Grounded Cache Routing for Retrieval-Augmented Generation: When Is It Safe to Reuse an Answer?
Pith reviewed 2026-06-29 17:13 UTC · model grok-4.3
The pith
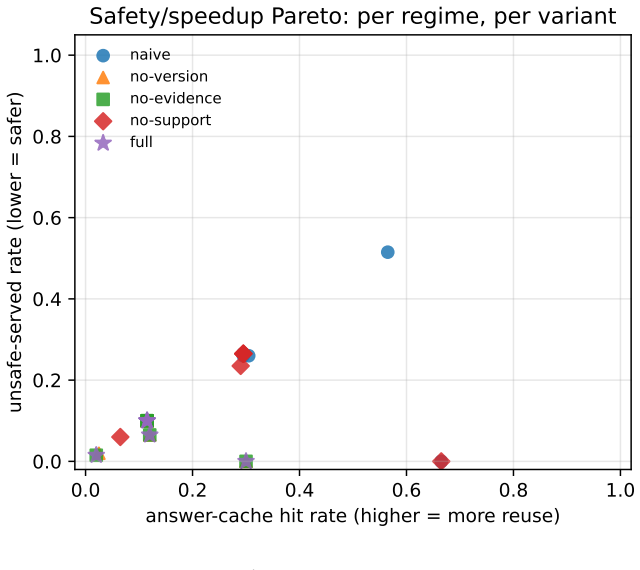
GroundedCache admits a cached RAG answer only when four evidence gates hold, driving unsafe-served rate to 0 percent on HotpotQA and 1.5 percent on mtRAG drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
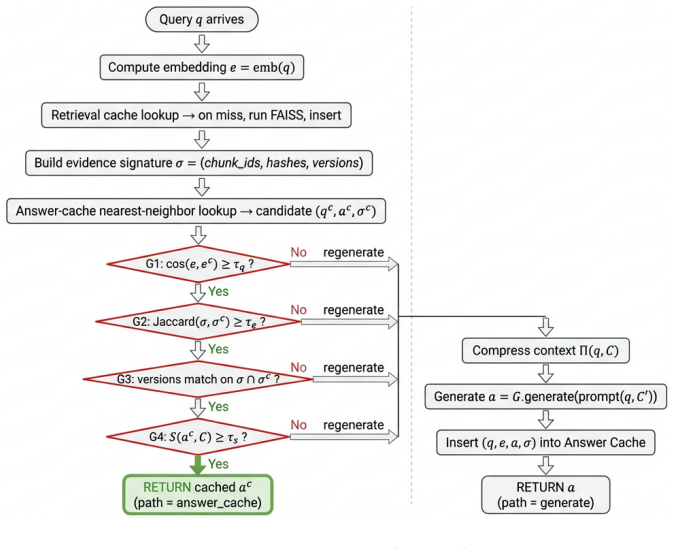
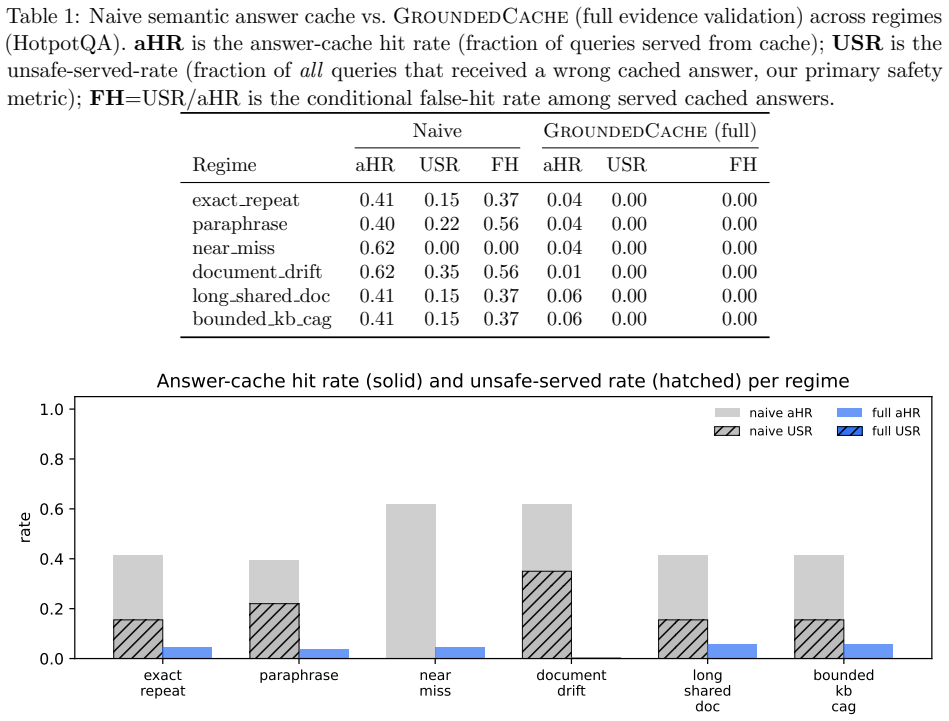
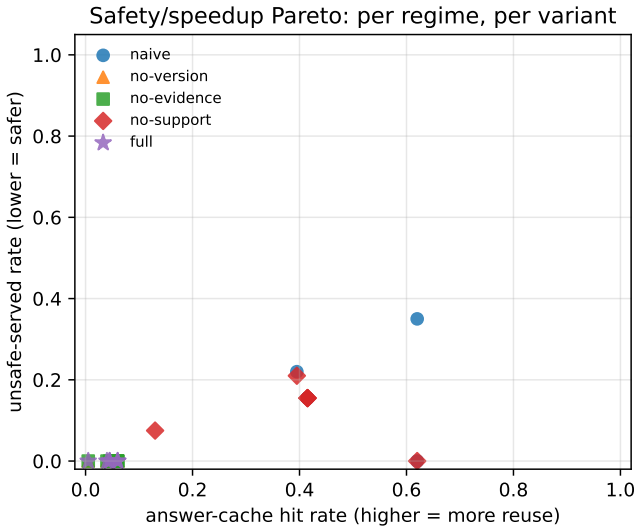
GroundedCache is an evidence-validated cache router that admits a cached answer only when query similarity, retrieved-evidence overlap, source-version validity, and lexical (or judge-based) support of the cached answer by the freshly retrieved evidence all hold simultaneously. On a six-regime workload covering 12,000 generations with Qwen2.5-7B-Instruct, it drives unsafe-served rate to 0.0 percent on every HotpotQA regime versus 15-35 percent under naive caching and to 1.5 percent on mtRAG document drift versus 51.5 percent, producing a 34x reduction on the design-point adversarial regime and 3-10x reductions elsewhere, while end-to-end p50 latency remains 1.04-1.07x of a no-cache RAG baseli
What carries the argument
The four-gate evidence-validated router, with lexical (or judge-based) support of the cached answer by fresh evidence serving as the primary safety gate.
If this is right
- RAG deployments can safely reuse cached answers in dynamic corpora without exposing users to incorrect responses at scale.
- Unsafe-served rate becomes a practical operator metric for evaluating cache safety beyond hit rate.
- The remaining three gates supply defense-in-depth at negligible added cost once lexical support is in place.
- End-to-end latency overhead stays small enough that safety gains do not trade off against responsiveness.
Where Pith is reading between the lines
- Similar gated validation could be applied to output caches outside RAG where evidence or context changes over time.
- Replacing lexical support with a lightweight judge model might preserve safety while further reducing token cost.
- The approach suggests a general pattern for safe reuse in any system that pairs retrieval with generative output.
Load-bearing premise
Lexical or judge-based support of the cached answer by the freshly retrieved evidence is a reliable indicator that the cached answer remains correct.
What would settle it
A query instance in which all four gates pass yet the cached answer is factually incorrect or mismatched to the current evidence.
Figures




read the original abstract
Modern retrieval-augmented generation(RAG) deployments increasingly rely on caching to reduce token cost and time-to-first-token(TTFT). Prefix-level KV reuse is now standard in serving stacks such as vLLM, and chunk-level and position-independent reuse have been pushed further by recent systems(RAGCache, TurboRAG, CacheBlend, EPIC, ContextPilot, PCR, LMCache). Output-level semantic answer caches, by contrast, remain fragile: similar prompts can map to different correct answers, retrieved evidence drifts as the corpus is updated, and adversarial collision attacks have been shown to hijack cached responses. We argue that the right framing for cached answer reuse is not how to reuse faster but when reuse is safe. We propose GroundedCache, an evidence-validated cache router that admits a cached answer only when 4 cheap gates simultaneously hold: query similarity, retrieved-evidence overlap, source-version validity, and lexical (or judge-based) support of the cached answer by the freshly retrieved evidence. We build a six-regime workload that stress-tests cache safety rather than only hit rate, and introduce an operator-facing metric, the unsafe-served rate (USR), fraction of all queries that received a wrong cached answer. Across 2 datasets and 12,000 real-LLM generations(Qwen2.5-7B-Instruct on vLLM with Automatic Prefix Caching), GroundedCache drives USR to 0.0% on every HotpotQA regime(vs. 15-35% under naive caching) and to 1.5% on mtRAG document drift(vs. 51.5%), a 34x reduction on the design-point adversarial regime and 3-10x reductions across the other mtRAG regimes, while end-to-end p50 latency stays within 1.04-1.07x of a no-cache RAG baseline. A per-gate ablation isolates the lexical support gate as the load-bearing safety mechanism on both datasets, with the remaining gates providing defense-in-depth at near-zero cost. We release the implementation, workload, and evaluation harness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
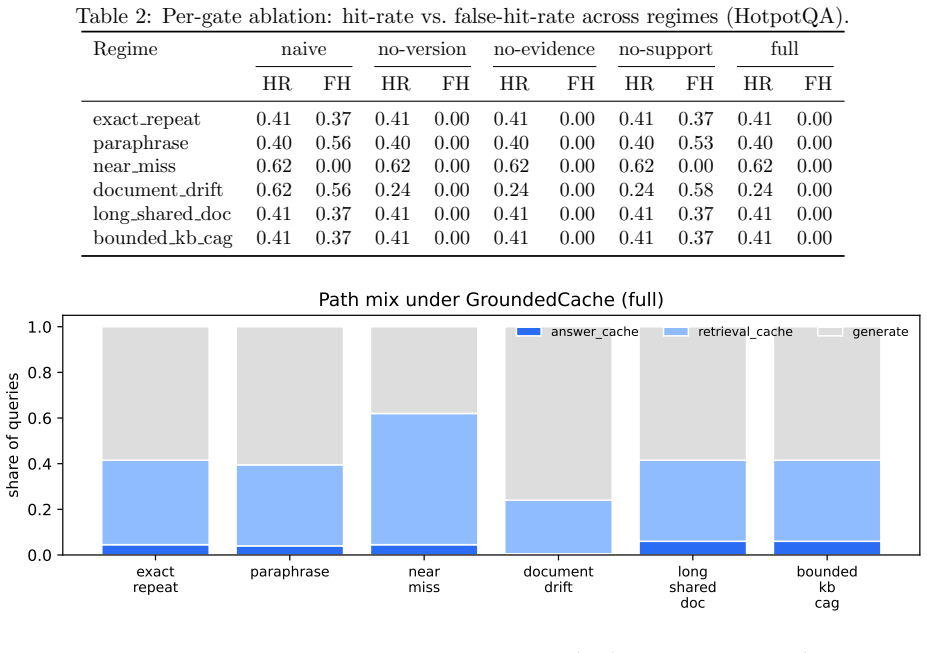
Summary. The manuscript proposes GroundedCache, an evidence-validated cache router for RAG systems that admits a cached answer only when four gates hold simultaneously: query similarity, retrieved-evidence overlap, source-version validity, and lexical (or judge-based) support of the cached answer by fresh evidence. Evaluated on HotpotQA and mtRAG across 12,000 real generations with Qwen2.5-7B-Instruct on vLLM, it reports USR reductions to 0.0% on all HotpotQA regimes (vs. 15-35% naive) and 1.5% on mtRAG document drift (vs. 51.5%), with p50 latency 1.04-1.07x of no-cache baseline; per-gate ablation identifies the support gate as load-bearing.
Significance. If the safety claims hold under independent verification, the work supplies a practical, low-overhead mechanism for safe output-level caching in production RAG, directly addressing collision and drift risks. The introduction of the USR metric, the six-regime stress-test workload, and the public release of code, workload, and harness are concrete strengths that support reproducibility and further research.
major comments (1)
- [Abstract] Abstract (per-gate ablation paragraph): the claim that simultaneous satisfaction of the four gates (especially lexical/judge-based support) implies the cached answer remains correct is load-bearing, yet the manuscript provides no details on the exact support threshold, judge prompt, inter-annotator agreement, or the independent correctness oracle used to compute USR. Without these, it is impossible to rule out correlated failure modes between the support gate and the USR evaluator, particularly on multi-hop HotpotQA queries where evidence overlap can hold while the answer is still incorrect due to reasoning differences.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on transparency and reproducibility. We agree that the abstract requires additional detail to support the load-bearing claim and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (per-gate ablation paragraph): the claim that simultaneous satisfaction of the four gates (especially lexical/judge-based support) implies the cached answer remains correct is load-bearing, yet the manuscript provides no details on the exact support threshold, judge prompt, inter-annotator agreement, or the independent correctness oracle used to compute USR. Without these, it is impossible to rule out correlated failure modes between the support gate and the USR evaluator, particularly on multi-hop HotpotQA queries where evidence overlap can hold while the answer is still incorrect due to reasoning differences.
Authors: We agree the abstract paragraph is insufficiently detailed for independent verification. In the revised manuscript we will expand the abstract (and ensure the body already contains or will explicitly cross-reference) the exact lexical support threshold, the full judge prompt for the alternative variant, inter-annotator agreement statistics, and the independent correctness oracle (human annotation against ground truth on sampled queries) used to compute USR. On the correlated-failure concern, the primary support gate is lexical n-gram overlap, which is surface-form based and therefore orthogonal to the semantic correctness judgment underlying USR; the judge-based variant is presented only as an optional alternative. The query-similarity and evidence-overlap gates further constrain admission on multi-hop queries. We will add a short discussion of these independence properties and any residual risks. revision: yes
Circularity Check
No significant circularity; empirical system evaluated on external benchmarks
full rationale
The paper introduces GroundedCache as a set of four explicitly defined gates (query similarity, evidence overlap, source validity, lexical/judge support) and measures its effect via the externally defined USR metric on HotpotQA and mtRAG workloads using real LLM generations. No equations, fitted parameters, self-citations as load-bearing premises, or renamings of known results appear in the provided text. The central safety claim is supported by direct ablation and comparison against naive caching on independent datasets rather than reducing to a definitional identity or self-referential fit.
Axiom & Free-Parameter Ledger
free parameters (1)
- gate thresholds (query similarity, evidence overlap, lexical support)
Reference graph
Works this paper leans on
-
[1]
https://docs.vllm.ai/en/latest/features/automatic_ prefix_caching.html, 2024
vLLM automatic prefix caching. https://docs.vllm.ai/en/latest/features/automatic_ prefix_caching.html, 2024. Accessed: 2026
2024
-
[2]
SGLang: Efficient execution of structured language model programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, et al. SGLang: Efficient execution of structured language model programs. InNeurIPS, 2024
2024
-
[3]
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Xin Liu, Xuanzhe Liu, and Xin Jin. RAGCache: Efficient knowledge caching for retrieval-augmented generation.arXiv preprint arXiv:2404.12457, 2024
-
[4]
Songshuo Lu, Hua Wang, Yutian Rong, Zhi Chen, and Yaohua Tang. TurboRAG: Accelerating retrieval-augmented generation with precomputed KV caches for chunked text.arXiv preprint arXiv:2410.07590, 2024
-
[5]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. CacheBlend: Fast large language model serving for RAG with cached knowledge fusion.arXiv preprint arXiv:2405.16444, 2024
-
[6]
Junhao Hu, Wenrui Huang, Weidong Wang, Zhenwen Yuan, Tiancheng Xie, Zhixia Liu, Xusheng Liu, Tao Cui, Fei Liu, and Yizhou Cao. EPIC: Efficient position-independent caching for serving large language models.arXiv preprint arXiv:2410.15332, 2024
-
[7]
ContextPilot: Fast Long-Context Inference via Context Reuse
EfficientContext. ContextPilot: Fast long-context inference via context reuse.arXiv preprint arXiv:2511.03475, 2025. To appear, MLSys 2026
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Wenfeng Wang, Xiaofeng Hou, Peng Tang, et al. PCR: A prefetch-enhanced cache reuse system for low-latency RAG serving.arXiv preprint arXiv:2603.23049, 2026. 17
-
[9]
arXiv preprint arXiv:2510.09665 , year=
LMCache Team. LMCache: An efficient KV cache layer for enterprise-scale LLM inference. arXiv preprint arXiv:2510.09665, 2025
-
[10]
Leveraging approximate caching for faster retrieval-augmented generation
Shai Bergman et al. Leveraging approximate caching for faster retrieval-augmented generation. arXiv preprint arXiv:2503.05530, 2025. EuroMLSys 2025
-
[11]
QVCache: A query-aware vector cache.arXiv preprint arXiv:2602.02057, 2026
Anıl Eren G¨ o¸ cer et al. QVCache: A query-aware vector cache.arXiv preprint arXiv:2602.02057, 2026
-
[12]
GPTCache: An open-source semantic cache for LLM applications enabling faster answers and cost savings.Proceedings of the NLP-OSS Workshop, 2023
Fu Bang. GPTCache: An open-source semantic cache for LLM applications enabling faster answers and cost savings.Proceedings of the NLP-OSS Workshop, 2023
2023
-
[13]
ContextCache: Context-aware semantic cache for multi-turn queries in large language models
Jianxin Yan, Wangze Ni, Lei Chen, Xuemin Lin, Peng Cheng, Zhan Qin, and Kui Ren. ContextCache: Context-aware semantic cache for multi-turn queries in large language models. Proc. VLDB Endowment, 2025. arXiv:2506.22791
-
[14]
Zhixiang Zhang, Zesen Liu, Yuchong Xie, Quanfeng Huang, and Dongdong She. From similarity to vulnerability: Key collision attack on LLM semantic caching.arXiv preprint arXiv:2601.23088, 2026
-
[15]
Fangyuan Xu, Weijia Shi, and Eunsol Choi. RECOMP: Improving retrieval-augmented LMs with compression and selective augmentation.arXiv preprint arXiv:2310.04408, 2023
-
[16]
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. LongLLMLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression.arXiv preprint arXiv:2310.06839, 2023
-
[17]
Nadezhda Chirkova, Thibault Formal, Vassilina Nikoulina, and St´ ephane Clinchant. Provence: Efficient and robust context pruning for retrieval-augmented generation.arXiv preprint arXiv:2501.16214, 2025. ICLR 2025
-
[18]
Maxime Louis, Nadezhda Chirkova, Thibault Formal, and St´ ephane Clinchant. PISCO: Pretty simple compression for retrieval-augmented generation.arXiv preprint arXiv:2501.16075, 2025
-
[19]
OSCAR: Online soft compression and reranking.arXiv preprint arXiv:2504.07109, 2025
Maxime Louis, Nadezhda Chirkova, Thibault Formal, and St´ ephane Clinchant. OSCAR: Online soft compression and reranking.arXiv preprint arXiv:2504.07109, 2025
-
[20]
Anonymous. Rethinking soft compression in retrieval-augmented generation: A query- conditioned selector perspective.arXiv preprint arXiv:2602.15856, 2026. SeleCom
-
[21]
REFRAG: Rethinking RAG based decoding.arXiv preprint arXiv:2509.01092, 2025
Meta Superintelligence Labs. REFRAG: Rethinking RAG based decoding.arXiv preprint arXiv:2509.01092, 2025
-
[22]
Ragas: Automated Evaluation of Retrieval Augmented Generation
Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. RAGAS: Automated evaluation of retrieval augmented generation.arXiv preprint arXiv:2309.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Jon Saad-Falcon, Omar Khattab, Christopher Potts, and Matei Zaharia. ARES: An au- tomated evaluation framework for retrieval-augmented generation systems.arXiv preprint arXiv:2311.09476, 2023
-
[24]
Context: {c} \\ Question: {q} \\Answer:
Cheng Niu, Yuanhao Wu, Juno Zhu, Siliang Xu, Kashun Shum, Randy Zhong, Juntong Song, and Tong Zhang. RAGTruth: A hallucination corpus for developing trustworthy retrieval- augmented language models.arXiv preprint arXiv:2401.00396, 2024. 18
-
[25]
Robert Friel, Masha Belyi, and Atindriyo Sanyal. RAGBench: Explainable benchmark for retrieval-augmented generation systems.arXiv preprint arXiv:2407.11005, 2024
-
[26]
Dongyu Ru, Lin Qiu, Xiangkun Hu, Tianhang Zhang, Peng Shi, Shuaichen Chang, Cheng Jiayang, Cunxiang Wang, Siyuan Sun, Hang Li, Zheng Zhang, Binjie Wang, Jiarong Jiang, Tong He, Zhiguo Wang, Pengfei Liu, Yue Zhang, and Zheng Zhang. RAGChecker: A fine-grained framework for diagnosing retrieval-augmented generation.arXiv preprint arXiv:2408.08067, 2024
-
[27]
Yannis Katsis, Sara Rosenthal, Kshitij Fadnis, Chulaka Gunasekara, Young-Suk Lee, Lu- cian Popa, Vraj Shah, Huaiyu Zhu, Danish Contractor, and Marina Danilevsky. MTRAG: A multi-turn conversational benchmark for evaluating retrieval-augmented generation sys- tems.Transactions of the Association for Computational Linguistics, 2025. arXiv:2501.03468; benchma...
-
[28]
Anonymous. T 2-RAGBench: Text-and-table benchmark for evaluating retrieval-augmented generation.arXiv preprint arXiv:2506.12071, 2025. EACL 2026
-
[29]
Brian J Chan, Chao-Ting Chen, Jui-Hung Cheng, and Hen-Hsen Huang. Don’t do RAG: When cache-augmented generation is all you need for knowledge tasks.arXiv preprint arXiv:2412.15605, 2024
-
[30]
MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. InNeurIPS, 2020
2020
-
[31]
Billion-scale similarity search with GPUs
Jeff Johnson, Matthijs Douze, and Herv´ e J´ egou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 2017. 19
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.