Mandol: An Agglomerative Agent Memory System for Long-Term Conversations
Pith reviewed 2026-06-30 04:10 UTC · model grok-4.3
The pith
Mandol replaces heterogeneous databases with a unified agglomerative semantic graph for agent memory, achieving best accuracy and 5.4x retrieval speedup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
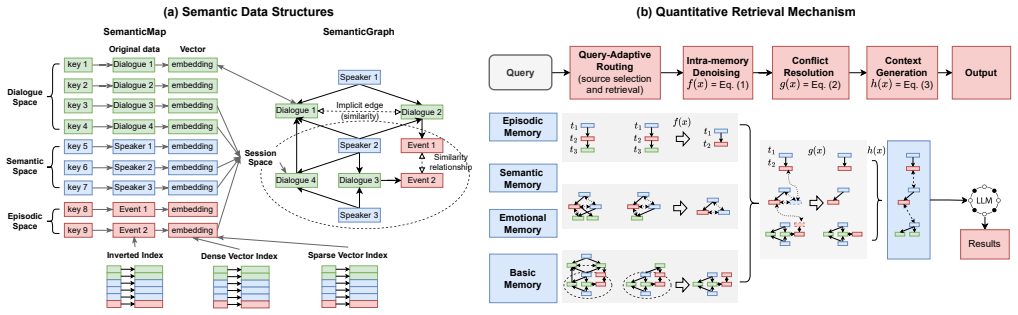
Mandol is an agglomerative memory system that consolidates memory into a unified architecture consisting of a hierarchical memory model with basic raw and high-level abstract layers represented as structured semantic graphs, an agglomerative semantic data structure that combines SemanticMap and SemanticGraph to fuse key-value, vector, and graph structures with unified hybrid retrieval operators, and a quantitative query mechanism featuring query-adaptive routing, quantitative denoising, conflict resolution, and token-constrained context generation without LLM involvement during retrieval.
What carries the argument
The agglomerative semantic data structure that combines SemanticMap and SemanticGraph to natively fuse key-value, vector, and graph structures and provide unified hybrid retrieval operators, eliminating cross-database I/O.
Load-bearing premise
The premise that cross-database I/O latency and RAG-style noise are the main problems and that a single agglomerative semantic graph can handle complex correlations without introducing new information loss.
What would settle it
Running Mandol on a benchmark with many conflicting cross-session facts and measuring if its accuracy falls below that of a well-tuned heterogeneous system.
Figures

read the original abstract
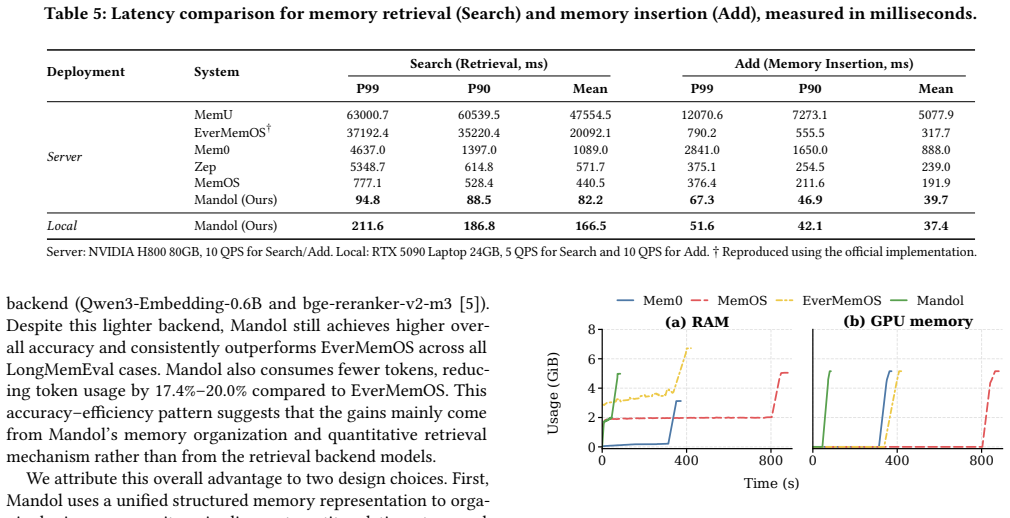
Long-term conversational agents need to remember and query cross-session, multi-typed information with complex correlations. Existing agent memory systems rely on heterogeneous vector and graph databases, which fragment memory information and cause high cross-database I/O latency. For retrieval, common RAG-style methods tend to introduce noise, miss correlated clues, and lack token budget control, degrading LLM accuracy and efficiency. We propose Mandol, an agglomerative memory system that consolidates fragmented memory representations and storage into a unified memory-native architecture. Its core components include: (1) a hierarchical memory model that organizes memory into a basic layer representing raw memory information and a high-level abstract layer that agglomerates basic memories into traceable abstract memories, both uniformly represented as structured semantic graphs; (2) an agglomerative semantic data structure combining SemanticMap and SemanticGraph, which natively fuses key-value, vector, and graph structures and provides unified hybrid retrieval operators to eliminate cross-database I/O; and (3) a quantitative query mechanism with query-adaptive routing, quantitative denoising and conflict resolution, and token-constrained context generation, all without involving LLMs during retrieval. Experiments on two widely used long-term conversation benchmarks, LoCoMo and LongMemEval, show that Mandol achieves the best overall accuracy among representative agent memory systems. For performance comparison, Mandol also obtains a 5.4x retrieval speedup and a 4.8x insertion speedup under 10 QPS concurrent load, while still maintaining low latency on consumer-grade hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mandol, an agglomerative memory system for long-term conversational agents. It consolidates heterogeneous vector/graph storage into a unified hierarchical semantic graph architecture consisting of a basic layer for raw memories and an abstract layer for agglomerated traceable memories, fused via a SemanticMap+SemanticGraph structure with hybrid retrieval operators. A quantitative query mechanism handles routing, denoising, conflict resolution, and token-constrained generation without LLM calls during retrieval. On LoCoMo and LongMemEval, it reports the highest overall accuracy among compared systems, plus 5.4x retrieval and 4.8x insertion speedups at 10 QPS on consumer hardware.
Significance. If the accuracy and speedup claims hold under rigorous evaluation, the unified architecture could meaningfully reduce fragmentation and cross-database latency in agent memory systems while providing controllable, non-LLM retrieval. The explicit fusion of key-value/vector/graph structures and the quantitative operators are concrete engineering contributions that address stated pain points in existing RAG-style and heterogeneous setups.
minor comments (3)
- [Abstract, §4] Abstract and §4 (experiments): the accuracy claims are presented without error bars, standard deviations, or mention of run-to-run variance; adding these would strengthen the 'best overall accuracy' statement.
- [§3.2] §3.2 (data structure): the description of how SemanticMap and SemanticGraph are fused and how the hybrid operators are implemented would benefit from a small pseudocode or complexity table to clarify the claimed elimination of cross-database I/O.
- [§4.3] §4.3 (performance): the 10 QPS concurrent-load experiment lacks details on the exact workload mix, number of sessions, and hardware configuration; these would make the 5.4x/4.8x speedups easier to reproduce and compare.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the significance of the unified architecture, and recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity; system architecture and empirical results are self-contained
full rationale
The paper describes an engineering system (hierarchical memory model, SemanticMap/SemanticGraph structure, quantitative query operators) and reports benchmark accuracy plus speedups on LoCoMo and LongMemEval. No equations, fitted parameters renamed as predictions, self-citations invoked as uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. Claims rest on experimental measurements rather than any derivation that reduces to the authors' own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cross-database I/O and RAG noise are the primary sources of latency and accuracy loss in long-term agent memory.
- domain assumption Hierarchical agglomeration into traceable abstract memories preserves necessary correlations for downstream LLM use.
invented entities (1)
-
SemanticMap and SemanticGraph fused structure
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Renzo Angles and Claudio Gutierrez. 2008. Survey of Graph Database Models. Comput. Surveys40, 1 (2008), 1–39
2008
-
[2]
Ilias Azizi, Karima Echihabi, and Themis Palpanas. 2025. Graph-Based Vector Search: An Experimental Evaluation of the State-of-the-Art.Proc. ACM Manag. Data (SIGMOD)3, 1 (2025), 43:1–43:31
2025
-
[3]
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. 2025. Titans: Learning to Memorize at Test Time. InAdvances in Neural Information Processing Systems, Vol. 38. Curran Associates, Inc., San Diego, CA, USA and Mexico City, Mexico
2025
-
[4]
Cheng Chen, Chenzhe Jin, Yunan Zhang, Sasha Podolsky, Chun Wu, Szu- Po Wang, Eric Hanson, Zhou Sun, Robert Walzer, and Jianguo Wang. 2024. SingleStore-V: An Integrated Vector Database System in SingleStore.Proc. VLDB Endow.17, 12 (2024), 3772–3785
2024
-
[5]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[6]
InFindings of the Associ- ation for Computational Linguistics: ACL 2024
M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. InFindings of the Associ- ation for Computational Linguistics: ACL 2024. Association for Computational Linguistics, Bangkok, Thailand, 2318–2335
2024
-
[7]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav
-
[8]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory. InECAI 2025 - 28th European Conference on Artificial Intelligence, 25–30 October 2025, Bologna, Italy - Including 14th Conference on Prestigious Applica- tions of Intelligent Systems (PAIS 2025) (Frontiers in Artificial Intelligence and Applications). IOS Press, Bologna, Italy, 2993–3000
2025
-
[9]
Cormack, Charles L
Gordon V. Cormack, Charles L. A. Clarke, and Stefan Büttcher. 2009. Reciprocal Rank Fusion Outperforms Condorcet and Individual Rank Learning Methods. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Association for Computing Machinery, Boston, MA, USA, 758–759
2009
-
[10]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2025. From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. Association for Computing Machinery, Virtual Event, Canada, 2288–2292
2021
-
[12]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2024. Retrieval-Augmented Genera- tion for Large Language Models: A Survey. arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
-
[14]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2025. LightRAG: Simple and Fast Retrieval-Augmented Generation. InFindings of the Associa- tion for Computational Linguistics: EMNLP 2025. Association for Computational Linguistics, Suzhou, China, 10746–10761
2025
-
[15]
Bernal Jimenez Gutierrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[16]
InAdvances in Neural Information Processing Systems, Vol
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models. InAdvances in Neural Information Processing Systems, Vol. 37. Curran Associates, Inc., Vancouver, BC, Canada, 59532–59569
- [17]
-
[18]
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong Cheng, Xuanbo Fan, Jiaxin Guo, Xinlei Yu, Zhenhong Zhou, Zewen Hu, Jiahao Huo, Junhao Wang, Yuwei Niu, Yu Wang, Zhe...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Xu Huang, Jianxun Lian, Yuxuan Lei, Jing Yao, Defu Lian, and Xing Xie. 2025. Recommender AI Agent: Integrating Large Language Models for Interactive Recommendations.ACM Transactions on Information Systems43, 4 (2025), 96:1– 96:33
2025
-
[20]
Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2024. LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, B...
2024
-
[21]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2021. Billion-Scale Similarity Search with GPUs.IEEE Transactions on Big Data7, 3 (2021), 535–547
2021
-
[22]
Mosh Levy, Alon Jacoby, and Yoav Goldberg. 2024. Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand, 15339–15353
2024
-
[23]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Informa- tion Processing Systems, Vol. 33. Curran Associates, Inc., Virtua...
2020
-
[24]
Guoliang Li, Ji Sun, James Pan, Jiang Wang, Yongqing Xie, Ruicheng Liu, and Wen Nie. 2025. GaussDB-Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications.Proc. VLDB Endow.18, 12 (2025), 4951–4963
2025
-
[25]
Hao Li, Chenghao Yang, An Zhang, Yang Deng, Xiang Wang, and Tat-Seng Chua
-
[26]
Hello Again! LLM-powered Personalized Agent for Long-term Dialogue. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2025 - Volume 1: Long Papers, Albuquerque, New Mexico, USA, April 29 - May 4, 2025. Association for Computational Linguistics, A...
2025
- [27]
-
[28]
Yunxiang Li, Zihan Li, Kai Zhang, Ruilong Dan, Steve Jiang, and You Zhang
-
[29]
ChatDoctor: A Medical Chat Model Fine-Tuned on a Large Language Model Meta-AI (LLaMA) Using Medical Domain Knowledge.Cureus15, 6 (2023), e40895
2023
-
[30]
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, Qingchen Yu, Jihao Zhao, Yezhaohui Wang, Peng Liu, Zehao Lin, Pengyuan Wang, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhen Tao, Huayi Lai, Hao Wu, Bo Tang, Zhengren Wang, Zhaoxin Fan, Ningyu Zhang, Linfeng Zhang, Junchi Yan, Mingchuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Jiayi Liu, Yunan Zhang, Chenzhe Jin, Aditya Gupta, Shige Liu, and Jianguo Wang. 2026. Fast Vector Search in PostgreSQL: A Decoupled Approach. In16th 9 Conference on Innovative Data Systems Research, CIDR 2026, Chaminade, CA, USA, January 18-21, 2026. www.cidrdb.org
2026
-
[32]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173
2024
-
[33]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao, Chenwu Liu, Jingyang Yuan, Shichang Zhang, Yiqiao Jin, Fan Zhang, Xian Wu, Hanqing Zhao, Dacheng Tao, Philip S. Yu, and Ming Zhang. 2025. Large Language Model Agent: A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. 2024. Evaluating Very Long-Term Conversational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Bangkok, Thailand, 13851–13870
2024
-
[35]
Ilyas, Umar Farooq Minhas, Jeffrey Pound, and Theodoros Rekatsinas
Jason Mohoney, Anil Pacaci, Shihabur Rahman Chowdhury, Ali Mousavi, Ihab F. Ilyas, Umar Farooq Minhas, Jeffrey Pound, and Theodoros Rekatsinas. 2023. High-Throughput Vector Similarity Search in Knowledge Graphs.Proc. ACM Manag. Data (SIGMOD)1, 2 (2023), 197:1–197:25
2023
-
[36]
Tsendsuren Munkhdalai, Manaal Faruqui, and Siddharth Gopal. 2024. Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention. arXiv:2404.07143
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Neo4j, Inc. 2026. Neo4j Graph Database. https://neo4j.com/product/neo4j-graph- database/. Accessed: 2026-06-28
2026
-
[38]
NevaMind-AI. 2026. MemU: 24/7 Always-On Proactive Memory for AI Agents. https://github.com/NevaMind-AI/memU. Accessed: 2026-06-01
2026
-
[39]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. Association for Computing Machinery, San Francisco, CA, USA, Article 2, 22 pages
2023
-
[40]
Liana Patel, Peter Kraft, Carlos Guestrin, and Matei Zaharia. 2024. ACORN: Per- formant and Predicate-Agnostic Search Over Vector Embeddings and Structured Data.Proc. ACM Manag. Data (SIGMOD)2, 3 (2024), 120
2024
-
[41]
Qdrant Team. 2026. Qdrant: High-performance Vector Search Engine. https: //qdrant.tech/. Accessed: 2026-06-28
2026
-
[42]
Mark Raasveldt and Hannes Mühleisen. 2019. DuckDB: An Embeddable Analyti- cal Database. InProceedings of the 2019 International Conference on Management of Data. Association for Computing Machinery, Amsterdam, Netherlands, 1981– 1984
2019
-
[43]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: A Temporal Knowledge Graph Architecture for Agent Memory. arXiv:2501.13956
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Foundations and Trends in Information Retrieval3, 4 (2009), 333–389
2009
-
[45]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. InThe Twelfth International Conference on Learning Representations. OpenReview.net, Vienna, Austria
2024
-
[46]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, Kun Yu, Yuxing Yuan, Yinghao Zou, Jiquan Long, Yudong Cai, Zhenxiang Li, Zhifeng Zhang, Yihua Mo, Jun Gu, Ruiyi Jiang, Yi Wei, and Charles Xie. 2021. Milvus: A Purpose-Built Vector Data Management System. InSIGMOD ’21: Internatio...
2021
-
[47]
Noah Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Wenhao Huang, Jie Fu, and Junran Peng. 2024. RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models. InFindings of the Association for Com...
2024
-
[48]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu
-
[49]
InThe Thirteenth International Conference on Learning Representations
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. InThe Thirteenth International Conference on Learning Representations. OpenReview.net, Singapore
-
[50]
Yisha Wu, Cen Mia Zhao, Yuanpei Cao, Xiaoqing Xu, Yashar Mehdad, Mindy Ji, and Claire Na Cheng. 2025. Incremental Summarization for Customer Support via Progressive Note-Taking and Agent Feedback. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025 - Industry Track, Suzhou, China, November 4-9, 2025. Associ...
2025
-
[51]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient Streaming Language Models with Attention Sinks. InThe Twelfth In- ternational Conference on Learning Representations. OpenReview.net, Vienna, Austria
2024
-
[52]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang
-
[53]
InAdvances in Neural Informa- tion Processing Systems, Vol
A-MEM: Agentic Memory for LLM Agents. InAdvances in Neural Informa- tion Processing Systems, Vol. 38. Curran Associates, Inc., San Diego, CA, USA and Mexico City, Mexico
-
[54]
Hongkang Yang, Zehao Lin, Wenjin Wang, Hao Wu, Zhiyu Li, Bo Tang, Wenqiang Wei, Jinbo Wang, Zeyun Tang, Shichao Song, Chenyang Xi, Yu Yu, Kai Chen, Feiyu Xiong, Linpeng Tang, and Weinan E. 2024. Memory3: Language Modeling with Explicit Memory.Journal of Machine Learning3 (2024), 300–346
2024
-
[55]
N., Zeyuan Chen, Jianguo Zhang, Devansh Arpit, Ran Xu, Phil Mui, Huan Wang, Caiming Xiong, and Silvio Savarese
Weiran Yao, Shelby Heinecke, Juan Carlos Niebles, Zhiwei Liu, Yihao Feng, Le Xue, Rithesh R. N., Zeyuan Chen, Jianguo Zhang, Devansh Arpit, Ran Xu, Phil Mui, Huan Wang, Caiming Xiong, and Silvio Savarese. 2024. Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization. InThe Twelfth International Conference on Learning Representat...
2024
- [56]
-
[57]
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2025. A Survey on the Memory Mechanism of Large Language Model-based Agents.ACM Trans. Inf. Syst.43, 6 (2025), 155:1–155:47
2025
-
[58]
Xinyi Zhu, Haoyang Li, Yongqi Zhang, and Lei Chen. 2026. Skyline Retrieval meets Set-Cover Chunk Merging: A Cost-Effective RAG-Sketch for Long-Context LLM QA.Proc. ACM Manag. Data (SIGMOD)(2026). 10
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.