Trajectory-Level Redirection Attacks on Vision-Language-Action Models
Pith reviewed 2026-06-27 06:31 UTC · model grok-4.3
The pith
Near-benign prompt perturbations can redirect VLA rollouts to attacker-specified targets under a prompt-only threat model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
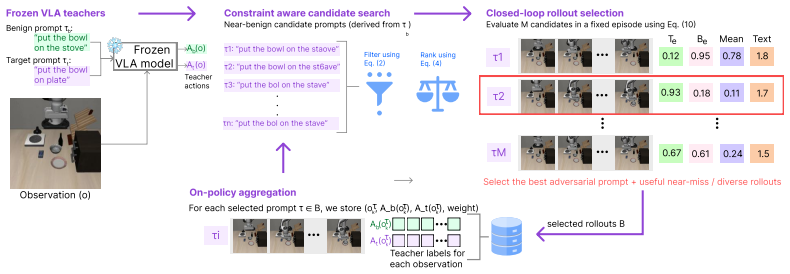
A single attacker-chosen prompt, fixed before the episode, can make a VLA policy's closed-loop behavior track an attacker-specified target task while satisfying the constraints of command-preserving trajectory redirection: the prompt stays near the benign instruction, omits target words and correction language, and all other policy and environment components remain unchanged. The prompt is found by an on-policy search that uses rollouts to identify perturbations whose executed trajectories match the target.
What carries the argument
Command-preserving trajectory redirection, a prompt-only threat model in which one fixed prompt redirects the full trajectory to a new target while staying close to the original instruction and omitting target words or corrections, located via on-policy prompt search that evaluates candidates through actual rollouts.
If this is right
- Prompt perturbations achieve redirection to attacker-specified targets while obeying the closeness and omission constraints.
- The on-policy rollout search locates perturbations whose closed-loop trajectories track the chosen target task.
- The redirection occurs in both simulated and physical hardware settings.
- Text that appears to preserve the intended command can still give control over the robot's final physical outcome.
Where Pith is reading between the lines
- Safety checks for VLA systems may need to evaluate candidate prompts by simulating their potential full trajectories rather than inspecting text alone.
- The same redirection risk could appear in other closed-loop language-controlled processes where instructions are reused across steps.
- Applying the search across wider task distributions would reveal whether the redirection capability scales or breaks on more complex behaviors.
Load-bearing premise
The assumption that an on-policy prompt search using rollouts can reliably discover perturbations that satisfy the command-preserving constraints while achieving the target trajectory without the search itself introducing artifacts that would not appear in a real deployment.
What would settle it
Execute the prompts discovered by the search method inside an actual deployed VLA system that never ran the search procedure, and check whether the redirection to the attacker target still occurs or whether no qualifying near-benign prompts exist for the tested tasks.
Figures







read the original abstract
Vision-language-action (VLA) policies bring natural language into closed-loop robot control, enabling robots to execute manipulation tasks directly from text instructions. The same interface gives text a recurring role in control because the prompt is reused at every replanning step, and each prompt-conditioned action changes the future observations on which the policy acts. Existing VLA attacks study adversarial prompts that elicit targeted low-level actions or make such actions persist across changing images. We identify a stronger trajectory-level failure mode: a prompt that still $\textit{appears}$ to specify the intended task but redirects the final physical outcome. We mathematically formalize this setting as $\textit{command-preserving trajectory redirection}$, a prompt-only threat model in which the attacker chooses one prompt before the episode, all policy and environment components remain fixed, and the prompt must stay close to the benign instruction while omitting target words and correction language. To find such prompts, we introduce an on-policy prompt search method that uses rollouts to discover perturbations whose closed-loop behavior tracks a target task while satisfying the command-preserving constraints. Experiments in simulation and on hardware show that near-benign prompt perturbations can redirect VLA rollouts to attacker-specified targets. These results expose a trajectory-level vulnerability in VLA instruction grounding: text that appears to preserve the intended command can still give an adversary control over the robot's final physical outcome. Project website: https://vla-redirection-attack.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that near-benign prompt perturbations, found via an on-policy search over rollouts, can redirect closed-loop VLA trajectories to attacker-specified targets while satisfying a command-preserving threat model (prompt chosen once before the episode, remains close to the benign instruction, omits target words and correction language, and all other components fixed). Simulation and hardware experiments are said to support the existence of such prompts.
Significance. If the central claim holds under the stated threat model, the result would identify a trajectory-level vulnerability in VLA instruction grounding that goes beyond existing low-level action attacks, with potential implications for the security of language-conditioned robot policies.
major comments (1)
- [Abstract (threat model and method description)] The threat model (stated in the abstract) requires the attacker to select one fixed prompt before the episode begins, with all policy and environment components remaining fixed thereafter. However, the on-policy prompt search method relies on repeated full rollouts to discover and optimize the perturbation while enforcing the command-preserving constraints inside the same loop. This procedure implicitly grants the attacker repeated execution access during discovery, which appears inconsistent with the one-shot pre-episode choice and raises the possibility that reported successes exploit transient state sequences or observation statistics induced by the search itself rather than generalizing to a single fixed prompt chosen without further interaction.
minor comments (1)
- [Abstract] The abstract states that simulation and hardware experiments support the claim but provides no quantitative results, success rates, number of trials, or details on how redirection success and command preservation were measured.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a potential ambiguity between the threat model and the prompt discovery procedure. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (threat model and method description)] The threat model (stated in the abstract) requires the attacker to select one fixed prompt before the episode begins, with all policy and environment components remaining fixed thereafter. However, the on-policy prompt search method relies on repeated full rollouts to discover and optimize the perturbation while enforcing the command-preserving constraints inside the same loop. This procedure implicitly grants the attacker repeated execution access during discovery, which appears inconsistent with the one-shot pre-episode choice and raises the possibility that reported successes exploit transient state sequences or observation statistics induced by the search itself rather than generalizing to a single fixed prompt chosen without further interaction.
Authors: We agree that the distinction between prompt discovery and deployment requires clearer separation to avoid ambiguity. The on-policy search is an offline optimization performed by the attacker (typically in simulation or with white-box access to the policy) to identify a prompt satisfying the command-preserving constraints; once identified, that single prompt is fixed and used for the entire episode with no further interaction or adaptation. The reported results evaluate the fixed prompt on independent rollouts (including hardware transfers), not on the search trajectories themselves. We will revise the abstract, threat model section, and method description to explicitly delineate the discovery phase (offline, attacker-controlled) from the attack phase (one-shot, fixed prompt, no repeated access), and we will add explicit statements that success is measured on held-out episodes after search termination. revision: partial
Circularity Check
No circularity detected in empirical attack paper
full rationale
The paper is an empirical demonstration of a prompt-only attack on VLA policies. It formalizes a threat model and introduces an on-policy search procedure whose success is shown via simulation and hardware experiments. No equations, fitted parameters, or derivations are presented that reduce a claimed result to its own inputs by construction. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear in the provided text. The central claim rests on experimental outcomes rather than any self-referential reduction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLA policies condition actions on the same text prompt at every replanning step
invented entities (1)
-
command-preserving trajectory redirection threat model
no independent evidence
Reference graph
Works this paper leans on
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[3]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[4]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.pi 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[5]
E. K. Jones, A. Robey, A. Zou, Z. Ravichandran, G. J. Pappas, H. Hassani, M. Fredrikson, and J. Z. Kolter. Adversarial attacks on robotic vision language action models.arXiv preprint arXiv:2506.03350, 2025
arXiv 2025
-
[6]
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson. Universal and transfer- able adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023
Pith/arXiv arXiv 2023
-
[8]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011
2011
-
[9]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[10]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[11]
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
Pith/arXiv arXiv 2023
-
[12]
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, et al. Molmoact: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025. 9
Pith/arXiv arXiv 2025
-
[13]
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. FAST: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
Pith/arXiv arXiv 2025
-
[14]
Y . Wang, H. Zhu, M. Liu, J. Yang, H.-S. Fang, and T. He. VQ-VLA: Improving vision- language-action models via scaling vector-quantized action tokenizers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[15]
Bousmalis, G
K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauza, T. Davchev, Y . Zhou, A. Gupta, et al. RoboCat: A self-improving generalist agent for robotic manipulation.Trans- actions on Machine Learning Research (TMLR), 2023
2023
-
[16]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[17]
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, J. Luo, Y . L. Tan, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[18]
Physical Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[19]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. RDT-1B: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
Pith/arXiv arXiv 2024
-
[20]
Y . Li, Y . Deng, J. Zhang, J. Jang, M. Memmel, C. Garrett, F. Ramos, D. Fox, A. Li, A. Gupta, et al. Hamster: Hierarchical action models for open-world robot manipulation. InInternational Conference on Learning Representations, volume 2025, pages 24040–24068, 2025
2025
-
[21]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
Pith/arXiv arXiv 2025
-
[22]
Y . Ji, H. Tan, J. Shi, X. Hao, Y . Zhang, H. Zhang, P. Wang, M. Zhao, Y . Mu, P. An, et al. Robobrain: A unified brain model for robotic manipulation from abstract to concrete. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1724–1734, 2025
2025
-
[23]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
- [24]
-
[25]
J. Wen, Y . Zhu, J. Li, M. Zhu, Z. Tang, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation. IEEE Robotics and Automation Letters, 2025
2025
- [26]
-
[27]
D. Niu, Y . Sharma, G. Biamby, J. Quenum, Y . Bai, B. Shi, T. Darrell, and R. Herzig. Llarva: Vision-action instruction tuning enhances robot learning.arXiv preprint arXiv:2406.11815, 2024. 10
arXiv 2024
-
[28]
Jia and P
R. Jia and P. Liang. Adversarial examples for evaluating reading comprehension systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2021–2031, Sept. 2017
2017
-
[29]
Ebrahimi, A
J. Ebrahimi, A. Rao, D. Lowd, and D. Dou. HotFlip: White-box adversarial examples for text classification. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 31–36, 2018
2018
-
[30]
J. Gao, J. Lanchantin, M. L. Soffa, and Y . Qi. Black-box generation of adversarial text se- quences to evade deep learning classifiers. In2018 IEEE security and privacy workshops (SPW), pages 50–56. IEEE, 2018
2018
-
[31]
J. Li, S. Ji, T. Du, B. Li, and T. Wang. Textbugger: Generating adversarial text against real- world applications.arXiv preprint arXiv:1812.05271, 2018
Pith/arXiv arXiv 2018
-
[32]
S. Ren, Y . Deng, K. He, and W. Che. Generating natural language adversarial examples through probability weighted word saliency. InProceedings of the 57th Annual Meeting of the Associ- ation for Computational Linguistics, pages 1085–1097, July 2019
2019
-
[33]
Alzantot, Y
M. Alzantot, Y . Sharma, A. Elgohary, B.-J. Ho, M. Srivastava, and K.-W. Chang. Generating natural language adversarial examples. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2890–2896, 2018
2018
-
[34]
D. Jin, Z. Jin, J. T. Zhou, and P. Szolovits. Is bert really robust? a strong baseline for natural language attack on text classification and entailment, 2020. URLhttps://arxiv.org/abs/ 1907.11932
arXiv 2020
-
[35]
L. Li, R. Ma, Q. Guo, X. Xue, and X. Qiu. BERT-ATTACK: Adversarial attack against BERT using BERT. InProceedings of the 2020 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP), pages 6193–6202, Nov. 2020
2020
-
[36]
D. Li, Y . Zhang, H. Peng, L. Chen, C. Brockett, M.-T. Sun, and B. Dolan. Contextualized perturbation for textual adversarial attack. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, pages 5053–5069, June 2021
2021
-
[37]
Garg and G
S. Garg and G. Ramakrishnan. BAE: BERT-based adversarial examples for text classification. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Process- ing (EMNLP), pages 6174–6181, Nov. 2020. URLhttps://aclanthology.org/2020. emnlp-main.498/
2020
-
[38]
N. Boucher, I. Shumailov, R. Anderson, and N. Papernot. Bad characters: Imperceptible nlp attacks, 2021. URLhttps://arxiv.org/abs/2106.09898
arXiv 2021
-
[39]
Wallace, S
E. Wallace, S. Feng, N. Kandpal, M. Gardner, and S. Singh. Universal adversarial triggers for attacking and analyzing NLP. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2153–2162, Nov. 2019
2019
-
[40]
T. Shin, Y . Razeghi, R. L. L. IV , E. Wallace, and S. Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts, 2020. URLhttps://arxiv. org/abs/2010.15980
arXiv 2020
-
[41]
Schwinn, D
L. Schwinn, D. Dobre, S. Xhonneux, G. Gidel, and S. G ¨unnemann. Soft prompt threats: Attacking safety alignment and unlearning in open-source llms through the embedding space. Advances in Neural Information Processing Systems, 37:9086–9116, 2024
2024
-
[42]
X. Liu, N. Xu, M. Chen, and C. Xiao. Autodan: Generating stealthy jailbreak prompts on aligned large language models, 2024. URLhttps://arxiv.org/abs/2310.04451. 11
Pith/arXiv arXiv 2024
-
[43]
K. Zhu, J. Wang, J. Zhou, Z. Wang, H. Chen, Y . Wang, L. Yang, W. Ye, Y . Zhang, N. Z. Gong, and X. Xie. Promptrobust: Towards evaluating the robustness of large language models on adversarial prompts, 2024. URLhttps://arxiv.org/abs/2306.04528
arXiv 2024
-
[45]
H. Lu, Y . Yu, Y . Yang, C. Yi, Q. Zhang, B. Shen, A. C. Kot, and X. Jiang. When robots obey the patch: Universal transferable patch attacks on vision-language-action models, 2026. URL https://arxiv.org/abs/2511.21192
arXiv 2026
-
[46]
T. Wang, C. Han, J. C. Liang, W. Yang, D. Liu, L. X. Zhang, Q. Wang, J. Luo, and R. Tang. Exploring the adversarial vulnerabilities of vision-language-action models in robotics, 2025. URLhttps://arxiv.org/abs/2411.13587
arXiv 2025
-
[47]
X. Wang, J. Li, Z. Weng, Y . Wang, Y . Gao, T. Pang, C. Du, Y . Teng, Y . Wang, Z. Wu, X. Ma, and Y .-G. Jiang. Freezevla: Action-freezing attacks against vision-language-action models,
-
[48]
URLhttps://arxiv.org/abs/2509.19870
- [49]
-
[50]
Y . Yan, Y . Xie, Y . Zhang, L. Lyu, H. Wang, and Y . Jin. When alignment fails: Multimodal ad- versarial attacks on vision-language-action models, 2025. URLhttps://arxiv.org/abs/ 2511.16203
arXiv 2025
-
[51]
Q. Li, B. Yin, W. Huang, R. Liu, B. Zou, R. Yu, J. Ye, W. Yu, and X. Wang. Vision- language-action safety: Threats, challenges, evaluations, and mechanisms, 2026. URL https://arxiv.org/abs/2604.23775
Pith/arXiv arXiv 2026
-
[52]
Ebrahimi, A
J. Ebrahimi, A. Rao, D. Lowd, and D. Dou. Hotflip: White-box adversarial examples for text classification. InProceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), 2018
2018
-
[53]
J. Gao, J. Lanchantin, M. L. Soffa, and Y . Qi. Black-box generation of adversarial text se- quences to evade deep learning classifiers. InIEEE Security and Privacy Workshops (SPW), 2018
2018
-
[54]
Wallace, S
E. Wallace, S. Feng, N. Kandpal, M. Gardner, and S. Singh. Universal adversarial triggers for attacking and analyzing nlp. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019
2019
-
[55]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
- [56]
-
[57]
NVIDIA, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 12 Appendix Contents A Experimental Details and Evaluation Protocol 14 A.1 LIBERO Setup and Model Inference Details . . . . . . . . . . . . . . . ...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.