Parameter-Efficient CT Reconstruction via Deep Graph Laplacian Regularization
Pith reviewed 2026-06-29 20:03 UTC · model grok-4.3
The pith
Deep Graph Laplacian Regularization reconstructs low-dose CT scans at 30.70 dB PSNR using only 91,848 parameters and 1,000 training samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
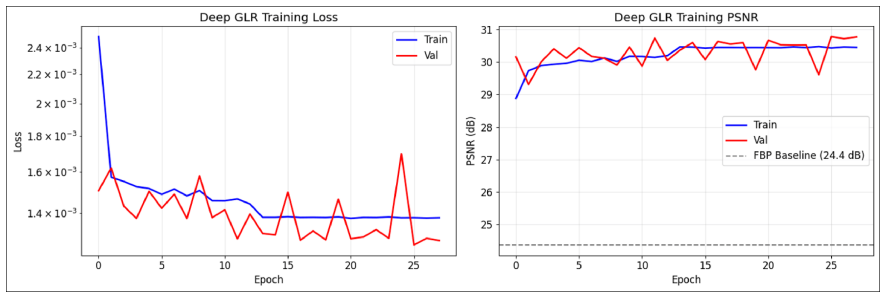
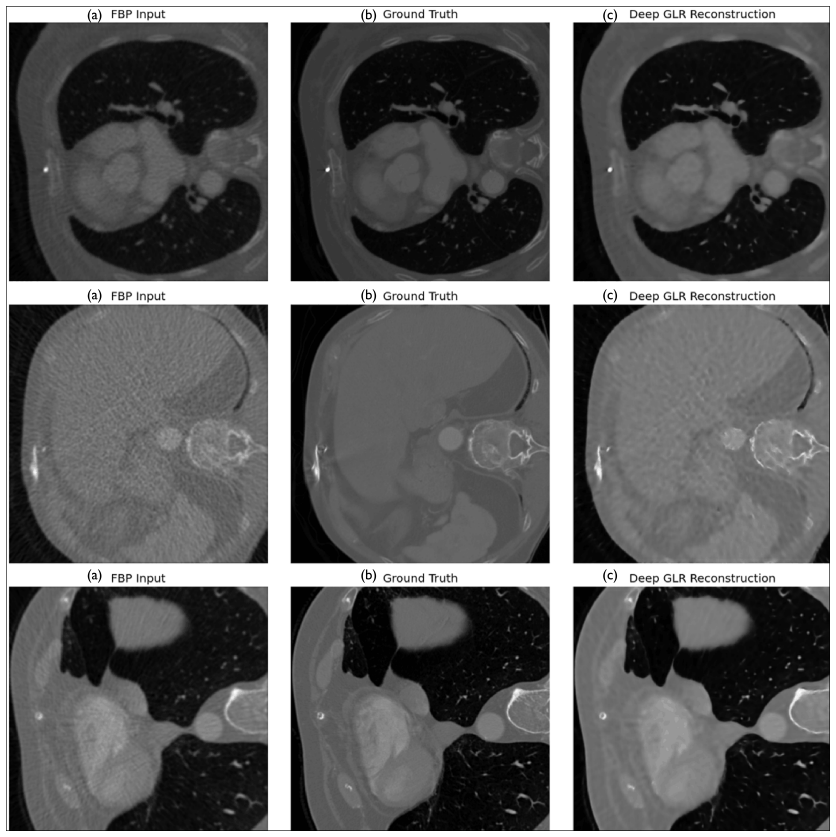
The paper claims that Deep GLR, by integrating quadratic graph regularization into Proximal Forward-Backward Splitting with three lightweight CNN modules, achieves 30.70 dB PSNR on LoDoPaB-CT with 91,848 parameters trained on 1000 samples, providing 5.8 times better parameter efficiency and 30 times better data efficiency per dB improvement compared to benchmark methods.
What carries the argument
Quadratic graph Laplacian regularization inside a Proximal Forward-Backward Splitting framework using three lightweight CNN modules that learn the graph bandwidth parameter.
If this is right
- The approach yields a 6.33 dB PSNR gain over filtered backprojection while keeping parameter count low.
- Training data can be reduced to 2.8 percent of standard sets without losing the efficiency advantage.
- The converged graph bandwidth of 1.25 suggests the model learns meaningful priors rather than overfitting.
- Resource-constrained medical imaging applications can benefit from this efficiency-quality balance despite a remaining gap to full-scale deep learning.
Where Pith is reading between the lines
- Similar graph regularization could extend to other medical imaging inverse problems such as MRI or ultrasound reconstruction.
- Deployment on portable or low-power devices becomes more feasible due to the reduced model size.
- Investigating the interaction between the graph term and the specific CNN modules might reveal further optimizations for closing the performance gap to state-of-the-art methods.
Load-bearing premise
The performance improvements arise from the graph regularization and proximal framework rather than from unstated network design choices or evaluation specifics on the LoDoPaB-CT benchmark.
What would settle it
A controlled experiment removing the graph Laplacian regularization term and retraining the remaining components to measure the resulting PSNR on the same test set would determine if the regularization drives the reported gains.
Figures

read the original abstract
Low-dose computed tomography (LDCT) reconstruction faces a critical tradeoff between reconstruction quality and resource requirements. While recent deep learning methods achieve state-of-the-art performance, they typically rely on over 500,000 parameters trained on large-scale datasets exceeding 35,000 scans. This work investigates whether graph-based regularization can provide meaningful noise reduction under strict resource constraints. We propose Deep Graph Laplacian Regularization (Deep GLR), integrating quadratic graph regularization into a Proximal Forward-Backward Splitting optimization framework with three lightweight CNN modules. Evaluated on the LoDoPaB-CT benchmark, Deep GLR achieves 30.70 dB PSNR, representing a 6.33 dB improvement over filtered backprojection, while using only 91,848 parameters trained on 1000 samples (2.8\% of standard training set). Compared to benchmark methods, this represents 5.8 times better parameter efficiency and 30 times better data efficiency per dB improvement. The learned graph bandwidth parameter ($\epsilon$=1.25) converges to interpretable values, suggesting the method captures meaningful image priors rather than overfitting. While a 13 dB gap remains versus state-of-the-art methods, results demonstrate that graph-based regularization provides a favorable efficiency-quality tradeoff for resource-constrained medical imaging scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Deep Graph Laplacian Regularization (Deep GLR) for low-dose CT reconstruction. It integrates quadratic graph Laplacian regularization into a Proximal Forward-Backward Splitting framework using three lightweight CNN modules. Evaluated on LoDoPaB-CT, it reports 30.70 dB PSNR (6.33 dB above FBP) using 91,848 parameters trained on 1000 samples (2.8% of the standard set), claiming 5.8× better parameter efficiency and 30× better data efficiency per dB gain versus benchmarks. The learned bandwidth ε converges to 1.25, interpreted as capturing meaningful priors, though a 13 dB gap to SOTA remains.
Significance. If the reported efficiency gains and attribution to the graph term hold after verification, the work would demonstrate a useful efficiency-quality tradeoff for resource-constrained medical imaging. The explicit per-dB efficiency ratios and the single learned scalar ε are concrete strengths that could be reproduced if the implementation details are supplied.
major comments (2)
- [Abstract / Methods] The central efficiency claims (5.8× parameter, 30× data) and the 6.33 dB PSNR gain rest on the assumption that these numbers arise specifically from the quadratic graph Laplacian term inside the proximal splitting scheme rather than from unstated CNN architecture choices, sinogram preprocessing, or graph-construction details on the 1000-sample subset. No ablation isolating the graph regularizer or parameter-count breakdown is referenced.
- [Abstract / Results] The statement that ε=1.25 'converges to interpretable values' and 'captures meaningful image priors' is offered as supporting evidence, yet the manuscript provides no independent validation (e.g., sensitivity analysis on held-out data or comparison against a fixed-ε baseline) that would rule out circularity with the fitted model on the same 1000 samples.
minor comments (2)
- [Abstract] The abstract states 'three lightweight CNN modules' without specifying their individual architectures, channel counts, or how the total of 91,848 parameters is obtained; a table or equation listing the parameter breakdown would improve clarity.
- [Abstract] The 13 dB gap to state-of-the-art methods is mentioned but not contextualized with the specific SOTA methods or their parameter counts on the same benchmark; adding this comparison would strengthen the efficiency discussion.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the attribution of our efficiency results. We respond to each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Methods] The central efficiency claims (5.8× parameter, 30× data) and the 6.33 dB PSNR gain rest on the assumption that these numbers arise specifically from the quadratic graph Laplacian term inside the proximal splitting scheme rather than from unstated CNN architecture choices, sinogram preprocessing, or graph-construction details on the 1000-sample subset. No ablation isolating the graph regularizer or parameter-count breakdown is referenced.
Authors: The reported metrics are obtained from the complete Deep GLR pipeline that embeds the quadratic graph Laplacian term inside the proximal forward-backward splitting iteration together with the three lightweight CNN modules (see Sections 2.2–2.3 and 3). The 91,848-parameter count and the 1000-sample training regime are those of the full model; graph construction follows the standard k-NN procedure on image patches described in Section 3.2. We agree that an explicit ablation isolating the graph regularizer would strengthen the causal attribution. In the revised manuscript we will add (i) a detailed parameter-count breakdown table and (ii) an ablation that removes the graph Laplacian term while keeping the CNN modules and optimization framework identical. revision: yes
-
Referee: [Abstract / Results] The statement that ε=1.25 'converges to interpretable values' and 'captures meaningful image priors' is offered as supporting evidence, yet the manuscript provides no independent validation (e.g., sensitivity analysis on held-out data or comparison against a fixed-ε baseline) that would rule out circularity with the fitted model on the same 1000 samples.
Authors: The scalar ε is learned jointly with the CNN weights on the 1000-sample training set and reaches 1.25 at convergence; this value is reported together with the resulting reconstruction quality. We acknowledge that the current manuscript does not supply an independent check against circularity. The revised version will therefore include (i) a sensitivity study of reconstruction PSNR versus ε on a held-out validation subset and (ii) a direct comparison against an otherwise identical model that uses a fixed ε chosen a priori. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper is an empirical proposal of Deep GLR (quadratic graph Laplacian regularization inside Proximal Forward-Backward Splitting with three lightweight CNN modules). Reported metrics (30.70 dB PSNR, 91,848 parameters, ε=1.25) are benchmark measurements on LoDoPaB-CT, not derived quantities. No equation reduces a claimed result to its own inputs by construction, no fitted parameter is relabeled as an independent prediction, and no self-citation chain or uniqueness theorem is invoked to force the architecture. The convergence of ε is presented as supporting evidence of interpretability but is not load-bearing for the efficiency or PSNR claims. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
free parameters (1)
- graph bandwidth epsilon =
1.25
axioms (1)
- domain assumption Quadratic graph Laplacian regularization supplies useful image priors for LDCT reconstruction when integrated into proximal splitting.
Reference graph
Works this paper leans on
-
[1]
Epidemiolog- ical studies of CT scans and cancer risk: the state of the science,
A. Berrington de Gonzalez, E. Pasqual, and L. Veiga, “Epidemiolog- ical studies of CT scans and cancer risk: the state of the science,” Br. J. Radiol., vol. 94, no. 1126, Oct. 2021, Art. no. 20210471, doi: 10.1259/bjr.20210471
-
[2]
Canadian Medical Imaging Inventory 2022-2023: CT,
Canadian Agency for Drugs and Technologies in Health, “Canadian Medical Imaging Inventory 2022-2023: CT,”Can. J. Health Technol., vol. 4, no. 8, Aug. 2024
2022
-
[3]
Deep learning-based algorithms for low-dose CT imaging: A review,
H. Chen, Q. Li, L. Zhou, and F. Li, “Deep learning-based algorithms for low-dose CT imaging: A review,”Eur. J. Radiol., vol. 172, Mar. 2024, Art. no. 111355, doi: 10.1016/j.ejrad.2024.111355
-
[4]
Low-dose CT with deep learning regularization via proximal forward backward splitting,
Q. Ding, G. Chen, X. Zhang, Q. Huang, H. Ji, and H. Gao, “Low-dose CT with deep learning regularization via proximal forward backward splitting,”arXiv preprint arXiv:1909.09773, 2019
arXiv 1909
-
[5]
Low- dose CT with deep learning regularization via proximal forward-backward splitting,
Q. Ding, G. Chen, X. Zhang, Q. Huang, H. Ji, and H. Gao, “Low- dose CT with deep learning regularization via proximal forward-backward splitting,”Phys. Med. Biol., vol. 65, no. 12, Jun. 2020, Art. no. 125009, doi: 10.1088/1361-6560/ab831a
-
[6]
Deep graph Laplacian regu- larization for robust denoising of real images,
J. Zeng, J. Pang, W. Sun, and G. Cheung, “Deep graph Laplacian regu- larization for robust denoising of real images,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), 2019, pp. 1759– 1768, doi: 10.1109/CVPRW.2019.00226
-
[7]
LoDoPaB-CT, a benchmark dataset for low-dose computed tomography reconstruction,
J. Leuschner, M. Schmidt, D. O. Baguer, and P. Maass, “LoDoPaB-CT, a benchmark dataset for low-dose computed tomography reconstruction,” Sci. Data, vol. 8, no. 1, Apr. 2021, Art. no. 109, doi: 10.1038/s41597- 021-00893-z
-
[8]
Unrolling of deep graph total variation for image denoising,
H. Vu, G. Cheung, and Y . C. Eldar, “Unrolling of deep graph total variation for image denoising,” inProc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), 2021, pp. 2050–2054, doi: 10.1109/ICASSP39728.2021.9414453
-
[9]
S. Ramanathan and M. Ramasundaram, “Low-dose CT image reconstruc- tion using vector quantized convolutional autoencoder with perceptual loss,”Sadhana, vol. 48, Mar. 2023, Art. no. 43, doi: 10.1007/s12046- 023-02107-1
-
[10]
Parameter-efficient fine-tuning for medical image analysis: The missed opportunity,
R. Dutt, L. Ericsson, P. Sanchez, S. A. Tsaftaris, and T. Hospedales, “Parameter-efficient fine-tuning for medical image analysis: The missed opportunity,” inProc. 7th Int. Conf. Med. Imag. Deep Learn. (MIDL), 2024, pp. 406–425
2024
-
[11]
Algorithm unrolling: Inter- pretable, efficient deep learning for signal and image processing,
V . Monga, Y . Li, and Y . C. Eldar, “Algorithm unrolling: Inter- pretable, efficient deep learning for signal and image processing,”IEEE Signal Process. Mag., vol. 38, no. 2, pp. 18–44, Mar. 2021, doi: 10.1109/MSP.2020.3016905
-
[12]
Annotation-efficient deep learning for automatic medical image segmentation,
S. Wang et al., “Annotation-efficient deep learning for automatic medical image segmentation,”Nat. Commun., vol. 12, no. 1, Oct. 2021, Art. no. 5915, doi: 10.1038/s41467-021-26216-9
-
[13]
Graph Laplacian regularization for image de- noising: Analysis in the continuous domain,
J. Pang and G. Cheung, “Graph Laplacian regularization for image de- noising: Analysis in the continuous domain,”IEEE Trans. Image Process., vol. 26, no. 4, pp. 1770–1785, Apr. 2017, doi: 10.1109/TIP.2017.2651400
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.