OmniDrive: An LLM-Choreographed Multi-Agent World Model with Unified Latent Co-Compression for Multi-View Driving Video Generation
Pith reviewed 2026-06-27 01:43 UTC · model grok-4.3
The pith
An LLM multi-agent system unifies language, maps, and trajectories into one position-aware token sequence that a 3-D VAE co-compresses with multi-view video to enforce geometric consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
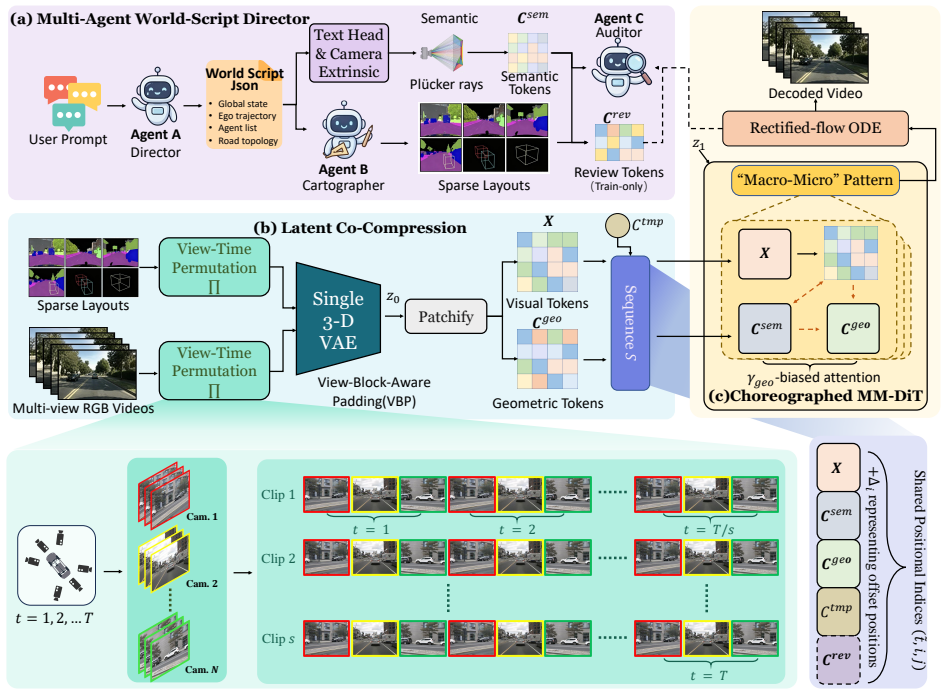
DRIVE-CHOREO recasts controllable multi-view video generation as latent choreography: a Director agent turns user intent into a WorldScript, a Cartographer grounds it in spatially anchored layout tokens, and an Auditor supplies cross-view critiques; the resulting position-aware token sequence is co-compressed with the multi-view video via a view-time permutation that places inter-camera geometry inside the receptive field of a 3-D VAE.
What carries the argument
The LLM-choreographed position-aware token sequence co-compressed with multi-view video via view-time permutation inside a 3-D VAE.
If this is right
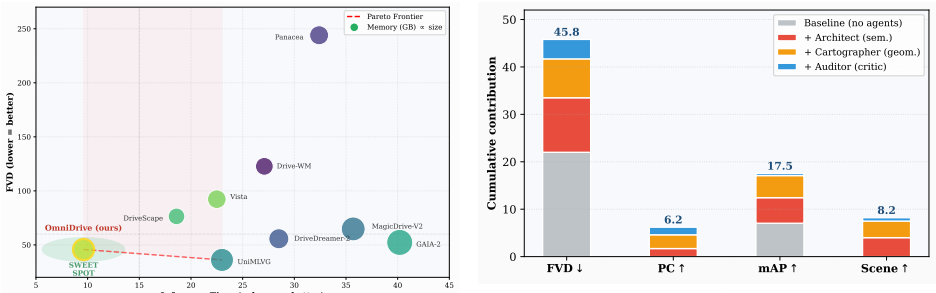
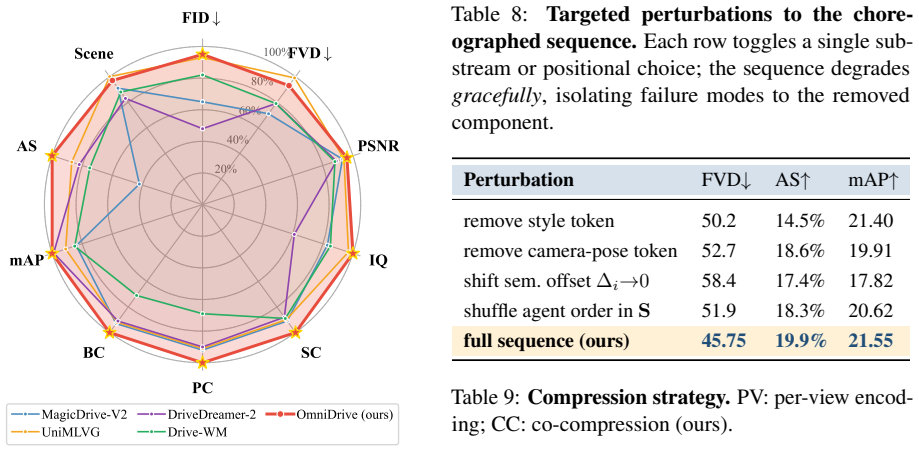
- Multi-view video generation reaches new state-of-the-art consistency and BEV mAP of 21.6 on nuScenes.
- A detector trained solely on the synthetic videos improves real-world NDS by 2.4 points.
- Free-form language, HD-maps, trajectories, and camera poses become compatible inputs through a single token sequence.
- Cross-view geometric consistency is achieved at compression time rather than by post-hoc fusion of separate camera latents.
Where Pith is reading between the lines
- The same token-choreography pattern could be tested on non-driving multi-view settings such as indoor robotics or surveillance if the view-time permutation is adapted to the new camera layout.
- If the Auditor agent's critiques can be made differentiable, the entire pipeline might support end-to-end fine-tuning of the VAE rather than the current two-stage training.
- The approach suggests that world models for driving may benefit more from explicit symbolic alignment than from larger diffusion or autoregressive backbones alone.
Load-bearing premise
The LLM-authored token sequence, once permuted with the video frames, actually places the necessary inter-camera geometric relations inside the 3-D VAE receptive field so that consistency is enforced during compression.
What would settle it
Generate the videos on nuScenes validation scenes, train a standard 3-D detector exclusively on those videos, and observe no gain or a loss in NDS when the detector is evaluated on the real validation split.
Figures





read the original abstract
Generative world models for autonomous driving face two unresolved tensions: heterogeneous control injection, where free-form language, HD-maps, trajectories, and camera poses reside in incompatible representational spaces, and post-hoc cross-view fusion, where per-camera latents fail to encode global 3-D geometry. We trace both to a single root cause: the absence of a shared symbolic interlingua aligning language, geometry, and pixels at the latent-token level. We present DRIVE-CHOREO, an LLM-choreographed multi-agent world model that recasts controllable multi-view video generation as latent choreography. Three Qwen2.5-VL agents - a Director parsing user intent into a structured WorldScript, a Cartographer grounding it into spatially-anchored layout tokens, and an Auditor feeding cross-view critiques back as auxiliary supervision - jointly author a single position-aware token sequence. This sequence is co-compressed with the multi-view video via a view-time permutation that enforces inter-camera geometry within the convolutional receptive field of a 3-D VAE. On nuScenes, DRIVE-CHOREO sets new state-of-the-art multi-view consistency and BEV mAP (21.6) with competitive FVD (45.7); a detector trained purely on our synthetic data gains +2.4 NDS on the real validation split, validating downstream utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DRIVE-CHOREO, an LLM-choreographed multi-agent world model for controllable multi-view driving video generation. Three Qwen2.5-VL agents (Director, Cartographer, Auditor) jointly produce a position-aware token sequence from a structured WorldScript; this sequence is co-compressed with multi-view video via a view-time permutation inside a 3-D VAE to enforce inter-camera geometry. On nuScenes the method claims new SOTA multi-view consistency and BEV mAP of 21.6 with competitive FVD of 45.7, plus a +2.4 NDS gain when a detector is trained solely on the generated data.
Significance. If the central mechanism is shown to work, the unified latent interlingua approach could meaningfully advance controllable generative world models for autonomous driving by aligning language, geometry and pixels without post-hoc fusion. The reported downstream detector improvement on real validation data would be a concrete strength.
major comments (2)
- [Abstract] Abstract: the quantitative claims (BEV mAP 21.6, FVD 45.7, +2.4 NDS) are stated without any description of experimental protocol, baselines, error bars, dataset splits, or verification procedure for the geometry-enforcement step, rendering the SOTA and downstream-utility assertions impossible to evaluate from the supplied information.
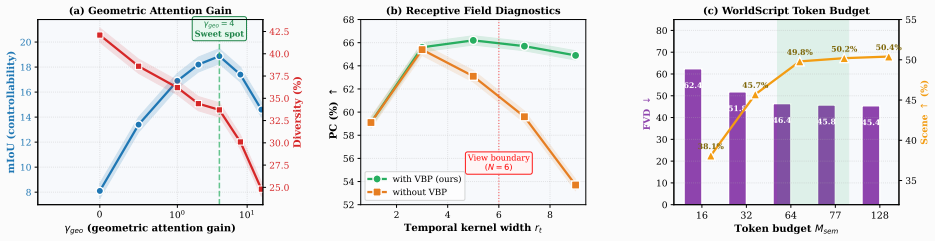
- [Abstract] Abstract: the claim that the view-time permutation places global 3-D geometry inside the 3-D VAE receptive field is load-bearing for both the consistency metric and the +2.4 NDS result, yet no derivation, receptive-field calculation, diagram, or comparison to explicit 3-D encodings or cross-view attention is provided.
minor comments (1)
- [Title] The manuscript title refers to OmniDrive while the abstract and technical claims consistently use DRIVE-CHOREO; this nomenclature inconsistency should be corrected for clarity.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on the abstract. We address the two major comments point-by-point below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the quantitative claims (BEV mAP 21.6, FVD 45.7, +2.4 NDS) are stated without any description of experimental protocol, baselines, error bars, dataset splits, or verification procedure for the geometry-enforcement step, rendering the SOTA and downstream-utility assertions impossible to evaluate from the supplied information.
Authors: We agree that the abstract's brevity makes the claims difficult to evaluate in isolation. In the revised version we will expand the abstract to briefly note the nuScenes dataset and splits used, the main baselines compared for the SOTA claims, and that the +2.4 NDS result comes from training a BEV detector on generated data and evaluating on the real validation set. Full experimental protocols, error bars, and verification details remain in Sections 4 and 5; we will also add a short clause referencing the geometry-enforcement verification procedure. revision: yes
-
Referee: [Abstract] Abstract: the claim that the view-time permutation places global 3-D geometry inside the 3-D VAE receptive field is load-bearing for both the consistency metric and the +2.4 NDS result, yet no derivation, receptive-field calculation, diagram, or comparison to explicit 3-D encodings or cross-view attention is provided.
Authors: The view-time permutation and its effect on the 3-D VAE receptive field are derived and illustrated in Section 3.2 and Figure 3 of the manuscript, including the token reordering that aligns inter-camera geometry within convolutional kernels and comparisons to cross-view attention baselines. We will revise the abstract to include a concise reference to this mechanism and, if space allows, a parenthetical note on the receptive-field alignment. Should the editor request, we can also add a short receptive-field calculation or explicit comparison table in the main text or supplement. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external dataset evaluation without self-referential reductions.
full rationale
The paper introduces an LLM-based multi-agent architecture (Director, Cartographer, Auditor) and a view-time permutation for latent co-compression, then validates it via reported metrics on the public nuScenes dataset (SOTA consistency, BEV mAP 21.6, FVD 45.7, +2.4 NDS downstream). No equations, parameter fits, or definitions are presented that reduce the central claims to inputs by construction, self-citation chains, or renamed known results. The derivation chain is architectural and tested externally, making it self-contained against benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Qwen2.5-VL agents can effectively parse user intent, ground to spatial layouts, and provide cross-view critiques
- domain assumption The view-time permutation in the 3-D VAE enforces inter-camera geometry
invented entities (2)
-
WorldScript
no independent evidence
-
position-aware token sequence
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jianhong Bai, Menghan Xia, et al. Synccam- master: Synchronizing multi-camera video gen- eration from diverse viewpoints.arXiv preprint arXiv:2412.07760, 2024
arXiv 2024
-
[2]
Shuai Bai et al. Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[3]
Lang, et al
Holger Caesar, Varun Bankiti, Alex H. Lang, et al. nuscenes: A multimodal dataset for au- tonomous driving.Proc. IEEE/CVF Conf. Com- puter Vision and Pattern Recognition (CVPR), 2020
2020
-
[4]
Rui Chen, Zehuan Wu, Yichen Liu, Yuxin Guo, Jingcheng Ni, Haifeng Xia, and Siyu Xia. Unim- lvg: Unified framework for multi-view long video generation with comprehensive control capabilities for autonomous driving.arXiv preprint arXiv:2412.04842, 2024
arXiv 2024
-
[5]
Mv-diffusion: Motion-aware video diffusion model
Zijun Deng, Xiangteng He, Yuxin Peng, Xiong- wei Zhu, and Lele Cheng. Mv-diffusion: Motion-aware video diffusion model. InPro- ceedings of the 31st ACM International Confer- ence on Multimedia, pages 7255–7263, 2023
2023
-
[6]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty- first international conference on machine learn- ing, 2024
2024
-
[7]
Scaling rectified flow transformers for high-resolution image synthesis.Proc
Patrick Esser, Sumith Kulal, Andreas Blattmann, et al. Scaling rectified flow transformers for high-resolution image synthesis.Proc. Interna- tional Conf. Machine Learning (ICML), 2024
2024
-
[8]
3d-rad: A comprehensive 3d radiology med-vqa dataset with multi-temporal analysis and diverse diag- nostic tasks.Advances in Neural Information Processing Systems, 38, 2026
Xiaotang Gai, Jiaxiang Liu, Yichen Li, Zijie Meng, Jian Wu, and Zuozhu Liu. 3d-rad: A comprehensive 3d radiology med-vqa dataset with multi-temporal analysis and diverse diag- nostic tasks.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[9]
Ruiyuan Gao, Kai Chen, Enze Xie, Lanqing Hong, Zhenguo Li, Dit-Yan Yeung, and Qiang Xu. Magicdrive: Street view generation with diverse 3d geometry control.arXiv preprint arXiv:2310.02601, 2023
arXiv 2023
-
[10]
Ruiyuan Gao, Kai Chen, Bo Xiao, Lanqing Hong, Zhenguo Li, and Qiang Xu. Magicdrive- v2: High-resolution long video generation for autonomous driving with adaptive control.arXiv preprint arXiv:2411.13807, 2024
arXiv 2024
-
[11]
Vista: A generalizable driv- ing world model with high fidelity and versatile controllability
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, 10 and Hongyang Li. Vista: A generalizable driv- ing world model with high fidelity and versatile controllability. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2024
2024
-
[12]
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Tokenflow: Consistent diffusion fea- tures for consistent video editing.arXiv preprint arXiv:2307.10373, 2023
Pith/arXiv arXiv 2023
-
[13]
Dist-4d: Disentangled spatiotemporal diffusion with metric depth for 4d driving scene gener- ation.Proc
Jiazhe Guo, Yikang Ding, Xiwu Chen, et al. Dist-4d: Disentangled spatiotemporal diffusion with metric depth for 4d driving scene gener- ation.Proc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2025
2025
-
[14]
Xiangyu Guo et al. Genesis: Multimodal driving scene generation with spatio-temporal and cross-modal consistency.arXiv preprint arXiv:2506.07497, 2025
arXiv 2025
-
[15]
Ltx-video: Realtime video la- tent diffusion.arXiv preprint arXiv:2501.00103, 2024
Yoav HaCohen, Nisan Chiprut, Benny Bra- zowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Vic- tor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. Ltx-video: Realtime video la- tent diffusion.arXiv preprint arXiv:2501.00103, 2024
Pith/arXiv arXiv 2024
-
[16]
Liu He et al. Kubrick: Multimodal agent collab- orations for synthetic video generation.arXiv preprint arXiv:2408.10453, 2024
arXiv 2024
-
[17]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chan- paisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[18]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, et al. Vbench++: Comprehensive and versatile bench- mark suite for video generative models.arXiv preprint arXiv:2411.13503, 2024
arXiv 2024
-
[19]
Yishen Ji et al. Cogen: 3d consistent video generation via adaptive conditioning for autonomous driving.arXiv preprint arXiv:2503.22231, 2025
arXiv 2025
-
[20]
Dive: Dit- based video generation with enhanced control
Junpeng Jiang, Gangyi Hong, Lijun Zhou, En- hui Ma, Hengtong Hu, Xia Zhou, Jie Xiang, Fan Liu, Kaicheng Yu, Haiyang Sun, et al. Dive: Dit- based video generation with enhanced control. arXiv preprint arXiv:2409.01595, 2024
arXiv 2024
-
[21]
Drivegan: Towards a controllable high-quality neural simulation
Seung Wook Kim, Jonah Philion, Antonio Tor- ralba, and Sanja Fidler. Drivegan: Towards a controllable high-quality neural simulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5820–5829, 2021
2021
-
[22]
Auto- encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Diederik P Kingma and Max Welling. Auto- encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
Pith/arXiv arXiv 2013
-
[23]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video genera- tive models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[24]
Vivid-zoo: Multi-view video gener- ation with diffusion model.Advances in Neu- ral Information Processing Systems, 37:62189– 62222, 2024
Bing Li, Cheng Zheng, Wenxuan Zhu, Jinjie Mai, Biao Zhang, Peter Wonka, and Bernard Ghanem. Vivid-zoo: Multi-view video gener- ation with diffusion model.Advances in Neu- ral Information Processing Systems, 37:62189– 62222, 2024
2024
-
[25]
Driv- ingdiffusion: Layout-guided multi-view driving scenarios video generation with latent diffusion model
Xiaofan Li, Yifu Zhang, and Xiaoqing Ye. Driv- ingdiffusion: Layout-guided multi-view driving scenarios video generation with latent diffusion model. InEuropean Conference on Computer Vision, pages 469–485. Springer, 2024
2024
-
[26]
Anim-director: A large mul- timodal model powered agent for controllable animation video generation.SIGGRAPH Asia Conference Papers, 2024
Yunxin Li et al. Anim-director: A large mul- timodal model powered agent for controllable animation video generation.SIGGRAPH Asia Conference Papers, 2024
2024
-
[27]
Bevformer: learning bird’s-eye-view repre- sentation from lidar-camera via spatiotemporal 11 transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view repre- sentation from lidar-camera via spatiotemporal 11 transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[28]
Creativity in llm-based multi-agent systems: A survey.Proc
Yi-Cheng Lin et al. Creativity in llm-based multi-agent systems: A survey.Proc. Empir- ical Methods in Natural Language Processing (EMNLP), 2025
2025
-
[29]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Yaron Lipman, Ricky TQ Chen, Heli Ben- Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[30]
Rectified diffusion: Straight- ness is not your need in rectified flow.Proc
Fu-Yun Liu et al. Rectified diffusion: Straight- ness is not your need in rectified flow.Proc. International Conf. Learning Representations (ICLR), 2025
2025
-
[31]
Jiwen Liu, Shujuan Li, Zhixue Fang, Xiao- han Li, Yan Zhou, Zijie Meng, Zhimin Zhang, Yawen Luo, Guoxin Zhang, Yu-Shen Liu, et al. Omnidirector: General multi-shot cam- era cloning without cross-paired data.arXiv preprint arXiv:2606.13432, 2026
Pith/arXiv arXiv 2026
-
[32]
Yichen Liu et al. Cvd-storm: Cross-view video diffusion with spatial-temporal reconstruction model for autonomous driving.arXiv preprint arXiv:2510.07944, 2025
arXiv 2025
-
[33]
Synpo: Boosting training-free few-shot medical segmentation via high-quality negative prompts
Yufei Liu, Haoke Xiao, Jiaxing Chai, Yongcun Zhang, Rong Wang, Zijie Meng, and Zhiming Luo. Synpo: Boosting training-free few-shot medical segmentation via high-quality negative prompts. InInternational Conference on Med- ical Image Computing and Computer-Assisted Intervention, pages 594–603. Springer, 2025
2025
-
[34]
Unleash- ing generalization of end-to-end autonomous driving with controllable long video generation
Enhui Ma, Lijun Zhou, Tao Tang, Zhan Zhang, Dong Han, Junpeng Jiang, Kun Zhan, Peng Jia, Xianpeng Lang, Haiyang Sun, et al. Unleash- ing generalization of end-to-end autonomous driving with controllable long video generation. arXiv preprint arXiv:2406.01349, 2024
arXiv 2024
-
[35]
Jianbiao Mei, Tao Hu, Xuemeng Yang, Licheng Wen, Yu Yang, Tiantian Wei, Yukai Ma, Min Dou, Botian Shi, and Yong Liu. Dreamforge: Motion-aware autoregressive video generation for multi-view driving scenes.arXiv preprint arXiv:2409.04003, 2024
arXiv 2024
-
[36]
Zijie Meng. Decoupling semantics from distor- tions: Multi-scale two-stream vision-language alignment for ai-generated image quality assess- ment, 2026. URL https://arxiv.org/abs/ 2606.16799
arXiv 2026
-
[37]
Orpaint: a zero-shot inpainting model for oracle bone inscription rub- bings with visual mamba block.Science China Information Sciences, 68(8):189102, 2025
Zijie Meng, Yuanze Zeng, Xiang Chang, Tian- shuo Xu, Fei Chao, Xixin Cao, Changjing Shang, and Qiang Shen. Orpaint: a zero-shot inpainting model for oracle bone inscription rub- bings with visual mamba block.Science China Information Sciences, 68(8):189102, 2025
2025
-
[38]
Make a game: A novel paradigm for interactive game rendering
Zijie Meng, Jinming Che, Bingcai Wei, and Xixin Cao. Make a game: A novel paradigm for interactive game rendering. InICASSP 2026- 2026 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), pages 1026–1030. IEEE, 2026
2026
-
[39]
Zijie Meng, Jiwen Liu, Yufei Liu, Chengzhuo Tong, Xiaoqiang Liu, Yuanxing Zhang, Yu- long Xu, and Pengfei Wan. Argus: Stacked multi-view identity mosaic injection for subject- preserving video generation.arXiv preprint arXiv:2606.11670, 2026
Pith/arXiv arXiv 2026
-
[40]
T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models.Proc
Chong Mou et al. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models.Proc. AAAI Conf. Artificial Intelligence (AAAI), 2024
2024
-
[41]
Color transfer be- tween images.IEEE Computer Graphics and Applications, 21(5):34–41, 2001
Erik Reinhard, Michael Adhikhmin, Bruce Gooch, and Peter Shirley. Color transfer be- tween images.IEEE Computer Graphics and Applications, 21(5):34–41, 2001
2001
-
[42]
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A con- trollable multi-view generative world model for autonomous driving.arXiv preprint arXiv:2503.20523, 2025
Pith/arXiv arXiv 2025
-
[43]
Editduet: A multi-agent system for video editing.arXiv preprint, 2025
Marcelo Sandoval-Castaneda et al. Editduet: A multi-agent system for video editing.arXiv preprint, 2025
2025
-
[44]
Directorllm for human- centric video generation.arXiv preprint arXiv:2412.14484, 2024
Kunpeng Song et al. Directorllm for human- centric video generation.arXiv preprint arXiv:2412.14484, 2024. 12
arXiv 2024
-
[45]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
Pith/arXiv arXiv 2025
-
[46]
et al. Wang. Geniedrive: Towards physics-aware driving world model with 4d occupancy guided video generation.Proc. IEEE/CVF Conf. Com- puter Vision and Pattern Recognition (CVPR), 2026
2026
-
[47]
Haiguang Wang, Daqi Liu, et al. Mila: Multi- view intensive-fidelity long-term video genera- tion world model for autonomous driving.arXiv preprint arXiv:2503.15875, 2025
arXiv 2025
-
[48]
Kaiyi Wang et al. Genmac: Compositional text- to-video generation with multi-agent collabora- tion.arXiv preprint arXiv:2412.04440, 2024
arXiv 2024
-
[49]
Cine- master: A 3d-aware and controllable framework for cinematic text-to-video generation
Qinghe Wang, Yawen Luo, Xiaoyu Shi, Xu Jia, Huchuan Lu, Tianfan Xue, Xintao Wang, Pengfei Wan, Di Zhang, and Kun Gai. Cine- master: A 3d-aware and controllable framework for cinematic text-to-video generation. InPro- ceedings of the Special Interest Group on Com- puter Graphics and Interactive Techniques Con- ference Conference Papers, pages 1–10, 2025
2025
-
[50]
Drive- dreamer: Towards real-world-drive world mod- els for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drive- dreamer: Towards real-world-drive world mod- els for autonomous driving. InEuropean confer- ence on computer vision, pages 55–72. Springer, 2024
2024
-
[51]
Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recog- nition, pages 14749–14759, 2024
2024
-
[52]
Robust single image sand removal by leveraging uncertainty- aware sam priors and prompt learning with re- fined perceptual loss
Bingcai Wei, Hui Liu, Chuang Qian, Zijian Li, Wangyu Wu, and Zijie Meng. Robust single image sand removal by leveraging uncertainty- aware sam priors and prompt learning with re- fined perceptual loss. InProceedings of the 33rd ACM International Conference on Multimedia, pages 4932–4941, 2025
2025
-
[53]
Panacea: Panoramic and controllable video gen- eration for autonomous driving
Yuqing Wen, Yucheng Zhao, Yingfei Liu, Fan Jia, Yanhui Wang, Chong Luo, Chi Zhang, Tian- cai Wang, Xiaoyan Sun, and Xiangyu Zhang. Panacea: Panoramic and controllable video gen- eration for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 6902–6912, 2024
2024
-
[54]
et al. Wu. Hollywood town: Long-video genera- tion via cross-modal multi-agent orchestration. arXiv preprint arXiv:2510.22431, 2025
arXiv 2025
-
[55]
Ic-world: In-context genera- tion for shared world modeling.arXiv preprint arXiv:2512.02793, 2025
Fan Wu et al. Ic-world: In-context genera- tion for shared world modeling.arXiv preprint arXiv:2512.02793, 2025
arXiv 2025
-
[56]
Wei Wu, Xi Guo, Weixuan Tang, Tingxuan Huang, Chiyu Wang, Dongyue Chen, and Chen- jing Ding. Drivescape: Towards high-resolution controllable multi-view driving video genera- tion.arXiv preprint arXiv:2409.05463, 2024
arXiv 2024
-
[57]
Generating mul- timodal driving scenes via next-scene prediction
Yanhao Wu, Haoyang Zhang, Tianwei Lin, Lichao Huang, Shujie Luo, Rui Wu, Congpei Qiu, Wei Ke, and Tong Zhang. Generating mul- timodal driving scenes via next-scene prediction. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 6844–6853, 2025. 13
2025
-
[58]
Multiagentesc: A llm-based multi-agent collaboration frame- work for emotional support conversation.Proc
Yangyang Xu, Jinpeng Hu, et al. Multiagentesc: A llm-based multi-agent collaboration frame- work for emotional support conversation.Proc. Empirical Methods in Natural Language Pro- cessing (EMNLP), 2025
2025
-
[59]
Drivingsphere: Building a high-fidelity 4d world for closed-loop simulation.Proc
Tianyi Yan, Dongming Wu, Wencheng Han, et al. Drivingsphere: Building a high-fidelity 4d world for closed-loop simulation.Proc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[60]
Xuemeng Yang, Licheng Wen, Yukai Ma, Jian- biao Mei, Xin Li, Tiantian Wei, Wenjie Lei, Daocheng Fu, Pinlong Cai, Min Dou, et al. Drivearena: A closed-loop generative simula- tion platform for autonomous driving.arXiv preprint arXiv:2408.00415, 2024
arXiv 2024
-
[61]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffu- sion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[62]
Yining Yao, Xi Guo, Chenjing Ding, and Wei Wu. Mygo: Consistent and controllable multi- view driving video generation with camera con- trol.arXiv preprint arXiv:2409.06189, 2024
arXiv 2024
-
[63]
Adding conditional control to text-to- image diffusion models.Proc
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to- image diffusion models.Proc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2023
2023
-
[64]
Drivedreamer4d: World models are effective data machines for 4d driving scene rep- resentation
Guosheng Zhao, Chaojun Ni, Xiaofeng Wang, Zheng Zhu, Xueyang Zhang, Yida Wang, Guan Huang, Xinze Chen, Boyuan Wang, Youyi Zhang, et al. Drivedreamer4d: World models are effective data machines for 4d driving scene rep- resentation. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 12015–12026, 2025
2025
-
[65]
Drivedreamer-2: Llm-enhanced world models for diverse driving video genera- tion
Guosheng Zhao, Xiaofeng Wang, Zheng Zhu, Xinze Chen, Guan Huang, Xiaoyi Bao, and Xin- gang Wang. Drivedreamer-2: Llm-enhanced world models for diverse driving video genera- tion. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 10412– 10420, 2025
2025
-
[66]
Drivedreamer-2: Llm- enhanced world models for diverse driving video generation.Proc
Guosheng Zhao et al. Drivedreamer-2: Llm- enhanced world models for diverse driving video generation.Proc. AAAI Conf. Artificial Intelligence (AAAI), 2025
2025
-
[67]
Long-video audio synthesis with multi-agent collaboration.arXiv preprint arXiv:2503.10719, 2025
Yehang Zhao et al. Long-video audio synthesis with multi-agent collaboration.arXiv preprint arXiv:2503.10719, 2025
arXiv 2025
-
[68]
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, et al. Vbench- 2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025. 14 Appendix A ARCHITECTAgent The ARCHITECTconverts a free-form user prompt pusr (optionally paired with a multi...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.