Express Language Modeling
Pith reviewed 2026-06-27 13:43 UTC · model grok-4.3
The pith
Express converts non-causal attention approximations into causal ones while preserving their error guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
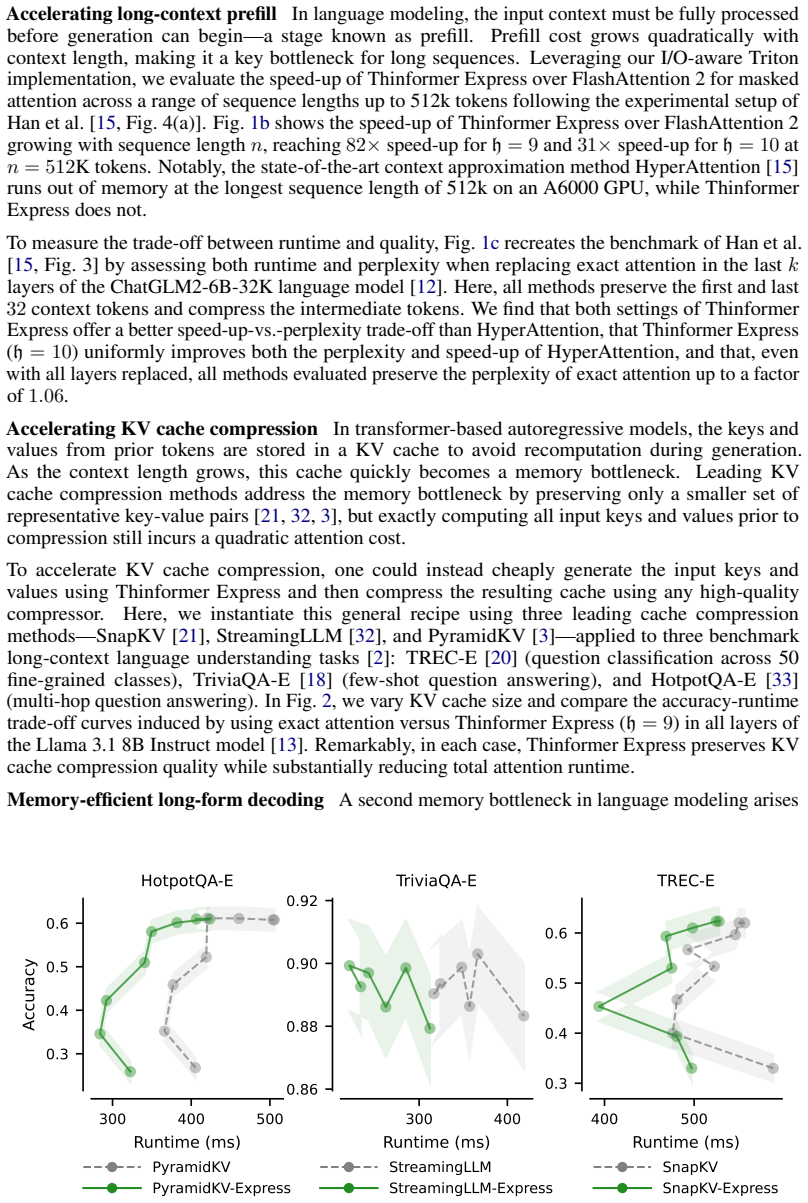
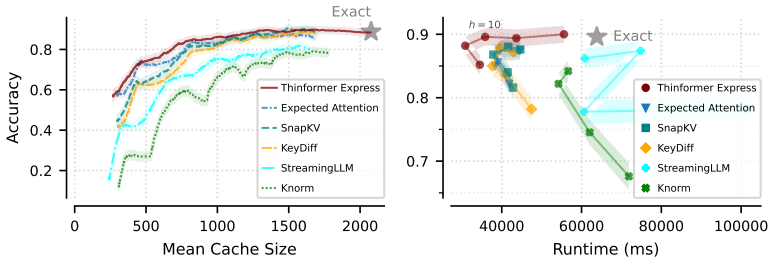
Express is a conversion tool that takes a non-causal attention approximation and produces a causal version with exactly the same approximation guarantees. When combined with the state-of-the-art Thinformer approximation, Express improves upon the best known causal attention guarantees, delivering log to the three-halves of n over s approximation error with only O(s) memory and O(s squared log squared of n) compression overhead for a sequence of length n. The method is realized in an efficient I/O-aware Triton implementation that demonstrates substantial speedups over FlashAttention 2 and removes four resource bottlenecks in the language modeling pipeline: long-context prefill, KV cache compr
What carries the argument
Express, the conversion procedure from non-causal to causal attention approximation that preserves the original approximation guarantees exactly.
If this is right
- Causal attention can now achieve the same approximation quality previously available only in non-causal settings.
- The error bound improves to log to the three-halves of n over s with linear memory in s.
- Compression overhead remains O(s squared log squared of n) for sequence length n.
- An efficient Triton implementation produces speedups relative to FlashAttention 2.
- Four concrete bottlenecks in long-context language modeling are removed: prefill, KV cache compression, memory-constrained decoding, and compute-constrained decoding.
Where Pith is reading between the lines
- Future non-causal approximation improvements can transfer directly to causal language models via the same conversion.
- Separate lines of research on causal-only approximations may become less necessary.
- The memory and overhead scaling could support longer context windows under fixed hardware budgets.
Load-bearing premise
The conversion procedure from non-causal to causal approximation preserves the original approximation guarantees exactly, without requiring additional assumptions on the attention matrix or sequence statistics.
What would settle it
An explicit attention matrix and sequence where the causal approximation produced by Express exhibits strictly larger error than the original non-causal approximation.
Figures

read the original abstract
We introduce a new tool, Express, for converting a non-causal attention approximation into a causal approximation with matching approximation guarantees. When combined with the state-of-the-art Thinformer approximation, Express improves upon the best known causal attention guarantees, delivering $\log^{3/2}(n)/s$ approximation error with only $O(s)$ memory and $O(s^2 \log^2(n))$ compression overhead for a sequence of length $n$. We pair these developments with an efficient I/O-aware Triton implementation, demonstrate substantial speedups over FlashAttention 2, and use Express to overcome four resource bottlenecks in the language modeling pipeline: long-context prefill, KV cache compression, long-form memory-constrained decoding, and long-form compute-constrained decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Express, a conversion tool that transforms non-causal attention approximations into causal ones while preserving the original approximation guarantees. When paired with the Thinformer approximation, Express yields a causal attention guarantee of log^{3/2}(n)/s error using O(s) memory and O(s^2 log^2(n)) compression overhead for sequence length n. The work also provides an I/O-aware Triton implementation demonstrating speedups over FlashAttention 2 and applies the method to address bottlenecks in long-context prefill, KV cache compression, and memory/compute-constrained decoding.
Significance. If the conversion procedure indeed maps non-causal guarantees to causal attention without additional error terms or assumptions, the result would strengthen the best-known theoretical bounds for causal attention and enable more efficient long-context language modeling. The combination of improved bounds, low memory overhead, and a practical implementation would be a notable contribution to efficient transformer research.
major comments (1)
- [Abstract] Abstract: The central claim that Express converts a non-causal approximation (Thinformer) into a causal one while delivering exactly the same log^{3/2}(n)/s error bound (with no extra terms) is load-bearing for the stated improvement over prior causal attention results. The skeptic concern that the conversion step may introduce lower-order error or require additional matrix assumptions (e.g., decay properties away from the diagonal) is not resolved by the abstract alone; without the explicit construction and error analysis, the bound does not follow directly from the non-causal case.
Simulated Author's Rebuttal
We thank the referee for their careful review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that Express converts a non-causal approximation (Thinformer) into a causal one while delivering exactly the same log^{3/2}(n)/s error bound (with no extra terms) is load-bearing for the stated improvement over prior causal attention results. The skeptic concern that the conversion step may introduce lower-order error or require additional matrix assumptions (e.g., decay properties away from the diagonal) is not resolved by the abstract alone; without the explicit construction and error analysis, the bound does not follow directly from the non-causal case.
Authors: The manuscript provides the explicit construction of Express together with the full error analysis in Sections 3 and 4. The conversion maps any non-causal approximation to a causal one while preserving the original error bound exactly, without introducing lower-order terms. The argument relies only on the standard assumptions already used for the non-causal Thinformer guarantee and does not require additional decay properties away from the diagonal. Consequently the stated causal bound follows directly from the non-causal result via the given mapping. revision: no
Circularity Check
No circularity detected; derivation self-contained
full rationale
The paper introduces Express as a new conversion procedure that maps non-causal approximations (such as Thinformer) to causal ones while preserving the original error bounds exactly. No equations, fitted parameters, or derivation steps are exhibited in the provided text that reduce the claimed log^{3/2}(n)/s guarantee to a self-definition, a renamed fit, or a load-bearing self-citation chain. Thinformer is referenced as an external state-of-the-art result, and the conversion is presented as a novel construction whose guarantees follow from its definition rather than tautologically equaling its inputs. The central claim therefore remains independent of the patterns that would trigger circularity scores above 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Discrepancy minimization via a self-balancing walk
Ryan Alweiss, Yang P Liu, and Mehtaab Sawhney. Discrepancy minimization via a self-balancing walk. InProceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pages 14–20, 2021.(Cited on page 6.)
2021
-
[2]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages ...
2024
-
[3]
Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, et al. Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling. InSecond Conference on Language Modeling, 2025.(Cited on pages 2 and 8.)
2025
-
[4]
Low-rank thinning
Annabelle Michael Carrell, Albert Gong, Abhishek Shetty, Raaz Dwivedi, and Lester Mackey. Low-rank thinning. InInternational Conference on Machine Learning, pages 6811–6848. PMLR, 2025.(Cited on pages 1, 2, 5, 6, 7, 13, 16, and 17.)
2025
-
[5]
On linear-time deterministic algorithms for optimization problems in fixed dimension.Journal of Algorithms, 21(3):579–597, 1996.(Cited on page 6.)
Bernard Chazelle and Jiri Matousek. On linear-time deterministic algorithms for optimization problems in fixed dimension.Journal of Algorithms, 21(3):579–597, 1996.(Cited on page 6.)
1996
-
[6]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=mZn2Xyh9Ec.(Cited on pages 1, 7, and 10.)
2024
-
[7]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in Neural Information Processing Systems, 35:16344–16359, 2022.(Cited on pages 1 and 7.)
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in Neural Information Processing Systems, 35:16344–16359, 2022.(Cited on pages 1 and 7.)
2022
-
[8]
A simple and effective l_2 norm-based strategy for kv cache compression
Alessio Devoto, Yu Zhao, Simone Scardapane, and Pasquale Minervini. A simple and effective l_2 norm-based strategy for kv cache compression. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18476–18499, 2024.(Cited on page 9.)
2024
-
[9]
Alessio Devoto, Maximilian Jeblick, and Simon Jégou. Expected attention: Kv cache compression by estimating attention from future queries distribution.arXiv preprint arXiv:2510.00636, 2025.(Cited on pages 9 and 21.)
-
[10]
Generalized kernel thinning
Raaz Dwivedi and Lester Mackey. Generalized kernel thinning. InInternational Conference on Learning Representations, 2022.(Cited on pages 2 and 5.) 10
2022
-
[11]
Kernel thinning.Journal of Machine Learning Research, 25 (152):1–77, 2024.(Cited on pages 2, 5, and 15.)
Raaz Dwivedi and Lester Mackey. Kernel thinning.Journal of Machine Learning Research, 25 (152):1–77, 2024.(Cited on pages 2, 5, and 15.)
2024
-
[12]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team Glm, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024.(Cited on page 8.)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024.(Cited on page 8.)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025.(Cited on pages 1 and 9.)
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025.(Cited on pages 1 and 9.)
2025
-
[15]
Hyperattention: Long-context attention in near-linear time
Insu Han, Rajesh Jayaram, Amin Karbasi, Vahab Mirrokni, David Woodruff, and Amir Zandieh. Hyperattention: Long-context attention in near-linear time. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=Eh0Od2BJIM.(Cited on pages 1, 6, and 8.)
2024
-
[16]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URL https://openreview.net/forum?id=7Bywt2mQsCe.(Cited on pages ...
2021
- [17]
-
[18]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, 2017.(Cited on page 8.)
2017
-
[19]
Streaming attention approximation via discrepancy theory
Ekaterina Kochetkova, Kshiteej Sheth, Insu Han, Amir Zandieh, and Michael Kapralov. Streaming attention approximation via discrepancy theory. InAdvances in Neural Information Processing Systems, 2025.(Cited on pages 1 and 6.)
2025
-
[20]
Learning question classifiers
Xin Li and Dan Roth. Learning question classifiers. InCOLING 2002: The 19th International Conference on Computational Linguistics, 2002.(Cited on page 8.)
2002
-
[21]
Snapkv: Llm knows what you are looking for before generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation. InAdvances in Neural Information Processing Systems, volume 37, 2024. (Cited on pages 2, 8, and 9.)
2024
-
[22]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023.(Cited on pages 2, 9, and 21.)
2023
-
[23]
Approximations and optimal geometric divide-and-conquer.Journal of Computer and System Sciences, 50(2):203–208, 1995.(Cited on page 6.)
Jiri Matousek. Approximations and optimal geometric divide-and-conquer.Journal of Computer and System Sciences, 50(2):203–208, 1995.(Cited on page 6.)
1995
-
[24]
Keydiff: Key similarity-based kv cache eviction for long-context llm inference in resource-constrained environments
Junyoung Park, Dalton Jones, Matthew J Morse, Raghavv Goel, Mingu Lee, and Christopher Lott. Keydiff: Key similarity-based kv cache eviction for long-context llm inference in resource-constrained environments. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025.(Cited on page 9.)
2025
-
[25]
Algorithms for ε-approximations of terrains
Jeff M Phillips. Algorithms for ε-approximations of terrains. InInternational Colloquium on Automata, Languages, and Programming, pages 447–458. Springer, 2008.(Cited on page 6.)
2008
-
[26]
WildCat: Near-Linear Attention in Theory and Practice
Tobias Schröder and Lester Mackey. Wildcat: Near-linear attention in theory and practice. arXiv preprint arXiv:2602.10056, 2026.(Cited on pages 1 and 6.)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Flashattention-3: Fast and accurate attention with asynchrony and low-precision.Advances in Neural Information Processing Systems, 37:68658–68685, 2024.(Cited on page 10.)
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision.Advances in Neural Information Processing Systems, 37:68658–68685, 2024.(Cited on page 10.)
2024
-
[28]
Distribution compression in near-linear time
Abhishek Shetty, Raaz Dwivedi, and Lester Mackey. Distribution compression in near-linear time. InInternational Conference on Learning Representations, 2022.(Cited on pages 3 and 14.) 11
2022
-
[29]
Support vector machines.Wiley Interdisciplinary Reviews: Computational Statistics, 1, 2008
Ingo Steinwart and Andreas Christmann. Support vector machines.Wiley Interdisciplinary Reviews: Computational Statistics, 1, 2008. URL https://api.semanticscholar.org/ CorpusID:661123.(Cited on pages 2 and 15.)
2008
-
[30]
Triton: an intermediate language and compiler for tiled neural network computations
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019.(Cited on pages 1 and 7.)
2019
-
[31]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY , USA, 2017. Curran Associates Inc. ISBN 9781510860964.(Cited on pages 1,...
2017
-
[32]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations,
-
[33]
URLhttps://openreview.net/forum?id=NG7sS51zVF.(Cited on pages 2, 8, and 9.)
-
[34]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2369–2380, 2018.(Cited on page 8.)
2018
-
[35]
Kdeformer: Accelerating transformers via kernel density estimation
Amir Zandieh, Insu Han, Majid Daliri, and Amin Karbasi. Kdeformer: Accelerating transformers via kernel density estimation. InInternational Conference on Machine Learning, pages 40605–40623. PMLR, 2023.(Cited on page 1.) 12 A Kernel Halving For completeness, we reproduce the KH(δ)halving algorithm of Carrell et al. [4, Alg. B.1]. Algorithm A.1:KH(δ): Kern...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.