Guided Action Flow: Q-Guided Inference for Flow-Matching Vision-Language-Action Policies
Pith reviewed 2026-07-03 11:46 UTC · model grok-4.3
The pith
A learned action-chunk critic can guide the reverse-time sampler of a frozen flow-matching VLA policy to raise task success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
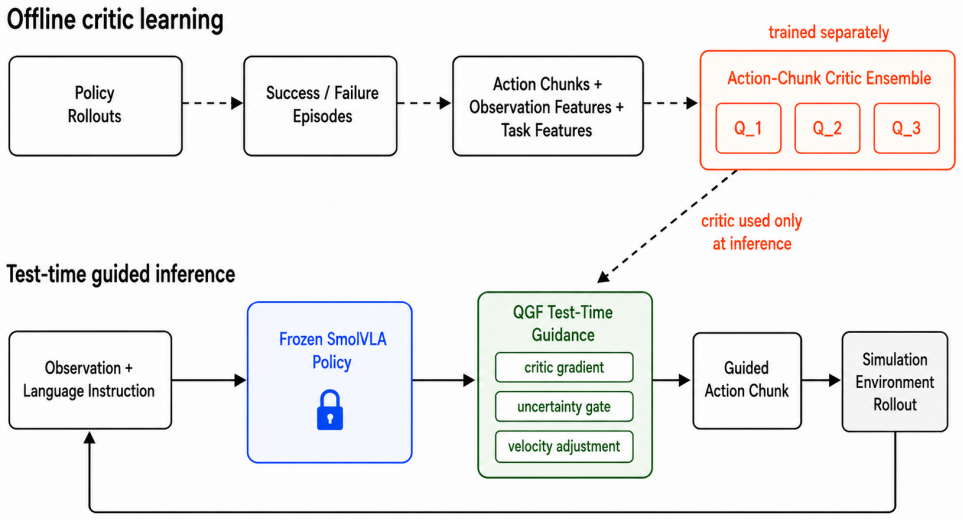
Guided Action Flow keeps a pretrained flow-matching VLA policy frozen and uses a learned action-chunk critic, trained from success and failure rollouts, to guide its reverse-time flow sampler through action gradients. The critic may also condition on task-description features extracted from the policy's own language pathway. On LIBERO tasks this produces measurable success-rate gains without any policy weight updates.
What carries the argument
Action-chunk critic that supplies gradients to steer the reverse-time flow sampler of a frozen flow-matching VLA policy.
If this is right
- Test-time guidance becomes possible for any frozen flow-matching VLA without retraining.
- Single-task critics produce larger gains than multi-family critics on the evaluated tasks.
- Critic generalization and uncertainty-aware guidance remain the main performance bottlenecks.
- The same critic can be conditioned on task-description features already present in the base policy.
Where Pith is reading between the lines
- The method could be tested on flow-matching policies outside the SmolVLA family to check transfer.
- Adding explicit uncertainty estimates to the critic might reduce the modest held-out gains observed.
- If the critic can be trained from simulation rollouts instead of real ones, deployment cost would drop.
Load-bearing premise
A critic trained only on real success and failure rollouts can reliably improve the frozen policy's sampler without introducing instability or needing policy updates.
What would settle it
Running the guided sampler on the same LIBERO tasks and observing success rates equal to or lower than the unguided baseline.
Figures
read the original abstract
Flow-matching vision-language-action policies generate robot action chunks through an iterative transport process, creating an opportunity for test-time guidance without retraining the base policy. We study this opportunity in Guided Action Flow, an inference-time framework that keeps a pretrained SmolVLA policy frozen and uses a learned action-chunk critic to guide its reverse-time flow sampler. The critic is trained from real success and failure rollouts, can condition on task-description features from the frozen SmolVLA language pathway, and is used only through action gradients during sampling. We evaluate the approach on LIBERO manipulation tasks. A single-task critic improves success from 68.0% to 82.0% on one seed window and from 82.0% to 86.0% on another. A multi-family task-description critic improves validation success from 46.0% to 56.0%, while the locked held-out test gain is positive but modest, from 65.0% to 67.5%. These results support the feasibility of Q-guided inference for frozen flow-matching VLA policies, while showing that critic generalization and uncertainty-aware guidance remain the central bottlenecks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Guided Action Flow, an inference-time framework that keeps a pretrained SmolVLA flow-matching VLA policy frozen and uses a separately trained action-chunk critic (conditioned on language features) to steer its reverse-time sampler via action gradients. The critic is learned from real success/failure rollouts. On LIBERO tasks the approach reports success-rate gains from 68.0% to 82.0% (single-task critic, one seed window), 82.0% to 86.0% (another window), 46.0% to 56.0% (multi-family validation), and a smaller held-out test lift from 65.0% to 67.5%.
Significance. If the central feasibility claim holds, the work demonstrates that test-time Q-guidance can improve frozen flow-matching VLA policies without policy updates, a practically relevant capability for robotics. The explicit identification of critic generalization and uncertainty-aware guidance as remaining bottlenecks is a useful contribution. The modest held-out gains, however, indicate that the method is not yet robust across task families.
major comments (3)
- [Abstract and §5] Abstract and §5 (Experimental Results): the reported percentage improvements are presented without accompanying information on number of evaluation trials, statistical significance tests, variance across random seeds, or explicit baseline definitions. This information is load-bearing for the feasibility claim and must be supplied.
- [§4 and §3.2] §4 (Guidance Mechanism) and §3.2 (Critic Architecture): the central assumption that a critic trained solely on terminal success/failure outcomes supplies informative gradients at every intermediate reverse-time step of the flow sampler is not accompanied by supporting analysis (e.g., gradient-norm statistics, trajectory deviation metrics, or ablation on guidance scale). Without such evidence the risk of off-manifold trajectories or instability remains unaddressed.
- [§6] §6 (Multi-Task Experiments): the held-out test improvement is only 2.5 percentage points (65.0% → 67.5%). This modest gain, contrasted with larger validation gains, directly limits the strength of the generalization claim and requires further analysis or mitigation strategies.
minor comments (2)
- [§3.2] Clarify the precise mathematical form of the critic loss and the exact conditioning pathway on SmolVLA language features.
- [Figures 3–5] Add error bars or confidence intervals to all success-rate plots and tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions that will be incorporated to strengthen the presentation of results, supporting analyses, and discussion of limitations.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experimental Results): the reported percentage improvements are presented without accompanying information on number of evaluation trials, statistical significance tests, variance across random seeds, or explicit baseline definitions. This information is load-bearing for the feasibility claim and must be supplied.
Authors: We agree that these details are essential. In the revised manuscript we will expand §5 to report the number of evaluation trials per task (20 episodes), standard deviations across three random seeds, results of paired statistical significance tests, and an explicit statement that the baseline is the frozen SmolVLA policy without guidance. These additions will be placed in both the abstract and the experimental section. revision: yes
-
Referee: [§4 and §3.2] §4 (Guidance Mechanism) and §3.2 (Critic Architecture): the central assumption that a critic trained solely on terminal success/failure outcomes supplies informative gradients at every intermediate reverse-time step of the flow sampler is not accompanied by supporting analysis (e.g., gradient-norm statistics, trajectory deviation metrics, or ablation on guidance scale). Without such evidence the risk of off-manifold trajectories or instability remains unaddressed.
Authors: We will add the requested supporting analysis. The revision will include gradient-norm statistics computed across sampling steps, trajectory deviation metrics relative to the unguided flow, and an ablation on guidance scale in §4. These new results will directly address concerns about gradient quality and potential instability. revision: yes
-
Referee: [§6] §6 (Multi-Task Experiments): the held-out test improvement is only 2.5 percentage points (65.0% → 67.5%). This modest gain, contrasted with larger validation gains, directly limits the strength of the generalization claim and requires further analysis or mitigation strategies.
Authors: We acknowledge that the modest held-out gain limits the strength of the generalization claim. In the revised §6 we will add per-task breakdowns, explicit discussion of the distribution shift between validation and test families, and a tempered statement of the generalization results. We will also outline mitigation directions such as uncertainty-aware guidance, consistent with the bottlenecks already identified in the conclusion. revision: yes
Circularity Check
No circularity: empirical gains measured on held-out data with separately trained critic
full rationale
The paper reports experimental success-rate improvements from applying a separately trained action-chunk critic (fit only on terminal success/failure rollouts) to guide a frozen SmolVLA flow sampler. Gains are quantified on both validation and locked held-out test splits (e.g., 65.0% to 67.5%), with no equations, uniqueness theorems, or first-principles derivations that reduce to the same fitted quantities by construction. The method description contains no self-citations that bear the central claim, and the results remain falsifiable against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CLIPort: What and where pathways for robotic manipulation,
M. Shridhar, L. Manuelli, and D. Fox, “CLIPort: What and where pathways for robotic manipulation,” 2021. [Online]. Available: https://arxiv.org/abs/2109.12098
-
[2]
Perceiver-actor: A multi-task transformer for robotic manipula- tion,
——, “Perceiver-actor: A multi-task transformer for robotic manipula- tion,” 2022. [Online]. Available: https://arxiv.org/abs/2209.05451
-
[3]
BC-Z: Zero-shot task generalization with robotic imitation learning,
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn, “BC-Z: Zero-shot task generalization with robotic imitation learning,” 2022. [Online]. Available: https: //arxiv.org/abs/2202.02005
-
[4]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,” 2022. [Online]. Available: https://arxiv.org/abs/2212.06817
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finnet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” 2023. [Online]. Available: https://arxiv.org/abs/2307.15818
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yuet al., “Palm-e: An embodied multimodal language model,” 2023. [Online]. Available: https://arxiv.org/abs/2303.03378
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaborationet al., “Open x-embodiment: Robotic learning datasets and rt-x models,” 2023. [Online]. Available: https://arxiv.org/abs/2310.08864
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xuet al., “Octo: An open-source generalist robot policy,” 2024. [Online]. Available: https://arxiv.org/abs/2405.12213
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open-source vision-language-action model,” 2024. [Online]. Available: https://arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “π 0: A vision-language-action flow model for general robot control,” 2024. [Online]. Available: https://arxiv.org/abs/2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine, “Fast: Efficient action tokenization for vision-language-action models,” 2025. [Online]. Available: https: //arxiv.org/abs/2501.09747
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, S. Alibert, M. Cord, T. Wolf, and R. Cadene, “Smolvla: A vision-language-action model for affordable and efficient robotics,” 2025. [Online]. Available: https://arxiv.org/abs/2506.01844
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learning,” 2023. [Online]. Available: https://arxiv.org/abs/2306.03310
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu, “Libero-plus: In-depth robustness analysis of vision-language-action models,” 2025. [Online]. Available: https://arxiv.org/abs/2510.13626
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
LIBERO-PRO: Towards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun, “Libero-pro: Towards robust and fair evaluation of vision-language-action models beyond memorization,” 2025. [Online]. Available: https://arxiv.org/abs/2510.03827
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
X. Tan, N. Bai, H. Gardener, Z. Zhong, L. Zhang, L. Yang, Z. Duan, M. Galeitsiwe, and Z. Tang, “Signvla: A gloss-free vision-language-action framework for real-time sign language-guided robotic manipulation,” 2026. [Online]. Available: https://arxiv.org/abs/ 2602.22514
-
[17]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” 2022. [Online]. Available: https://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Denoising Diffusion Probabilistic Models
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” 2020. [Online]. Available: https://arxiv.org/abs/2006.11239
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[19]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” 2023. [Online]. Available: https://arxiv.org/abs/2303.04137
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Diffusion Models Beat GANs on Image Synthesis
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,” 2021. [Online]. Available: https://arxiv.org/abs/2105.05233
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” 2022. [Online]. Available: https://arxiv.org/abs/2207.12598
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Planning with Diffusion for Flexible Behavior Synthesis
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” 2022. [Online]. Available: https://arxiv.org/abs/2205.09991
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning
Z. Wang, J. J. Hunt, and M. Zhou, “Diffusion policies as an expressive policy class for offline reinforcement learning,” 2022. [Online]. Available: https://arxiv.org/abs/2208.06193
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
P. Hansen-Estruch, I. Kostrikov, M. Janner, J. G. Kuba, and S. Levine, “Idql: Implicit q-learning as an actor-critic method with diffusion policies,” 2023. [Online]. Available: https://arxiv.org/abs/2304.10573
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Test-Time Gradient Guidance of Flow Policies in Reinforcement Learning
Z. Zhou, A. Peng, C. Xu, Q. Li, T. Springenberg, K. Frans, and S. Levine, “Test-time gradient guidance of flow policies in reinforcement learning,” 2026. [Online]. Available: https://arxiv.org/abs/2606.11087
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
H. Zhao, Z. Tang, Z. Li, Y . Dong, Y . Si, M. Lu, and G. Panoutsos, “Real- time object detection and robotic manipulation for agriculture using a yolo-based learning approach,” in2024 IEEE International Conference on Industrial Technology (ICIT). IEEE, Mar 2024, pp. 1–6. [Online]. Available: http://dx.doi.org/10.1109/ICIT58233.2024.10540740
-
[27]
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” 2017. [Online]. Available: https://arxiv.org/abs/1703.06907
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Sim-to-Real Transfer of Robotic Control with Dynamics Randomization
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel, “Sim-to- real transfer of robotic control with dynamics randomization,” 2017. [Online]. Available: https://arxiv.org/abs/1710.06537
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
EPOpt: Learning Robust Neural Network Policies Using Model Ensembles
A. Rajeswaran, S. Ghotra, B. Ravindran, and S. Levine, “EPOpt: Learning robust neural network policies using model ensembles,” 2016. [Online]. Available: https://arxiv.org/abs/1610.01283
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[30]
Robust Adversarial Reinforcement Learning
L. Pinto, J. Davidson, R. Sukthankar, and A. Gupta, “Robust adversarial reinforcement learning,” 2017. [Online]. Available: https: //arxiv.org/abs/1703.02702
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Action Robust Reinforcement Learning and Applications in Continuous Control
C. Tessler, Y . Efroni, and S. Mannor, “Action robust reinforcement learning and applications in continuous control,” 2019. [Online]. Available: https://arxiv.org/abs/1901.09184
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[32]
Disturbance observer-based robust control and its applications: 35th anniversary overview,
E. Sariyildiz, R. Oboe, and K. Ohnishi, “Disturbance observer-based robust control and its applications: 35th anniversary overview,”IEEE Transactions on Industrial Electronics, vol. 67, no. 3, pp. 2042–2053,
2042
-
[33]
Available: https://doi.org/10.1109/TIE.2019.2903752
[Online]. Available: https://doi.org/10.1109/TIE.2019.2903752
-
[34]
Output tracking for uncertain time-delay systems via robust reinforcement learning control,
Z. Tang, J. A. Rossiter, X. Jin, B. Zhang, and G. Panoutsos, “Output tracking for uncertain time-delay systems via robust reinforcement learning control,” in2024 43rd Chinese Control Conference (CCC). IEEE, July 2024, pp. 2219–2226. [Online]. Available: http://dx.doi.org/ 10.23919/CCC63176.2024.10662811
-
[35]
Disturbance observer-based tracking control for roll-to-roll slot die coating systems under gap and pump rate disturbances,
Z. Tang, C. Passmore, A. I. Campbell, J. Howse, J. A. Rossiter, S. Ebbens, and G. Panoutsos, “Disturbance observer-based tracking control for roll-to-roll slot die coating systems under gap and pump rate disturbances,” 2026. [Online]. Available: https://arxiv.org/abs/2601. 08488
2026
-
[37]
Z. Tang, J. A. Rossiter, Y . Dong, and G. Panoutsos, “Reinforcement learning-based output stabilization control for nonlinear systems with generalized disturbances,” in2024 IEEE International Conference on Industrial Technology (ICIT). IEEE, Mar 2024, pp. 1–6. [Online]. Available: http://dx.doi.org/10.1109/ICIT58233.2024.10540609
-
[38]
Z. Tang, J. A. Rossiter, and G. Panoutsos, “A reinforcement learning-based approach for optimal output tracking in uncertain nonlinear systems with mismatched disturbances,” in2024 UKACC 14th International Conference on Control (CONTROL). IEEE, Apr 2024, pp. 169–174. [Online]. Available: http://dx.doi.org/10.1109/ CONTROL60310.2024.10532060
-
[39]
N. Bai, C. P. Chan, Q. Yin, T. Gong, Y . Yan, and Z. Tang, “Deep reinforcement learning optimization for uncertain nonlinear systems via event-triggered robust adaptive dynamic programming,” 2025. [Online]. Available: https://arxiv.org/abs/2512.15735
-
[40]
Hierarchical testing with rabbit optimization for industrial cyber- physical systems,
J. Hu, Z. Tang, X. Jin, B. Zhang, Y . Dong, and X. Huang, “Hierarchical testing with rabbit optimization for industrial cyber- physical systems,”IEEE Transactions on Industrial Cyber-Physical Systems, vol. 3, pp. 472–484, 2025. [Online]. Available: http: //dx.doi.org/10.1109/TICPS.2025.3586988
-
[41]
T. Gong, Y . Xu, Z. Li, Z. Tang, and Z. Ding, “Distributed time- varying optimization with inequality constraints via prescribed-time distributed average tracking,” in2025 44th Chinese Control Conference (CCC). IEEE, July 2025, pp. 2272–2277. [Online]. Available: http://dx.doi.org/10.23919/CCC64809.2025.11179599
-
[42]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu, “Offline reinforcement learning: Tutorial, review, and perspectives on open problems,” 2020. [Online]. Available: https://arxiv.org/abs/2005.01643
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[43]
Conservative q- learning for offline reinforcement learning,
A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q- learning for offline reinforcement learning,” 2020. [Online]. Available: https://arxiv.org/abs/2006.04779
-
[44]
Offline Reinforcement Learning with Implicit Q-Learning
I. Kostrikov, A. Nair, and S. Levine, “Offline reinforcement learning with implicit q-learning,” 2021. [Online]. Available: https: //arxiv.org/abs/2110.06169
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[45]
MOPO: Model-based offline policy optimization,
T. Yu, G. Thomas, L. Yu, S. Ermon, J. Zou, S. Levine, C. Finn, and T. Ma, “MOPO: Model-based offline policy optimization,” 2020. [Online]. Available: https://arxiv.org/abs/2005.13239
-
[46]
Uncertainty-based offline reinforcement learning with diversified q-ensemble,
G. An, S. Moon, J.-H. Kim, and H. O. Song, “Uncertainty-based offline reinforcement learning with diversified q-ensemble,” 2021. [Online]. Available: https://arxiv.org/abs/2110.01548
-
[47]
Lerobot: State-of-the-art machine learning for real-world robotics,
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Aractingi, M. Shukor, D. Aubakirovaet al., “Lerobot: State-of-the-art machine learning for real-world robotics,”
-
[48]
Available: https://github.com/huggingface/lerobot
[Online]. Available: https://github.com/huggingface/lerobot
-
[49]
Residual Reinforcement Learning for Robot Control
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine, “Residual reinforcement learning for robot control,” 2018. [Online]. Available: https://arxiv.org/abs/1812.03201
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.