Probing Collision Grounding in Vision-Language Models for Safe Human-Robot Collaboration
Pith reviewed 2026-06-28 23:15 UTC · model grok-4.3
The pith
Vision-language models cannot reliably detect robot collisions with humans or scenes in a new physics-based benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
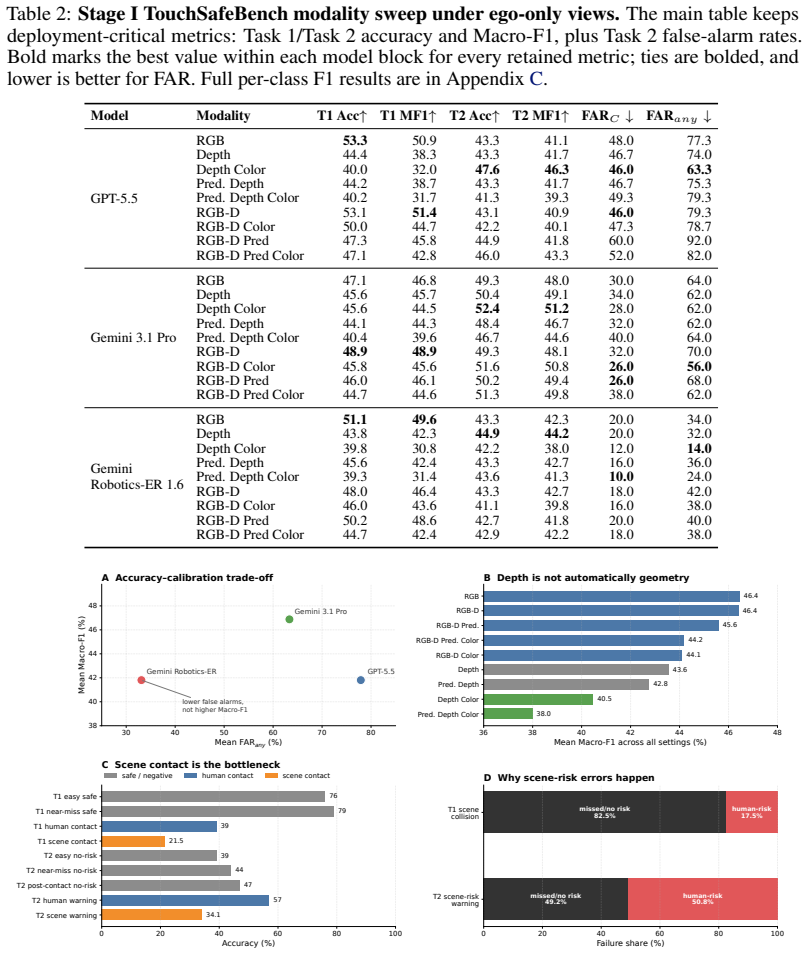
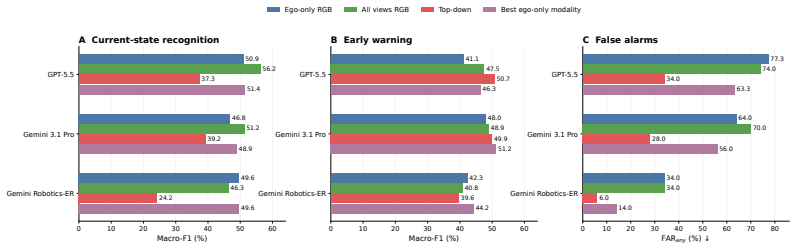
TouchSafeBench shows that current vision-language models achieve less than 50 percent average Macro-F1 on collision-grounding tasks, do not automatically convert explicit depth into robot-body collision evidence, and consistently perform worse on robot-scene contact than on human-contact risk, demonstrating that visual fluency does not imply physical accountability.
What carries the argument
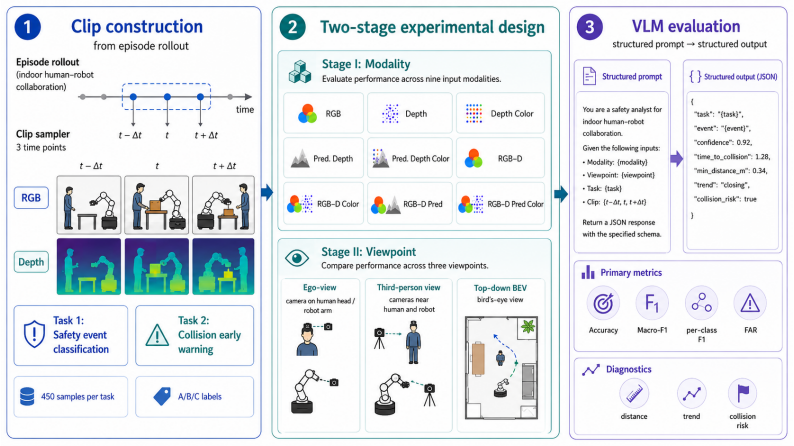
TouchSafeBench benchmark, which supplies synchronized multi-view RGB-D observations, top-down trajectory maps, camera metadata, and simulator-derived contact labels across social navigation and rearrangement episodes to test safety-state classification and imminent-collision warning.
If this is right
- Reliable robot safety monitors will require representations that explicitly bind viewpoint, robot morphology, metric geometry, and future collision.
- Visual description alone cannot determine whether a robot body is safely separated, colliding, or about to collide.
- Robot-scene contact detection remains harder than human-contact risk for existing models.
- Providing explicit depth does not automatically produce robot-body collision evidence.
- Deployment of vision-language models for human-robot safety needs new mechanisms beyond current visual fluency.
Where Pith is reading between the lines
- Similar benchmarks could expose comparable gaps in other embodied tasks that require metric spatial reasoning with moving agents.
- Combining vision-language models with separate geometric or physics modules might close the observed performance gap in simulation.
- Real-robot experiments using the same task definitions would test whether simulation-to-reality gaps change the reliability conclusion.
- The results imply that any application needing dynamic physical risk assessment from images will face the same accountability shortfall until representations improve.
Load-bearing premise
Physics-grounded simulations in Habitat 3.0 with derived contact labels accurately represent real-world collision grounding for human-robot collaboration.
What would settle it
Observation of any tested vision-language model reaching above 80 percent Macro-F1 on both safety-state classification and imminent-collision warning tasks in the released benchmark episodes.
Figures






read the original abstract
Safe human--robot collaboration requires more than visual description: a monitor must determine whether the robot body is safely separated, already colliding with the scene or a person, or about to collide. We call this capability collision grounding: binding visual observations to robot body geometry, camera viewpoint, scene layout, human proximity, and temporal motion in order to infer present and imminent contact. We introduce TouchSafeBench, a physics-grounded benchmark for evaluating collision grounding in vision-language models (VLMs). Built in Habitat~3.0, TouchSafeBench contains 2,940 simulated indoor co-presence episodes across social navigation and social rearrangement, with synchronized multi-view RGB-D observations, top-down trajectory maps, calibrated camera metadata, and simulator-derived contact labels. We study two deployment-facing tasks: classifying the current safety state and warning about imminent collision before contact. Across three frontier or robotics-oriented VLMs and nine visual representations, current models remain far from reliable: the best average Macro-F1 stays below 50\%, explicit depth is not automatically transformed into robot-body collision evidence, and robot--scene contact is consistently harder than human-contact risk. TouchSafeBench reveals a central limitation of embodied VLMs: visual fluency does not imply physical accountability. Reliable robot safety monitors will need representations that explicitly bind viewpoint, robot morphology, metric geometry, and future collision. We will release the benchmark upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TouchSafeBench, a physics-grounded benchmark built in Habitat 3.0 containing 2,940 simulated indoor episodes with synchronized multi-view RGB-D, top-down maps, and simulator-derived contact labels. It evaluates frontier and robotics-oriented VLMs on two tasks—classifying current safety state and warning of imminent collision—reporting that the best average Macro-F1 remains below 50%, explicit depth is not automatically used for robot-body evidence, and robot-scene contact is harder than human-contact risk. The central claim is that visual fluency in VLMs does not imply physical accountability for collision grounding and that reliable monitors require explicit binding of viewpoint, robot morphology, metric geometry, and future collision.
Significance. If the simulation results generalize, the work would be significant as an empirical demonstration of a gap between visual description and physical safety reasoning in embodied VLMs, supplying a reproducible benchmark that could drive development of models with explicit geometric and temporal binding for human-robot collaboration safety.
major comments (2)
- [Abstract] Abstract: The claim that TouchSafeBench results demonstrate unreliability of current VLMs for real human-robot collaboration safety monitors is load-bearing, yet the manuscript reports no real-robot episodes, sensor noise injection, or sim-to-real transfer experiments; the physics-grounded simulation with perfect-state labels therefore remains an untested proxy for the safety conclusions.
- [Abstract] Abstract and benchmark description: The reported Macro-F1 <50% and differential difficulty (robot-scene vs. human contact) are presented as evidence of missing representations, but without details on model prompts, exact visual representations tested, data splits, or error analysis in the provided text, the support for the unreliability claim cannot be fully verified.
minor comments (1)
- The manuscript states it will release the benchmark upon acceptance, but no link, license, or reproducibility checklist is provided in the current version.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our work. We address each major comment point by point below, with proposed revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that TouchSafeBench results demonstrate unreliability of current VLMs for real human-robot collaboration safety monitors is load-bearing, yet the manuscript reports no real-robot episodes, sensor noise injection, or sim-to-real transfer experiments; the physics-grounded simulation with perfect-state labels therefore remains an untested proxy for the safety conclusions.
Authors: We agree this is a substantive limitation for direct claims about real-world safety monitors. TouchSafeBench is intentionally a controlled simulation benchmark that supplies perfect contact labels to isolate VLM collision-grounding failures from sensor or calibration confounds. We will revise the abstract to state explicitly that the reported performance gaps are demonstrated in simulation and to list real-robot validation (including noise injection and sim-to-real transfer) as required future work. revision: yes
-
Referee: [Abstract] Abstract and benchmark description: The reported Macro-F1 <50% and differential difficulty (robot-scene vs. human contact) are presented as evidence of missing representations, but without details on model prompts, exact visual representations tested, data splits, or error analysis in the provided text, the support for the unreliability claim cannot be fully verified.
Authors: The full manuscript supplies these details: model prompts appear in Section 4.2, the nine visual representations (RGB, depth, top-down, and combinations) are defined in Section 3.3, episode splits are described in Section 3.1, and error analysis (per-class F1, robot-scene vs. human-contact breakdowns, and qualitative examples) is in Sections 5.2–5.3. We will add a concise summary of these elements to the abstract and benchmark description section, with explicit cross-references, to improve verifiability without lengthening the abstract. revision: yes
Circularity Check
Empirical benchmark study with no derivations or self-referential elements
full rationale
The paper introduces TouchSafeBench as a simulation-based benchmark and reports Macro-F1 scores from evaluating existing VLMs on classification and warning tasks. No equations, parameter fitting, predictions derived from inputs, or self-citations appear in the provided text. The central claims follow directly from the experimental results on the described episodes and labels, with no reduction of outputs to inputs by construction. This is a standard empirical evaluation paper whose conclusions rest on external model performance rather than internal definitional loops.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
B. Chen, Z. Xu, S. Kirmani, B. Ichter, D. Sadigh, L. Guibas, and F. Xia. SpatialVLM: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14455–14465, 2024
2024
-
[2]
J. Yang, S. Yang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10632– 10643, 2025
2025
- [3]
-
[4]
ISO 10218-1:2011 Robots and robotic devices – Safety requirements for industrial robots – Part 1: Robots, 2011
International Organization for Standardization. ISO 10218-1:2011 Robots and robotic devices – Safety requirements for industrial robots – Part 1: Robots, 2011. International Standard
2011
-
[5]
ISO/TS 15066:2016 Robots and robotic devices – Collaborative robots, 2016
International Organization for Standardization. ISO/TS 15066:2016 Robots and robotic devices – Collaborative robots, 2016. Technical Specification
2016
-
[6]
Sermanet, A
P. Sermanet, A. Majumdar, A. Irpan, D. Kalashnikov, and V . Sindhwani. Generating robot constitutions & benchmarks for semantic safety. InConference on Robot Learning, pages 4767–4823. PMLR, 2025
2025
- [7]
-
[8]
Sultani, C
W. Sultani, C. Chen, and M. Shah. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6479–6488, 2018
2018
-
[9]
Zanella, W
L. Zanella, W. Menapace, M. Mancini, Y . Wang, and E. Ricci. Harnessing large language models for training-free video anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18527–18536, 2024
2024
-
[10]
Y . Luo, C.-K. Fan, M. Dong, J. Shi, M. Zhao, B.-W. Zhang, C. Chi, J. Liu, G. Dai, R. Zhang, et al. RoboBench: A comprehensive evaluation benchmark for multimodal large language models as embodied brain.arXiv preprint arXiv:2510.17801, 2025
-
[11]
R. Yang, H. Chen, J. Zhang, M. Zhao, C. Qian, K. Wang, Q. Wang, T. V . Koripella, M. Movahedi, M. Li, et al. EmbodiedBench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. InInternational Conference on Machine Learning, pages 70576–70631. PMLR, 2025
2025
-
[12]
X. Puig, E. Undersander, A. Szot, M. Dallaire Cote, T.-Y . Yang, R. Partsey, R. Desai, A. Clegg, M. Hlavac, S. Y . Min, et al. Habitat 3.0: A co-habitat for humans, avatars, and robots. In International Conference on Learning Representations, volume 2024, pages 15306–15336, 2024
2024
-
[13]
AI2-THOR: An Interactive 3D Environment for Visual AI
E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, M. Deitke, K. Ehsani, D. Gordon, Y . Zhu, et al. AI2-THOR: An interactive 3D environment for visual AI.arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
C. Gan, J. Schwartz, S. Alter, M. Schrimpf, J. Traer, J. De Freitas, J. Kubilius, A. Bhandwaldar, N. Haber, M. Sano, et al. ThreeDWorld: A platform for interactive multi-modal physical simulation.Advances in Neural Information Processing Systems (NeurIPS), 2021. 9
2021
-
[15]
C. Li, F. Xia, R. Martín-Martín, M. Lingelbach, S. Srivastava, B. Shen, K. E. Vainio, C. Gokmen, G. Dharan, T. Jain, et al. iGibson 2.0: Object-centric simulation for robot learning of everyday household tasks. InConference on Robot Learning. PMLR, 2021
2021
-
[16]
X. Puig, K. Ra, M. Boben, J. Li, T. Wang, S. Fidler, and A. Torralba. VirtualHome: Simulating household activities via programs. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8494–8502, 2018
2018
- [17]
-
[18]
X. Lu, Z. Chen, X. Hu, Y . Zhou, W. Zhang, D. Liu, L. Sheng, and J. Shao. IS-Bench: Evaluating interactive safety of VLM-driven embodied agents in daily household tasks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 35680–35688, 2026
2026
- [19]
-
[20]
L. Zhang, J. Dong, K. Bai, M. Ni, Z.-C. Marton, Z. Chen, and J. Zhang. ResponsibleRobotBench: Benchmarking responsible robot manipulation using multi-modal large language models.arXiv preprint arXiv:2512.04308, 2025
- [21]
-
[22]
P. Wu, J. Liu, Y . Shi, Y . Sun, F. Shao, Z. Wu, and Z. Yang. Not only look, but also listen: Learning multimodal violence detection under weak supervision. InEuropean conference on computer vision, pages 322–339. Springer, 2020
2020
- [23]
-
[24]
X. Xu, Y . Cao, H. Zhang, N. Sang, and X. Huang. Customizing Visual-Language Foundation Models for Multi-Modal Anomaly Detection and Reasoning. In2025 28th International Conference on Computer Supported Cooperative Work in Design (CSCWD), pages 1443–1448. IEEE, 2025
2025
-
[25]
arXiv preprint arXiv:2406.12235 (2024)
H. Zhang, X. Xu, X. Wang, J. Zuo, C. Han, X. Huang, C. Gao, Y . Wang, and N. Sang. Holmes- V AD: Towards unbiased and explainable video anomaly detection via multi-modal LLM.arXiv preprint arXiv:2406.12235, 2024
-
[26]
Zhang, X
H. Zhang, X. Xu, X. Wang, J. Zuo, X. Huang, C. Gao, S. Zhang, L. Yu, and N. Sang. Holmes- V AU: Towards long-term video anomaly understanding at any granularity. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13843–13853, 2025
2025
-
[27]
M. Ye, W. Liu, and P. He. VERA: Explainable video anomaly detection via verbalized learning of vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8679–8688, 2025
2025
-
[28]
W. Li, Y . Gu, X. Chen, X. Xu, M. Hu, X. Huang, and Y . Wu. Towards visual discrimination and reasoning of real-world physical dynamics: Physics-grounded anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 30409–30419, 2025
2025
- [29]
-
[30]
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han. BEVFusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In2023 IEEE international conference on robotics and automation (ICRA), pages 2774–2781. IEEE, 2023
2023
-
[31]
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai. BEVFormer: learning bird’s-eye-view representation from LiDAR-Camera via spatiotemporal transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(3):2020–2036, 2025
2020
-
[32]
X. Xu, Y . Li, T. Zhang, J. Yang, M. Johnson-Roberson, and X. Huang. Unified self-supervised representation learning for multi-modal and single-modal 3D perception. In2025 IEEE 21st International Conference on Automation Science and Engineering (CASE), pages 2881–2888. IEEE, 2025
2025
-
[33]
Zhang, D
S. Zhang, D. Huang, J. Deng, S. Tang, W. Ouyang, T. He, and Y . Zhang. Agent3D-Zero: An agent for zero-shot 3D understanding. InEuropean Conference on Computer Vision, pages 186–202. Springer, 2024
2024
- [34]
-
[35]
C. Li, J. Wen, Y . Peng, Y . Peng, and Y . Zhu. PointVLA: Injecting the 3D world into vision- language-action models.IEEE Robotics and Automation Letters, 11(3):2506–2513, 2026
2026
-
[36]
G. R. Team, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, T. Armstrong, A. Balakr- ishna, R. Baruch, M. Bauza, M. Blokzijl, et al. Gemini robotics: Bringing AI into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
X. Wu, S. Chakraborty, R. Xian, J. Liang, T. Guan, F. Liu, B. M. Sadler, D. Manocha, and A. S. Bedi. On the vulnerability of LLM/VLM-controlled robotics. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1914–1921. IEEE, 2025
1914
-
[38]
GPT-5.5 system card
OpenAI. GPT-5.5 system card. Technical report, OpenAI, 2026. URL https://openai.com/ index/gpt-5-5-system-card/. Accessed: 2026-05-28
2026
-
[39]
Gemini 3.1 Pro model card
Google DeepMind. Gemini 3.1 Pro model card. Technical report, Google DeepMind, 2026. URL https://deepmind.google/models/model-cards/gemini-3-1-pro/ . Accessed: 2026-05-28
2026
-
[40]
Gemini Robotics-ER 1.6: Powering real-world robotics tasks through enhanced embodied reasoning
Google DeepMind. Gemini Robotics-ER 1.6: Powering real-world robotics tasks through enhanced embodied reasoning. Google DeepMind Blog, 2026. URL https://deepmind. google/blog/gemini-robotics-er-1-6/. Accessed: 2026-05-28
2026
-
[41]
Y . Liu, C. Zhang, R. Xing, B. Tang, B. Yang, and L. Yi. Core4D: A 4D human-object-human interaction dataset for collaborative object rearrangement. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1769–1782, 2025
2025
-
[42]
X. Xu, T. Zhang, S. Zhao, X. Li, S. Wang, Y . Chen, Y . Li, B. Raj, M. Johnson-Roberson, S. Scherer, et al. Scalable benchmarking and robust learning for noise-free ego-motion and 3D reconstruction from noisy video. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[43]
X. Li, K. Qiu, J. Wang, X. Xu, R. Singh, K. Yamazaki, H. Chen, X. Huang, and B. Raj. R2- Bench: Benchmarking the robustness of referring perception models under perturbations. In European Conference on Computer Vision, pages 211–230. Springer, 2024
2024
-
[44]
Guiochet, M
J. Guiochet, M. Machin, and H. Waeselynck. Safety-critical advanced robots: A survey.Robotics and Autonomous Systems, 94:43–52, 2017. 11
2017
-
[45]
Failure pattern A brick wall fills the entire arm camera at step 103 (scene flags all True), yet themodel dismisses this because
Y . Gu, X. Xu, and Y . Wu. Multi-Turn Physics-Informed Vision-Language Model for physics- grounded anomaly detection. InICASSP 2026-2026 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), pages 12752–12756. IEEE, 2026. 12 A Extended Discussion: What TouchSafeBench Reveals Collision grounding is a different problem from vi...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.