Purified OPSD: On-Policy Self-Distillation Without Losing How to Think
Pith reviewed 2026-07-03 13:53 UTC · model grok-4.3
The pith
Purifying the self-distillation signal by subtracting reference-only outputs lets long-CoT models improve without losing reflective reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
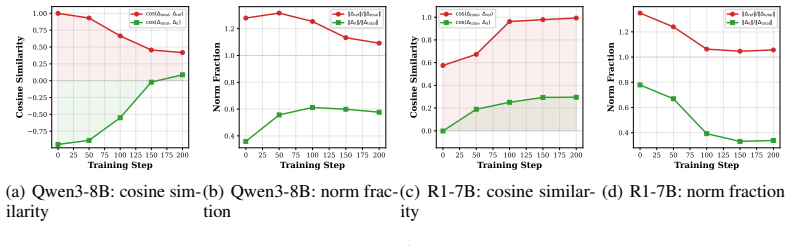
The teacher's supervision in OPSD contains a dominant reference-induced component that drives memorization of shortcuts and a weaker question-conditioned component that carries transferable inference corrections; isolating the former via a reference-only teacher and converting the residual with pointwise mutual information produces a clean target that supports effective distillation without destabilizing reflection.
What carries the argument
Reference-only teacher subtraction to isolate the residual correction signal, followed by pointwise mutual information to form the PMI target distribution for distillation.
If this is right
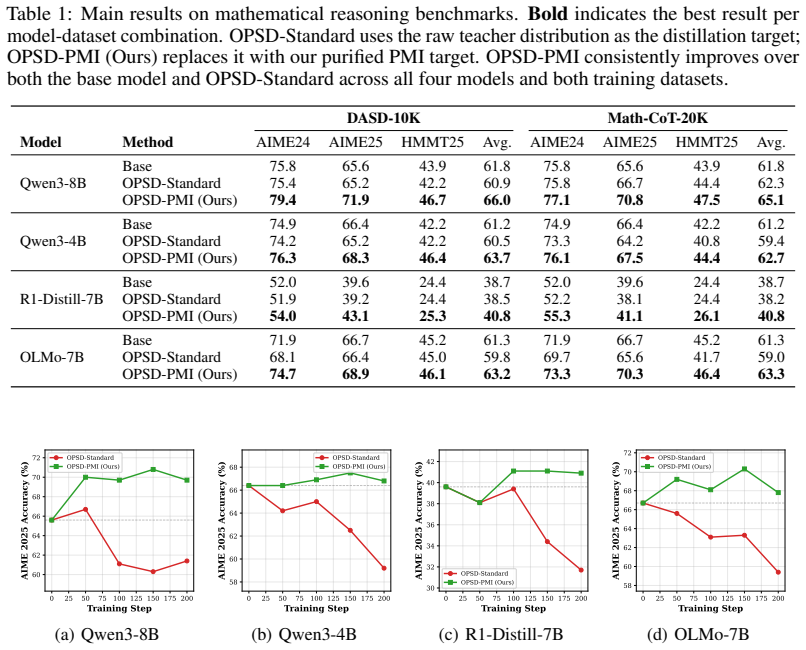
- Consistent performance improvements over base models and standard OPSD on long-CoT reasoning tasks.
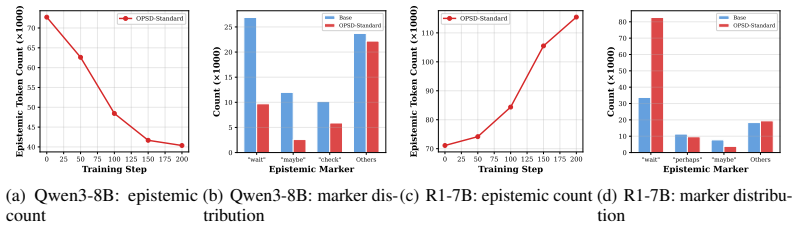
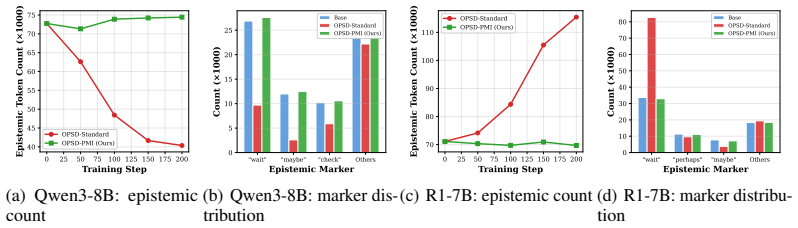
- Preservation of the models' natural epistemic behavior throughout training.
- Effective filtering of reference-induced shortcuts that cause rote memorization.
- Applicability across multiple long-CoT models and datasets.
Where Pith is reading between the lines
- The same decomposition might apply to other forms of privileged supervision in LLM training.
- PMI could be compared to alternative measures for shaping the residual signal.
- Scaling the method to larger models or more complex reasoning tasks remains to be tested.
Load-bearing premise
The residual after subtracting the reference-only teacher's output captures the question-conditioned, inference-transferable correction that can be turned into a usable distillation target by PMI.
What would settle it
If training with the purified targets produces no improvement over standard OPSD or causes the same destabilization of reflective reasoning as the unpurified version, the central claim would be falsified.
Figures



read the original abstract
On-policy self-distillation (OPSD) has emerged as a promising paradigm for improving LLM reasoning, where a privileged teacher with access to reference solutions provides token-level supervision on the student's own generated trajectories. However, we find that OPSD consistently fails on long chain-of-thought (long-CoT) reasoning models, yielding at best marginal gains while destabilizing the reflective reasoning capability these models depend on. Through a novel decomposition of the teacher's supervision signal, we identify the root cause: the teacher's supervision is dominated by a reference-induced component that drives rote memorization of reference-specific shortcuts, while the question-conditioned, inference-transferable component is ignored or actively opposed. Based on this diagnosis, we propose a two-step solution. First, we construct a reference-only teacher (the same model conditioned on the reference without the question) to isolate the non-transferable component of the supervision signal; the residual after subtracting this component captures the question-conditioned, inference-transferable correction. Second, we use pointwise mutual information (PMI) as the mechanism to transform this residual into a well-formed PMI target distribution that the student can directly distill from, filtering out the reference-induced shortcut. Experiments on four long-CoT models across two datasets demonstrate consistent improvements over both the base model and standard OPSD, while preserving the models' natural epistemic behavior throughout training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard on-policy self-distillation (OPSD) fails on long chain-of-thought reasoning models because the teacher's token-level supervision is dominated by reference-induced shortcuts that promote rote memorization, while the question-conditioned transferable component is ignored. It proposes Purified OPSD: (1) construct a reference-only teacher (same model conditioned only on the reference) to isolate the non-transferable component, (2) subtract to obtain the residual as the transferable correction, and (3) apply pointwise mutual information (PMI) to convert the residual into a valid distillation target. Experiments on four long-CoT models across two datasets are reported to yield consistent gains over both the base model and standard OPSD while preserving natural epistemic behavior.
Significance. If the decomposition via subtraction is valid and the PMI target reliably filters shortcuts without introducing new artifacts, the method could offer a practical improvement to self-distillation pipelines for reasoning models, addressing instability in reflective capabilities that current OPSD approaches exhibit.
major comments (2)
- [Abstract, two-step solution paragraph] Abstract, paragraph describing the two-step solution: the central construction assumes the teacher's supervision decomposes additively into a reference-induced component (isolated by the reference-only teacher) and a residual that is precisely the question-conditioned, inference-transferable correction. No derivation is given showing why subtraction (in logits, probabilities, or other space) isolates this component rather than mixing artifacts, nor why the residual is guaranteed to be non-negative or normalizable before PMI is applied. If this does not hold, the PMI target is not guaranteed to filter shortcuts while preserving reasoning.
- [Experiments section] Experiments (as summarized in abstract): the claim of 'consistent improvements' and 'preservation of the models' natural epistemic behavior throughout training' is presented without quantitative details on effect sizes, variance across runs, or ablation controls that isolate the contribution of the reference-only subtraction versus PMI. This makes it difficult to verify that the gains are robust and attributable to the proposed purification rather than other factors.
minor comments (1)
- [Methods] Notation for the residual and PMI target distribution should be defined explicitly with equations early in the methods, as the abstract description leaves the precise mathematical form of the subtraction and normalization ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract, two-step solution paragraph] Abstract, paragraph describing the two-step solution: the central construction assumes the teacher's supervision decomposes additively into a reference-induced component (isolated by the reference-only teacher) and a residual that is precisely the question-conditioned, inference-transferable correction. No derivation is given showing why subtraction (in logits, probabilities, or other space) isolates this component rather than mixing artifacts, nor why the residual is guaranteed to be non-negative or normalizable before PMI is applied. If this does not hold, the PMI target is not guaranteed to filter shortcuts while preserving reasoning.
Authors: We agree that a more explicit justification of the additive decomposition assumption would strengthen the paper. The subtraction is performed in logit space prior to the PMI transformation, motivated by the goal of isolating the question-conditioned residual; however, the manuscript presents this primarily through empirical diagnosis rather than a formal derivation. We will revise the method section to include a dedicated paragraph discussing the assumptions underlying the logit-space subtraction, potential mixing of artifacts, conditions for non-negativity after adjustment, and the role of PMI in producing a valid target distribution, supported by additional empirical checks. revision: yes
-
Referee: [Experiments section] Experiments (as summarized in abstract): the claim of 'consistent improvements' and 'preservation of the models' natural epistemic behavior throughout training' is presented without quantitative details on effect sizes, variance across runs, or ablation controls that isolate the contribution of the reference-only subtraction versus PMI. This makes it difficult to verify that the gains are robust and attributable to the proposed purification rather than other factors.
Authors: The experiments section reports results across four models and two datasets with tables showing performance deltas relative to the base model and standard OPSD. We acknowledge that the current presentation would be improved by explicit reporting of effect sizes, run-to-run variance, and ablations that separately disable the reference-only subtraction and the PMI step. We will expand the experiments section with these quantitative details and ablation results to better isolate the contribution of each component. revision: yes
Circularity Check
No significant circularity; explicit heuristic construction validated by experiments
full rationale
The paper's core contribution is an explicit two-step construction: (1) a reference-only teacher to isolate a non-transferable component, followed by subtraction to obtain a residual claimed to be the question-conditioned correction, and (2) PMI applied to that residual to produce the distillation target. This is presented as a diagnostic decomposition rather than a mathematical derivation from first principles. No equations or self-citations are shown that reduce the claimed performance gains or preservation of epistemic behavior to a tautology, fitted parameter, or self-referential definition. The improvements are asserted via experiments on four models and two datasets, making the argument self-contained against external benchmarks rather than internally forced.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The residual supervision signal after subtracting the reference-only teacher output represents the question-conditioned, inference-transferable component.
Reference graph
Works this paper leans on
-
[1]
Rishabh Agarwal, Nino Vieillard, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes.arXiv preprint arXiv:2306.13649,
-
[2]
Xiao Chen, Sihang Zhou, Ke Liang, Xiaoyu Sun, and Xinwang Liu. Skip-thinking: Chunk-wise chain-of-thought distillation enable smaller language models to reason better and faster.arXiv preprint arXiv:2505.18642, 2025a. Xinghao Chen, Zhijing Sun, Wenjin Guo, Miaoran Zhang, Yanjun Chen, Yirong Sun, Hui Su, Yijie Pan, Dietrich Klakow, Wenjie Li, et al. Unveil...
-
[3]
A Brief Overview: On-Policy Self-Distillation In Large Language Models
Fangming Cui, Sunan Li, and Jiahong Li. A brief overview: On-policy self-distillation in large language models.arXiv preprint arXiv:2605.18141,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Kanishk Gandhi, Denise Lee, Gabriel Grand, Muxin Liu, Winson Cheng, Archit Sharma, and Noah D Goodman. Stream of search (sos): Learning to search in language.arXiv preprint arXiv:2404.03683,
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Yinghui He, Simran Kaur, Adithya Bhaskar, Yongjin Yang, Jiarui Liu, Narutatsu Ri, Liam Fowl, Abhishek Panigrahi, Danqi Chen, and Sanjeev Arora. Self-distillation zero: Self-revision turns binary rewards into dense supervision.arXiv preprint arXiv:2604.12002,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Simran Kaur, Narutatsu Ri, Yinghui He, Liam H Fowl, and Sanjeev Arora. Rethinking on-policy self-distillation for thinking models. InICML 2026 Workshop on Foundations of Deep Generative Models: Understanding Memorization, Generalization, and Reasoning. Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Y...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Zihao Li, Xu Wang, Yuzhe Yang, Ziyu Yao, Haoyi Xiong, and Mengnan Du. Feature extrac- tion and steering for enhanced chain-of-thought reasoning in language models.arXiv preprint arXiv:2505.15634,
-
[12]
Renjie Luo, Jiaxi Li, Chen Huang, and Wei Lu. Through the valley: Path to effective long cot training for small language models.arXiv preprint arXiv:2506.07712, 2025a. Yijia Luo, Yulin Song, Xingyao Zhang, Jiaheng Liu, Weixun Wang, GengRu Chen, Wenbo Su, and Bo Zheng. Deconstructing long chain-of-thought: A structured reasoning optimization framework for ...
-
[13]
URL https://arxiv.org/abs/ 2604.06628. Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
OLMo Team, Dirk Groeneveld, Luca Soldaini, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, et al. Olmo 2: The best fully open language model to date.arXiv preprint arXiv:2501.00656,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Yibo Wang, Li Shen, Huanjin Yao, Tiansheng Huang, Rui Liu, Naiqiang Tan, Jiaxing Huang, Kai Zhang, and Dacheng Tao. R1-compress: Long chain-of-thought compression via chunk compression and search.arXiv preprint arXiv:2505.16838,
-
[16]
Liang Wen et al. Light-r1: Curriculum sft, dpo and rl for long cot from scratch and beyond.arXiv preprint arXiv:2503.10460,
-
[17]
Beyond Scaling Law: A Data-Efficient Distillation Framework for Reasoning
Xiaojun Wu, Xiaoguang Jiang, Huiyang Li, Jucai Zhai, Dengfeng Liu, Qiaobo Hao, Huang Liu, Zhiguo Yang, Ji Xie, Ninglun Gu, et al. Beyond scaling law: A data-efficient distillation framework for reasoning.arXiv preprint arXiv:2508.09883,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Haotian Xu, Xing Yang, Yixiao Song, Hengyuan Wang, Yezeng Ren, Erlu Liu, Haoran Peng, et al. Redstar: Does scaling long-cot data unlock better slow-reasoning systems?arXiv preprint arXiv:2501.11284,
-
[19]
URLhttps://arxiv.org/abs/2601.09088. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[20]
LIMO: Less is More for Reasoning
Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. Limo: Less is more for reasoning.arXiv preprint arXiv:2502.03387,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Distilling system 2 into system 1.arXiv preprint arXiv:2407.06023,
14 Ping Yu, Jing Xu, Jason Weston, and Ilia Kulikov. Distilling system 2 into system 1.arXiv preprint arXiv:2407.06023,
-
[22]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.