
Authors: We agree that the use of LAION-CLAP in both map construction and evaluation introduces a degree of circularity, limiting the independence of the metric. The paper already notes this fact, but we will revise the abstract and evaluation section to more explicitly discuss this as a limitation of the proxy and temper the claims accordingly. The primary purpose of the evaluation is to show that the retrieval backend finds configurations with higher CLAP scores than random selection from the valid set, which it does, but we acknowledge this does not constitute fully independent validation of semantic alignment. revision: partial
-
Referee: [Evaluation section] Evaluation section: the central claim that 'most valid combinations are designed to sound musically coherent' and enable fine-grained control rests on the LAION-CLAP proxy without an independent validation step (e.g., listener study or alternative metric) described to confirm coherence separate from the map-construction process.
Authors: We clarify that the statement 'most valid combinations are designed to sound musically coherent' refers to the intentional design of the categorical schema itself, where parameter ranges and combinations were curated by the authors to avoid musically implausible results (e.g., incompatible rhythm and timbre pairings). This is separate from the LAION-CLAP evaluation, which assesses only the text-to-configuration mapping quality of the backends. The fine-grained control is enabled by the steerable parameters in the schema, demonstrated through the interface design. We will revise the evaluation section to better separate these aspects and note the absence of a listener study as a limitation. revision: yes
Circularity Check
Circularity in LAION-CLAP evaluation undermines proxy for semantic alignment
specific steps
-
fitted input called prediction
[Abstract]
"We evaluate text-audio semantic alignment using LAION-CLAP on held-out prompts as a technical proxy, finding that retrieval-based configuration outperforms random valid configurations on this metric, while noting that LAION-CLAP also informed retrieval-map construction."
The retrieval map is constructed using LAION-CLAP embeddings; therefore reporting that retrieval outperforms random on the same LAION-CLAP metric is expected by construction and does not provide independent evidence that the schema produces musically coherent or semantically aligned outputs.
full rationale
The paper's evaluation of retrieval-based configurations outperforming random ones on LAION-CLAP is load-bearing for claims of text-audio alignment and coherence of the categorical schema. However, the abstract explicitly states that LAION-CLAP informed the retrieval-map construction, so the metric is not independent. This matches the fitted_input_called_prediction pattern exactly. No other circular steps (self-citation chains, ansatz smuggling, or self-definitional derivations) appear in the provided text; the coherence assumption and backend interchangeability are stated as design choices without reduction to the evaluation metric.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Most valid combinations in the categorical schema sound musically coherent by design.
invented entities (1)
-
categorical schema for audio configurations
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I. Denk, Zalán Borsos, Jesse Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matt Sharifi, Neil Zeghidour, and Christian Frank. 2023. Mu- sicLM: Generating Music from Text.arXiv preprint arXiv:2301.11325(2023). https://doi.org/10.48550/arXiv.2301.11325
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2301.11325 2023
-
[2]
Misagh Azimi and Mo H. Zareei. 2025. Live Improvisation with Fine-Tuned Generative AI: A Musical Metacreation Approach. InProceedings of the In- ternational Conference on New Interfaces for Musical Expression. Canberra, Australia, Article 54, 389–393 pages. https://doi.org/10.5281/zenodo.15698902
-
[3]
Stephen Brade, Bryan Wang, Mauricio Sousa, Gregory Lee Newsome, Sageev Oore, and Tovi Grossman. 2024. SynthScribe: Deep Multimodal Tools for Synthesizer Sound Retrieval and Exploration. InProceedings of the 29th Inter- national Conference on Intelligent User Interfaces. https://doi.org/10.1145/3640 543.3645158
-
[4]
Manuel Cherep, Nikhil Singh, and Jessica Shand. 2024. Creative Text-to- Audio Generation via Synthesizer Programming. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, 8270–8285. https://doi.org/10.48550/arXiv.2406.00 294
-
[5]
Isaac Clarke, Francesco Ardan Dal Rí, and Raul Masu. 2025. Longevity of Deep Generative Models in NIME: Challenges and Practices for Reactivation. InProceedings of the International Conference on New Interfaces for Musical Expression. Canberra, Australia, Article 32, 224–230 pages. https://doi.org/10 .5281/zenodo.15735662
2025
-
[6]
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre Défossez. 2023. Simple and Controllable Music Generation. InAdvances in Neural Information Processing Systems 36. https: //doi.org/10.48550/arXiv.2306.05284 arXiv:2306.05284
-
[7]
Zach Evans, CJ Carr, Josiah Taylor, Scott H. Hawley, and Jordi Pons. 2024. Fast Timing-Conditioned Latent Audio Diffusion. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, 12652–12665. https://doi.org/10.48550/arXiv.2402. 04825
-
[8]
Andy Hunt and Ross Kirk. 2000. Mapping Strategies for Musical Performance. InTrends in Gestural Control of Music, Marcelo M. Wanderley and Marc Battier (Eds.). IRCAM – Centre Pompidou, Paris, France. https://www-media.idmil. org/media/Trends_Ircam/DOS/P.HunKir.pdf
2000
-
[9]
Nikhil Kandpal, Brian Lester, Colin Raffel, Sebastian Majstorovic, Stella Bi- derman, Baber Abbasi, Luca Soldaini, Enrico Shippole, A. Feder Cooper, Aviya Skowron, John Kirchenbauer, Shayne Longpre, Lintang Sutawika, Alon Albalak, Zhenlin Xu, Guilherme Penedo, Loubna Ben Allal, Elie Bak- ouch, John David Pressman, Honglu Fan, Dashiell Stander, Guangyu Son...
-
[10]
Yikai Li and Ge Wang. 2024. ChAI => Interactive AI Tools in ChucK. InProceedings of the International Conference on New Interfaces for Musi- cal Expression. Utrecht, Netherlands, Article 81, 553–559 pages. https: //doi.org/10.5281/zenodo.13904949
-
[11]
2019.Sonic Writing: Technologies of Material, Symbolic, and Signal Inscriptions
Thor Magnusson. 2019.Sonic Writing: Technologies of Material, Symbolic, and Signal Inscriptions. Bloomsbury Academic. https://doi.org/10.5040/97815013 13899
-
[12]
Tim Murray-Browne and Panagiotis Tigas. 2021. Latent Mappings: Generating Open-Ended Expressive Mappings Using Variational Autoencoders. InProceed- ings of the International Conference on New Interfaces for Musical Expression. Shanghai, China, Article 66. https://doi.org/10.21428/92fbeb44.9d4bcd4b
-
[13]
Nicola Privato, Victor Shepardson, Giacomo Lepri, and Thor Magnusson
-
[14]
InProceedings of the International Conference on New Inter- faces for Musical Expression
Stacco: Exploring the Embodied Perception of Latent Representations in Neural Synthesis. InProceedings of the International Conference on New Inter- faces for Musical Expression. Utrecht, Netherlands, Article 62, 424–431 pages. https://doi.org/10.5281/zenodo.13904899
-
[15]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. InProceedings of the 2019 Conference on Em- pirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Association for Computational Lin- guistics, Hong Kong, China, 3982–3992. https://doi.or...
-
[16]
Nicholas Shaheed and Ge Wang. 2025. ChuMP and the Zen of Package Management. InProceedings of the International Conference on New Interfaces for Musical Expression. Canberra, Australia, Article 90, 610–617 pages. https: //doi.org/10.5281/zenodo.15698984
-
[17]
Victor Shepardson, Jonathan Reus, and Thor Magnusson. 2024. Tungnáá: a Hyper-realistic Voice Synthesis Instrument for Real-Time Exploration of Extended Vocal Expressions. InProceedings of the International Conference on New Interfaces for Musical Expression. Utrecht, Netherlands, Article 78, 536–540 pages. https://doi.org/10.5281/zenodo.13904943
-
[18]
Yusong Wu, Ke Chen, Tianyu Zhang, Yuchen Hui, Taylor Berg-Kirkpatrick, and Shlomo Dubnov. 2023. Large-Scale Contrastive Language-Audio Pretrain- ing with Feature Fusion and Keyword-to-Caption Augmentation. InICASSP 2023 – 2023 IEEE International Conference on Acoustics, Speech and Signal Processing. 1–5. https://doi.org/10.1109/ICASSP49357.2023.10095969 A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.