Reinforcing Few-step Generators via Reward-Tilted Distribution Matching
Pith reviewed 2026-06-29 22:18 UTC · model grok-4.3
The pith
RTDMD aligns few-step flow generators to preferences by minimizing KL to a reward-tilted teacher distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
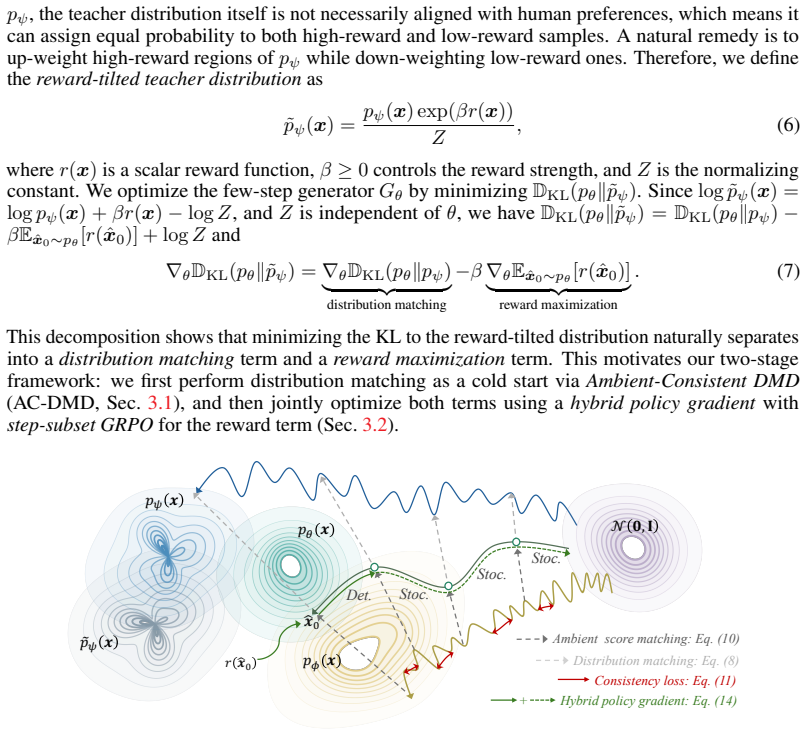
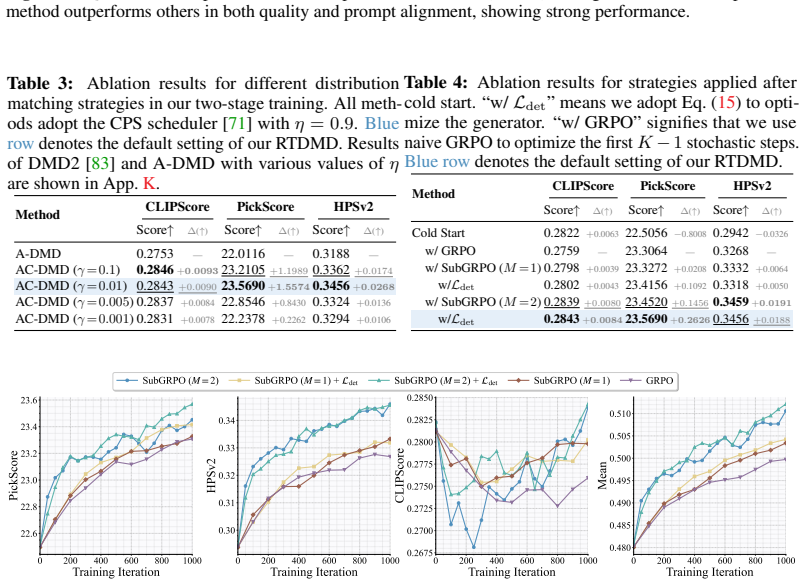
Minimizing the KL divergence to a reward-tilted teacher distribution decomposes into a distribution matching term and a reward maximization term. The first stage applies Ambient-Consistent Distribution Matching Distillation (AC-DMD) that performs subinterval-wise matching and augments the fake score objective with a consistency regularizer. The second stage jointly optimizes both terms via a hybrid policy gradient that mixes GRPO-style estimation for stochastic intermediate transitions with direct reward backpropagation through the deterministic final step, plus step-subset GRPO (SubGRPO) to reduce variance, producing new state-of-the-art results across preference, aesthetic, and composition
What carries the argument
The reward-tilted teacher distribution, whose KL divergence decomposes into separate distribution-matching and reward-maximization objectives that are optimized in two stages.
If this is right
- Few-step generators can reach high preference alignment by optimizing the decomposed objective rather than applying RL from scratch.
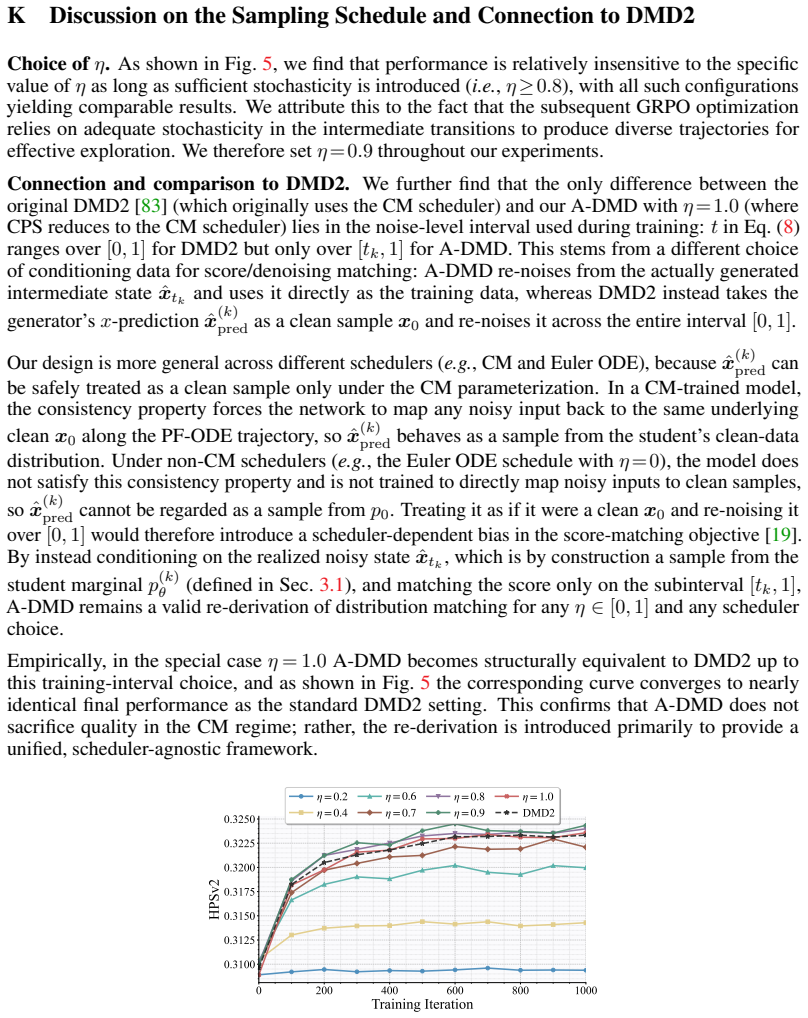
- Subinterval-wise matching plus the consistency regularizer keeps the fake score model stable when the generator distribution shifts under limited updates.
- The hybrid policy gradient plus SubGRPO lowers variance enough to make joint optimization of matching and reward terms practical.
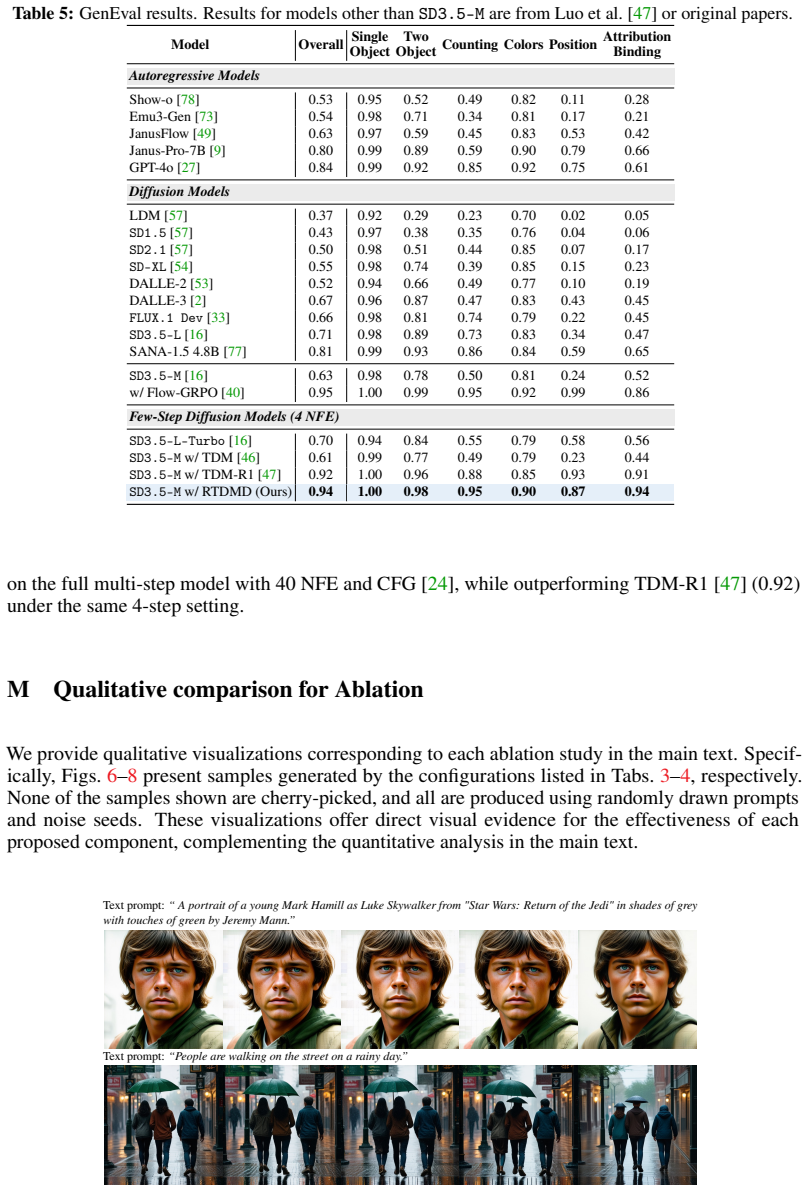
- The same four-step regime yields simultaneous gains on aesthetic and compositional metrics, not only preference scores.
Where Pith is reading between the lines
- The decomposition may let practitioners dial the strength of the reward tilt independently of the distillation term to control quality-diversity trade-offs.
- The framework could be tested on video or audio flow generators to see whether the same two-stage schedule transfers to other modalities.
- If the reward model itself contains systematic biases, those biases may become more visible in the low-step regime where the generator has less opportunity to average them out.
Load-bearing premise
The two-stage procedure can practically realize the reward-tilted teacher distribution without the reward model or consistency regularizer introducing hidden biases that only appear outside the reported metrics.
What would settle it
Retraining the same SD3 or FLUX.2 backbones with RTDMD and finding no gain, or a loss, on independent human preference ratings or on un-reported measures such as output diversity or artifact frequency would falsify the central claim.
Figures







read the original abstract
Recent advances in few-step diffusion distillation have enabled efficient image generation, yet aligning these models with human preferences remains challenging. We propose Reward-Tilted Distribution Matching Distillation (RTDMD), a two-stage framework that unifies distribution matching distillation with reward-guided reinforcement learning for few-step flow generators. We show that minimizing the KL divergence to a reward-tilted teacher distribution naturally decomposes into a distribution matching term and a reward maximization term. In the first stage, we introduce Ambient-Consistent Distribution Matching Distillation (AC-DMD), which performs subinterval-wise distribution matching and augments the fake score objective with a consistency regularizer to help the fake score model track the shifting generator distribution under limited updates. In the second stage, we jointly optimize both terms: for the reward maximization term, we derive a hybrid policy gradient that combines a GRPO-style estimator for the stochastic intermediate transitions with direct reward backpropagation through the deterministic final step, and further introduce step-subset GRPO (SubGRPO) to reduce variance. Experiments on SD3, SD3.5, and FLUX.2 demonstrate that RTDMD establishes new state-of-the-art results across preference, aesthetic, and compositional metrics with only 4 inference steps, outperforming previous few-step text-to-image generation methods. Code and models are available at https://github.com/Harahan/RTDMD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Reward-Tilted Distribution Matching Distillation (RTDMD), a two-stage framework that unifies distribution matching distillation with reward-guided reinforcement learning for few-step flow generators. It claims that minimizing KL divergence to a reward-tilted teacher distribution decomposes into a distribution matching term plus a reward maximization term. Stage 1 introduces Ambient-Consistent Distribution Matching Distillation (AC-DMD) with subinterval matching and a consistency regularizer; stage 2 uses a hybrid policy gradient (GRPO-style for stochastic transitions plus direct backpropagation) and SubGRPO for variance reduction. Experiments on SD3, SD3.5, and FLUX.2 claim new SOTA results on preference, aesthetic, and compositional metrics at 4 inference steps, with code released.
Significance. If the decomposition is exact and the two-stage procedure produces stable gains without metric-specific biases from the reward model or regularizer, the work would advance efficient preference alignment for text-to-image models and provide a template for combining distillation with RL. Code and model release is a clear strength for reproducibility.
major comments (3)
- [Abstract / §3] Abstract and method section: the central claim that KL minimization to the reward-tilted teacher 'naturally decomposes' into a distribution-matching term and reward-maximization term is asserted without visible derivation or proof; this identity is load-bearing for the entire framework and must be shown to survive the approximations inherent to few-step flow generators.
- [Experiments] Experiments section: the abstract states empirical SOTA but supplies no quantitative tables, ablation controls, or statistical significance tests; without these, the cross-model claim on SD3/SD3.5/FLUX.2 cannot be evaluated and the weakest assumption (realizability of the reward-tilted teacher without hidden biases) remains untested.
- [§4 / §5] Stage-1 / Stage-2 description: the consistency regularizer in AC-DMD and the hybrid policy gradient + SubGRPO are presented as stabilizing the procedure, yet no analysis shows they do not simply mask distribution shift rather than correct it; this directly affects whether the reported metric gains are robust.
minor comments (2)
- [Abstract] Abstract: the acronym RTDMD is used before its expansion; define on first use for clarity.
- [Method] Notation: the distinction between the 'fake score objective' and the full distribution-matching loss should be made explicit with equation numbers to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and indicate the revisions that will be incorporated to address the concerns.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and method section: the central claim that KL minimization to the reward-tilted teacher 'naturally decomposes' into a distribution-matching term and reward-maximization term is asserted without visible derivation or proof; this identity is load-bearing for the entire framework and must be shown to survive the approximations inherent to few-step flow generators.
Authors: We will expand the derivation in the revised §3 to include an explicit step-by-step proof. Starting from the reward-tilted target p* ∝ p_teacher ⋅ exp(β r), the KL objective decomposes exactly into a distribution-matching term (equivalent to the DMD objective) plus a reward term; we will then analyze the effect of the few-step flow approximations (e.g., discretization and limited denoising steps) on this identity and show that the decomposition remains valid up to a bounded error term that is controlled by the consistency regularizer. revision: yes
-
Referee: [Experiments] Experiments section: the abstract states empirical SOTA but supplies no quantitative tables, ablation controls, or statistical significance tests; without these, the cross-model claim on SD3/SD3.5/FLUX.2 cannot be evaluated and the weakest assumption (realizability of the reward-tilted teacher without hidden biases) remains untested.
Authors: The current experiments section reports comparative results on the three models but lacks the requested tables, ablations, and significance tests. In the revision we will add comprehensive tables with all metrics, ablation studies isolating each component (AC-DMD, hybrid gradient, SubGRPO), and statistical significance tests (paired t-tests with p-values) across multiple random seeds. We will also include controls that vary the reward model to assess potential biases in the realizability of the tilted teacher. revision: yes
-
Referee: [§4 / §5] Stage-1 / Stage-2 description: the consistency regularizer in AC-DMD and the hybrid policy gradient + SubGRPO are presented as stabilizing the procedure, yet no analysis shows they do not simply mask distribution shift rather than correct it; this directly affects whether the reported metric gains are robust.
Authors: We will add a dedicated analysis subsection in the revised §4 and §5 that tracks distribution-shift metrics (e.g., empirical KL between generator and teacher at intermediate steps) with and without the regularizer and SubGRPO. New experiments will demonstrate that the regularizer reduces the shift rather than concealing it, and that the hybrid gradient yields lower variance without inflating metrics on held-out reward models. revision: yes
Circularity Check
Derivation chain is self-contained; no circular reductions identified
full rationale
The paper's core step is the claim that KL minimization to a reward-tilted teacher 'naturally decomposes' into a distribution-matching term plus reward-maximization term; this is presented as a direct mathematical identity rather than a fitted or self-referential construction. The subsequent AC-DMD stage, consistency regularizer, hybrid policy gradient, and SubGRPO are algorithmic procedures whose definitions do not reduce to their own outputs by construction. No self-citation is invoked as a load-bearing uniqueness theorem, no parameter is fitted on a subset and then renamed a 'prediction,' and no ansatz is smuggled via prior work. Experiments report performance on external models (SD3, SD3.5, FLUX.2) using an external reward model, keeping the derivation independent of its own fitted values.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sd3.5.https://github.com/Stability-AI/sd3.5, 2024
Stability AI. Sd3.5.https://github.com/Stability-AI/sd3.5, 2024. 2, 7, 8, 24
2024
-
[2]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023. 25
2023
-
[3]
Training diffusion models with reinforcement learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=YCWjhGrJFD. 1, 17
2024
-
[4]
George Casella and Christian P. Robert. Rao-blackwellisation of sampling schemes.Biometrika, 83(1):81–94, 1996. 7
1996
-
[5]
Flash diffusion: Accel- erating any conditional diffusion model for few steps image generation
Clement Chadebec, Onur Tasar, Eyal Benaroche, and Benjamin Aubin. Flash diffusion: Accel- erating any conditional diffusion model for few steps image generation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 15686–15695, 2025. 7, 8, 17
2025
-
[6]
arXiv preprint arXiv:2511.20549 (2025)
Guanjie Chen, Shirui Huang, Kai Liu, Jian-Xiang Zhu, Xiaoye Qu, Peng Chen, Yu Cheng, and Yifu Sun. Flash-dmd: Towards high-fidelity few-step image generation with efficient distillation and joint reinforcement learning.ArXiv, abs/2511.20549, 2025. 1, 17
-
[7]
NFT: Bridging supervised learning and reinforcement learning in math reasoning
Huayu Chen, Kaiwen Zheng, Qinsheng Zhang, Ganqu Cui, Yin Cui, Haotian Ye, Tsung-Yi Lin, Ming-Yu Liu, Jun Zhu, and Haoxiang Wang. NFT: Bridging supervised learning and reinforcement learning in math reasoning. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=ujBrsQm6Zu. 17
2026
-
[8]
Junying Chen, Zhenyang Cai, Pengcheng Chen, Shunian Chen, Ke Ji, Xidong Wang, Yunjin Yang, and Benyou Wang. Sharegpt-4o-image: Aligning multimodal models with gpt-4o-level image generation.arXiv preprint arXiv:2506.18095, 2025. 7
-
[9]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling, 2025. URLhttps://arxiv.org/abs/2501.17811. 25
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Kevin Clark, Paul Vicol, Kevin Swersky, and David J. Fleet. Directly fine-tuning diffusion models on differentiable rewards. InThe Twelfth International Conference on Learning Repre- sentations, 2024. URLhttps://openreview.net/forum?id=1vmSEVL19f. 1, 17 10
2024
-
[11]
Consistent diffusion models: Mitigating sampling drift by learning to be consistent.Advances in Neural Information Processing Systems, 36:42038–42063, 2023
Giannis Daras, Yuval Dagan, Alex Dimakis, and Constantinos Daskalakis. Consistent diffusion models: Mitigating sampling drift by learning to be consistent.Advances in Neural Information Processing Systems, 36:42038–42063, 2023. 2, 5
2023
-
[12]
Consistent diffusion meets tweedie: Training exact ambient diffusion models with noisy data
Giannis Daras, Alex Dimakis, and Constantinos Costis Daskalakis. Consistent diffusion meets tweedie: Training exact ambient diffusion models with noisy data. InForty-first Interna- tional Conference on Machine Learning, 2024. URL https://openreview.net/forum? id=PlVjIGaFdH. 2, 5, 20
2024
-
[13]
text-to-image-2m
Hugging Face Open Data. text-to-image-2m. https://huggingface.co/datasets/ jackyhate/text-to-image-2M, 2024. 7
2024
-
[14]
Guiding Distribution Matching Distillation with Gradient-Based Reinforcement Learning
Linwei Dong, Ruoyu Guo, Ge Bai, Zehuan Yuan, Yawei Luo, and Changqing Zou. Guiding distribution matching distillation with gradient-based reinforcement learning, 2026. URL https://arxiv.org/abs/2604.19009. 1, 7, 8, 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024. 8, 27
2024
-
[16]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024. 1, 2, 3, 5, 7, 17, 25
2024
-
[17]
Online reward-weighted fine-tuning of flow matching with wasserstein regularization
Jiajun Fan, Shuaike Shen, Chaoran Cheng, Yuxin Chen, Chumeng Liang, and Ge Liu. Online reward-weighted fine-tuning of flow matching with wasserstein regularization. InThe Thirteenth International Conference on Learning Representations, 2025. 17
2025
-
[18]
URL https://arxiv.org/ abs/2603.28460
Linqian Fan, Peiqin Sun, Tiancheng Wen, Shun Lu, and Chengru Song.rdm: Re-conceptualizing distribution matching as a reward for diffusion distillation, 2026. URL https://arxiv.org/ abs/2603.28460. 1, 7, 8, 17
-
[19]
Phased dmd: Few-step distribution matching distillation via score matching within subintervals, 2026
Xiangyu Fan, Zesong Qiu, Zhuguanyu Wu, Fanzhou Wang, Zhiqian Lin, Tianxiang Ren, Dahua Lin, Ruihao Gong, and Lei Yang. Phased dmd: Few-step distribution matching distillation via score matching within subintervals, 2026. URL https://arxiv.org/abs/2510.27684. 1, 4, 17, 24
-
[20]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023. 1, 17
2023
-
[21]
Xingtong Ge, Xin Zhang, Tongda Xu, Yi Zhang, Xinjie Zhang, Yan Wang, and Jun Zhang. Senseflow: Scaling distribution matching for flow-based text-to-image distillation.arXiv preprint arXiv:2506.00523, 2025. 1
-
[22]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023. 7, 24
2023
-
[23]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021. 7, 8
2021
-
[24]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. URLhttps://openreview. net/forum?id=qw8AKxfYbI. 2, 7, 17, 25, 28
2021
-
[25]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1, 2, 17 11
2020
-
[26]
Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022. 7, 23
2022
-
[27]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 25
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
URLhttps://doi.org/10.48550/arXiv.2511.13649
Dengyang Jiang, Dongyang Liu, Zanyi Wang, Qilong Wu, Liuzhuozheng Li, Hengzhuang Li, Xin Jin, David Liu, Zhen Li, Bo Zhang, et al. Distribution matching distillation meets reinforcement learning.arXiv preprint arXiv:2511.13649, 2025. 1, 2, 7, 8, 17
-
[30]
Geneval 2: Addressing benchmark drift in text-to-image evaluation, 2025
Amita Kamath, Kai-Wei Chang, Ranjay Krishna, Luke Zettlemoyer, Yushi Hu, and Marjan Ghazvininejad. Geneval 2: Addressing benchmark drift in text-to-image evaluation, 2025. URL https://arxiv.org/abs/2512.16853. 7, 8
-
[31]
Consistency trajectory models: Learning probability flow ODE trajectory of diffusion
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ODE trajectory of diffusion. InICLR. OpenReview.net, 2024. 17
2024
-
[32]
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023. 7, 8
2023
-
[33]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024. 1, 25
2024
-
[34]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2,
-
[35]
Aligning Text-to-Image Models using Human Feedback
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. Aligning text-to-image models using human feedback.arXiv preprint arXiv:2302.12192, 2023. 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
SDXL-Lightning: Progressive Adversarial Diffusion Distillation
Shanchuan Lin, Anran Wang, and Xiao Yang. Sdxl-lightning: Progressive adversarial diffusion distillation.arXiv preprint arXiv:2402.13929, 2024. 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t. 1, 3, 5, 17
2023
-
[39]
Decoupled DMD: CFG augmentation as the spear, distribution matching as the shield
Dongyang Liu, Peng Gao, David Liu, Ruoyi Du, Zhen Li, Qilong Wu, Xin Jin, Sihan Cao, Shifeng Zhang, Steven HOI, and Hongsheng Li. Decoupled DMD: CFG augmentation as the spear, distribution matching as the shield. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=jBztvOiCKE. 1, 17
2026
-
[40]
Flow-GRPO: Training flow matching models via online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di ZHANG, and Wanli Ouyang. Flow-GRPO: Training flow matching models via online RL. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=oCBKGw5HNf. 1, 2, 8, 10, 17, 24, 25 12
2026
-
[41]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations,
-
[42]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URL https://openreview.net/forum? id=Bkg6RiCqY7. 23
2019
-
[43]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378,
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Weijian Luo. Diff-instruct++: Training one-step text-to-image generator model to align with human preferences, 2025. URLhttps://arxiv.org/abs/2410.18881. 17
-
[45]
Diff- instruct: A universal approach for transferring knowledge from pre-trained diffusion models
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. Diff- instruct: A universal approach for transferring knowledge from pre-trained diffusion models. In NeurIPS, 2023. 17
2023
-
[46]
Learning few-step diffusion models by trajectory distribution matching
Yihong Luo, Tianyang Hu, Jiacheng Sun, Yujun Cai, and Jing Tang. Learning few-step diffusion models by trajectory distribution matching. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17719–17728, 2025. 1, 7, 8, 17, 25
2025
-
[47]
Tdm-r1: Reinforcing few-step diffusion models with non-differentiable reward, 2026
Yihong Luo, Tianyang Hu, Weijian Luo, and Jing Tang. Tdm-r1: Reinforcing few-step diffusion models with non-differentiable reward, 2026. URLhttps://arxiv.org/abs/2603.07700. 1, 7, 8, 17, 25
-
[48]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Computer Vision, pages 23–40. Springer, 2024. 3
2024
-
[49]
Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, et al. Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7739–7751, 2025. 25
2025
-
[50]
Hpsv3: Towards wide-spectrum hu- man preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum hu- man preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025. 7
2025
-
[51]
Flow matching policy gradients
David McAllister, Songwei Ge, Brent Yi, Chung Min Kim, Ethan Weber, Hongsuk Choi, Haiwen Feng, and Angjoo Kanazawa. Flow matching policy gradients. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=eoEmoKoQpJ. 17
2026
-
[52]
Tuning timestep-distilled diffusion model using pairwise sample optimization
Zichen Miao, Zhengyuan Yang, Kevin Lin, Ze Wang, Zicheng Liu, Lijuan Wang, and Qiang Qiu. Tuning timestep-distilled diffusion model using pairwise sample optimization. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=fXnE4gB64o. 17
2025
-
[53]
Dalle-2, 2023
OpenAI. Dalle-2, 2023. URLhttps://openai.com/dall-e-2. 25
2023
-
[54]
SDXL: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=di52zR8xgf. 1, 25
2024
-
[55]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=HPuSIXJaa9. 17 13
2023
-
[56]
Hyper-SD: Trajectory segmented consistency model for efficient image synthesis
Yuxi Ren, Xin Xia, Yanzuo Lu, Jiacheng Zhang, Jie Wu, Pan Xie, XING W ANG, and Xuefeng Xiao. Hyper-SD: Trajectory segmented consistency model for efficient image synthesis. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=O5XbOoi0x3. 7, 8, 17
2024
-
[57]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 17, 25
2022
-
[58]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id= TIdIXIpzhoI. 1, 17
2022
-
[59]
Fast high-resolution image synthesis with latent adversarial diffusion distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rombach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 1, 17
2024
-
[60]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103. Springer, 2024. 1, 17
2024
-
[61]
Laion-aesthetics
Christoph Schuhmann. Laion-aesthetics. https://laion.ai/blog/laion-aesthetics/,
-
[62]
Laion- 5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion- 5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022. 7
2022
-
[63]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. 17
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[64]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 6, 17, 22, 26
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=St1giarCHLP. 1, 2
2021
-
[66]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021. URL https://openreview. net/forum?id=PxTIG12RRHS. 1
2021
-
[67]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. In International Conference on Machine Learning, pages 32211–32252. PMLR, 2023. 17, 19
2023
-
[69]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Z-Image Team. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025. 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024. 1, 17
2024
-
[71]
Feng Wang and Zihao Yu. Coefficients-preserving sampling for reinforcement learning with flow matching.arXiv preprint arXiv:2509.05952, 2025. 4, 7, 9, 19 14
-
[72]
Phased consistency models.Advances in neural information processing systems, 37:83951–84009, 2024
Fu-Yun Wang, Zhaoyang Huang, Alexander Bergman, Dazhong Shen, Peng Gao, Michael Lingelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, et al. Phased consistency models.Advances in neural information processing systems, 37:83951–84009, 2024. 17
2024
-
[73]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, and Zhongyuan Wang. Emu3: Next-token prediction is all you need, 2024...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Diffusion-gan: Training gans with diffusion
Zhendong Wang, Huangjie Zheng, Pengcheng He, Weizhu Chen, and Mingyuan Zhou. Diffusion-gan: Training gans with diffusion. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URLhttps://openreview.net/forum?id=HZf7UbpWHuA. 17
2023
-
[75]
Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in Neural Information Processing Systems, 36:8406–8441, 2023. 17
2023
-
[76]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023. 1, 7, 8, 24
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[77]
SANA 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng YU, Ligeng Zhu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, Han Cai, Bingchen Liu, Daquan Zhou, and Song Han. SANA 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.ne...
2025
-
[78]
Show-o: One single transformer to unify multimodal understanding and generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=o6Ynz6OIQ6. 25
2025
-
[79]
Imagereward: Learning and evaluating human preferences for text-to-image generation
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems, 36:15903–15935, 2023. 1, 2, 7, 17
2023
-
[80]
Shuchen Xue, Chongjian Ge, Shilong Zhang, Yichen Li, and Zhi-Ming Ma. Advantage weighted matching: Aligning rl with pretraining in diffusion models.arXiv preprint arXiv:2509.25050,
-
[82]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818, 2025. 8, 10, 17
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.