RLVR without Ineffective Samples: Group Prioritized Off-Policy Optimization for LLM Reasoning
Pith reviewed 2026-06-28 17:23 UTC · model grok-4.3
The pith
POPO replaces ineffective on-policy sample groups with effective off-policy ones using recency-based replay to speed up LLM reasoning RL without added rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
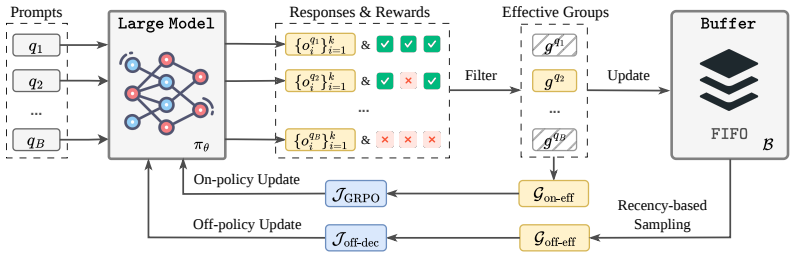
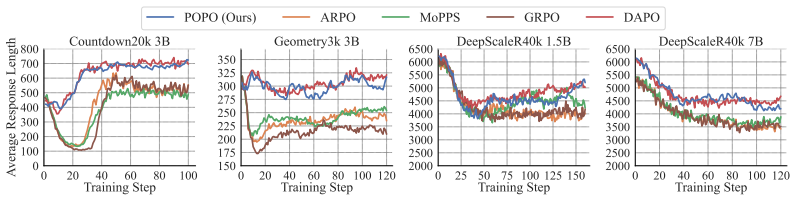
By replacing ineffective on-policy groups with effective off-policy groups through a recency-based replay mechanism that jointly considers sample quality and the degree of off-policiness, and by using decoupled importance sampling to correct off-policy bias under consistent trust-region constraints, POPO fully exploits effective training batches without additional rollout overhead and substantially accelerates RL finetuning for LLM reasoning.
What carries the argument
The recency-based replay mechanism that jointly considers sample quality and the degree of off-policiness, combined with decoupled importance sampling for bias correction.
If this is right
- RL finetuning accelerates substantially across reasoning tasks.
- Strong reasoning performance is achieved with significantly fewer rollouts.
- Computational overhead from extensive LLM rollouts for filtering is avoided.
- Systematic bias or suboptimal constraints from alternative methods are mitigated.
- Effective training batches are fully exploited without extra costs.
Where Pith is reading between the lines
- This approach could reduce the total computational cost of developing reasoning-capable LLMs.
- It may extend to other reinforcement learning domains where reward variance is frequently zero.
- Combining the replay with other efficiency techniques like predictive sampling could yield further gains.
- The method's reliance on off-policy data suggests potential benefits in continual learning settings for LLMs.
Load-bearing premise
The recency-based replay mechanism can reliably replace ineffective on-policy groups with effective off-policy groups without introducing systematic bias or suboptimal constraints.
What would settle it
An experiment where the final reasoning performance of POPO-trained models falls below that of a baseline that simply discards ineffective samples and generates new on-policy ones, when total rollout budget is equalized.
Figures
read the original abstract
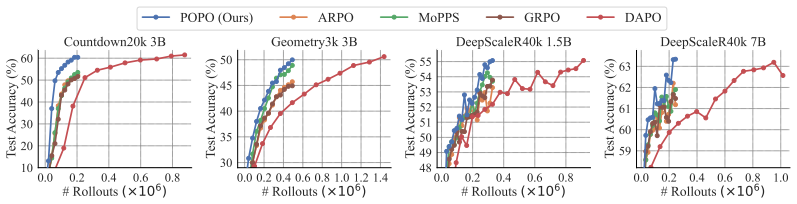
Reinforcement learning with verifiable rewards (RLVR) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). However, its effectiveness is substantially hindered by the prevalence of ineffective training data: many sampled prompts yield response groups that are either entirely correct or entirely incorrect, resulting in zero-variance rewards and limited learning signals. Recent state-of-the-art methods address this issue through extensive LLM rollouts to filter ineffective samples, but at the cost of considerable computational overhead. Alternative approaches, including predictive sampling and trajectory replay, aim to improve data efficiency but often remain insufficient and may introduce additional issues such as systematic bias or suboptimal constraints. To address these limitations, we propose Group Prioritized Off-Policy Optimization (POPO), a simple yet effective framework that fully exploits effective training batches without additional rollout overhead. POPO comprises two key components: prioritized group replay and decoupled off-policy optimization. The former replaces ineffective on-policy groups with effective off-policy groups via a recency-based replay mechanism that jointly considers sample quality and the degree of off-policiness. To further mitigate the off-policy gap, POPO employs decoupled importance sampling to correct off-policy bias while maintaining stable policy updates under consistent trust-region constraints. Empirical evaluations across diverse reasoning tasks, including mathematics, planning, and visual geometry, demonstrate that POPO substantially accelerates RL finetuning and achieves strong reasoning performance with significantly fewer rollouts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
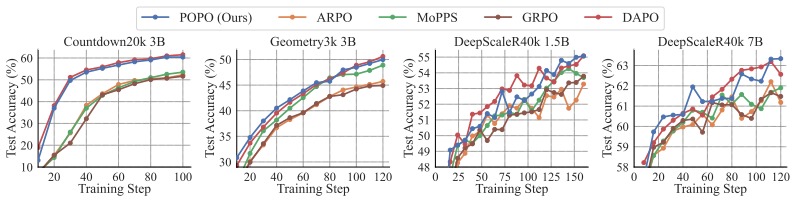
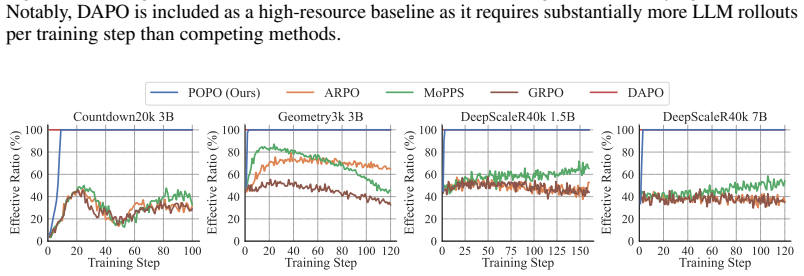
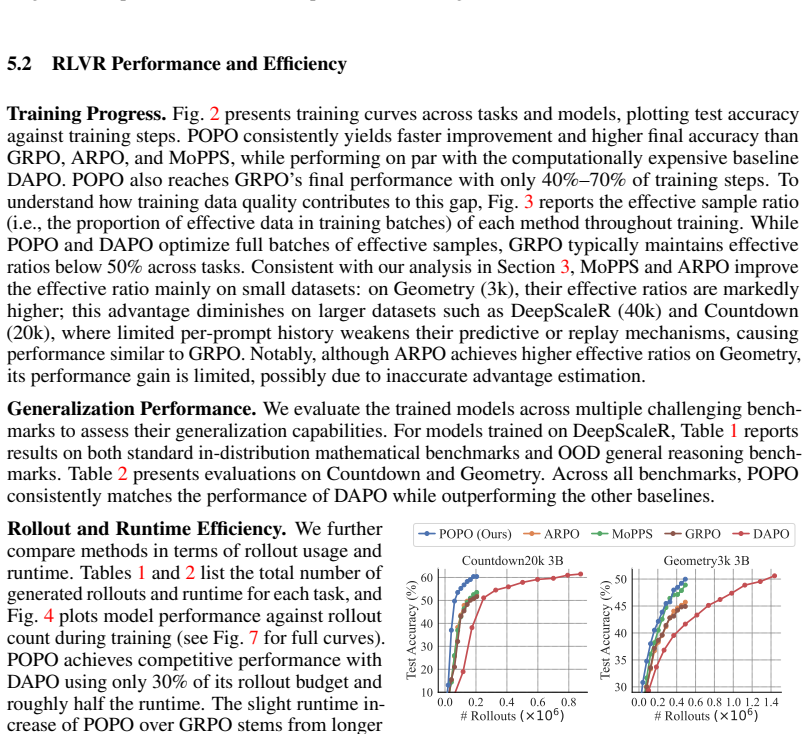
Summary. The manuscript proposes Group Prioritized Off-Policy Optimization (POPO) for reinforcement learning with verifiable rewards (RLVR) on LLMs. It identifies ineffective samples (zero-variance response groups) as a bottleneck and introduces two components: (1) prioritized group replay that replaces ineffective on-policy groups with effective off-policy groups using a recency-based score combining sample quality and off-policiness, and (2) decoupled importance sampling that corrects off-policy bias while preserving trust-region constraints. The central claim is that POPO accelerates RL finetuning and attains strong reasoning performance across mathematics, planning, and visual geometry tasks while using substantially fewer rollouts than prior methods that rely on extensive filtering or predictive sampling.
Significance. If the empirical claims and unbiasedness of the replay mechanism hold, the work would address a practical inefficiency in RLVR pipelines by reducing rollout overhead without sacrificing learning signal. This could lower the computational barrier for scaling reasoning improvements in LLMs. The approach builds on established off-policy techniques but applies them at the group level; confirmation via ablations and bias analysis would strengthen its contribution to data-efficient RL for language models.
major comments (2)
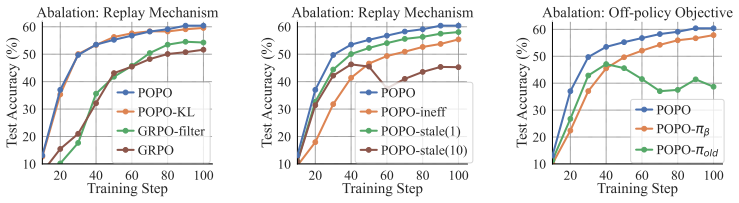
- [Method (prioritized group replay)] Method section on prioritized group replay: the description states that the recency-based mechanism 'jointly considers sample quality and the degree of off-policiness' to substitute groups, yet no derivation or proof is supplied showing that the induced group distribution remains unbiased (or that any residual bias is fully canceled) once decoupled importance sampling is applied. If recency correlates with prompt difficulty or response length, the effective sampling distribution may deviate from the on-policy target in ways not corrected by per-token ratios under trust-region constraints.
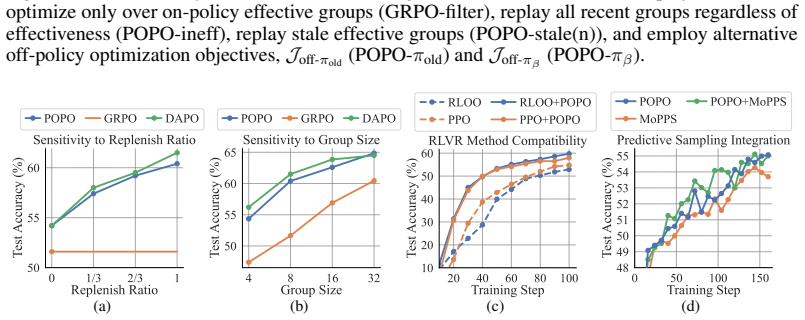
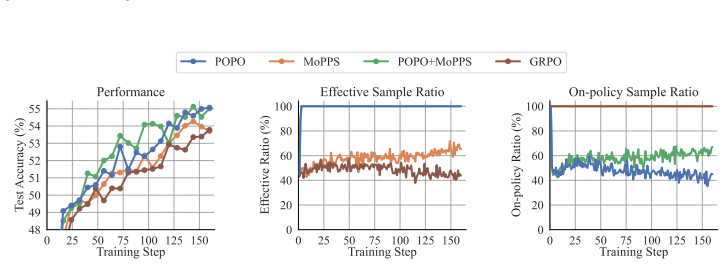
- [Experiments] Empirical evaluations section: the abstract asserts 'substantially accelerates RL finetuning' and 'significantly fewer rollouts' across tasks, but the provided text contains no quantitative results, baseline comparisons, rollout counts, variance estimates, or ablation studies isolating the replay versus decoupled-IS components. Without these, the acceleration claim cannot be assessed for magnitude or robustness.
minor comments (1)
- [Abstract] The abstract refers to 'decoupled importance sampling' and 'consistent trust-region constraints' without defining the precise form of the importance weights or the trust-region objective; adding these equations would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Method (prioritized group replay)] Method section on prioritized group replay: the description states that the recency-based mechanism 'jointly considers sample quality and the degree of off-policiness' to substitute groups, yet no derivation or proof is supplied showing that the induced group distribution remains unbiased (or that any residual bias is fully canceled) once decoupled importance sampling is applied. If recency correlates with prompt difficulty or response length, the effective sampling distribution may deviate from the on-policy target in ways not corrected by per-token ratios under trust-region constraints.
Authors: We agree that the current manuscript lacks a formal derivation showing that the recency-based replay preserves an unbiased group distribution after decoupled importance sampling is applied. In the revised version we will add a dedicated subsection deriving the expected policy gradient under the combined mechanism and proving that the per-token importance ratios, together with the trust-region constraint, yield an unbiased estimate with respect to the on-policy target. We will also explicitly discuss the possibility that recency may correlate with prompt difficulty or response length and show how the decoupled correction and trust-region clipping bound any resulting deviation. revision: yes
-
Referee: [Experiments] Empirical evaluations section: the abstract asserts 'substantially accelerates RL finetuning' and 'significantly fewer rollouts' across tasks, but the provided text contains no quantitative results, baseline comparisons, rollout counts, variance estimates, or ablation studies isolating the replay versus decoupled-IS components. Without these, the acceleration claim cannot be assessed for magnitude or robustness.
Authors: The referee correctly observes that the version under review does not contain the quantitative results, rollout counts, baseline tables, variance estimates, or component ablations needed to evaluate the acceleration claims. We will expand the experimental section in the revision to include all of these elements: concrete performance numbers on each task, direct comparisons against prior RLVR methods, exact rollout budgets, variance statistics, and ablations that isolate the contribution of prioritized group replay versus decoupled importance sampling. revision: yes
Circularity Check
No circularity: method components are independently motivated and do not reduce to input fits or self-citations by construction
full rationale
The paper introduces POPO via two explicitly described algorithmic components (prioritized group replay using recency-based scoring of quality and off-policiness, plus decoupled importance sampling under trust-region constraints). No equations, fitting procedures, or self-citations are shown that would make any claimed performance gain equivalent to a renamed input quantity or a self-referential definition. The central claim of acceleration with fewer rollouts rests on the empirical behavior of these mechanisms rather than on any derivation that collapses to the problem statement itself. External benchmarks and task diversity are invoked without load-bearing reliance on prior author work that would itself be unverified.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
TRACE: A Unified Rollout Budget Allocation Framework for Efficient Agentic Reinforcement Learning
TRACE is a rollout budget allocation framework that models ReAct turns as tree nodes and uses a predictor to allocate samples to informative prefixes, yielding a 2.8-point accuracy gain on Multi-Hop QA at equal cost.
Reference graph
Works this paper leans on
-
[1]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms.arXiv preprint arXiv:2402.14740, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Y ., Kim, H., Nam, J., and Kwak, D
Sanghwan Bae, Jiwoo Hong, Min Young Lee, Hanbyul Kim, JeongYeon Nam, and Donghyun Kwak. Online difficulty filtering for reasoning oriented reinforcement learning.arXiv preprint arXiv:2504.03380, 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Self-evolving curriculum for llm reasoning
Xiaoyin Chen, Jiarui Lu, Minsu Kim, Dinghuai Zhang, Jian Tang, Alexandre Piché, Nicolas Gontier, Yoshua Bengio, and Ehsan Kamalloo. Self-evolving curriculum for llm reasoning. arXiv preprint arXiv:2505.14970, 2025
-
[5]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training.arXiv preprint arXiv:2501.17161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, et al. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, and Yaodong Yang. Safe rlhf: Safe reinforcement learning from human feedback.arXiv preprint arXiv:2310.12773, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Quy-Anh Dang and Chris Ngo. Reinforcement learning for reasoning in small llms: What works and what doesn’t.arXiv preprint arXiv:2503.16219, 2025
-
[10]
RLHF Workflow: From Reward Modeling to Online RLHF
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, and Tong Zhang. Rlhf workflow: From reward modeling to online rlhf. arXiv preprint arXiv:2405.07863, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Improving rl exploration for llm reasoning through retrospective replay
Shihan Dou, Muling Wu, Jingwen Xu, Rui Zheng, Tao Gui, and Qi Zhang. Improving rl exploration for llm reasoning through retrospective replay. InCCF International Conference on Natural Language Processing and Chinese Computing, pages 594–606. Springer, 2025
2025
-
[12]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning.arXiv preprint arXiv:2505.24298, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Prompt curriculum learning for efficient llm post-training.arXiv preprint arXiv:2510.01135, 2025
Zhaolin Gao, Joongwon Kim, Wen Sun, Thorsten Joachims, Sid Wang, Richard Yuanzhe Pang, and Liang Tan. Prompt curriculum learning for efficient llm post-training.arXiv preprint arXiv:2510.01135, 2025
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Batch size-invariance for policy optimization
Jacob Hilton, Karl Cobbe, and John Schulman. Batch size-invariance for policy optimization. Advances in Neural Information Processing Systems, 35:17086–17098, 2022
2022
-
[17]
Geometry3K: A large-scale multi-modal geometry reasoning dataset
Hiyouga. Geometry3K: A large-scale multi-modal geometry reasoning dataset. https:// huggingface.co/datasets/hiyouga/geometry3k, 2025
2025
-
[18]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
arXiv preprint arXiv:2410.01679 , year=
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment.arXiv preprint arXiv:2410.01679, 2024
-
[22]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[23]
Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35:3843–3857, 2022
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35:3843–3857, 2022
2022
-
[24]
Repo: Replay-enhanced policy optimization.arXiv preprint arXiv:2506.09340, 2025
Siheng Li, Zhanhui Zhou, Wai Lam, Chao Yang, and Chaochao Lu. Repo: Replay-enhanced policy optimization.arXiv preprint arXiv:2506.09340, 2025
-
[25]
Jing Liang, Hongyao Tang, Yi Ma, Jinyi Liu, Yan Zheng, Shuyue Hu, Lei Bai, and Jianye Hao. Squeeze the soaked sponge: Efficient off-policy reinforcement finetuning for large language model.arXiv preprint arXiv:2507.06892, 2025
-
[26]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[27]
Self-improving reactive agents based on reinforcement learning, planning and teaching.Machine learning, 8(3):293–321, 1992
Long-Ji Lin. Self-improving reactive agents based on reinforcement learning, planning and teaching.Machine learning, 8(3):293–321, 1992
1992
-
[28]
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models. arXiv preprint arXiv:2505.24864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Fanbin Lu, Zhisheng Zhong, Shu Liu, Chi-Wing Fu, and Jiaya Jia. Arpo: End-to-end policy optimization for gui agents with experience replay.arXiv preprint arXiv:2505.16282, 2025
-
[31]
Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning
Pan Lu, Ran Gong, Shibiao Jiang, Liang Qiu, Siyuan Huang, Xiaodan Liang, and Song- Chun Zhu. Inter-gps: Interpretable geometry problem solving with formal language and symbolic reasoning. InThe Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Proces...
2021
-
[32]
Deepcoder: A fully open-source 14b coder at o3-mini level.Notion Blog, 2025
Michael Luo, Sijun Tan, Roy Huang, Ameen Patel, Alpay Ariyak, Qingyang Wu, Xiaoxiang Shi, Rachel Xin, Colin Cai, Maurice Weber, et al. Deepcoder: A fully open-source 14b coder at o3-mini level.Notion Blog, 2025
2025
-
[33]
Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 2025
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Tianjun Zhang, Li Erran Li, et al. Deepscaler: Surpassing o1-preview with a 1.5 b model by scaling rl.Notion Blog, 2025
2025
-
[34]
Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning.CoRR, 2025
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, et al. Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning.CoRR, 2025
2025
-
[35]
Playing Atari with Deep Reinforcement Learning
V olodymyr Mnih. Playing atari with deep reinforcement learning.arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[36]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
2015
-
[37]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[38]
Tinyzero
Jiayi Pan, Junjie Zhang, Xingyao Wang, Lifan Yuan, Hao Peng, and Alane Suhr. Tinyzero. https://github.com/Jiayi-Pan/TinyZero, 2025. Accessed: 2025-01-24
2025
-
[39]
Yun Qu, Qi Wang, Yixiu Mao, Vincent Tao Hu, Björn Ommer, and Xiangyang Ji. Can prompt difficulty be online predicted for accelerating rl finetuning of reasoning models?arXiv preprint arXiv:2507.04632, 2025
-
[40]
Generalized proximal policy optimization with sample reuse.Advances in Neural Information Processing Systems, 34: 11909–11919, 2021
James Queeney, Yannis Paschalidis, and Christos G Cassandras. Generalized proximal policy optimization with sample reuse.Advances in Neural Information Processing Systems, 34: 11909–11919, 2021
2021
-
[41]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[42]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
2024
-
[43]
Tom Schaul, John Quan, Ioannis Antonoglou, and David Silver. Prioritized experience replay. arXiv preprint arXiv:1511.05952, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[44]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Qianli Shen, Daoyuan Chen, Yilun Huang, Zhenqing Ling, Yaliang Li, Bolin Ding, and Jingren Zhou. Bots: A unified framework for bayesian online task selection in llm reinforcement finetuning.arXiv preprint arXiv:2510.26374, 2025
-
[47]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Yifan Sun, Jingyan Shen, Yibin Wang, Tianyu Chen, Zhendong Wang, Mingyuan Zhou, and Huan Zhang. Improving data efficiency for llm reinforcement fine-tuning through difficulty- targeted online data selection and rollout replay.arXiv preprint arXiv:2506.05316, 2025. 12
-
[49]
Aligning Large Multimodal Models with Factually Augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually augmented rlhf.arXiv preprint arXiv:2309.14525, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
X., Wen, Z., Zhang, Z., and Zhou, J
Xinyu Tang, Zhenduo Zhang, Yurou Liu, Wayne Xin Zhao, Zujie Wen, Zhiqiang Zhang, and Jun Zhou. Towards high data efficiency in reinforcement learning with verifiable reward.arXiv preprint arXiv:2509.01321, 2025
-
[51]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
2024
-
[53]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[54]
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. Logic-rl: Unleashing llm reasoning with rule-based reinforcement learning.arXiv preprint arXiv:2502.14768, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Guowei Xu, Peng Jin, Li Hao, Yibing Song, Lichao Sun, and Li Yuan. Llava-o1: Let vision language models reason step-by-step.arXiv preprint arXiv:2411.10440, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Single-stream policy optimization.arXiv preprint arXiv:2509.13232, 2025
Zhongwen Xu and Zihan Ding. Single-stream policy optimization.arXiv preprint arXiv:2509.13232, 2025
-
[57]
Learning to Reason under Off-Policy Guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance.arXiv preprint arXiv:2504.14945, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv e-prints, pages arXiv–2412, 2024
2024
-
[59]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
arXiv preprint arXiv:2503.01491 , year=
Yufeng Yuan, Yu Yue, Ruofei Zhu, Tiantian Fan, and Lin Yan. What’s behind ppo’s collapse in long-cot? value optimization holds the secret.arXiv preprint arXiv:2503.01491, 2025
-
[61]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Yu Yue, Yufeng Yuan, Qiying Yu, Xiaochen Zuo, Ruofei Zhu, Wenyuan Xu, Jiaze Chen, Chengyi Wang, TianTian Fan, Zhengyin Du, et al. Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks.arXiv preprint arXiv:2504.05118, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild.arXiv preprint arXiv:2503.18892, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Runzhe Zhan, Yafu Li, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F Wong, and Yu Cheng. Exgrpo: Learning to reason from experience.arXiv preprint arXiv:2510.02245, 2025
-
[64]
Hongzhi Zhang, Jia Fu, Jingyuan Zhang, Kai Fu, Qi Wang, Fuzheng Zhang, and Guorui Zhou. Rlep: Reinforcement learning with experience replay for llm reasoning.arXiv preprint arXiv:2507.07451, 2025
-
[65]
A Survey of Reinforcement Learning for Large Reasoning Models
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, et al. A survey of reinforcement learning for large reasoning models.arXiv preprint arXiv:2509.08827, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Xiaojiang Zhang, Jinghui Wang, Zifei Cheng, Wenhao Zhuang, Zheng Lin, Minglei Zhang, Shaojie Wang, Yinghan Cui, Chao Wang, Junyi Peng, et al. Srpo: A cross-domain imple- mentation of large-scale reinforcement learning on llm.arXiv preprint arXiv:2504.14286, 2025
-
[67]
Improving sampling efficiency in rlvr through adaptive rollout and response reuse
Yuheng Zhang, Wenlin Yao, Changlong Yu, Yao Liu, Qingyu Yin, Bing Yin, Hyokun Yun, and Lihong Li. Improving sampling efficiency in rlvr through adaptive rollout and response reuse. arXiv preprint arXiv:2509.25808, 2025
-
[68]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang
Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, Hao Lin, Chencan Wu, Feng Hu, et al. Stabilizing reinforcement learning with llms: Formulation and practices.arXiv preprint arXiv:2512.01374, 2025
-
[69]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Haizhong Zheng, Yang Zhou, Brian R Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and Beidi Chen. Act only when it pays: Efficient reinforcement learning for llm reasoning via selective rollouts.arXiv preprint arXiv:2506.02177, 2025. 14 A Related Work RL Finetuning for LLMs.RL has emerged as a central paradigm for adapting LLMs to complex tasks and t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.