OmniMem: Perturbation-aware Memory Compression for Streaming Audio-Visual LLMs
Pith reviewed 2026-06-29 16:54 UTC · model grok-4.3
The pith
OmniMem compresses KV caches in audio-visual LLMs by allocating memory separately to visual and audio tokens and selecting non-redundant states through perturbation awareness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OmniMem shows that modality-aware allocation combined with perturbation-aware selection of KV states produces more compact memory footprints than uniform compression while preserving the long-range understanding required for audio-visual video tasks. The framework therefore allows streaming inference on extended video sequences without proportional growth in memory usage.
What carries the argument
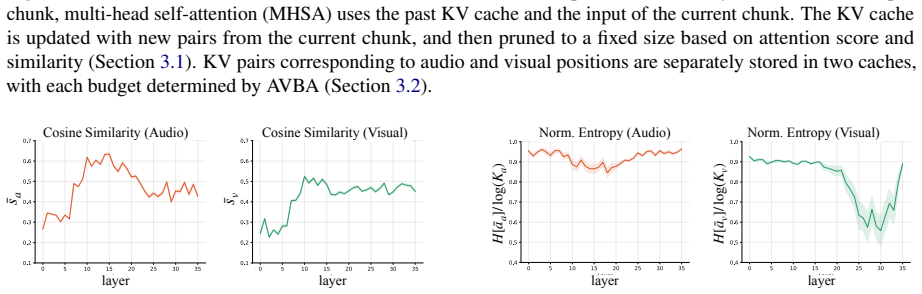
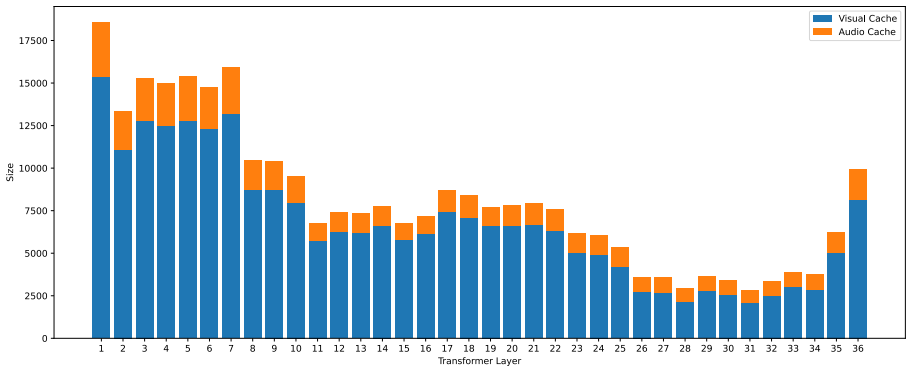
modality-aware memory allocation paired with perturbation-aware memory selection, which separately budgets visual and audio contexts and retains only those KV states whose removal would most change the model's predictions.
If this is right
- Longer video sequences become feasible under fixed GPU memory limits.
- Audio and visual information remain balanced even when their token counts differ by orders of magnitude.
- Fine-tuning under the compression budget further improves retained information density.
- The same selection logic can be applied at inference time without retraining the base model.
Where Pith is reading between the lines
- The same perturbation criterion might extend to other multimodal settings such as text-plus-image or speech-plus-text models that also face token imbalance.
- If perturbation scores correlate with semantic importance, they could serve as a general diagnostic for what information the model actually uses during long-context reasoning.
- Budget-aware fine-tuning may reduce the need for ever-larger context windows by teaching models to compress their own histories more effectively.
Load-bearing premise
Perturbation-aware selection can reliably keep the most informative non-redundant KV states and that splitting memory between modalities will resolve visual-audio imbalance without creating new failure modes.
What would settle it
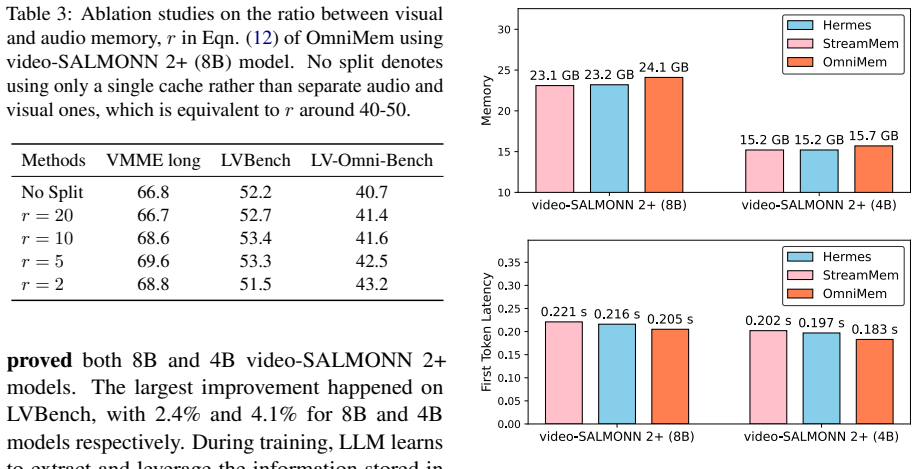
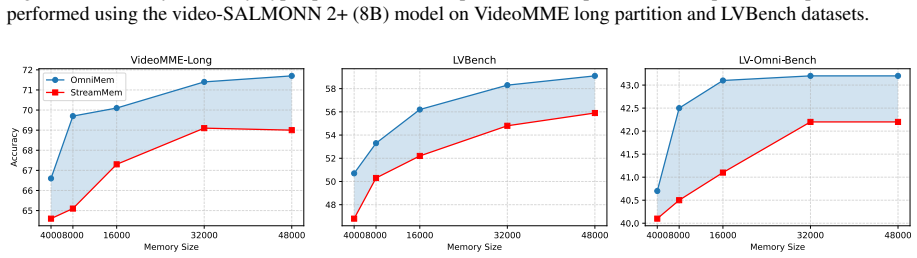
A controlled experiment that applies the same memory budget to long video inputs and finds that OmniMem produces lower accuracy than uniform compression baselines on VideoMME Long or LVBench would falsify the central claim.
Figures

read the original abstract
Audio-visual large language models (LLMs) hold strong promise for long-form video understanding, yet their long-video inference is fundamentally limited by the linear growth of video tokens and key-value (KV) caches. We present OmniMem, a memory-efficient streaming framework designed specifically for audio-visual LLMs. Unlike existing compression methods that treat all tokens uniformly, OmniMem introduces a modality-aware memory allocation strategy that separately manages visual and audio contexts, addressing the severe token imbalance between the two modalities. OmniMem further preserves informative and non-redundant KV states through perturbation-aware memory selection, enabling compact memory without sacrificing long-range understanding. To strengthen compression under realistic deployment constraints, we also explore budget-aware fine-tuning, which encourages the model to consolidate useful information into retained memory. Experiments on VideoMME Long, LVBench, and LVOmniBench with video-SALMONN 2+ and Qwen-2.5-Omni show that OmniMem consistently improves over strong training-free compression baselines by 2-4% absolute accuracy under the same memory budgets, with an additional 1-2% gain after fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniMem, a memory-efficient streaming framework for audio-visual LLMs. It introduces a modality-aware memory allocation strategy to separately manage visual and audio contexts (addressing token imbalance) and a perturbation-aware memory selection method to retain informative, non-redundant KV states. The framework also explores budget-aware fine-tuning. Experiments on VideoMME Long, LVBench, and LVOmniBench using video-SALMONN 2+ and Qwen-2.5-Omni report 2-4% absolute accuracy gains over strong training-free compression baselines under identical memory budgets, plus an additional 1-2% after fine-tuning.
Significance. If the empirical gains are robustly validated, the work would offer a practical contribution to long-form audio-visual understanding by mitigating KV cache growth in streaming settings. The modality-aware allocation directly targets a known multi-modal imbalance, and the perturbation-aware selection provides a mechanism for preserving long-range dependencies under compression. The multi-benchmark, multi-model evaluation strengthens the case for applicability.
major comments (1)
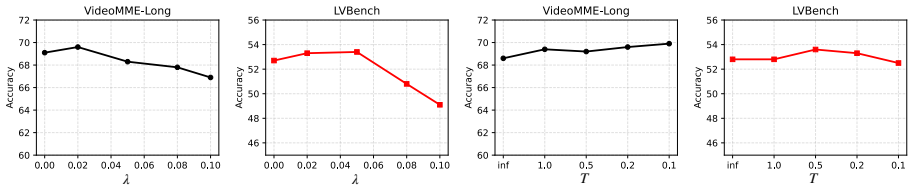
- [Abstract] Abstract: The central empirical claim of consistent 2-4% accuracy improvements (plus 1-2% post-fine-tuning) is presented without implementation details on the perturbation-aware selection criterion, the precise memory budget allocations per modality, ablation studies isolating each component, or error analysis. This absence makes it impossible to determine whether the reported gains are attributable to the proposed mechanisms or to uncontrolled variables in baseline comparisons.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive comment on the abstract. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of consistent 2-4% accuracy improvements (plus 1-2% post-fine-tuning) is presented without implementation details on the perturbation-aware selection criterion, the precise memory budget allocations per modality, ablation studies isolating each component, or error analysis. This absence makes it impossible to determine whether the reported gains are attributable to the proposed mechanisms or to uncontrolled variables in baseline comparisons.
Authors: Abstracts are intentionally concise and high-level; they are not the venue for implementation specifics, precise allocations, full ablations, or error analysis, which are provided in the main manuscript (modality-aware allocation in Sec. 3.1, perturbation-aware selection in Sec. 3.2, ablations isolating components in Sec. 4.2, and error analysis in Sec. 4.3). Baseline comparisons control for identical memory budgets as stated in Sec. 4.1. We can revise the abstract to add one sentence briefly naming the two core mechanisms if space permits, but the detailed validation remains in the body. revision: partial
Circularity Check
No significant circularity: empirical performance claims only
full rationale
The paper's central claims are direct experimental measurements of accuracy improvements (2-4% over baselines, plus 1-2% post-fine-tuning) on public benchmarks (VideoMME Long, LVBench, LVOmniBench) using specific models. No derivation chain, first-principles predictions, fitted parameters renamed as outputs, or self-citation load-bearing premises are present in the abstract or described claims. The modality-aware allocation and perturbation-aware selection are presented as engineering mechanisms evaluated empirically, not as quantities derived by construction from their own definitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Audio-visual LLMs are limited by linear growth of video tokens and KV caches during long-video inference.
- ad hoc to paper Separate management of visual and audio contexts addresses severe token imbalance between modalities.
invented entities (1)
-
perturbation-aware memory selection
no independent evidence
Reference graph
Works this paper leans on
-
[1]
StreamMem: Query-Agnostic KV Cache Memory for Streaming Video Understanding , author =. arXiv:2508.15717 , year =
-
[2]
2024 , journal=
StreamingBench: Assessing the Gap for MLLMs to Achieve Streaming Video Understanding , author=. 2024 , journal=
2024
-
[3]
StreamKV: Streaming Video Question-Answering with Segment-based KV Cache Retrieval and Compression , author =. arXiv:2511.07278 , year =
-
[4]
InfiniPot-V: Memory-Constrained KV Cache Compression for Streaming Video Understanding , author =. Proc. NeurIPS 2025 , year =
2025
-
[5]
2026 , booktitle =
HERMES: KV Cache as Hierarchical Memory for Efficient Streaming Video Understanding , author=. 2026 , booktitle =
2026
-
[6]
video-SALMONN 2: Caption-Enhanced Audio-Visual Large Language Models , author =. arXiv:2506.15220 , year =
-
[7]
Qwen2.5-Omni Technical Report , author =. arXiv:2503.20215 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis , author =. arXiv:2405.21075 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
LVBench: An Extreme Long Video Understanding Benchmark
LVBench: An Extreme Long Video Understanding Benchmark , author =. arXiv:2406.08035 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs , author =
-
[11]
2025 , booktitle=
StreamForest: Efficient Online Video Understanding with Persistent Event Memory , author=. 2025 , booktitle=
2025
-
[12]
2026 , booktitle=
video-SALMONN S: Memory-Enhanced Streaming Audio-Visual LLM , author=. 2026 , booktitle=
2026
-
[13]
2025 , journal=
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling , author=. 2025 , journal=
2025
-
[14]
Squeezed Attention: Accelerating Long Context Length LLM Inference , author=. arXiv:2411.09688 , year=
-
[15]
2025 , journal=
LAVa: Layer-wise KV Cache Eviction with Dynamic Budget Allocation , author=. 2025 , journal=
2025
-
[16]
2025 , journal=
EvolKV: Evolutionary KV Cache Compression for LLM Inference , author=. 2025 , journal=
2025
-
[17]
Shangzhe Di and Zhelun Yu and Guanghao Zhang and Haoyuan Li and Tao Zhong and Hao Cheng and Bolin Li and Wanggui He and Fangxun Shu and Hao Jiang , title =. arXiv preprint arXiv:2503.00540 , year =
-
[18]
Long Context Transfer from Language to Vision
Long Context Transfer from Language to Vision , author=. arXiv preprint arXiv:2406.16852 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Kim, Hyunwoo and Soran, Bilge and Krishnamoorthi, Raghuraman and Elhoseiny, Mohamed and Chandra, Vikas , journal=
Shen, Xiaoqian and Xiong, Yunyang and Zhao, Changsheng and Wu, Lemeng and Chen, Jun and Zhu, Chenchen and Liu, Zechun and Xiao, Fanyi and Varadarajan, Balakrishnan and Bordes, Florian and Liu, Zhuang and Xu, Hu and J. Kim, Hyunwoo and Soran, Bilge and Krishnamoorthi, Raghuraman and Elhoseiny, Mohamed and Chandra, Vikas , journal=
-
[20]
Shu, Yan and Zhang, Peitian and Liu, Zheng and Qin, Minghao and Zhou, Junjie and Huang, Tiejun and Zhao, Bo , journal=
-
[21]
CVPR , year=
StreamingTOM: Streaming Token Compression for Efficient Video Understanding , author=. CVPR , year=
-
[22]
Enxin Song and Wenhao Chai and Guanhong Wang and Yucheng Zhang and Haoyang Zhou and Feiyang Wu and Haozhe Chi and Xun Guo and Tian Ye and Yanting Zhang and Yan Lu and Jenq-Neng Hwang and Gaoang Wang , year=
-
[23]
2024 , eprint=
LongVILA: Scaling Long-Context Visual Language Models for Long Videos , author=. 2024 , eprint=
2024
-
[24]
Liu, Xiangrui and Shu, Yan and Liu, Zheng and Li, Ao and Tian, Yang and Zhao, Bo , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.