Audio-Mind: An Auditable Agentic Framework for Audio Understanding
Pith reviewed 2026-06-29 10:01 UTC · model grok-4.3
The pith
Audio understanding improves when agentic tool calls are used only if a strong frontend leaves evidence gaps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
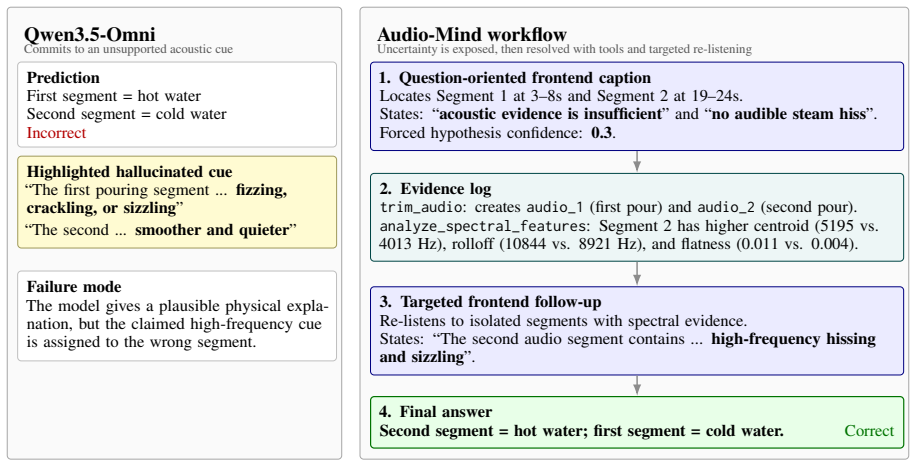
Core claim
Audio-Mind dynamically combines a strong frontend with planner-guided tool use, preserving frontend judgment when initial evidence is sufficient while acquiring bounded external evidence for questions with unresolved evidence gaps. Experiments on MMAR and MSU-Bench show that Audio-Mind outperforms prior audio-agent baselines, reaching 80.4% accuracy on MMAR and 82.8% accuracy on MSU-Bench. A matched-backbone comparison highlights why this design matters: under strong audio frontends, agentic decomposition can become an orchestration bottleneck when the workflow does not preserve the frontend's holistic audio-grounded judgment. Beyond accuracy, Audio-Mind produces higher-quality, auditable re
What carries the argument
The planner-guided conditional evidence acquisition that decides whether to preserve frontend output or invoke bounded external tools.
If this is right
- Accuracy on MMAR reaches 80.4 percent and on MSU-Bench reaches 82.8 percent, exceeding prior audio-agent baselines.
- Reasoning traces become auditable by exposing uncertainty, tool evidence, and answer rationales.
- Agentic decomposition becomes an orchestration bottleneck precisely when the workflow overrides a strong frontend's holistic judgment.
- The framework remains pluggable so that any strong audio frontend can be paired with the conditional planner.
Where Pith is reading between the lines
- The same conditional logic could be tested in vision or multimodal settings where frontends are already reliable on many inputs.
- Reducing unnecessary tool calls may lower latency and cost in deployed audio systems without sacrificing answer quality.
- The auditable traces could support systematic error analysis for improving future audio datasets or model training.
- If planners improve at gap detection, the fraction of questions routed to tools may shrink further over time.
Load-bearing premise
The planner can reliably detect when initial frontend evidence is insufficient and that acquiring bounded external evidence will close those gaps without introducing new errors.
What would settle it
An experiment in which the planner frequently judges evidence as sufficient when it is not, or in which the added tool calls lower accuracy below the frontend-alone baseline on the same questions.
Figures

read the original abstract
Audio agents extend large audio-language models (LALMs) by decomposing audio questions into tool calls, intermediate evidence, and iterative reasoning steps. However, as LALMs become stronger, the key challenge shifts from enabling tool use to determining when agentic evidence acquisition genuinely benefits audio understanding. We propose Audio-Mind, an auditable and pluggable framework for conditional evidence acquisition in audio understanding. Audio-Mind dynamically combines a strong frontend with planner-guided tool use, preserving frontend judgment when initial evidence is sufficient while acquiring bounded external evidence for questions with unresolved evidence gaps. Experiments on MMAR and MSU-Bench show that Audio-Mind outperforms prior audio-agent baselines, reaching 80.4% accuracy on MMAR and 82.8% accuracy on MSU-Bench. A matched-backbone comparison highlights why this design matters: under strong audio frontends, agentic decomposition can become an orchestration bottleneck when the workflow does not preserve the frontend's holistic audio-grounded judgment. Beyond accuracy, Audio-Mind produces higher-quality, auditable reasoning traces that expose uncertainty, tool evidence, and answer rationales, offering a potential basis for more reliable audio-QA annotation and error analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Audio-Mind, an auditable and pluggable agentic framework for audio understanding that dynamically combines a strong LALM frontend with planner-guided tool use. It preserves the frontend's holistic judgment when initial evidence suffices and acquires bounded external evidence only for unresolved gaps. The central claims are that this conditional design outperforms prior audio-agent baselines (80.4% accuracy on MMAR, 82.8% on MSU-Bench) and that agentic decomposition becomes an orchestration bottleneck under strong frontends; the framework also yields higher-quality auditable reasoning traces.
Significance. If the empirical claims hold with proper validation, the work addresses a timely transition in audio agents: as LALMs strengthen, the problem shifts from enabling tool use to deciding when it genuinely helps. The emphasis on auditable traces and conditional acquisition could support more reliable error analysis and annotation pipelines in audio QA.
major comments (3)
- [Abstract / Experiments] Abstract and experimental sections: the headline accuracies (80.4% MMAR, 82.8% MSU-Bench) and the matched-backbone comparison are presented without any description of the experimental protocol, dataset splits, statistical tests, number of runs, or ablation studies. This absence makes it impossible to assess whether the reported gains support the central claim of conditional evidence acquisition.
- [Abstract] Abstract: the planner's core decision rule for detecting when 'initial evidence is insufficient' and for ensuring that bounded tool evidence closes gaps without introducing new errors is invoked as the key mechanism but is given no implementation details, pseudocode, or evaluation (e.g., precision of insufficiency calls against oracle labels). This assumption is load-bearing for both the performance numbers and the bottleneck claim.
- [Abstract] Abstract: the statement that 'agentic decomposition can become an orchestration bottleneck when the workflow does not preserve the frontend's holistic audio-grounded judgment' rests on the matched-backbone comparison, yet no quantitative results, backbone details, or workflow variants from that comparison are supplied.
minor comments (1)
- [Abstract] The abstract uses the term 'LALM' without an initial expansion; a parenthetical definition on first use would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional transparency is needed to support the central claims. We address each point below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental sections: the headline accuracies (80.4% MMAR, 82.8% MSU-Bench) and the matched-backbone comparison are presented without any description of the experimental protocol, dataset splits, statistical tests, number of runs, or ablation studies. This absence makes it impossible to assess whether the reported gains support the central claim of conditional evidence acquisition.
Authors: We agree that the abstract omits these details. The full manuscript's Experiments section (Section 4) specifies the MMAR and MSU-Bench splits, reports means and standard deviations over three independent runs, and presents ablation studies on the conditional mechanism. To address the concern directly, we will expand the abstract with a concise statement of the protocol and run count, and ensure the experimental section explicitly notes any statistical tests applied. revision: yes
-
Referee: [Abstract] Abstract: the planner's core decision rule for detecting when 'initial evidence is insufficient' and for ensuring that bounded tool evidence closes gaps without introducing new errors is invoked as the key mechanism but is given no implementation details, pseudocode, or evaluation (e.g., precision of insufficiency calls against oracle labels). This assumption is load-bearing for both the performance numbers and the bottleneck claim.
Authors: Section 3.2 and Algorithm 1 of the manuscript provide the decision rule implementation and pseudocode. However, we did not report an explicit precision evaluation of the insufficiency detector against oracle labels. This is a substantive gap; we will add such an analysis in the revision, including precision/recall figures derived from our internal annotations of planner decisions. revision: partial
-
Referee: [Abstract] Abstract: the statement that 'agentic decomposition can become an orchestration bottleneck when the workflow does not preserve the frontend's holistic audio-grounded judgment' rests on the matched-backbone comparison, yet no quantitative results, backbone details, or workflow variants from that comparison are supplied.
Authors: The matched-backbone results, including specific backbone configurations and workflow variants, appear in Section 4.3 and Table 3. We will revise the abstract to include a brief quantitative summary of these findings so the bottleneck claim is directly supported at the abstract level. revision: yes
Circularity Check
No circularity: empirical framework with benchmark results, no derivations or self-referential claims
full rationale
The paper proposes Audio-Mind as an auditable agentic framework that conditionally combines a strong frontend with planner-guided tool use, reporting empirical accuracies (80.4% on MMAR, 82.8% on MSU-Bench) without any equations, fitted parameters, predictions, or first-principles derivations. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear; the central claims rest on external benchmark comparisons rather than reducing to internal definitions or ansatzes. The planner's decision rule is presented as a design choice with an acknowledged assumption, but this does not constitute circularity in any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, and 1 others. 2025. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. https://doi.org/10.48550/arXiv.2303.00747 Whisperx: Time-accurate speech transcription of long-form audio . In Proceedings of Interspeech 2023
-
[3]
Herv \'e Bredin. 2023. pyannote.audio 2.1 speaker diarization pipeline: Principle, benchmark, and recipe. In Proceedings of Interspeech 2023
2023
-
[4]
Liyang Chen, Hongkai Chen, Yujun Cai, Sifan Li, Qingwen Ye, and Yiwei Wang. 2026. https://doi.org/10.48550/arXiv.2602.10439 Audiorouter: Data efficient audio understanding via rl based dual reasoning . arXiv preprint arXiv:2602.10439
-
[5]
Ching-Yu Chiu, Meinard M \"u ller, Matthew EP Davies, Alvin Wen-Yu Su, and Yi-Hsuan Yang. 2022. An analysis method for metric-level switching in beat tracking. IEEE Signal Processing Letters, 29:2153--2157
2022
-
[6]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. 2024. https://doi.org/10.48550/arXiv.2407.10759 Qwen2-audio technical report . arXiv preprint arXiv:2407.10759
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.10759 2024
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Wenqian Cui, Dianzhi Yu, Xiaoqi Jiao, Ziqiao Meng, Guangyan Zhang, Qichao Wang, Yiwen Guo, and Irwin King. 2024. https://doi.org/10.48550/arXiv.2410.03751 Recent advances in speech language models: A survey . arXiv preprint arXiv:2410.03751
-
[9]
Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, and 1 others. 2025. Kimi-audio technical report. arXiv preprint arXiv:2504.18425
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang-gil Lee, Chao-Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. 2025. https://doi.org/10.48550/arXiv.2507.08128 Audio flamingo 3: Advancing audio intelligence with fully open large audio language models . arXiv preprint arXiv:2507.08128
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.08128 2025
-
[11]
Google . 2025. https://modelcards.withgoogle.com/assets/documents/gemini-2-flash.pdf Gemini 2.0 flash model card
2025
-
[12]
Google DeepMind . 2026. https://deepmind.google/gemini Gemini 3
2026
-
[13]
Jiangyu Han, Petr P \'a lka, Marc Delcroix, Federico Landini, Johan Rohdin, Jan Cernock \'y , and Luk \'a s Burget. 2025. https://doi.org/10.48550/arXiv.2506.18623 Efficient and generalizable speaker diarization via structured pruning of self-supervised models . arXiv preprint arXiv:2506.18623
-
[14]
Ailin Huang, Boyong Wu, Bruce Wang, Chao Yan, Chen Hu, Chengli Feng, Fei Tian, Feiyu Shen, Jingbei Li, Mingrui Chen, and 1 others. 2025. Step-audio: Unified understanding and generation in intelligent speech interaction. arXiv preprint arXiv:2502.11946
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Junyan Jiang, Ke Chen, Wei Li, and Gus Xia. 2019. http://archives.ismir.net/ismir2019/paper/000078.pdf Large-vocabulary chord transcription via chord structure decomposition . In Proceedings of the 20th International Society for Music Information Retrieval Conference, pages 644--651, Delft, The Netherlands
2019
-
[17]
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. 2024. https://doi.org/10.48550/arXiv.2402.01831 Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities . arXiv preprint arXiv:2402.01831
-
[18]
Hendrik Vincent Koops, W Bas de Haas, Jeroen Bransen, and Anja Volk. 2017. Chord label personalization through deep learning of integrated harmonic interval-based representations. arXiv preprint arXiv:1706.09552
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Chun-Yi Kuan, Chih-Kai Yang, Wei-Ping Huang, Ke-Han Lu, and Hung-yi Lee. 2024. https://doi.org/10.48550/arXiv.2407.09886 Speech-copilot: Leveraging large language models for speech processing via task decomposition, modularization, and program generation . arXiv preprint arXiv:2407.09886
-
[20]
Sonal Kumar, S imon Sedl \'a c ek, Vaibhavi Lokegaonkar, Fernando L \'o pez, Wenyi Yu, Nishit Anand, Hyeonggon Ryu, Lichang Chen, Maxim Pli c ka, Miroslav Hlav \'a c ek, and 1 others. 2025. https://doi.org/10.48550/arXiv.2508.13992 MMAU-Pro : A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence . arXiv preprint a...
-
[21]
Kuan-Yi Lee, Tsung-En Lin, and Hung-Yi Lee. 2025. https://doi.org/10.48550/arXiv.2510.11454 Audio-maestro: Enhancing large audio-language models with tool-augmented reasoning . arXiv preprint arXiv:2510.11454
-
[22]
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi-Wen Chao, Ruiyang Xu, Wenxi Chen, Yuanzhe Chen, Zhuo Chen, Jian Cong, and 1 others. 2025. https://doi.org/10.48550/arXiv.2505.13032 MMAR : A challenging benchmark for deep reasoning in speech, audio, music, and their mix . arXiv preprint arXiv:2505.13032
-
[23]
Ziyang Ma, Ruiyang Xu, Yinghao Ma, Chao-Han Huck Yang, Bohan Li, Jaeyeon Kim, Jin Xu, Jinyu Li, Carlos Busso, Kai Yu, Eng Siong Chng, and Xie Chen. 2026. https://doi.org/10.48550/arXiv.2602.14224 The interspeech 2026 audio reasoning challenge: Evaluating reasoning process quality for audio reasoning models and agents . arXiv preprint arXiv:2602.14224
-
[24]
Brian McFee, Colin Raffel, Dawen Liang, Daniel PW Ellis, Matt McVicar, Eric Battenberg, Oriol Nieto, and 1 others. 2015. librosa: Audio and music signal analysis in python. SciPy, 2015(18-24):7
2015
-
[25]
Aivo Olev and Tanel Alum \"a e. 2026. https://doi.org/10.48550/arXiv.2603.17822 Multi-source evidence fusion for audio question answering . arXiv preprint arXiv:2603.17822
-
[26]
Puvvada, Jagadeesh Balam, and Boris Ginsburg
Taejin Park, Ivan Medennikov, Kunal Dhawan, Weiqing Wang, He Huang, Nithin Rao Koluguri, Krishna C. Puvvada, Jagadeesh Balam, and Boris Ginsburg. 2025. https://doi.org/10.48550/arXiv.2409.06656 Sortformer: A novel approach for permutation-resolved speaker supervision in speech-to-text systems . In Proceedings of the 42nd International Conference on Machin...
-
[27]
Jing Peng, Yucheng Wang, Bohan Li, Yiwei Guo, Hankun Wang, Yangui Fang, Yu Xi, Haoyu Li, Xu Li, Ke Zhang, Shuai Wang, and Kai Yu. 2024. https://doi.org/10.48550/arXiv.2410.18908 A survey on speech large language models for understanding . arXiv preprint arXiv:2410.18908
-
[28]
Alexis Plaquet and Herv \'e Bredin. 2023. Powerset multi-class cross entropy loss for neural speaker diarization. In Proceedings of Interspeech 2023
2023
-
[29]
Qwen Team . 2026. https://doi.org/10.48550/arXiv.2604.15804 Qwen3.5-omni technical report . arXiv preprint arXiv:2604.15804
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.15804 2026
-
[30]
Yan Rong, Chenxing Li, Dong Yu, and Li Liu. 2025. https://doi.org/10.48550/arXiv.2509.16971 Audiogenie-reasoner: A training-free multi-agent framework for coarse-to-fine audio deep reasoning . arXiv preprint arXiv:2509.16971
-
[31]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
S. Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. 2024. https://doi.org/10.48550/arXiv.2410.19168 MMAU : A massive multi-task audio understanding and reasoning benchmark . arXiv preprint arXiv:2410.19168
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.19168 2024
-
[32]
Hendrik Schreiber and Meinard M \"u ller. 2018. https://doi.org/10.5281/zenodo.1492353 A single-step approach to musical tempo estimation using a convolutional neural network . In Proceedings of the 19th International Society for Music Information Retrieval Conference, pages 98--105, Paris, France
-
[33]
Mingchen Shao, Hang Su, Wenjie Tian, Bingshen Mu, Zhennan Lin, Lichun Fan, Zhenbo Luo, Jian Luan, and Lei Xie. 2026. https://doi.org/10.48550/arXiv.2604.22245 Listening with time: Precise temporal awareness for long-form audio understanding . arXiv preprint arXiv:2604.22245
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.22245 2026
-
[34]
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. 2026. https://doi.org/10.48550/arXiv.2601.21337 Qwen3-asr technical report . arXiv preprint arXiv:2601.21337
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.21337 2026
-
[35]
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun MA, and Chao Zhang. 2023. https://doi.org/10.48550/arXiv.2310.13289 SALMONN : Towards generic hearing abilities for large language models . arXiv preprint arXiv:2310.13289
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.13289 2023
-
[36]
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Yuxin Li, Daijiao Liu, Yayue Deng, Donghang Wu, Jun Chen, Liang Zhao, Chengyuan Yao, Hexin Liu, Eng Siong Chng, Xuerui Yang, Xiangyu Zhang, Daxin Jiang, and Gang Yu. 2025. https://doi.org/10.48550/arXiv.2511.15848 Step-audio-r1 technical report . arXiv preprint arXiv:2511.15848
-
[37]
Suramya Tomar. 2006. Converting video formats with ffmpeg. Linux journal, 2006(146):10
2006
-
[38]
Siqian Tong, Xuan Li, Yiwei Wang, Baolong Bi, Yujun Cai, Shenghua Liu, Yuchen He, and Chengpeng Hao. 2026. https://doi.org/10.48550/arXiv.2602.13685 Autagent: A reinforcement learning framework for tool-augmented audio reasoning . arXiv preprint arXiv:2602.13685
-
[39]
Zhen Wan, Chao-Han Huck Yang, Jinchuan Tian, Hanrong Ye, Ankita Pasad, Szu-wei Fu, Arushi Goel, Ryo Hachiuma, Shizhe Diao, Kunal Dhawan, Sreyan Ghosh, Yusuke Hirota, Zhehuai Chen, Rafael Valle, Ehsan Hosseini Asl, Chenhui Chu, Shinji Watanabe, Yu-Chiang Frank Wang, and Boris Ginsburg. 2026. https://doi.org/10.48550/arXiv.2601.09413 Speech-hands: A self-re...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.09413 2026
-
[40]
Hongji Wang, Chengdong Liang, Shuai Wang, Zhengyang Chen, Binbin Zhang, Xu Xiang, Yanlei Deng, and Yanmin Qian. 2023. https://doi.org/10.48550/arXiv.2210.17016 Wespeaker: A research and production oriented speaker embedding learning toolkit . In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing
-
[41]
Shuai Wang, Zhaokai Sun, Zhennan Lin, Chengyou Wang, Zhou Pan, and Lei Xie. 2025. https://doi.org/10.48550/arXiv.2508.08155 MSU-Bench : Towards understanding the conversational multi-talker scenarios . arXiv preprint arXiv:2508.08155
-
[42]
Gijs Wijngaard, Elia Formisano, Michel Dumontier, and Jenia Jitsev. 2025. https://doi.org/10.48550/arXiv.2510.02995 Audiotoolagent: An agentic framework for audio-language models . arXiv preprint arXiv:2510.02995
-
[43]
Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian, Feiyu Shen, Gang Yu, Haoyang Zhang, Jingbei Li, and 1 others. 2025. Step-audio 2 technical report. arXiv preprint arXiv:2507.16632
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Zhen Xiong, Yujun Cai, Zhecheng Li, Junsong Yuan, and Yiwei Wang. 2025. https://doi.org/10.48550/arXiv.2509.21749 Thinking with sound: Audio chain-of-thought enables multimodal reasoning in large audio-language models . arXiv preprint arXiv:2509.21749
-
[45]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, and 1 others. 2025 a . Qwen3-omni technical report. arXiv preprint arXiv:2509.17765
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Kai-Tuo Xu, Feng-Long Xie, Xu Tang, and Yao Hu. 2025 b . https://doi.org/10.48550/arXiv.2501.14350 Fireredasr: Open-source industrial-grade mandarin speech recognition models from encoder-decoder to llm integration . arXiv preprint arXiv:2501.14350
-
[47]
Kaituo Xu, Yan Jia, Kai Huang, Junjie Chen, Wenpeng Li, Kun Liu, Feng-Long Xie, Xu Tang, and Yao Hu. 2026. https://doi.org/10.48550/arXiv.2603.10420 Fireredasr2s: A state-of-the-art industrial-grade all-in-one automatic speech recognition system . arXiv preprint arXiv:2603.10420
-
[48]
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, Xiaohuan Zhou, Yichong Leng, Yuanjun Lv, Zhou Zhao, Chang Zhou, and Jingren Zhou. 2024. https://doi.org/10.48550/arXiv.2402.07729 AIR-Bench : Benchmarking large audio-language models via generative comprehension . arXiv preprint arXiv:2402.07729
-
[49]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. https://doi.org/10.48550/arXiv.2210.03629 ReAct : Synergizing reasoning and acting in language models . arXiv preprint arXiv:2210.03629
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.03629 2022
- [50]
-
[51]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[52]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.