Managing Procedural Memory in LLM Agents: Control, Adaptation, and Evaluation
Pith reviewed 2026-06-26 08:38 UTC · model grok-4.3
The pith
Procedural memory improves LLM agent performance on 382 enterprise tasks by 3.7-6.7 points after one refinement round, with multi-model skills reaching 73.1% cross-model accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Procedural memory delivers consistent gains in industrial workflows: a single refinement round improves aggregate performance by 3.7-6.7 points, while skills evolved from diverse multi-model execution traces achieve 73.1% cross-model test accuracy, outperforming all single-model trace sources. Some skills generalize broadly across tasks and models, whereas others become specialized to role-specific workflows and lose effectiveness under transfer.
What carries the argument
The AFTER benchmark, which tests procedural memory transfer across tasks, roles, and model backbones through controlled settings for local improvement, cross-task transfer, cross-role transfer, and cross-model generalization.
If this is right
- A single refinement round on procedural memory yields measurable performance lifts across multiple industrial workflows.
- Skills built from multi-model execution traces generalize better across different LLM backbones than skills from any single model.
- Broadly generalizing skills can be reused across tasks and roles, while role-specific skills require separate maintenance.
- Production agent platforms can use cross-model accuracy as a selection criterion when evolving reusable skills.
Where Pith is reading between the lines
- If the benchmark tasks capture typical enterprise patterns, organizations could maintain a shared library of refined skills updated from multiple model sources.
- Specialized skills that lose transfer value suggest a need for role-aware skill routing mechanisms in agent systems.
- Cross-model generalization at 73.1% indicates procedural memory could help reduce lock-in to any particular LLM provider.
Load-bearing premise
The 382 tasks and 22 skills in AFTER are representative enough of real enterprise workflows that the measured transfer and generalization effects will hold outside the benchmark.
What would settle it
Running the same refinement and skill-evolution procedures on a fresh collection of enterprise tasks outside the AFTER benchmark and observing no performance gains or transfer benefits.
Figures





read the original abstract
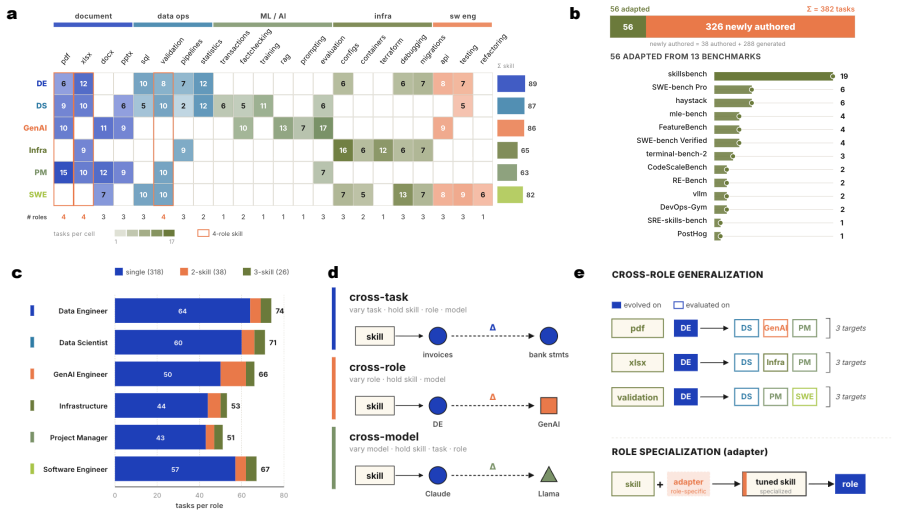
Procedural memory is increasingly used to improve LLM agents on recurring workplace tasks, yet its ability to produce reusable skills remains poorly understood. We introduce AFTER, a benchmark of 382 realistic enterprise tasks spanning six professional roles and 22 procedural skills, designed to evaluate how skills transfer across tasks, roles, and model backbones. The benchmark includes controlled evaluation settings for local improvement, cross-task transfer, cross-role transfer, and cross-model generalization. Experiments show that procedural memory delivers consistent gains in industrial workflows: a single refinement round improves aggregate performance by 3.7-6.7 points, while skills evolved from diverse multi-model execution traces achieve 73.1% cross-model test accuracy, outperforming all single-model trace sources. We further find that some skills generalize broadly across tasks and models, whereas others become specialized to role-specific workflows and lose effectiveness under transfer. These results provide practical guidance for building, evaluating, and deploying procedural memory systems in production agent platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AFTER, a benchmark of 382 realistic enterprise tasks spanning six professional roles and 22 procedural skills, to evaluate procedural memory in LLM agents under controlled settings for local improvement, cross-task/role transfer, and cross-model generalization. It claims that a single refinement round yields 3.7-6.7 point aggregate gains and that skills evolved from diverse multi-model traces reach 73.1% cross-model accuracy (outperforming single-model sources), while some skills generalize broadly and others specialize to roles.
Significance. If the benchmark holds as representative, the results supply actionable guidance on skill evolution and transfer for production agent platforms, including the value of multi-model traces and the distinction between generalizable versus role-specific skills.
major comments (2)
- [Abstract] Abstract: the headline claim that procedural memory 'delivers consistent gains in industrial workflows' is load-bearing on AFTER's 382 tasks and 22 skills being representative of real enterprise settings, yet the manuscript supplies no external anchoring (comparison to deployed logs, expert validation of task distributions, or coverage of long-horizon/noisy conditions).
- [Abstract] Abstract (performance claims): the reported numeric gains (3.7-6.7 points, 73.1% cross-model accuracy) are presented without details on task selection criteria, scoring rubrics, statistical significance testing, or controls for prompt variation, leaving the central empirical results on unexamined experimental design choices.
minor comments (1)
- [Abstract] Abstract: the phrase 'controlled evaluation settings for local improvement, cross-task transfer...' is used without a forward reference to the specific protocol definitions or tables that implement them.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract and empirical presentation. We address each major comment below, acknowledging limitations where the manuscript falls short of ideal standards for benchmark validation and experimental transparency. We propose targeted revisions to strengthen the claims without overstating the work's scope.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that procedural memory 'delivers consistent gains in industrial workflows' is load-bearing on AFTER's 382 tasks and 22 skills being representative of real enterprise settings, yet the manuscript supplies no external anchoring (comparison to deployed logs, expert validation of task distributions, or coverage of long-horizon/noisy conditions).
Authors: We agree that the phrasing 'industrial workflows' implies broader representativeness than the benchmark construction can support. The 382 tasks were synthesized from role descriptions and procedural patterns drawn from public enterprise documentation and expert consultation, but the manuscript indeed provides no direct comparison to proprietary deployed logs or formal expert validation of task distributions. We cannot supply such anchoring without access to confidential production data. We will revise the abstract to qualify the claim as applying 'in the controlled evaluation settings of the AFTER benchmark' and add an explicit limitations paragraph discussing the synthetic nature of the tasks and the absence of long-horizon or noisy real-world conditions. This addresses the concern without misrepresenting the contribution. revision: yes
-
Referee: [Abstract] Abstract (performance claims): the reported numeric gains (3.7-6.7 points, 73.1% cross-model accuracy) are presented without details on task selection criteria, scoring rubrics, statistical significance testing, or controls for prompt variation, leaving the central empirical results on unexamined experimental design choices.
Authors: The full manuscript contains dedicated sections on benchmark construction (including task selection criteria and coverage of the 22 skills), the evaluation protocol (scoring rubrics with human-verified rubrics), and experimental controls (including prompt templates and model backbones). However, the referee is correct that these details are not summarized in the abstract and that statistical significance testing and explicit controls for prompt variation are not highlighted in the reported results. We will expand the abstract with a brief methods clause and add statistical significance results (paired t-tests with p-values) plus prompt-variation ablation tables to the main results section. These changes make the experimental design choices more transparent without altering the reported numbers. revision: yes
Circularity Check
No significant circularity; results are direct empirical measurements
full rationale
The paper introduces the AFTER benchmark (382 tasks, 22 skills) and reports performance numbers from controlled experiments on held-out test sets, including 3.7-6.7 point gains after refinement and 73.1% cross-model accuracy. These are measured outcomes rather than quantities derived from fitted parameters, self-referential equations, or load-bearing self-citations. No derivation chain reduces by construction to the paper's own inputs; the central claims rest on external benchmark execution and transfer evaluations, which are falsifiable outside the reported numbers. The representativeness of AFTER for real workflows is an external validity concern, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 382 tasks adequately sample real enterprise procedural work and the four controlled settings isolate memory effects.
Reference graph
Works this paper leans on
-
[1]
Reflexion: language agents with verbal reinforcement learning , booktitle =
Noah Shinn and Federico Cassano and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao , editor =. Reflexion: language agents with verbal reinforcement learning , booktitle =. 2023 , url =
2023
-
[2]
Andrew Zhao and Daniel Huang and Quentin Xu and Matthieu Lin and Yong. ExpeL:. Thirty-Eighth. 2024 , url =. doi:10.1609/AAAI.V38I17.29936 , timestamp =
-
[3]
From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions , booktitle =
Changle Qu and Sunhao Dai and Xiaochi Wei and Hengyi Cai and Shuaiqiang Wang and Dawei Yin and Jun Xu and Ji. From Exploration to Mastery: Enabling LLMs to Master Tools via Self-Driven Interactions , booktitle =. 2025 , url =
2025
-
[4]
Empowering Large Language Model Agents through Action Learning , journal =
Haiteng Zhao and Chang Ma and Guoyin Wang and Jing Su and Lingpeng Kong and Jingjing Xu and Zhi. Empowering Large Language Model Agents through Action Learning , journal =. 2024 , url =. doi:10.48550/ARXIV.2402.15809 , eprinttype =. 2402.15809 , timestamp =
-
[5]
Le and Denny Zhou and Xinyun Chen , title =
Chengrun Yang and Xuezhi Wang and Yifeng Lu and Hanxiao Liu and Quoc V. Le and Denny Zhou and Xinyun Chen , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[6]
Yutao Yang and Junsong Li and Qianjun Pan and Bihao Zhan and Yuxuan Cai and Lin Du and Jie Zhou and Kai Chen and Qin Chen and Xin Li and Bo Zhang and Liang He , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.01145 , eprinttype =. 2603.01145 , timestamp =
-
[7]
Memp: Exploring Agent Procedural Memory
Runnan Fang and Yuan Liang and Xiaobin Wang and Jialong Wu and Shuofei Qiao and Pengjun Xie and Fei Huang and Huajun Chen and Ningyu Zhang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.06433 , eprinttype =. 2508.06433 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.06433 2025
-
[8]
2026 , doi =
Chenxi Wang and Zhuoyun Yu and Xin Xie and Wuguannan Yao and Runnan Fang and Shuofei Qiao and Kexin Cao and Guozhou Zheng and Xiang Qi and Peng Zhang and Shumin Deng , journal =. 2026 , doi =
2026
-
[9]
arXiv preprint arXiv:2512.18925 , year =
Beyond the Prompt: An Empirical Study of Cursor Rules , author =. arXiv preprint arXiv:2512.18925 , year =. doi:10.48550/arXiv.2512.18925 , url =
-
[10]
2026 , doi =
YanZhao Zheng and ZhenTao Zhang and Chao Ma and YuanQiang Yu and JiHuai Zhu and Yong Wu and Tianze Xu and Baohua Dong and Hangcheng Zhu and Ruohui Huang and Gang Yu , journal =. 2026 , doi =
2026
-
[11]
Graph-of-Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills
Graph of Skills: Dependency-Aware Structural Retrieval for Massive Agent Skills , author =. arXiv preprint arXiv:2604.05333 , year =. doi:10.48550/arXiv.2604.05333 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.05333
-
[12]
SkillReducer: Optimizing LLM Agent Skills for Token Efficiency
Yudong Gao and Zongjie Li and Yuanyuan Yuan and Zimo Ji and Pingchuan Ma and Shuai Wang , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.29919 , eprinttype =. 2603.29919 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.29919 2026
-
[13]
2026 , doi =
Le Chen and Erhu Feng and Yubin Xia and Haibo Chen , journal =. 2026 , doi =
2026
-
[14]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li and Wenbo Chen and Yimin Liu and Shenghan Zheng and Xiaokun Chen and Yifeng He and Yubo Li and Bingran You and Haotian Shen and Jiankai Sun and Shuyi Wang and Qunhong Zeng and Di Wang and Xuandong Zhao and Yuanli Wang and Roey Ben Chaim and Zonglin Di and Yipeng Gao and Junwei He and Yizhuo He and Liqiang Jing and Luyang Kong and Xin Lan and Ji...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.12670 2026
-
[15]
How Well Do Agentic Skills Work in the Wild: Benchmarking
Yujian Liu and Jiabao Ji and Li An and Tommi Jaakkola and Yang Zhang and Shiyu Chang , journal =. How Well Do Agentic Skills Work in the Wild: Benchmarking. 2026 , doi =
2026
-
[16]
WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting , journal =
Olly Styles and Sam Miller and Patricio Cerda. WorkBench: a Benchmark Dataset for Agents in a Realistic Workplace Setting , journal =. 2024 , url =. doi:10.48550/ARXIV.2405.00823 , eprinttype =. 2405.00823 , timestamp =
-
[17]
2026 , doi =
Xiaomeng Hu and Yinger Zhang and Fei Huang and Jianhong Tu and Yang Su and Lianghao Deng and Yuxuan Liu and Yantao Liu and Dayiheng Liu and Tsung-Yi Ho , journal =. 2026 , doi =
2026
-
[18]
2026 , doi =
Bowen Ye and Rang Li and Qibin Yang and Yuanxin Liu and Linli Yao and Hanglong Lv and Zhihui Xie and Chenxin An and Lei Li and Lingpeng Kong and Qi Liu and Zhifang Sui and Tong Yang , journal =. 2026 , doi =
2026
-
[19]
2026 , doi =
Xirui Li and Ming Li and Derry Xu and Ion Stoica and Cho-Jui Hsieh and Tianyi Zhou , journal =. 2026 , doi =
2026
-
[20]
Darwin Godel Machine: Open-Ended Evolution of Self-Improving Agents
Jenny Zhang and Shengran Hu and Cong Lu and Robert T. Lange and Jeff Clune , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.22954 , eprinttype =. 2505.22954 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.22954 2025
-
[21]
Foerster and Jeff Clune and Minqi Jiang and Sam Devlin and Tatiana Shavrina , title =
Jenny Zhang and Bingchen Zhao and Wannan Yang and Jakob N. Foerster and Jeff Clune and Minqi Jiang and Sam Devlin and Tatiana Shavrina , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.19461 , eprinttype =. 2603.19461 , timestamp =
-
[22]
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence , author =. arXiv preprint arXiv:2604.18292 , year =. doi:10.48550/arXiv.2604.18292 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.18292
-
[23]
Wangtao Sun and Xiang Cheng and Jialin Fan and Yao Xu and Xing Yu and Shizhu He and Jun Zhao and Kang Liu , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.14253 , eprinttype =. 2510.14253 , timestamp =
-
[24]
2025 , doi =
Xiao Wu and Ting-Zhu Huang and Liang-Jian Deng and Xiaobing Yu and Yu Zhong and Shangqi Deng and Ufaq Khan and Jianghao Wu and Xiaofeng Liu and Imran Razzak and Xiaojun Chang and Yutong Xie , journal =. 2025 , doi =
2025
-
[25]
A Survey of Self-Evolving Agents: What, When, How, and Where to Evolve on the Path to Artificial Super Intelligence , author =. arXiv preprint arXiv:2507.21046 , year =. doi:10.48550/arXiv.2507.21046 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.21046
-
[26]
Tennison Liu and Mihaela van der Schaar , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.05109 , eprinttype =. 2506.05109 , timestamp =
-
[27]
Huichi Zhou and Siyuan Guo and Anjie Liu and Zhongwei Yu and Ziqin Gong and Bowen Zhao and Zhixun Chen and Menglong Zhang and Yihang Chen and Jinsong Li and Runyu Yang and Qiangbin Liu and Xinlei Yu and Jianmin Zhou and Na Wang and Chunyang Sun and Jun Wang , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.18743 , eprinttype =. 2603.18743 ...
-
[28]
EvoSkill: Automated Skill Discovery for Multi-Agent Systems
Salaheddin Alzubi and Noah Provenzano and Jaydon Bingham and Weiyuan Chen and Tu Vu , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2603.02766 , eprinttype =. 2603.02766 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.02766 2026
-
[29]
2026 , doi =
Hanrong Zhang and Shicheng Fan and Henry Peng Zou and Yankai Chen and Zhenting Wang and Jiayu Zhou and others , journal =. 2026 , doi =
2026
-
[30]
2026 , doi =
Ziyu Ma and Shidong Yang and Yuxiang Ji and Xucong Wang and Yong Wang and Yiming Hu and Tongwen Huang and Xiangxiang Chu , journal =. 2026 , doi =
2026
-
[31]
Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R
Carlos E. Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R. Narasimhan , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[32]
The Twelfth International Conference on Learning Representations,
Gr. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[33]
Fadhel Ayed and Ali Maatouk and Nicola Piovesan and Antonio De Domenico and M. Hermes:. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2411.06490 , eprinttype =. 2411.06490 , timestamp =
-
[34]
Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =
Shuyan Zhou and Frank F. Xu and Hao Zhu and Xuhui Zhou and Robert Lo and Abishek Sridhar and Xianyi Cheng and Tianyue Ou and Yonatan Bisk and Daniel Fried and Uri Alon and Graham Neubig , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[35]
The Thirteenth International Conference on Learning Representations,
Jun Shern Chan and Neil Chowdhury and Oliver Jaffe and James Aung and Dane Sherburn and Evan Mays and Giulio Starace and Kevin Liu and Leon Maksin and Tejal Patwardhan and Aleksander Madry and Lilian Weng , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[36]
2020 , journal =
Scaling Laws for Neural Language Models , author =. 2020 , journal =
2020
-
[37]
Advances in Neural Information Processing Systems , year =
Training Compute-Optimal Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[38]
Forty-first International Conference on Machine Learning , year =
Position: Will we run out of data? Limits of LLM scaling based on human--generated data , author =. Forty-first International Conference on Machine Learning , year =
-
[39]
Frontiers of Computer Science , volume =
A Survey on Large Language Model Based Autonomous Agents , author =. Frontiers of Computer Science , volume =. 2024 , publisher =
2024
-
[40]
arXiv preprint arXiv:2503.21460 , year =
Large Language Model Agent: A Survey on Methodology, Applications and Challenges , author =. arXiv preprint arXiv:2503.21460 , year =
-
[41]
2026 , url =
Mi, Qirui and Ma, Zhijian and Yang, Mengyue and Li, Haoxuan and Wang, Yisen and Zhang, Haifeng and Wang, Jun , journal =. 2026 , url =
2026
-
[42]
Authorea Preprints , year =
Agent Skills from the Perspective of Procedural Memory: A Survey , author =. Authorea Preprints , year =
-
[43]
arXiv preprint arXiv:2410.14826 , year =
Sprig: Improving Large Language Model Performance by System Prompt Optimization , author =. arXiv preprint arXiv:2410.14826 , year =
-
[44]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
A Systematic Survey of Automatic Prompt Optimization Techniques , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , year =
2025
-
[45]
Gomez and Lukasz Kaiser and Illia Polosukhin , volume =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , volume =. Attention Is All You Need , booktitle =. 2017 , url =
2017
-
[46]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[47]
2023 , url =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik Narasimhan and Yuan Cao , booktitle =. 2023 , url =
2023
-
[48]
ChatDev: Communicative agents for software development
Chen Qian and Wei Liu and Hongzhang Liu and Nuo Chen and Yufan Dang and Jiahao Li and Cheng Yang and Weize Chen and Yusheng Su and Xin Cong and Juyuan Xu and Dahai Li and Zhiyuan Liu and Maosong Sun , booktitle =. 2024 , publisher =. doi:10.18653/v1/2024.acl-long.810 , url =
-
[49]
Journal of Machine Learning Research , volume =
Scaling Instruction-Finetuned Language Models , author =. Journal of Machine Learning Research , volume =. 2024 , url =
2024
-
[50]
Po. Active Instruction Tuning: Improving Cross-Task Generalization by Training on Prompt Sensitive Tasks , booktitle =. 2023 , url =. doi:10.18653/V1/2023.EMNLP-MAIN.112 , timestamp =
-
[51]
Anwoy Chatterjee and H. S. V. N. S. Kowndinya Renduchintala and Sumit Bhatia and Tanmoy Chakraborty , title =. Trans. Assoc. Comput. Linguistics , volume =. 2025 , url =. doi:10.1162/TACL.A.42 , timestamp =
-
[52]
American Journal of Physics , volume=
Interactive-engagement versus traditional methods: A six-thousand-student survey of mechanics test data for introductory physics courses , author=. American Journal of Physics , volume=. 1998 , publisher=
1998
-
[53]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng and Jeff Da and Edwin Pan and Yannis Yiming He and Charles Ide and Kanak Garg and Niklas Lauffer and Andrew Park and Nitin Pasari and Chetan Rane and Karmini Sampath and Maya Krishnan and Srivatsa Kundurthy and Sean Hendryx and Zifan Wang and Vijay Bharadwaj and Jeff Holm and Raja Aluri and Chen Bo Calvin Zhang and Noah Jacobson and Bing Liu an...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.16941 2025
-
[54]
The Fourteenth International Conference on Learning Representations,
Qixing Zhou and Jiacheng Zhang and Haiyang Wang and Rui Hao and Jiahe Wang and Minghao Han and Yuxue Yang and Shuzhe Wu and Feiyang Pan and Lue Fan and Dandan Tu and Zhaoxiang Zhang , title =. The Fourteenth International Conference on Learning Representations,. 2026 , url =
2026
-
[55]
Merrill and Alexander G
Mike A. Merrill and Alexander G. Shaw and Nicholas Carlini and Boxuan Li and Harsh Raj and Ivan Bercovich and Lin Shi and others , title =. The Fourteenth International Conference on Learning Representations,. 2026 , eprinttype =
2026
-
[56]
Proceedings of the 42nd International Conference on Machine Learning,
Hjalmar Wijk and Tao Lin and Joel Becker and Sami Jawhar and Neev Parikh and Thomas Broadley and Lawrence Chan and Michael Chen and Josh Clymer and Jai Dhyani and Elena Ericheva and Katharyn Garcia and Brian Goodrich and Nikola Jurkovic and Holden Karnofsky and Megan Kinniment and Aron Lajko and Seraphina Nix and Lucas Sato and William Saunders and Maksym...
2025
-
[57]
The Fourteenth International Conference on Learning Representations,
Yuheng Tang and Kaijie Zhu and Bonan Ruan and Chuqi Zhang and Michael Yang and Hongwei Li and Suyue Guo and Tianneng Shi and Zekun Li and Christopher Kruegel and Giovanni Vigna and Dawn Song and William Yang Wang and Lun Wang and Yangruibo Ding and Zhenkai Liang and Wenbo Guo , title =. The Fourteenth International Conference on Learning Representations,....
2026
-
[58]
Gonzalez and Hao Zhang and Ion Stoica , title =
Woosuk Kwon and Zhuohan Li and Siyuan Zhuang and Ying Sheng and Lianmin Zheng and Cody Hao Yu and Joseph E. Gonzalez and Hao Zhang and Ion Stoica , title =. Proceedings of the 29th Symposium on Operating Systems Principles (. 2023 , doi =
2023
-
[59]
CodeScaleBench , author =
-
[60]
SRE-skills-bench , author =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.