An Open Multi-Center Whole-Body FDG PET/CT Foundation Model for Tumor Segmentation
Pith reviewed 2026-05-22 07:15 UTC · model grok-4.3
The pith
A multi-center PET/CT foundation model matches full-data lesion segmentation performance using only 10 percent of the labeled training examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pretraining hierarchical UNet-shaped networks on harmonized multi-center FDG PET/CT data via early channel-wise concatenation and a masked autoencoding objective that uses zero-mean imputation together with a weighted global reconstruction loss produces cross-modal representations that support label-efficient downstream tumor segmentation, such that models reach full-data performance on AutoPET lesion segmentation when fine-tuned on only 10 percent of the labeled examples and outperform separated-modality pretraining under 5-shot linear probing.
What carries the argument
Early channel-wise concatenation of PET and CT inputs inside a hierarchical UNet-shaped backbone, combined with masked autoencoding that replaces masked patches by zero-mean imputation and applies a weighted global reconstruction loss to avoid non-physical intensity jumps at boundaries.
If this is right
- Pretrained models reach lesion segmentation performance on AutoPET that is comparable to full supervised training when only 10 percent of the labeled data is available for fine-tuning.
- Joint pretraining on combined PET and CT data produces higher Dice scores than pretraining on each modality separately when evaluated under 5-shot linear probing.
- The open multi-center model reduces the volume of manual annotations required for clinical tumor segmentation tasks.
- Training on harmonized data from multiple public datasets supports generalization across different acquisition protocols and scanners.
Where Pith is reading between the lines
- The observed label efficiency could be tested on segmentation tasks involving other PET tracers or additional anatomical sites to see whether the same data reduction holds.
- If the harmonization step truly removes site biases, the released weights may serve as a practical starting point for quick adaptation at new hospitals that lack large local annotation teams.
- The early-fusion and zero-mean imputation design might be adapted to other paired imaging modalities where one modality supplies anatomical context and the other supplies functional information.
- Representations learned this way could be evaluated on related clinical tasks such as tumor detection, staging, or longitudinal response monitoring to measure broader utility.
Load-bearing premise
Harmonizing the 4,997 scans from four public datasets removes scanner- and protocol-specific biases so the learned features generalize to scans acquired at new clinical sites.
What would settle it
Showing that a model pretrained by this method and then fine-tuned on 10 percent of the AutoPET labels achieves substantially lower Dice scores than a model trained from scratch on the full labeled set would falsify the central label-efficiency claim.
Figures


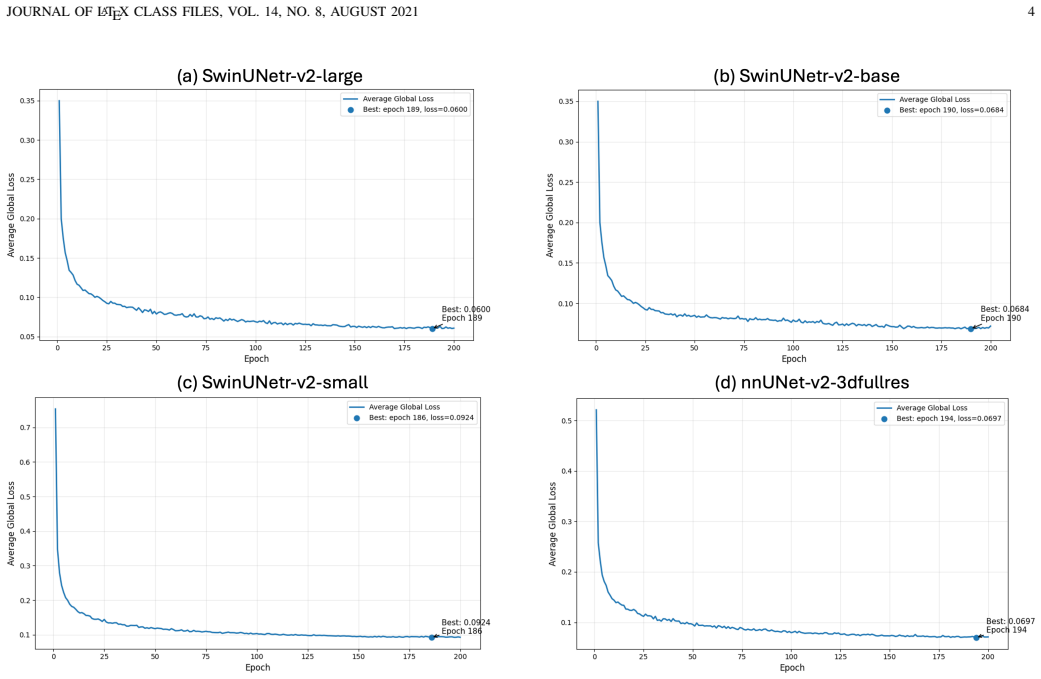


read the original abstract
The synergistic interpretation of anatomical information from computed tomography (CT) and metabolic information from positron emission tomography (PET) is important to oncologic imaging. However, existing deep learning methods for PET/CT remain largely task-specific, are often trained on single-center cohorts, or adopt dual-branch fusion schemes that delay cross-modal interaction and underutilize early spatial correspondence between PET and CT. To address these limitations, we present an open-source, multi-center, whole-body FDG PET/CT foundation model utilizing 4,997 harmonized scans from four public datasets. Our framework employs hierarchical UNet-shaped backbones with early channel-wise concatenation, enabling anatomical and metabolic features to interact from the first embedding layer onward. We further introduce a masked autoencoding objective based on zero-mean imputation, combined with a weighted global reconstruction loss. This design avoids non-physical intensity discontinuities at masked-region boundaries that arise from learnable mask tokens. On downstream AutoPET lesion segmentation, the proposed models demonstrate strong label efficiency: with only 10\% of the labeled training data, they achieve performance comparable to models trained from scratch on the full dataset. Under extreme 5-shot linear probing, joint PET/CT pretraining also achieves higher Dice scores than separated-modality pretraining. This multi-center foundation model demonstrates label efficiency and cross-modality representation learning for PET/CT tumor segmentation. It provides a robust, open-source basis for advancing automated oncologic imaging, significantly reducing the need for large-scale manual annotations in clinical practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an open-source multi-center whole-body FDG PET/CT foundation model pretrained on 4,997 harmonized scans from four public datasets. It employs hierarchical UNet-shaped backbones with early channel-wise PET/CT concatenation and a masked autoencoding objective using zero-mean imputation plus a weighted global reconstruction loss. The central empirical claim is strong label efficiency on downstream AutoPET lesion segmentation: models fine-tuned on only 10% of the labeled training data achieve performance comparable to models trained from scratch on the full dataset, with additional gains shown under 5-shot linear probing versus separated-modality pretraining.
Significance. If the quantitative results and generalization claims hold after addressing the points below, the work would be a useful contribution to automated oncologic imaging by demonstrating reduced annotation burden via multi-center pretraining and early cross-modal fusion. The open release of the model and use of public data are clear strengths that could enable follow-on studies. The label-efficiency result, if supported by ablations and statistical tests, addresses a practical bottleneck in PET/CT segmentation.
major comments (2)
- [Data harmonization / preprocessing] Data harmonization section: the process applied to the 4,997 scans is described at a high level (intensity normalization, resampling, attenuation correction) but provides no quantitative checks for residual scanner- or protocol-specific biases, such as center-wise distribution distances, domain-adversarial validation, or cross-center hold-out performance. This is load-bearing for the central claim because the reported 10% label-efficiency parity on AutoPET could otherwise reflect exploitation of in-distribution signatures rather than learned anatomical-metabolic features that transfer to new clinical sites.
- [Results / AutoPET lesion segmentation] AutoPET downstream experiments: the claim that 10% labeled data yields 'comparable' performance to full-data from-scratch training is stated without reporting exact Dice scores, standard deviations across runs, confidence intervals, or statistical tests (e.g., paired t-test or Wilcoxon). These details are required to evaluate whether the parity is meaningful or within experimental variance, directly affecting the strength of the label-efficiency conclusion.
minor comments (3)
- [Abstract] Abstract states performance gains and label efficiency but supplies no numerical values, error bars, or figure/table references; adding the key Dice scores for the 10% and full-data conditions would improve immediate readability.
- [Methods / pretraining objective] The exact weighting scheme and implementation of the 'weighted global reconstruction loss' combined with zero-mean imputation should be given explicitly (e.g., as an equation) to allow reproduction and to clarify how boundary discontinuities are avoided.
- [Data / references] Ensure all four source datasets are cited with version numbers, license information, and any usage restrictions; also confirm that AutoPET is strictly held out and not part of the pretraining corpus.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the presentation of our multi-center pretraining and label-efficiency results. We address each major comment below and have incorporated revisions to improve transparency and rigor.
read point-by-point responses
-
Referee: [Data harmonization / preprocessing] Data harmonization section: the process applied to the 4,997 scans is described at a high level (intensity normalization, resampling, attenuation correction) but provides no quantitative checks for residual scanner- or protocol-specific biases, such as center-wise distribution distances, domain-adversarial validation, or cross-center hold-out performance. This is load-bearing for the central claim because the reported 10% label-efficiency parity on AutoPET could otherwise reflect exploitation of in-distribution signatures rather than learned anatomical-metabolic features that transfer to new clinical sites.
Authors: We agree that explicit quantitative validation of harmonization is necessary to support claims of cross-center generalization. In the revised manuscript we will add a dedicated subsection with: (1) center-wise intensity histograms and Wasserstein distances before/after harmonization, (2) a domain-adversarial classifier trained to detect residual site signatures on the harmonized data, and (3) a cross-center hold-out experiment in which the pretrained model is evaluated on a held-out public dataset from a fifth center. These results will be reported with quantitative metrics to demonstrate that performance gains arise from transferable anatomical-metabolic features rather than site-specific cues. revision: yes
-
Referee: [Results / AutoPET lesion segmentation] AutoPET downstream experiments: the claim that 10% labeled data yields 'comparable' performance to full-data from-scratch training is stated without reporting exact Dice scores, standard deviations across runs, confidence intervals, or statistical tests (e.g., paired t-test or Wilcoxon). These details are required to evaluate whether the parity is meaningful or within experimental variance, directly affecting the strength of the label-efficiency conclusion.
Authors: We acknowledge that the main text relies on a qualitative statement of comparability. The full experimental results (including per-run Dice scores) exist in our internal logs and supplementary tables; we will move the precise numbers into the main results section. The revision will report mean Dice scores with standard deviations across five independent fine-tuning runs, 95% confidence intervals, and p-values from Wilcoxon signed-rank tests comparing the 10%-data pretrained model against the full-data from-scratch baseline. We will also state the numerical threshold used to define 'comparable' (e.g., within 2% absolute Dice). revision: yes
Circularity Check
No circularity: standard empirical pretraining and fine-tuning on external public datasets
full rationale
The paper presents an empirical foundation model trained via masked autoencoding on 4,997 harmonized scans from four public datasets, then evaluated for label efficiency on the separate AutoPET lesion segmentation task. The central results are performance metrics obtained by training and testing on external benchmarks; no equations, predictions, or uniqueness claims reduce by construction to fitted inputs or self-referential definitions. The harmonization and pretraining steps are described as standard preprocessing and self-supervised learning without load-bearing self-citations that would make the reported 10% label-efficiency result tautological. The derivation chain is self-contained against external data and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss weighting coefficients
axioms (1)
- domain assumption Early channel-wise concatenation of PET and CT allows anatomical and metabolic features to interact from the first embedding layer.
Reference graph
Works this paper leans on
-
[1]
S. Eyuboglu, G. Angus, B. N. Patel, A. Pareek, G. Davidzon, J. Long, J. Dunnmon, and M. P. Lungren, “Multi-task weak supervision enables anatomically-resolved abnormality detection in whole-body fdg-pet/ct,” Nat Commun, vol. 12, no. 1, p. 1880, 2021
work page 2021
-
[2]
Snmmi procedure standard/eanm practice guideline on pediatric 18f-fdg pet/ct for oncology 1.0,
R. Vali, A. Alessio, R. Balza, L. Borgwardt, Z. Bar-Sever, M. Cza- chowski, N. Jehanno, L. Kurch, N. Pandit-Taskar, M. Parisi, R. Lim et al., “Snmmi procedure standard/eanm practice guideline on pediatric 18f-fdg pet/ct for oncology 1.0,”J Nucl Med, vol. 62, no. 1, pp. 99–110, 2021
work page 2021
-
[3]
Ai- driven multi-lesion detection in whole-body fdg pet/ct,
X. Liu, M. Xia, Y . Chemli, G. El Fakhri, C. Liu, and J. Ouyang, “Ai- driven multi-lesion detection in whole-body fdg pet/ct,” inProc SPIE Med Imaging, 2026
work page 2026
-
[4]
Pet/ct based cross-modal deep learning signature to predict occult nodal metastasis in lung cancer,
Y . Zhong, C. Cai, T. Chen, H. Gui, J. Deng, M. Yang, B. Yu, Y . Song, T. Wang, X. Sunet al., “Pet/ct based cross-modal deep learning signature to predict occult nodal metastasis in lung cancer,”Nat Commun, vol. 14, no. 1, p. 7513, 2023
work page 2023
-
[5]
Head and neck tumor segmentation from [18F]F- FDG PET/CT images based on 3D diffusion model,
Y . Dong and K. Gong, “Head and neck tumor segmentation from [18F]F- FDG PET/CT images based on 3D diffusion model,”Phys Med Biol, vol. 69, no. 15, 2024
work page 2024
-
[6]
Developing a pet/ct foundation model for cross-modal anatomical and functional imaging,
Y . Oh, R. Seifert, Y . Cao, C. Clement, J. Ferdinandus, C. Lapa, A. Liebich, M. Amon, J. Enke, S. Songet al., “Developing a pet/ct foundation model for cross-modal anatomical and functional imaging,” J Nucl Med, vol. 66, no. suppl 1, p. 251598, 2025
work page 2025
-
[7]
J. Wi, Y . Jang, D. Lee, M. Nam, and D. Kim, “Delving into pre- training for domain transfer: A broad study of pre-training for domain generalization and domain adaptation: Wi et al.”Int J Comput Vis, vol. 134, no. 2, p. 50, 2026
work page 2026
-
[8]
Act: Semi-supervised domain-adaptive medical image segmentation with asymmetric co-training,
X. Liu, F. Xing, N. Shusharina, R. Lim, C.-C. Jay Kuo, G. El Fakhri, and J. Woo, “Act: Semi-supervised domain-adaptive medical image segmentation with asymmetric co-training,”Med Image Comput Comput Assist Interv, vol. 13435, pp. 66–76, 2022. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 9
work page 2022
-
[9]
S. Bakas, M. Reyes, A. Jakab, S. Bauer, M. Rempfler, A. Crimi, R. T. Shinohara, C. Berger, S. M. Ha, M. Rozyckiet al., “Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the brats challenge,”arXiv preprint arXiv:1811.02629, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Chest-diffusion: A light-weight text-to-image model for report-to-cxr generation,
P. Huang, X. Gao, L. Huang, J. Jiao, X. Li, Y . Wang, and Y . Guo, “Chest-diffusion: A light-weight text-to-image model for report-to-cxr generation,”Proc IEEE Int Symp Biomed Imaging, pp. 1–5, 2024
work page 2024
-
[11]
A generalizable foundation model for analysis of human brain mri,
D. Tak, B. A. Garomsa, A. Zapaishchykova, T. L. Chaunzwa, J. C. Climent Pardo, Z. Ye, J. Zielke, Y . Ravipati, S. Pai, S. Vajapeyamet al., “A generalizable foundation model for analysis of human brain mri,” Nat Neurosci, pp. 1–12, 2026
work page 2026
-
[12]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,”Proc IEEE/CVF Conf. Comput. Vis. Pattern Recognit, pp. 16 000–16 009, 2022
work page 2022
-
[13]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,”Proc Int Conf Mach Learn, pp. 1597–1607, 2020
work page 2020
-
[14]
Developing a pet/ct foundation model for cross-modal anatomical and functional imaging,
Y . Oh, R. Seifert, Y . Cao, C. Clement, J. Ferdinandus, C. Lapa, A. Liebich, M. Amon, J. Enke, S. Songet al., “Developing a pet/ct foundation model for cross-modal anatomical and functional imaging,” arXiv preprint arXiv:2503.02824, 2025
-
[15]
A whole- body fdg-pet/ct dataset with manually annotated tumor lesions,
S. Gatidis, T. Hepp, M. Fr”uh, C. La Foug `ere, K. Nikolaou, C. Pfannen- berg, B. Sch”olkopf, T. K”ustner, C. Cyran, and D. Rubin, “A whole- body fdg-pet/ct dataset with manually annotated tumor lesions,”Sci Data, vol. 9, no. 1, p. 601, 2022
work page 2022
-
[16]
P. Jackson, M. Hofman, J. P. Buteau, L. McIntosh, and Y . Sun, “A repository of annotated PSMA and FDG PET/CT images for algorithm development in staging of mcrpc for treament with 177Lu-PSMA ther- apy,” zenodo website. https://doi.org/10.5281/zenodo.15281784. Pub- lished November 2025. Accessed Dec 2, 2025
-
[17]
Spade (Stanford PET/CT abnormality detection),
S. Eyuboglu, G. Angus, B. N. Patel, A. Pareek, G. Davidzon, J. Long, J. Dunnmon, and M. P. Lungren, “Spade (Stanford PET/CT abnormality detection),” stanford AIMI website. https://stanfordaimi.azurewebsites. net/datasets/72dd9b3a-3a21-49ce-9583-be644d792f01. Published 2024. Accessed Dec 2, 2025
work page 2024
-
[18]
H. T. Nguyen, D. T. Nguyen, T. M. D. Nguyen, T. T. Nguyen, T. N. Truong, H. H. Pham, J. Barthelemy, M. Q. Tran, T. T. Nguyen, Q. V . H. Nguyenet al., “Toward a vision-language foundation model for medical data: Multimodal dataset and benchmarks for vietnamese pet/ct report generation,”Proc Adv Neural Inf Process Syst, 2025
work page 2025
-
[19]
Y . He, V . Nath, D. Yang, Y . Tang, A. Myronenko, and D. Xu, “Swinunetr-v2: Stronger swin transformers with stagewise convolutions for 3d medical image segmentation,”Med Image Comput Comput Assist Interv, pp. 416–426, 2023
work page 2023
-
[20]
nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,
F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, and K. H. Maier-Hein, “nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,”Nat Methods, vol. 18, no. 2, pp. 203–211, 2021
work page 2021
-
[21]
Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,
A. Hatamizadeh, V . Nath, Y . Tang, H. R. Roth, and D. Xu, “Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,”Brainlesion, pp. 272–284, 2021
work page 2021
-
[22]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,”Proc IEEE Int Conf Comput Vis, pp. 10 012–10 022, 2021
work page 2021
-
[23]
Rethinking evaluation of infrared small target detection,
Y . Pang, X. Zhao, L. Zhang, H. Lu, G. El Fakhri, X. Liu, and S. Lu, “Rethinking evaluation of infrared small target detection,” inThe Thirty- ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
work page 2025
-
[24]
Unimrseg: Unified modality-relax segmentation via hierarchical self-supervised compensation,
X. Zhao, Y . Pang, C. Yu, L. Zhang, H. Lu, S. Lu, G. El Fakhri, and X. Liu, “Unimrseg: Unified modality-relax segmentation via hierarchical self-supervised compensation,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[25]
Z. Li, Y . Shi, L. Wang, J. Lu, X. Liu, J. Woo, J. Ouyang, J. Hu, D. Zhou, W. Gonget al., “Deep learning-based non-contrast mri model for nasopharyngeal carcinoma diagnosis: an end-to-end gadolinium-free solution,”npj Digit Med, no. 1, p. 786, 2025
work page 2025
-
[26]
M3d: Advancing 3d medical image analysis with multi-modal large language models,
F. Bai, Y . Du, T. Huang, M. Q.-H. Meng, and B. Zhao, “M3d: Advancing 3d medical image analysis with multi-modal large language models,” arXiv preprint arXiv:2404.00578, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.