OpenURMA: A Clean-Room Open Implementation of the Unified Bus Protocol
Pith reviewed 2026-06-29 12:03 UTC · model grok-4.3
The pith
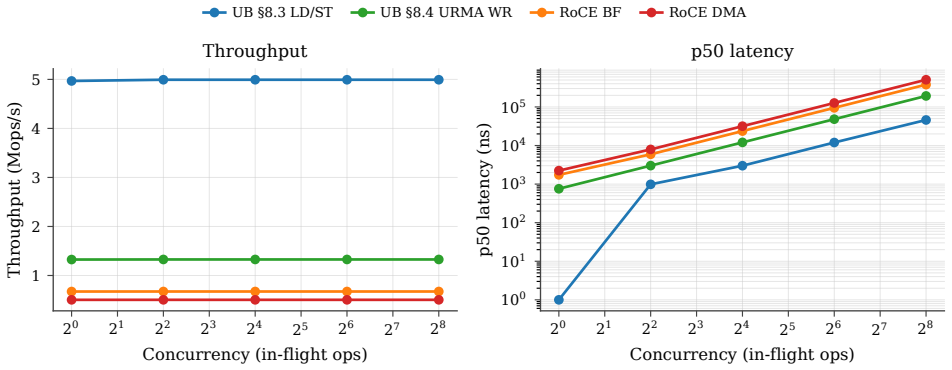
OpenURMA's clean-room implementation of the Unified Bus protocol achieves ~500 ns end-to-end latency on 64-byte remote fetches, 4.37 times lower than a matched RoCE baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
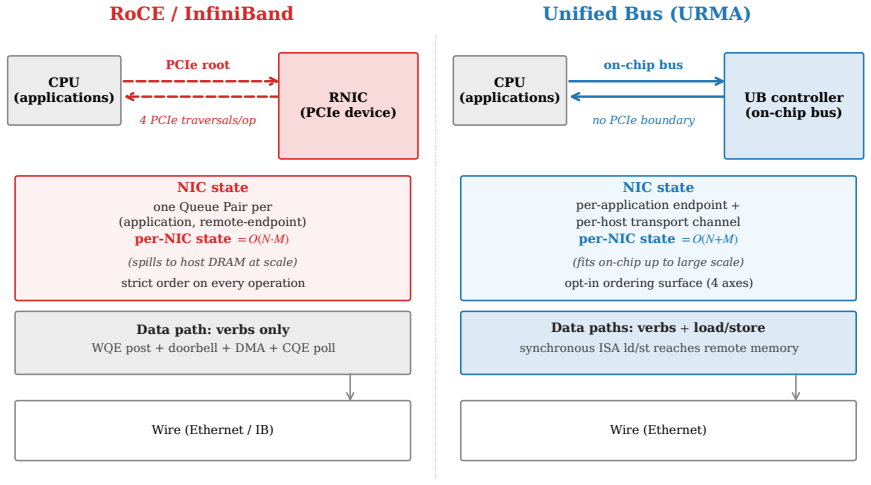
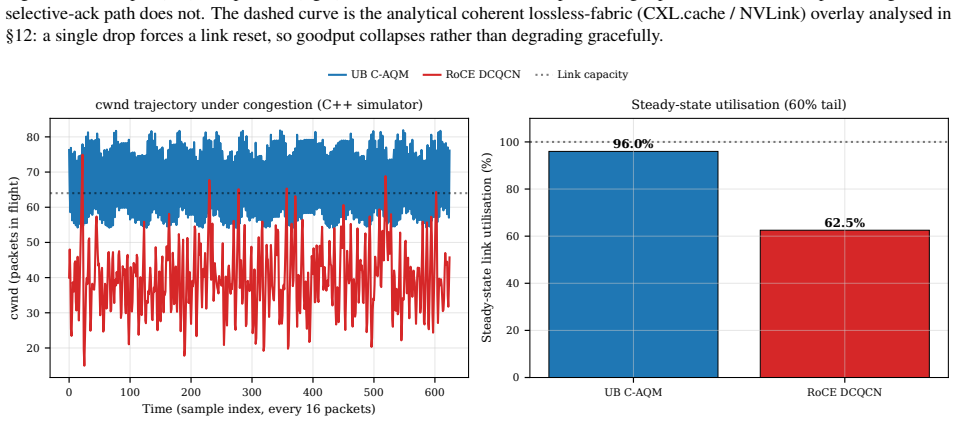
The central claim is that a faithful three-tier open realization of the public UB specification delivers a load/store remote-fetch path with ~500 ns end-to-end latency on the canonical 64-byte operation, 4.37 times below the matched OpenRoCE baseline of 2186 ns, while sustaining 2.80 times higher throughput and occupying only ~14 percent of a U50's LUTs.
What carries the argument
The three-tier OpenURMA stack (synthesisable RTL on Alveo U50, cycle-level two-node SystemC simulator, gem5 full-system scaffold) that implements UB transport and transaction layers and is compared against a matched OpenRoCEv2 RC baseline.
If this is right
- Connection context grows additively with applications rather than scaling with hundreds of megabytes per host at 1024-application fanout.
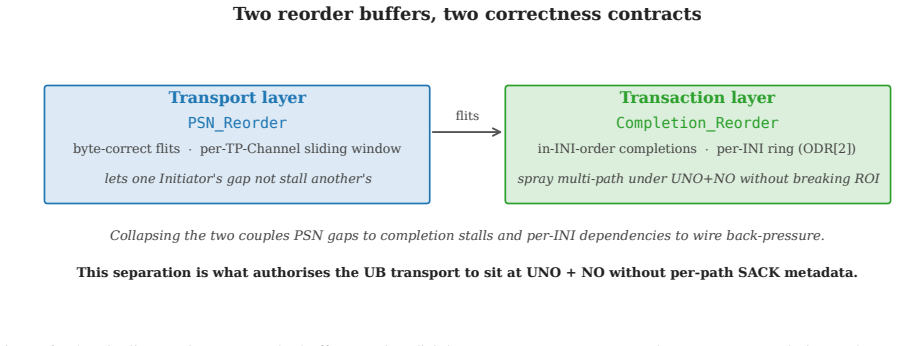
- Ordering guarantees become opt-in instead of mandatory for every operation.
- Remote memory is reached via a single on-chip-bus controller load/store rather than a four-traversal PCIe round trip.
- The measured resource footprint of 14 percent LUTs leaves headroom for additional on-NIC functions in the same silicon budget.
Where Pith is reading between the lines
- An open reference implementation allows other groups to test UB variants or port the design to different FPGA or ASIC targets without access to closed silicon.
- The latency reduction suggests that similar abstraction changes could be explored for non-Huawei RDMA stacks if the spec remains public.
- The gem5 scaffold provides a full-system model that could be extended to study interactions between UB and host OS or application runtimes.
- Low LUT usage implies UB could be integrated into smaller or lower-cost network devices than current RoCE NICs.
Load-bearing premise
The three-tier OpenURMA implementation correctly and faithfully realizes the public UB specification without hidden optimizations or deviations that would not be present in a production closed-silicon realization.
What would settle it
Independent synthesis and cycle-accurate measurement of the released RTL on the same U50 platform yielding latency or throughput numbers materially different from the reported 500 ns / 2.80 times figures would falsify the performance claim.
Figures




































read the original abstract
Modern datacenter RDMA is bottlenecked at the network interface, not the wire. A NIC running RoCE or InfiniBand holds per-connection state for every (application, remote-endpoint) pair - hundreds of megabytes at 1024-application fanout - and pays a four-traversal PCIe round trip on a 64-byte operation, inflating latency an order of magnitude beyond the wire. Both follow from the Queue Pair over PCIe abstraction RDMA inherits from InfiniBand. Huawei's Unified Bus (UB), a public 2025 specification, changes the abstraction: it decouples per-application endpoint state from per-host transport state so connection context grows additively, exposes ordering as opt-in, and reaches remote memory through native CPU load/store to an on-chip-bus controller. UB ships in Huawei's closed Ascend 950 silicon. OpenURMA is the first clean-room open implementation of UB's transport and transaction layers, realised at three tiers - synthesisable RTL on Alveo U50, a cycle-level two-node SystemC simulator, and a gem5 full-system scaffold - each with a matched OpenRoCE (RoCEv2 RC) baseline. The contribution is the implementation, harness, and controlled comparison closed silicon does not admit. On the canonical 64-byte remote fetch - LOAD on UB-spec Sec.8.3, READ on RoCEv2 RC - UB's load/store path delivers ~500 ns end-to-end, 4.37x below the matched baseline (2186 ns), sustains 2.80x higher throughput, and fits in ~14% of a U50's LUTs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents OpenURMA as the first clean-room open implementation of Huawei's public Unified Bus (UB) specification, realized in three tiers (synthesizable RTL on Alveo U50 FPGA, cycle-level SystemC simulator, and gem5 full-system scaffold) with matched OpenRoCEv2 RC baselines. It reports that on the canonical 64-byte remote fetch (LOAD per UB-spec Sec.8.3 vs. READ on RoCE), the UB load/store path achieves ~500 ns end-to-end latency (4.37× below the 2186 ns baseline), 2.80× higher throughput, and occupies ~14% of U50 LUTs. The contribution centers on the implementation, harness, and controlled comparison that closed silicon does not permit.
Significance. If the three-tier implementations faithfully realize the public UB specification without hidden deviations, the work supplies the first reproducible open platform for studying UB's decoupled state, opt-in ordering, and native load/store path against conventional RDMA. The multi-tier design (RTL + SystemC + gem5) is a concrete strength that enables different fidelity levels and controlled experiments. This is valuable because UB currently exists only in closed Ascend 950 silicon.
major comments (1)
- [Abstract and evaluation section] Abstract and § on evaluation (performance numbers): the central claims of 500 ns latency, 4.37× improvement, and 2.80× throughput rest on the three-tier OpenURMA exactly reproducing UB-spec Sec.8.3 behavior (decoupled state, opt-in ordering, native load/store without reduced PCIe traversals or idealized shortcuts). The manuscript supplies no machine-checked correspondence, external test vectors, third-party audit, or workload descriptions to confirm fidelity; self-reported matching is the sole evidence. This is load-bearing for the comparison to the matched OpenRoCE baseline.
minor comments (1)
- [Abstract] The abstract states performance numbers but omits workload descriptions, error bars, or measurement methodology; these details should be added for reproducibility even if moved to an appendix.
Simulated Author's Rebuttal
We thank the referee for the careful review and for recognizing the multi-tier design as a strength. We address the major comment on implementation fidelity point by point below.
read point-by-point responses
-
Referee: [Abstract and evaluation section] Abstract and § on evaluation (performance numbers): the central claims of 500 ns latency, 4.37× improvement, and 2.80× throughput rest on the three-tier OpenURMA exactly reproducing UB-spec Sec.8.3 behavior (decoupled state, opt-in ordering, native load/store without reduced PCIe traversals or idealized shortcuts). The manuscript supplies no machine-checked correspondence, external test vectors, third-party audit, or workload descriptions to confirm fidelity; self-reported matching is the sole evidence. This is load-bearing for the comparison to the matched OpenRoCE baseline.
Authors: We agree that fidelity to UB-spec Sec.8.3 is load-bearing for the reported latency, throughput, and comparison results. The three tiers were developed as a clean-room implementation strictly following the public specification, with explicit attention to decoupled per-application state, opt-in ordering, and the native load/store path without idealized shortcuts or reduced PCIe traversals. The SystemC model is cycle-level, the gem5 scaffold is full-system, and the RTL is synthesizable on the Alveo U50; the OpenRoCEv2 RC baseline was realized in identical environments for controlled comparison. That said, the manuscript provides no machine-checked correspondence, external test vectors, or third-party audit. We will revise the evaluation section to add explicit workload descriptions, sample test vectors with their mapping to specification sections, and additional validation details to make the fidelity evidence more transparent. revision: partial
Circularity Check
Implementation and measurement paper with no derivation chain or predictions
full rationale
The manuscript describes a clean-room open implementation of the public UB specification realized in three tiers (RTL on U50, SystemC simulator, gem5 scaffold) and reports measured latency/throughput numbers against a matched OpenRoCE baseline. No equations, first-principles derivations, fitted parameters, or predictions appear in the provided text; the central claims are direct empirical outcomes of running the implemented hardware and simulators. Because there is no load-bearing derivation step that could reduce to its own inputs by construction, the paper is self-contained against external benchmarks and exhibits no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Effec- tively prefetching remote memory with Leap
Hasan Al Maruf and Mosharaf Chowdhury. Effec- tively prefetching remote memory with Leap. In Proc. USENIX ATC, 2020. Far-memory prefetch heuristic; cited in §8.2 as an example of software- side swap optimisation
2020
-
[2]
Aguilera, Aurojit Panda, Sylvia Ratnasamy, and Scott Shenker
Emmanuel Amaro, Christopher Branner-Augmon, Zhihong Luo, Amy Ousterhout, Marcos K. Aguilera, Aurojit Panda, Sylvia Ratnasamy, and Scott Shenker. Can far memory improve job throughput? InProc. EuroSys, 2020. Introduces Fastswap; reports ∼1 µs kernel-side overhead and batched-prefetch swap-in, the basis of the second swap profile in §8.2
2020
-
[3]
Enabling programmable transport protocols in high-speed NICs
Mina Tahmasbi Arashloo, Alexey Lavrov, Manya Ghobadi, Jennifer Rexford, David Walker, and David Wentzlaff. Enabling programmable transport protocols in high-speed NICs. InProc. USENIX NSDI, 2020. 30
2020
-
[4]
Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears
Brian F. Cooper, Adam Silberstein, Erwin Tam, Raghu Ramakrishnan, and Russell Sears. Bench- marking cloud serving systems with YCSB. InProc. ACM SoCC, 2010. The Yahoo! Cloud Serving Benchmark; we use the YCSB-A 50/50 Get-Put Zipfian workload in §8.3
2010
-
[5]
Compute Express Link (CXL) Specification 3.1
CXL Consortium. Compute Express Link (CXL) Specification 3.1. https://www. computeexpresslink.org/, 2024
2024
-
[6]
FaRM: Fast remote memory
Aleksandar Dragojevi ´c, Dushyanth Narayanan, Orion Hodson, and Miguel Castro. FaRM: Fast remote memory. InProc. USENIX NSDI, 2014
2014
-
[7]
NICA: An infrastructure for inline acceleration of network applications
Haggai Eran, Lior Zeno, Maroun Tork, Gabi Malka, and Mark Silberstein. NICA: An infrastructure for inline acceleration of network applications. InProc. USENIX ATC, 2019
2019
-
[8]
Azure Accelerated Networking: SmartNICs in the public cloud
Daniel Firestone, Andrew Putnam, Sambhrama Mundkur, Derek Chiou, Alireza Dabagh, Mike An- drewartha, Hari Angepat, et al. Azure Accelerated Networking: SmartNICs in the public cloud. In Proc. USENIX NSDI, 2018
2018
-
[9]
RDMA over Ethernet for dis- tributed training at meta scale
Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Rohit Puri, Mohammad Riftadi, Ashmitha Jee- varaj Shetty, Jingyi Yang, Shuqiang Zhang, Mikel Jimenez Fernandez, Shashidhar Gandham, and Hongyi Zeng. RDMA over Ethernet for dis- tributed training at meta scale. InProc. ACM SIG- COMM, 2024
2024
-
[10]
Dan Gibson, Hema Hariharan, Eric Lance, Moray McLaren, Behnam Montazeri, Arjun Singh, Stephen Wang, Hassan M. G. Wassel, Zhehua Wu, Sungh- wan Yoo, Raghuraman Balasubramanian, Prashant Chandra, Michael Cutforth, Peter Cuy, David De- cotigny, Rakesh Gautam, Alex Iriza, Milo M. K. Martin, Rick Roy, Zuowei Shen, Ming Tan, Ye Tang, Monica Wong-Chan, Joe Zbici...
2022
-
[11]
Juncheng Gu, Youngmoon Lee, Yiwen Zhang, Mosharaf Chowdhury, and Kang G. Shin. Efficient memory disaggregation with Infiniswap. InProc. USENIX NSDI, 2017. Kernel-side overhead of 3– 5 µs on the swap-in path is the parameter referenced in §8.2
2017
-
[12]
Clio: A hardware- software co-designed disaggregated memory system
Zhiyuan Guo, Yizhou Shan, Xuhao Luo, Yutong Huang, and Yiying Zhang. Clio: A hardware- software co-designed disaggregated memory system. InProc. ACM ASPLOS, 2022
2022
-
[13]
TUR-DPO: Topology- and Uncertainty-Aware Direct Preference Optimization
Tingbo He. A time scaling theory for multi- layer electronic systems.ChinaXiv, May 2026. chinarxiv-202605.00224. Perspective from Huawei Semiconductor: τ scaling as successor to geomet- ric Moore’s-Law scaling; positions Unified Bus as the system-layer τ reduction mechanism with end-to-end remote-access latency from ∼10s of µs (TCP/IP-class) to∼100 ns
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
SwCC: Software- programmable and per-packet congestion control in RDMA engine
Hongjing Huang, Jie Zhang, Xuzheng Chen, Ziyu Song, Jiajun Qin, and Zeke Wang. SwCC: Software- programmable and per-packet congestion control in RDMA engine. InProc. USENIX ATC, 2025
2025
-
[15]
Fast and scal- able selective retransmission for RDMA
Peihao Huang, Guo Chen, Xin Zhang, Can Liu, Hongyu Wang, Huijun Shen, Ying Bian, Yuanwei Lu, Zhenyuan Ruan, Bojie Li, Jiansong Zhang, Yongfeng Liu, and Zhigang Chen. Fast and scal- able selective retransmission for RDMA. InProc. IEEE INFOCOM, 2025
2025
-
[16]
LEFT: Lightweight and fast packet reordering for RDMA
Peihao Huang, Xin Zhang, Zhigang Chen, Can Liu, and Guo Chen. LEFT: Lightweight and fast packet reordering for RDMA. InProc. APNet, 2024
2024
-
[17]
UB-base-specification 2.0.1
Huawei Technologies. UB-base-specification 2.0.1. https://www.unifiedbus.org/,
-
[18]
Unified Bus consortium specification, avail- able from the consortium’s documentation portal
-
[19]
Ascend 950 NPU archi- tecture white paper
Huawei Technologies. Ascend 950 NPU archi- tecture white paper. Huawei vendor white paper, May 2026. Architectural disclosure for the Ascend 950PR and 950DT NPUs; first publicly documented silicon implementing the Unified Bus spec, with URMA (asynchronous Write/Read/Send/Atomic via Jetty) and UB Memory (synchronous Load/Store + AtomicStore/Load/Swap/CAS) ...
2026
-
[20]
NanoTransport: A low-latency, programmable transport layer for NICs
Stephen Ibanez, Alex Mallery, Serhat Arslan, Theo Jepsen, Muhammad Shahbaz, Nick McKeown, and Changhoon Kim. NanoTransport: A low-latency, programmable transport layer for NICs. InProc. ACM SOSR, 2021
2021
-
[21]
An- dersen
Anuj Kalia, Michael Kaminsky, and David G. An- dersen. FaSST: Fast, scalable and simple dis- tributed transactions with two-sided (RDMA) data- gram RPCs. InProc. USENIX OSDI, 2016
2016
-
[22]
An- dersen
Anuj Kalia, Michael Kaminsky, and David G. An- dersen. Datacenter RPCs can be general and fast. In Proc. USENIX NSDI, 2019
2019
-
[23]
Sharma, Arvind Krishnamurthy, and Thomas Anderson
Antoine Kaufmann, Tim Stamler, Simon Peter, Naveen Kr. Sharma, Arvind Krishnamurthy, and Thomas Anderson. TAS: TCP acceleration as an OS service. InProc. EuroSys, 2019. Reports detailed PCIe-class transaction latency decompositions used as parameter references in §5
2019
-
[24]
Lebeck, and Danyang Zhuo
Xinhao Kong, Jingrong Chen, Wei Bai, Yechen Xu, Mahmoud Elhaddad, Shachar Raindel, Jiten- dra Padhye, Alvin R. Lebeck, and Danyang Zhuo. 31 Understanding RDMA microarchitecture resources for performance isolation. InProc. USENIX NSDI, 2023
2023
-
[25]
Collie: Finding performance anomalies in RDMA subsystems
Xinhao Kong, Yibo Zhu, Huaping Zhou, Zhuo Jiang, Jianxi Ye, Chuanxiong Guo, and Danyang Zhuo. Collie: Finding performance anomalies in RDMA subsystems. InProc. USENIX NSDI, 2022
2022
-
[26]
Gautam Kumar, Nandita Dukkipati, Keon Jang, Hassan M. G. Wassel, Xian Wu, Behnam Montaz- eri, Yaogong Wang, Kevin Springborn, Christopher Alfeld, Michael Ryan, David Wetherall, and Amin Vahdat. Swift: Delay is simple and effective for congestion control in the datacenter. InProc. ACM SIGCOMM, 2020
2020
-
[27]
STrack: A re- liable multipath transport for AI/ML clusters
Yanfang Le, Rong Pan, Peter Newman, Jeremias Blendin, Abdul Kabbani, Vipin Jain, Raghava Sivaramu, and Francis Matus. STrack: A re- liable multipath transport for AI/ML clusters. arXiv:2407.15266, 2024
-
[28]
OpenClickNP: a clean-room reimple- mentation of ClickNP on Alveo U50
Bojie Li. OpenClickNP: a clean-room reimple- mentation of ClickNP on Alveo U50. https: //github.com/bojieli/OpenClickNP, 2025–2026
2025
-
[29]
SocksDirect: Datacenter sockets can be fast and compatible
Bojie Li, Tianyi Cui, Zibo Wang, Wei Bai, and Lin- tao Zhang. SocksDirect: Datacenter sockets can be fast and compatible. InProc. ACM SIGCOMM, 2019
2019
-
[30]
KV-Direct: High- performance in-memory key-value store with pro- grammable NIC
Bojie Li, Zhenyuan Ruan, Wencong Xiao, Yuan- wei Lu, Yongqiang Xiong, Andrew Putnam, En- hong Chen, and Lintao Zhang. KV-Direct: High- performance in-memory key-value store with pro- grammable NIC. InProc. ACM SOSP, 2017
2017
-
[31]
ClickNP: Highly flexible and high-performance network processing with reconfigurable hardware
Bojie Li, Kun Tan, Layong Larry Luo, Yanqing Peng, Renqian Luo, Ningyi Xu, Yongqiang Xiong, Peng Cheng, and Enhong Chen. ClickNP: Highly flexible and high-performance network processing with reconfigurable hardware. InProc. ACM SIG- COMM, 2016
2016
-
[32]
FastWake: Revis- iting host network stack for interrupt-mode RDMA
Bojie Li, Zhilong Xiang, Xiang Wang, Hon- gru Jonathan Zhou, and Kun Tan. FastWake: Revis- iting host network stack for interrupt-mode RDMA. InProc. APNet, 2023
2023
-
[33]
1Pipe: Scalable total order communication in data center networks
Bojie Li, Gefei Zuo, Wei Bai, and Lintao Zhang. 1Pipe: Scalable total order communication in data center networks. InProc. ACM SIGCOMM, 2021
2021
-
[34]
Flor: An open high performance RDMA framework over heterogeneous RNICs
Qiang Li, Yixiao Gao, Xiaoliang Wang, Haonan Qiu, Yanfang Le, Derui Liu, Qiao Xiang, Fei Feng, Peng Zhang, Bo Li, Jianbo Dong, Lingbo Tang, Hongqiang Harry Liu, Shaozong Liu, Weijie Li, Rui Miao, Yaohui Wu, Zhiwu Wu, Chao Han, Lei Yan, Zheng Cao, Zhongjie Wu, Chen Tian, Guihai Chen, Dennis Cai, Jinbo Wu, Jiaji Zhu, Jiesheng Wu, and Jiwu Shu. Flor: An open...
2023
-
[35]
Revisiting RDMA reliability for lossy fabrics
Wenxue Li, Xiangzhou Liu, Yunxuan Zhang, Zi- hao Wang, Wei Gu, Tao Qian, Gaoxiong Zeng, Shoushou Ren, Xinyang Huang, Zhenghang Ren, Bowen Liu, Junxue Zhang, Kai Chen, and Bingyang Liu. Revisiting RDMA reliability for lossy fabrics. InProc. ACM SIGCOMM, 2025. Best Student Paper, Honorable Mention
2025
-
[36]
HPCC: High precision congestion control
Yuliang Li, Rui Miao, Hongqiang Harry Liu, Yan Zhuang, Fei Feng, Lingbo Tang, Zheng Cao, Ming Zhang, Frank Kelly, Mohammad Alizadeh, and Min- lan Yu. HPCC: High precision congestion control. InProc. ACM SIGCOMM, 2019
2019
-
[37]
Fast- socket: An almost drop-in replacement for the Linux socket interface for High-Performance Networking
Xiaofeng Lin, Yu Chen, Xiaodong Li, et al. Fast- socket: An almost drop-in replacement for the Linux socket interface for High-Performance Networking. InProc. USENIX ATC, 2017
2017
-
[38]
Harmonic: Hardware-assisted RDMA performance isolation for public clouds
Jiaqi Lou, Xinhao Kong, Jinghan Huang, Wei Bai, Nam Sung Kim, and Danyang Zhuo. Harmonic: Hardware-assisted RDMA performance isolation for public clouds. InProc. USENIX NSDI, 2024
2024
-
[39]
The gem5 Simulator: Version 20.0+,
Jason Lowe-Power et al. The gem5 simulator: Ver- sion 20.0+. arXiv:2007.03152, 2020. Open-source cycle-level micro-architecture simulator with Sys- temC TLM 2.0 interoperability bridge; v24.0.0.1 is used as the future-work substrate for full-system integration oflibopenurma_sc.a
-
[40]
Memory efficient loss recovery for hardware-based transport in datacenter
Yuanwei Lu, Guo Chen, Bojie Li, Kun Tan, Yongqiang Xiong, Peng Cheng, Jiansong Zhang, Enhong Chen, and Thomas Moscibroda. Memory efficient loss recovery for hardware-based transport in datacenter. InProc. APNet, 2017
2017
-
[41]
Multi- Path transport for RDMA in datacenters
Yuanwei Lu, Guo Chen, Bojie Li, Kun Tan, Yongqiang Xiong, Peng Cheng, Jiansong Zhang, Enhong Chen, and Thomas Moscibroda. Multi- Path transport for RDMA in datacenters. InProc. USENIX NSDI, 2018
2018
-
[42]
Michael Marty, Marc de Kruijf, Jacob Adriaens, Christopher Alfeld, Sean Bauer, Carlo Contavalli, Michael Dalton, Nandita Dukkipati, William C. Evans, Steve Gribble, Nicholas Kidd, Roman Kononov, Gautam Kumar, Carl Mauer, Emily Mu- sick, Lena Olson, Erik Rubow, Michael Ryan, Kevin Springborn, Paul Turner, Valas Valancius, Xi Wang, and Amin Vahdat. Snap: A ...
2019
-
[43]
TIMELY: RTT-based congestion control for the datacenter
Radhika Mittal, Vinh The Lam, Nandita Dukkipati, Emily Blem, Hassan Wassel, Monia Ghobadi, Amin Vahdat, Yaogong Wang, David Wetherall, and David Zats. TIMELY: RTT-based congestion control for the datacenter. InProc. ACM SIGCOMM, 2015
2015
-
[44]
Revisiting network sup- port for RDMA
Radhika Mittal, Alexander Shpiner, Aurojit Panda, Eitan Zahavi, Arvind Krishnamurthy, Sylvia Rat- nasamy, and Scott Shenker. Revisiting network sup- port for RDMA. InProc. ACM SIGCOMM, 2018. 32
2018
-
[45]
NVLink: A high-bandwidth inter-GPU interconnect
NVIDIA Corporation. NVLink: A high-bandwidth inter-GPU interconnect. Vendor whitepaper, 2014–
2014
-
[46]
Successive generations of the NVLink fabric are described in the NVIDIA whitepaper series
-
[47]
NVIDIA BlueField-3 DPU datasheet
NVIDIA Corporation. NVIDIA BlueField-3 DPU datasheet. NVIDIA Networking product brief, 2023. Available from NVIDIA’s data-processing-unit prod- uct page
2023
-
[48]
NVIDIA Spectrum-X: Adap- tive routing and telemetry-based congestion control for AI networks
NVIDIA Networking. NVIDIA Spectrum-X: Adap- tive routing and telemetry-based congestion control for AI networks. NVIDIA technical brief, 2024. Vendor description of multi-path adaptive-routing delivery over Spectrum-4 / BlueField-3 NICs; the closest commercially-deployed point of comparison to UB’s TPG multi-path scheme
2024
-
[49]
Hermit: Low-latency, high- throughput, and transparent remote memory via feedback-directed asynchrony
Yifan Qiao, Chenxi Wang, Zhenyuan Ruan, Adam Belay, Qingda Lu, Yiying Zhang, Miryung Kim, and Guoqing Harry Xu. Hermit: Low-latency, high- throughput, and transparent remote memory via feedback-directed asynchrony. InProc. USENIX NSDI, 2023. Asynchronous remote-memory swap with feedback-directed I/O; cited in §8.2 for the same workload regime as Infiniswa...
2023
-
[50]
Designing high-performance, low-latency multi-cluster com- munication on modern InfiniBand networks
Sebastian Ramos and Torsten Hoefler. Designing high-performance, low-latency multi-cluster com- munication on modern InfiniBand networks. In Proc. ACM HPDC, 2023. Reports ConnectX-7 PCIe round-trip latencies in the ∼300–500 ns range; we use this as the parameterised PCIe RTT in §5
2023
-
[51]
StRoM: Smart re- mote memory
David Sidler, Zeke Wang, Monica Chiosa, Amit Kulkarni, and Gustavo Alonso. StRoM: Smart re- mote memory. InProc. EuroSys, 2020
2020
-
[52]
Wenisch, Monica Wong-Chan, Sean Clark, Milo M
Arjun Singhvi, Aditya Akella, Dan Gibson, Thomas F. Wenisch, Monica Wong-Chan, Sean Clark, Milo M. K. Martin, Moray McLaren, Prashant Chandra, Rob Cauble, et al. 1RMA: Re- envisioning remote memory access for multi-tenant datacenters. InProc. ACM SIGCOMM, 2020
2020
-
[53]
Arjun Singhvi, Nandita Dukkipati, Prashant Chan- dra, Hassan M. G. Wassel, Naveen Kr. Sharma, Anthony Rebello, Henry Schuh, Praveen Kumar, Behnam Montazeri, Neelesh Bansod, Sarin Thomas, Inho Cho, Hyojeong Lee Seibert, Baijun Wu, Rui Yang, Yuliang Li, Kai Huang, Qianwen Yin, Ab- hishek Agarwal, Srinivas Vaduvatha, Weihuang Wang, Masoud Moshref, Tao Ji, Da...
2025
-
[54]
Network load balancing with in-network reordering support for RDMA
Cha Hwan Song, Xin Zhe Khooi, Raj Joshi, Inho Choi, Jialin Li, and Mun Choon Chan. Network load balancing with in-network reordering support for RDMA. InProc. ACM SIGCOMM, 2023
2023
-
[55]
Ultra Ethernet spec- ification 1.0
Ultra Ethernet Consortium. Ultra Ethernet spec- ification 1.0. Industry specification, 2025. Re- leased June 2025 under Linux Foundation JDF; https://ultraethernet.org/
2025
-
[56]
StaR: Break- ing the scalability limit for RDMA
Xizheng Wang, Guo Chen, Xijin Yin, Huichen Dai, Bojie Li, Binzhang Fu, and Kun Tan. StaR: Break- ing the scalability limit for RDMA. InProc. IEEE ICNP, 2021
2021
-
[57]
SRNIC: A scalable architecture for RDMA NICs
Zilong Wang, Layong Luo, Qingsong Ning, Chao- liang Zeng, Wenxue Li, Xinchen Wan, Peng Xie, Tao Feng, Ke Cheng, Xiongfei Geng, Tianhao Wang, Weicheng Ling, Kejia Huo, Pingbo An, Kui Ji, Shi- deng Zhang, Bin Xu, Ruiqing Feng, Tao Ding, Kai Chen, and Chuanxiong Guo. SRNIC: A scalable architecture for RDMA NICs. InProc. USENIX NSDI, 2023
2023
-
[58]
Justitia: Software multi- tenancy in hardware kernel-bypass networks
Yiwen Zhang, Yue Tan, Brent Stephens, and Mosharaf Chowdhury. Justitia: Software multi- tenancy in hardware kernel-bypass networks. In Proc. USENIX NSDI, 2022
2022
-
[59]
White-boxing RDMA with packet-granular software control
Chenxingyu Zhao, Jaehong Min, Ming Liu, and Arvind Krishnamurthy. White-boxing RDMA with packet-granular software control. InProc. USENIX NSDI, 2025
2025
-
[60]
Congestion control for Large-Scale RDMA deployments
Yibo Zhu, Haggai Eran, Daniel Firestone, Chuanx- iong Guo, Marina Lipshteyn, Yehonatan Liron, Ji- tendra Padhye, Shachar Raindel, Mohamad Haj Yahia, and Ming Zhang. Congestion control for Large-Scale RDMA deployments. InProc. ACM SIGCOMM, 2015. 33
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.