Beyond Agent Architecture: Execution Assumptions and Reproducibility in LLM-Based Trading Systems
Pith reviewed 2026-06-27 19:33 UTC · model grok-4.3
The pith
LLM trading papers report architectures more clearly than execution assumptions needed for reproducibility.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
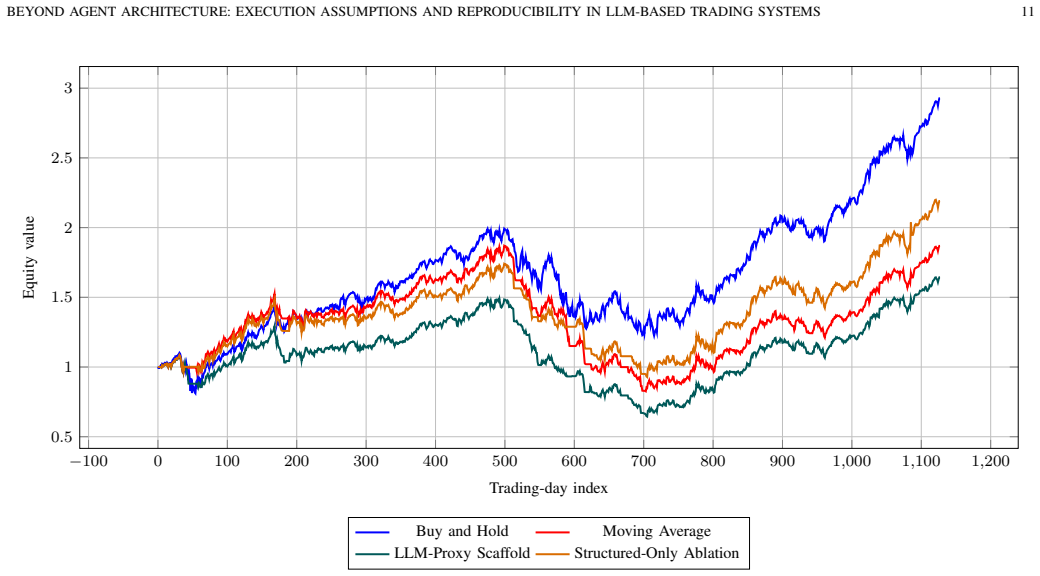
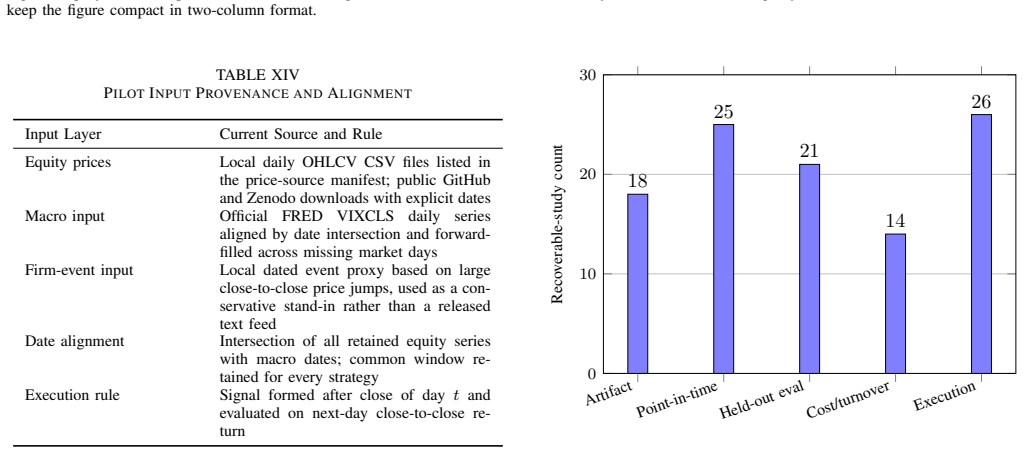
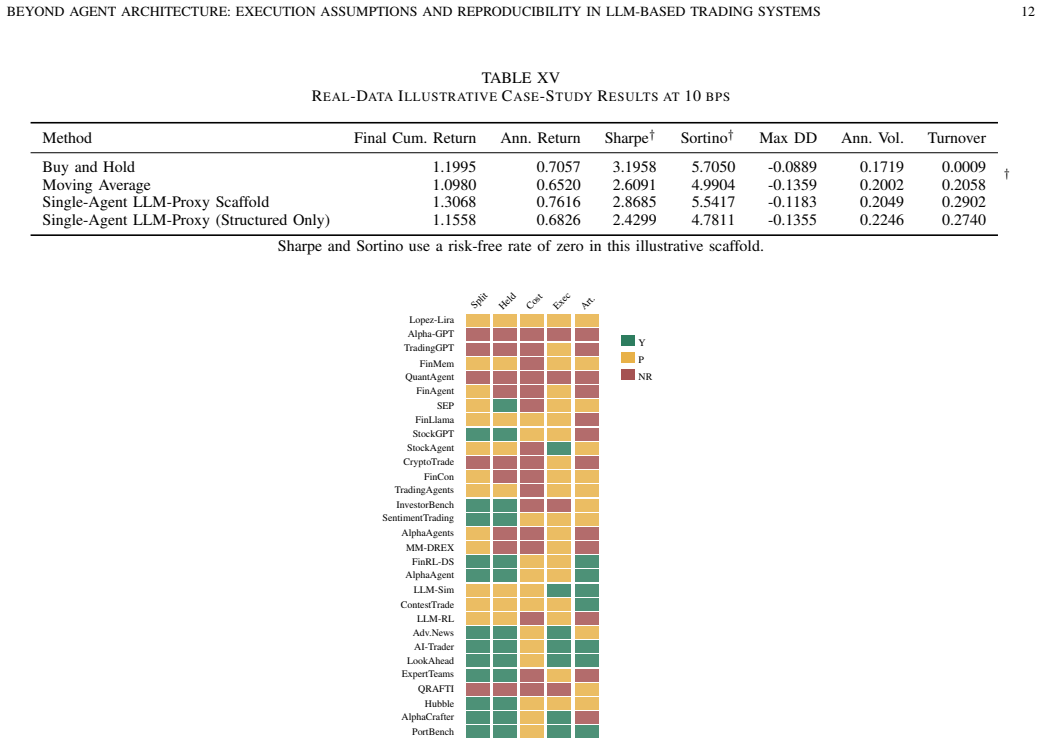
Across the audited sample, architecture reporting is generally clearer than the evaluation assumptions needed to judge whether a trading result is economically interpretable or reproducible. A coded evidence matrix covering 30 trade-relevant primary studies assesses point-in-time controls, split transparency, held-out evaluation, cost and turnover treatment, execution semantics, universe definition, and artifact release. The main conclusion is that the next useful step for LLM trading research is clearer reporting standards for execution realism, reproducibility, and evaluation comparability.
What carries the argument
A coded evidence matrix that systematically assesses point-in-time controls, split transparency, held-out evaluation, cost and turnover treatment, execution semantics, universe definition, and artifact release across the 30 studies.
If this is right
- Trading performance numbers cannot be compared across studies without consistent disclosure of execution timing and costs.
- Many published LLM trading results may shrink or disappear once realistic transaction costs and turnover are applied.
- Improvements in agent architecture alone will not resolve the field's comparability problems.
- Artifact release and universe definition details are frequently omitted, blocking exact replication.
- A methodological scaffold with explicit friction modeling can demonstrate material changes in strategy outcomes.
Where Pith is reading between the lines
- Adopting a minimal checklist for execution reporting could allow future meta-analyses to separate viable strategies from artifacts of optimistic assumptions.
- The same gaps in evaluation transparency likely appear in other LLM applications to finance and may require field-wide standards.
- Clearer execution reporting would make it easier to test whether LLM agents add value beyond simple momentum or mean-reversion rules.
Load-bearing premise
The selection of 30 primary studies and the coding criteria provide an unbiased and representative picture of the broader LLM trading literature.
What would settle it
An independent audit sampling a different collection of studies or applying altered coding criteria that finds evaluation assumptions reported at least as clearly as architectures.
Figures

read the original abstract
Large language models (LLMs) and agentic systems are increasingly proposed for financial trading, yet their reported performance remains difficult to compare because studies vary in data provenance, temporal split discipline, execution timing, turnover treatment, and transaction-cost modeling. This article presents a targeted topical review and reproducibility audit of execution realism in LLM-based trading research. A coded evidence matrix covering 30 trade-relevant primary studies is used to assess point-in-time controls, split transparency, held-out evaluation, cost and turnover treatment, execution semantics, universe definition, and artifact release. Across the audited sample, architecture reporting is generally clearer than the evaluation assumptions needed to judge whether a trading result is economically interpretable or reproducible. A 10-equity worked example is included only as a methodological scaffold to illustrate how explicit friction and timing choices can materially compress active-strategy results. The main conclusion is that the next useful step for LLM trading research is not only better agent design, but also clearer reporting standards for execution realism, reproducibility, and evaluation comparability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a targeted topical review and reproducibility audit of execution realism in LLM-based trading research. It codes an evidence matrix from 30 primary studies on point-in-time controls, split transparency, held-out evaluation, cost/turnover treatment, execution semantics, universe definition, and artifact release. The central finding is that architecture reporting is generally clearer than the evaluation assumptions required to assess economic interpretability or reproducibility. A 10-equity worked example is presented solely as a methodological scaffold to show how explicit friction and timing choices can compress active-strategy results. The conclusion calls for clearer reporting standards on execution realism rather than further focus on agent architecture alone.
Significance. If the audit accurately captures patterns in the sampled literature, the work usefully redirects attention in an emerging subfield from architectural novelty to foundational reproducibility and economic validity. The coded evidence matrix offers a reusable template for future audits, and the scaffold example concretely demonstrates the material impact of unstated assumptions. These elements provide practical value even if the sample's representativeness requires clarification.
major comments (1)
- [Methods / Audit Design] Methods / Audit Design (description of the 30-study sample): No search strategy, databases, date range, inclusion/exclusion criteria, or sampling justification is provided for the 'targeted topical review.' Because the central claim concerns a disparity observable 'across the audited sample' and is used to recommend field-wide changes in reporting standards, the absence of selection protocol details makes it impossible to judge whether the observed pattern is representative or an artifact of how the studies were chosen.
minor comments (2)
- [Abstract and Conclusion] The abstract and conclusion could more explicitly qualify the scope as applying to the audited sample rather than the entire LLM trading literature, to avoid overgeneralization while the selection protocol remains unspecified.
- [Worked Example] The 10-equity example is labeled a 'scaffold' and not a formal result, but its placement and level of detail could be clarified so readers do not mistake it for empirical evidence supporting the audit findings.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in our audit design. We agree that additional details on sample selection will strengthen the manuscript and will revise accordingly, while clarifying that the review is targeted rather than systematic.
read point-by-point responses
-
Referee: [Methods / Audit Design] Methods / Audit Design (description of the 30-study sample): No search strategy, databases, date range, inclusion/exclusion criteria, or sampling justification is provided for the 'targeted topical review.' Because the central claim concerns a disparity observable 'across the audited sample' and is used to recommend field-wide changes in reporting standards, the absence of selection protocol details makes it impossible to judge whether the observed pattern is representative or an artifact of how the studies were chosen.
Authors: We acknowledge the validity of this observation. The manuscript describes the work as a 'targeted topical review' of 30 trade-relevant primary studies but does not detail the identification process. To address this, we will add a new subsection under Methods that specifies: (1) keyword-based searches on arXiv, SSRN, and Google Scholar using terms such as 'LLM-based trading', 'LLM agent trading', and 'large language model trading system' from 2023 onward; (2) inclusion of papers that propose and evaluate an LLM or agentic trading strategy with reported performance metrics; (3) exclusion of purely theoretical or non-trading LLM papers; and (4) a convenience element limited to readily accessible English-language preprints and conference papers known in the subfield at the time of writing. We will also explicitly state that the sample is not intended to be exhaustive or statistically representative of the entire literature, but rather illustrative of patterns in published LLM trading work. This revision will allow readers to better evaluate the scope while preserving the paper's focus on execution assumptions rather than claiming broad generalizability. revision: yes
Circularity Check
No circularity: observational audit with no derivations or fitted predictions
full rationale
The paper is a targeted topical review and reproducibility audit of execution assumptions in 30 external LLM trading studies. It codes an evidence matrix on reporting practices and draws an observational conclusion that architecture reporting exceeds evaluation-assumption transparency in the sample. No mathematical derivations, first-principles results, parameter fitting, or predictions appear; the 10-equity example is explicitly labeled an illustration only. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing support. The central claim rests on the external audit rather than reducing to the paper's own inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard practices for literature coding and evidence synthesis apply to the construction of the 30-study matrix.
Reference graph
Works this paper leans on
-
[1]
Large language model agent in financial trading: A survey,
H. Ding, Y . Li, J. Wang, H. Chen, D. Guo, and Y . Zhang, “Large language model agent in financial trading: A survey,” arXiv preprint arXiv:2408.06361, 2024. [Online]. Available: https: //arxiv.org/abs/2408.06361
arXiv 2024
-
[2]
Y . Li, Y . Yu, H. Li, Z. Chen, and K. Khashanah, “TradingGPT: Multi- agent system with layered memory and distinct characters for enhanced financial trading performance,”arXiv preprint arXiv:2309.03736, 2023. [Online]. Available: https://arxiv.org/abs/2309.03736
arXiv 2023
-
[4]
Available: https://arxiv.org/abs/2407.18957
[Online]. Available: https://arxiv.org/abs/2407.18957
-
[6]
Available: https://arxiv.org/abs/2412.20138
[Online]. Available: https://arxiv.org/abs/2412.20138
-
[7]
FinMem: A performance- enhanced LLM trading agent with layered memory and character design,
Y . Yu, H. Li, Z. Chen, Y . Jiang, Y . Li, D. Zhang, R. Liu, J. W. Suchow, and K. Khashanah, “FinMem: A performance- enhanced LLM trading agent with layered memory and character design,”arXiv preprint arXiv:2311.13743, 2023. [Online]. Available: https://arxiv.org/abs/2311.13743
arXiv 2023
-
[8]
W. Zhang, L. Zhao, H. Xia, S. Sun, J. Sun, M. Qin, X. Li, Y . Zhao, Y . Zhao, X. Cai, L. Zheng, X. Wang, and B. An, “FinAgent: A multimodal foundation agent for financial trading: Tool-augmented, diversified, and generalist,”arXiv preprint arXiv:2402.18485, 2024. [Online]. Available: https://arxiv.org/abs/2402.18485
arXiv 2024
-
[9]
CryptoTrade: A reflective LLM-based agent to guide zero-shot cryptocurrency trading,
Y . Li, B. Luo, Q. Wang, N. Chen, X. Liu, and B. He, “CryptoTrade: A reflective LLM-based agent to guide zero-shot cryptocurrency trading,”arXiv preprint arXiv:2407.09546, 2024. [Online]. Available: https://arxiv.org/abs/2407.09546
arXiv 2024
-
[10]
Agentic trading: When LLM agents meet financial markets,
Y . Xia, P. You, T. Wang, F. Liu, H. Qi, X. Wu, and S. Zhang, “Agentic trading: When LLM agents meet financial markets,” arXiv preprint arXiv:2605.19337, 2026. [Online]. Available: https: //arxiv.org/abs/2605.19337
Pith/arXiv arXiv 2026
-
[11]
BloombergGPT: A large language model for finance,
S. Wu, O. Irsoy, S. Lu, V . Dabravolski, M. Dredze, S. Gehrmann, P. Kambadur, D. Rosenberg, and G. Mann, “BloombergGPT: A large language model for finance,”arXiv preprint arXiv:2303.17564, 2023. [Online]. Available: https://arxiv.org/abs/2303.17564
Pith/arXiv arXiv 2023
-
[12]
FinGPT: Open-source financial large language models,
H. Yang, X.-Y . Liu, and C. D. Wang, “FinGPT: Open-source financial large language models,”arXiv preprint arXiv:2306.06031, 2023. [Online]. Available: https://arxiv.org/abs/2306.06031
arXiv 2023
-
[13]
Large language models in finance: A survey,
Y . Li, S. Wang, H. Ding, and H. Chen, “Large language models in finance: A survey,”arXiv preprint arXiv:2311.10723, 2023. [Online]. Available: https://arxiv.org/abs/2311.10723
arXiv 2023
-
[14]
A survey of large language models in finance (FinLLMs),
J. Lee, N. Stevens, S. C. Han, and M. Song, “A survey of large language models in finance (FinLLMs),”arXiv preprint arXiv:2402.02315, 2024. [Online]. Available: https://arxiv.org/abs/2402.02315
arXiv 2024
-
[15]
FinanceBench: A new benchmark for financial question answering,
P. Islam, A. Kannappan, D. Kiela, R. Qian, N. Scherrer, and B. Vidgen, “FinanceBench: A new benchmark for financial question answering,”arXiv preprint arXiv:2311.11944, 2023. [Online]. Available: https://arxiv.org/abs/2311.11944
Pith/arXiv arXiv 2023
-
[16]
FinBen: A holistic financial benchmark for large language models,
Q. Xie, W. Han, Z. Chen, R. Xiang, X. Zhang, Y . He, M. Xiao, D. Li, Y . Dai, D. Feng, Y . Xu, H. Kang, Z. Kuang, C. Yuan, K. Yang, Z. Luo, T. Zhang, Z. Liu, G. Xiong, Z. Deng, Y . Jiang, Z. Yao, H. Li, Y . Yu, G. Hu, J. Huang, X.-Y . Liu, A. Lopez- Lira, B. Wang, Y . Lai, H. Wang, M. Peng, S. Ananiadou, and J. Huang, “FinBen: A holistic financial benchma...
arXiv 2024
-
[17]
FinRobot: An open-source AI agent platform for financial applications using large language models,
H. Yang, B. Zhang, N. Wang, C. Guo, X. Zhang, L. Lin, J. Wang, T. Zhou, M. Guan, R. Zhang, and C. D. Wang, “FinRobot: An open-source AI agent platform for financial applications using large language models,”arXiv preprint arXiv:2405.14767, 2024. [Online]. Available: https://arxiv.org/abs/2405.14767
arXiv 2024
-
[18]
Can ChatGPT forecast stock price movements? return predictability and large language models,
A. Lopez-Lira and Y . Tang, “Can ChatGPT forecast stock price movements? return predictability and large language models,”arXiv preprint arXiv:2304.07619, 2023. [Online]. Available: https://arxiv.org/ abs/2304.07619
arXiv 2023
-
[19]
Sentiment trading with large language models,
K. Kirtac and G. Germano, “Sentiment trading with large language models,”arXiv preprint arXiv:2412.19245, 2024. [Online]. Available: https://arxiv.org/abs/2412.19245
arXiv 2024
-
[20]
AlphaAgents: Large language model based multi-agents for equity portfolio constructions,
T. Zhao, J. Lyu, S. Jones, H. Garber, S. Pasquali, and D. Mehta, “AlphaAgents: Large language model based multi-agents for equity portfolio constructions,”arXiv preprint arXiv:2508.11152, 2025. [Online]. Available: https://arxiv.org/abs/2508.11152
arXiv 2025
-
[21]
ContestTrade: A multi-agent trading system based on internal contest mechanism,
L. Zhao, R. Sun, Z. Jiang, B. Yang, Y . Bai, M. Chen, X. Wang, J. Li, and Z. Bai, “ContestTrade: A multi-agent trading system based on internal contest mechanism,”arXiv preprint arXiv:2508.00554, 2025. [Online]. Available: https://arxiv.org/abs/2508.00554
arXiv 2025
-
[22]
Toward expert investment teams: A multi-agent LLM system with fine-grained trading tasks,
K. Miyazaki, T. Kawahara, S. Roberts, and S. Zohren, “Toward expert investment teams: A multi-agent LLM system with fine-grained trading tasks,”arXiv preprint arXiv:2602.23330, 2026. [Online]. Available: https://arxiv.org/abs/2602.23330
arXiv 2026
-
[23]
AlphaCrafter: A full-stack multi-agent framework for cross-sectional quantitative trading,
Y . Yuan, J. Sheng, S. Zeng, J. Wang, and J. Liu, “AlphaCrafter: A full-stack multi-agent framework for cross-sectional quantitative trading,”arXiv preprint arXiv:2605.05580, 2026. [Online]. Available: https://arxiv.org/abs/2605.05580
Pith/arXiv arXiv 2026
-
[24]
MM-DREX: Multimodal-driven dynamic routing of LLM experts for financial trading,
Y . Chen, Y . Jiang, Z. Ma, Y . Cao, J. Keung, K. Kuang, L. Gan, Y . Wu, and F. Wu, “MM-DREX: Multimodal-driven dynamic routing of LLM experts for financial trading,”arXiv preprint arXiv:2509.05080, 2025. [Online]. Available: https://arxiv.org/abs/2509.05080
arXiv 2025
-
[25]
QRAFTI: An agentic framework for empirical research in quantitative finance,
T. Lim, K. Muthuraman, and M. Sury, “QRAFTI: An agentic framework for empirical research in quantitative finance,”arXiv preprint arXiv:2604.18500, 2026. [Online]. Available: https://arxiv.org/ abs/2604.18500
Pith/arXiv arXiv 2026
-
[26]
Alpha-GPT: Human-AI interactive alpha mining for quantitative investment,
S. Wang, H. Yuan, L. Zhou, L. M. Ni, H.-Y . Shum, and J. Guo, “Alpha-GPT: Human-AI interactive alpha mining for quantitative investment,”arXiv preprint arXiv:2308.00016, 2023. [Online]. Available: https://arxiv.org/abs/2308.00016
arXiv 2023
-
[27]
QuantAgent: Seeking holy grail in trading by self-improving large language model,
S. Wang, H. Yuan, L. M. Ni, and J. Guo, “QuantAgent: Seeking holy grail in trading by self-improving large language model,” arXiv preprint arXiv:2402.03755, 2024. [Online]. Available: https: //arxiv.org/abs/2402.03755
arXiv 2024
-
[28]
StockGPT: A GenAI model for stock prediction and trading,
D. Mai, “StockGPT: A GenAI model for stock prediction and trading,”arXiv preprint arXiv:2404.05101, 2024. [Online]. Available: https://arxiv.org/abs/2404.05101
arXiv 2024
-
[30]
Available: https://arxiv.org/abs/2502.16789
[Online]. Available: https://arxiv.org/abs/2502.16789
-
[32]
Available: https://arxiv.org/abs/2502.07393
[Online]. Available: https://arxiv.org/abs/2502.07393
-
[33]
Hubble: An LLM-driven agentic framework for safe, diverse, and reproducible alpha factor discovery,
R. Shi, S. Yan, Y . Cai, and C. Lv, “Hubble: An LLM-driven agentic framework for safe, diverse, and reproducible alpha factor discovery,”arXiv preprint arXiv:2604.09601, 2026. [Online]. Available: https://arxiv.org/abs/2604.09601
Pith/arXiv arXiv 2026
-
[34]
INVESTORBENCH: A benchmark for financial decision-making tasks with LLM-based agent,
H. Li, Y . Cao, Y . Yu, S. R. Javaji, Z. Deng, Y . He, Y . Jiang, Z. Zhu, K. Subbalakshmi, G. Xiong, J. Huang, L. Qian, X. Peng, Q. Xie, and J. W. Suchow, “INVESTORBENCH: A benchmark for financial decision-making tasks with LLM-based agent,”arXiv preprint arXiv:2412.18174, 2024. [Online]. Available: https://arxiv.org/abs/2412. 18174
arXiv 2024
-
[35]
AI-Trader: Benchmarking autonomous agents in real-time financial markets,
T. Fan, Y . Yang, Y . Jiang, Y . Zhang, Y . Chen, and C. Huang, “AI-Trader: Benchmarking autonomous agents in real-time financial markets,”arXiv preprint arXiv:2512.10971, 2025. [Online]. Available: https://arxiv.org/abs/2512.10971
arXiv 2025
-
[36]
PortBench: A correlation-aware, full-pipeline benchmark for LLM-driven portfolio management,
Y . Zhao, S. Chen, and N. Su, “PortBench: A correlation-aware, full-pipeline benchmark for LLM-driven portfolio management,” arXiv preprint arXiv:2605.27887, 2026. [Online]. Available: https: //arxiv.org/abs/2605.27887
Pith/arXiv arXiv 2026
-
[37]
Look-Ahead-Bench: A standardized benchmark of look-ahead bias in point-in-time LLMs for finance,
M. Benhenda, “Look-Ahead-Bench: A standardized benchmark of look-ahead bias in point-in-time LLMs for finance,”arXiv preprint arXiv:2601.13770, 2026. [Online]. Available: https://arxiv.org/abs/2601. 13770
arXiv 2026
-
[38]
Can large language models trade? testing financial theories with LLM agents in market simulations,
A. Lopez-Lira, “Can large language models trade? testing financial theories with LLM agents in market simulations,”arXiv preprint arXiv:2504.10789, 2025. [Online]. Available: https://arxiv.org/abs/2504. 10789
arXiv 2025
-
[40]
Available: https://arxiv.org/abs/2601.13082
[Online]. Available: https://arxiv.org/abs/2601.13082
-
[41]
Ranking abuse via strategic pairwise data perturbations,
J. Yao, Z. Zheng, and J. Long, “Ranking abuse via strategic pairwise data perturbations,”arXiv preprint arXiv:2604.17805, 2026. [Online]. Available: https://arxiv.org/abs/2604.17805
Pith/arXiv arXiv 2026
-
[42]
The PRISMA 2020 statement: An updated guideline for reporting systematic reviews,
M. J. Page, J. E. McKenzie, P. M. Bossuyt, I. Boutron, T. C. Hoffmann, C. D. Mulrow, L. Shamseer, J. M. Tetzlaff, E. A. Akl, S. E. Brennan, R. Chou, J. Glanville, J. M. Grimshaw, A. Hr ´objartsson, M. M. Lalu, T. Li, E. W. Loder, E. Mayo-Wilson, S. McDonald, L. A. McGuinness, L. A. Stewart, J. Thomas, A. C. Tricco, V . A. Welch, P. Whiting, and BEYOND AGE...
2020
-
[43]
L. Cao, “Chain-of-alpha: Unleashing the power of large language models for alpha mining in quantitative trading,”arXiv preprint arXiv:2508.06312, 2025, withdrawn. [Online]. Available: https://arxiv. org/abs/2508.06312
arXiv 2025
-
[44]
Open-FinLLMs: Open multimodal large language models for financial applications,
J. Huang, M. Xiao, D. Li, Z. Jiang, Y . Yang, Y . Zhang, L. Qian, Y . Wang, X. Peng, Y . Renet al., “Open-FinLLMs: Open multimodal large language models for financial applications,” arXiv preprint arXiv:2408.11878, 2024. [Online]. Available: https: //arxiv.org/abs/2408.11878
arXiv 2024
-
[45]
Alpha-GPT 2.0: Human-in-the-loop AI for quantitative investment,
H. Yuan, S. Wang, and J. Guo, “Alpha-GPT 2.0: Human-in-the-loop AI for quantitative investment,”arXiv preprint arXiv:2402.09746, 2024. [Online]. Available: https://arxiv.org/abs/2402.09746
arXiv 2024
-
[46]
Learning to generate explainable stock predictions using self-reflective large language models,
K. J. L. Koa, Y . Ma, R. Ng, and T.-S. Chua, “Learning to generate explainable stock predictions using self-reflective large language models,”arXiv preprint arXiv:2402.03659, 2024. [Online]. Available: https://arxiv.org/abs/2402.03659
arXiv 2024
-
[48]
Available: https://arxiv.org/abs/2403.12285
[Online]. Available: https://arxiv.org/abs/2403.12285
-
[49]
Y . Yu, Z. Yao, H. Li, Z. Deng, Y . Cao, Z. Chen, J. W. Suchow, R. Liu, Z. Cui, Z. Xu, D. Zhang, K. Subbalakshmi, G. Xiong, Y . He, J. Huang, D. Li, and Q. Xie, “FinCon: A synthesized LLM multi-agent system with conceptual verbal reinforcement for enhanced financial decision making,”arXiv preprint arXiv:2407.06567, 2024. [Online]. Available: https://arxiv...
arXiv 2024
-
[51]
Available: https://arxiv.org/abs/2508.02366
[Online]. Available: https://arxiv.org/abs/2508.02366
-
[52]
Chatgpt,
OpenAI, “Chatgpt,” https://chatgpt.com/, 2026, aI system used for manuscript drafting assistance
2026
-
[53]
——, “Codex,” https://openai.com/codex/, 2026, aI coding assistant used for LaTeX editing and build verification
2026
-
[54]
Submission guidelines for authors,
IEEE Access, “Submission guidelines for authors,” https: //ieeeaccess.ieee.org/guide-for-authors/submission-guidelines/, 2026, accessed: 2026-05-30
2026
-
[55]
Preparing your article,
——, “Preparing your article,” https://ieeeaccess.ieee.org/authors/ preparing-your-article/, 2026, accessed: 2026-05-30
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.