AutoMem: Automated Learning of Memory as a Cognitive Skill
Pith reviewed 2026-07-02 12:07 UTC · model grok-4.3
The pith
Treating memory management as a trainable skill lets LLMs double or quadruple performance on long tasks by optimizing memory alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
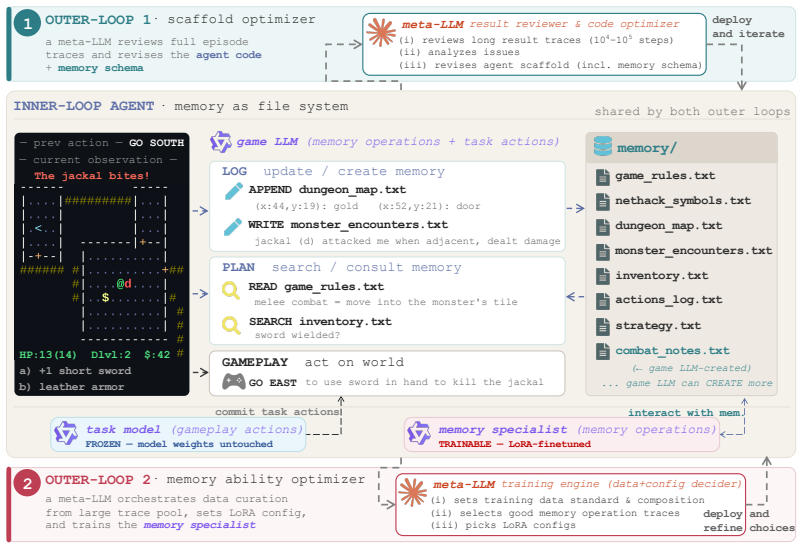
Memory management is an independently learnable skill. By elevating file-system operations to first-class actions and using two automated loops—one that iteratively revises memory structure from complete trajectories and one that extracts training signal from the agent's own successful memory decisions—the framework produces large performance lifts on long-horizon tasks without altering task-action behavior.
What carries the argument
AutoMem's two-loop process: the first loop uses a strong LLM to review full agent trajectories and revise memory file schemas and action vocabulary; the second loop identifies high-quality memory decisions across episodes and uses them as direct training data for the agent's memory proficiency.
If this is right
- Memory structure and memory proficiency can be improved independently of task policy.
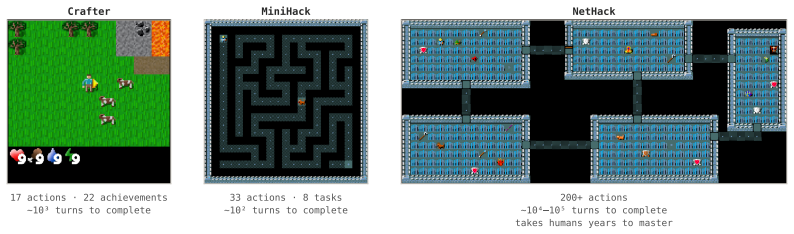
- A 32B model reaches parity with frontier systems on Crafter, MiniHack, and NetHack solely through memory optimization.
- Memory decisions become a high-leverage training target for any long-horizon agent.
- Human review of full trajectories is unnecessary once the strong LLM can perform the revision loop.
Where Pith is reading between the lines
- The separation of memory skill from task skill suggests memory modules could transfer across different environments with minimal retraining.
- The same automated loops might be applied to non-game domains such as tool-use agents or multi-step planning where memory errors also compound over long horizons.
- If memory proficiency scales with more training episodes, further gains could be obtained without increasing model size.
Load-bearing premise
A strong LLM can reliably review long agent trajectories to identify useful memory structures and good memory decisions despite the length and delayed feedback.
What would settle it
Training the memory skill on the three games and then testing the resulting agent on a fourth, held-out long-horizon procedural task shows no improvement over the base model that never learned memory actions.
Figures




read the original abstract
Memory expertise is a learned skill: knowing what to encode, when to retrieve, and how to organize knowledge--a capacity known in cognitive science as metamemory. We bring this perspective to LLMs by treating memory management as a trainable skill. We promote file-system operations to first-class memory actions alongside task actions, letting the model itself decide how to manage its memory. This memory skill improves along two axes: the structure that supports it (prompts, file schemas, action vocabulary), and the proficiency of the model exercising it. Both axes resist manual optimization: episodes in long-horizon tasks run for thousands of steps, and a single memory mistake can hide long before it surfaces, making human review of full trajectories impractical. We introduce AutoMem, a framework that automates both axes. In the first loop, a strong LLM reviews complete agent trajectories and iteratively revises the memory structure that shapes how the agent interacts with its memory files. In the second loop, the agent's own good memory decisions are identified from many episodes and used as training signal to sharpen the model's memory proficiency directly. Across three procedurally generated long-horizon games (Crafter, MiniHack, and NetHack), optimizing memory alone--without modifying the model's task-action behavior--improved the base agent's performance ~2x-4x, bringing a 32B open-weight model competitive with frontier systems such as Claude Opus 4.5 and Gemini 3.1 Pro Thinking. Our results show that memory management is an independently learnable skill, and a high-leverage objective yielding large gains on long-horizon tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that memory management can be treated as an independently trainable cognitive skill in LLM agents. AutoMem automates two axes of improvement via iterative loops: (1) a strong LLM reviews full trajectories to revise memory structures (prompts, file schemas, action vocabulary), and (2) good memory decisions extracted from episodes are used as training signal to improve the agent's memory proficiency. On Crafter, MiniHack, and NetHack, optimizing memory alone (task actions fixed) yields ~2x-4x gains, elevating a 32B open-weight model to parity with Claude Opus 4.5 and Gemini 3.1 Pro Thinking.
Significance. If the central empirical claim holds after validation, the result would be significant: it isolates memory management as a high-leverage, learnable component separate from task policy, with large gains on long-horizon tasks where human trajectory review is impractical. The automated loops provide a scalable alternative to manual design and directly test the metamemory hypothesis in agent settings.
major comments (2)
- [§3.2] §3.2 (second AutoMem loop): the training signal depends on a strong LLM labeling 'good memory decisions' from complete trajectories. No independent validation is reported (human agreement, label-noise ablation, or synthetic error-injection test) to confirm that labels isolate memory quality from task-action success in delayed-reward settings of thousands of steps; without this, the 2x-4x gains cannot be attributed to memory skill learning.
- [Results section] Results section and associated tables/figures: the reported ~2x-4x performance improvements lack reported details on number of runs, variance, statistical tests, or controls that hold task-action behavior strictly fixed while varying only memory actions; this information is load-bearing for the claim that memory optimization alone drives the gains.
minor comments (1)
- [§2] Notation for memory actions and file schemas could be formalized earlier (e.g., in §2) to improve readability of the two-loop description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2 (second AutoMem loop): the training signal depends on a strong LLM labeling 'good memory decisions' from complete trajectories. No independent validation is reported (human agreement, label-noise ablation, or synthetic error-injection test) to confirm that labels isolate memory quality from task-action success in delayed-reward settings of thousands of steps; without this, the 2x-4x gains cannot be attributed to memory skill learning.
Authors: We agree that the manuscript does not report independent validation of the LLM-generated labels (such as human agreement rates or noise ablations). The labeling process extracts memory decisions from trajectories that ultimately succeed, but this leaves open the possibility of confounding with task success in long-horizon settings. In the revised version we will add a dedicated label-quality subsection that includes (1) human agreement on a random sample of 200 labeled decisions and (2) a synthetic noise-injection experiment that perturbs a controlled fraction of memory labels and measures downstream performance degradation. revision: yes
-
Referee: [Results section] Results section and associated tables/figures: the reported ~2x-4x performance improvements lack reported details on number of runs, variance, statistical tests, or controls that hold task-action behavior strictly fixed while varying only memory actions; this information is load-bearing for the claim that memory optimization alone drives the gains.
Authors: The experimental design keeps task-action behavior fixed by (a) freezing the base model weights for all task actions and (b) applying memory-structure changes and memory-specific fine-tuning only. However, the current manuscript omits the requested statistical details. We will revise the Results section and all tables/figures to report: number of independent runs (five random seeds per environment), mean and standard deviation, and paired statistical significance tests (Wilcoxon signed-rank) between memory-optimized and baseline agents. We will also add an explicit paragraph describing the controls that isolate memory actions. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain consists of two automated loops (LLM-based structure revision from trajectories, followed by extraction of good memory decisions for supervised training) whose outputs are then evaluated on downstream task performance in Crafter, MiniHack, and NetHack. No equations, parameter-fitting steps, or self-citations are quoted that reduce the claimed performance gains or the 'independently learnable skill' conclusion to the inputs by construction. The identification of training signal is described at a high level without explicit overlap between selection criteria and evaluation metrics being shown, so the result remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rock- täschel. Promptbreeder: Self-referential self-improvement via prompt evolution.arXiv preprint arXiv:2309.16797,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Benchmarking the spectrum of agent capabilities.arXiv preprint arXiv:2109.06780,
Danijar Hafner. Benchmarking the spectrum of agent capabilities.arXiv preprint arXiv:2109.06780,
-
[3]
Automated Design of Agentic Systems
URL https://openreview.net/forum?id= nZeVKeeFYf9. Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems.arXiv preprint arXiv:2408.08435,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vard- hamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, et al. Dspy: Compiling declarative language model calls into self-improving pipelines.arXiv preprint arXiv:2310.03714,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
EvolveMem:Self-Evolving Memory Architecture via AutoResearch for LLM Agents
Jiaqi Liu, Xinyu Ye, Peng Xia, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. Evolve- mem: Self-evolving memory architecture via autoresearch for llm agents.arXiv preprint arXiv:2605.13941,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Memllm: Finetuning llms to use an explicit read-write memory.arXiv preprint arXiv:2404.11672,
Ali Modarressi, Abdullatif Köksal, Ayyoob Imani, Mohsen Fayyaz, and Hinrich Schütze. Memllm: Finetuning llms to use an explicit read-write memory.arXiv preprint arXiv:2404.11672,
-
[8]
MemGPT: Towards LLMs as Operating Systems
12 Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G Patil, Ion Stoica, and Joseph E Gonzalez. Memgpt: Towards llms as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2411.13543 (2024)
Davide Paglieri, Bartłomiej Cupiał, Samuel Coward, Ulyana Piterbarg, Maciej Wolczyk, Akbir Khan, Eduardo Pignatelli, Łukasz Kuci ´nski, Lerrel Pinto, Rob Fergus, et al. Balrog: Benchmarking agentic llm and vlm reasoning on games.arXiv preprint arXiv:2411.13543,
-
[10]
Ryan Wei Heng Quek, Sanghyuk Lee, Alfred Wei Lun Leong, Arun Verma, Alok Prakash, Nancy F Chen, Bryan Kian Hsiang Low, Daniela Rus, and Armando Solar-Lezama. Memo: Memory as a model.arXiv preprint arXiv:2605.15156,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Mikayel Samvelyan, Robert Kirk, Vitaly Kurin, Jack Parker-Holder, Minqi Jiang, Eric Hambro, Fabio Petroni, Heinrich Küttler, Edward Grefenstette, and Tim Rocktäschel. Minihack the planet: A sandbox for open-ended reinforcement learning research.arXiv preprint arXiv:2109.13202,
-
[12]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023a. Zihao Wang, Shaofei Cai, Guanzhou Chen, Anji Liu, Xiaojian Ma, and Yitao Liang. Describe, explain, plan and select: Interactive planning wit...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Haidong Xin, Xinze Li, Zhenghao Liu, Yukun Yan, Shuo Wang, Cheng Yang, Yu Gu, Ge Yu, and Maosong Sun. Metamem: Evolving meta-memory for knowledge utilization through self-reflective symbolic optimization.arXiv preprint arXiv:2602.11182,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z Pan, et al. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents.arXiv preprint arXiv:2601.01885,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
MemSearcher: Training LLMs to Reason, Search and Manage Memory via End-to-End Reinforcement Learning
Qianhao Yuan, Jie Lou, Zichao Li, Jiawei Chen, Yaojie Lu, Hongyu Lin, Le Sun, Debing Zhang, and Xianpei Han. Memsearcher: Training llms to reason, search and manage memory via end-to-end reinforcement learning.arXiv preprint arXiv:2511.02805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
MemEvolve: Meta-Evolution of Agent Memory Systems
Guibin Zhang, Haotian Ren, Chong Zhan, Zhenhong Zhou, Junhao Wang, He Zhu, Wangchunshu Zhou, and Shuicheng Yan. Memevolve: Meta-evolution of agent memory systems.arXiv preprint arXiv:2512.18746, 2025a. 13 Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evo...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
URL https://openreview.net/forum?id= 92gvk82DE-. Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents.arXiv preprint arXiv:2506.15841,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
gained +1 wood
A Implementation Details This appendix gives implementation configuration organized by components. The complete prompt templates for both outer loops, together with all code, are released in our codebase: https:// github.com/autoLearnMem/AutoMem. A.1 Game environment configuration BALROG environments.We use the BALROG harness as released [Paglieri et al.,...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.