Aristotelian Virtue Profiling of LLMs through Ethical Dilemmas
Pith reviewed 2026-06-30 10:16 UTC · model grok-4.3
The pith
VirtueMap profiles LLMs on Aristotelian virtues by scoring their rankings of dilemma responses against human-validated orderings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
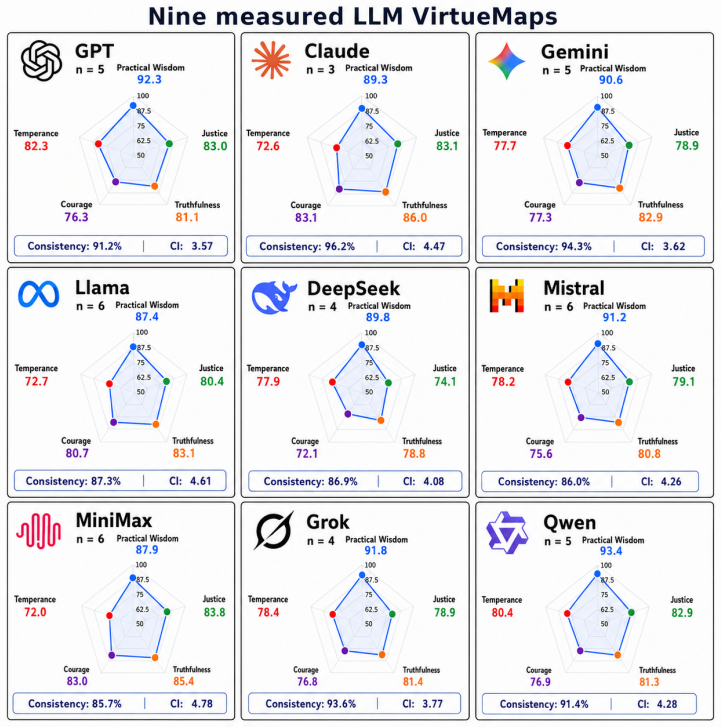
VirtueMap is a framework that asks both humans and LLMs to rank all five responses to each of seven ethical dilemmas according to five Aristotelian virtues. Reference orderings are first proposed and then kept as ground truth only when at least 95 percent of more than 100 human respondents confirm them. Rankings are scored via normalized Borda alignment to yield profiles over Practical Wisdom, Justice, Truthfulness, Courage, and Temperance. Application to nine LLM families in repeated-run evaluation shows 90.3 percent mean rank consistency, with the largest differences on Courage, Temperance, and Justice.
What carries the argument
VirtueMap, a ranking framework that scores LLM responses against 95-percent-human-confirmed Aristotelian virtue orderings using normalized Borda alignment.
If this is right
- LLM families produce stable virtue profiles across repeated evaluations.
- The greatest variation across families occurs in Courage, Temperance, and Justice.
- Profiles can be compared directly between models and with human respondents using the released interactive website.
- The method allows measurement of relative virtue priorities without requiring a single correct answer.
Where Pith is reading between the lines
- The observed consistency may reflect shared patterns in the training data of different model families.
- The framework could track how additional training or alignment steps alter a model's virtue profile over successive versions.
- Applying the same dilemmas to human respondents at scale would allow direct statistical comparison between human and LLM distributions on each virtue.
Load-bearing premise
The initially proposed orderings of the five responses for each dilemma and virtue accurately reflect Aristotelian virtue expression once confirmed by at least 95 percent of human respondents.
What would settle it
A new survey of over 100 respondents per ordering that finds agreement below 95 percent on any reference ranking, or repeated LLM evaluations that yield mean rank consistency substantially below 90.3 percent.
Figures

read the original abstract
Large Language Models (LLMs) often face ethical tradeoffs in which several responses may be defensible but express different priorities, such as fairness, honesty, courage, or restraint. We introduce VirtueMap, a framework for describing these patterns through an Aristotelian virtue-ethics lens. Instead of asking for a single correct answer, VirtueMap asks humans or LLMs to rank all five responses to each of seven general, non-lethal, non-political, and non-religious ethical dilemmas. To define the reference orderings used for scoring, we first proposed, for each dilemma and virtue, an ordering of the five responses from most to least expressive of that virtue. We then collected more than 100 respondent evaluations per ordering and retained it as operational ground truth only when at least 95% confirmed it. Rankings are scored against these retained orderings using normalized Borda alignment, yielding profiles over Practical Wisdom, Justice, Truthfulness, Courage, and Temperance. We apply VirtueMap to nine LLM families in a repeated-run evaluation and find high mean rank consistency (90.3%), with the largest differences appearing on Courage, Temperance, and Justice. We also release an interactive website that computes profiles locally in the browser and compares respondents with measured LLM profiles.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VirtueMap, a framework that profiles LLMs on five Aristotelian virtues (Practical Wisdom, Justice, Truthfulness, Courage, Temperance) by requiring models to rank all five responses to each of seven ethical dilemmas. Reference orderings are created by author proposal and retained only if confirmed by ≥95% of >100 human respondents; LLM outputs are scored via normalized Borda alignment. Applied to nine LLM families in repeated runs, the work reports 90.3% mean rank consistency, largest differences on Courage/Temperance/Justice, and releases a browser-based interactive tool for local profile computation.
Significance. If the retained orderings validly operationalize the virtues, the method supplies a reproducible, multi-response ranking approach to ethical evaluation that avoids single-answer assumptions and yields stable profiles across model families. The repeated-run design, Borda scoring, and open interactive website are concrete strengths that support reproducibility. The reported consistency statistic would be a useful benchmark for alignment work if the Aristotelian grounding holds.
major comments (2)
- [Abstract / reference-ordering section] Abstract and the section describing reference-ordering construction: the claim that retained orderings constitute 'operational ground truth' for Aristotelian virtues rests on ≥95% human confirmation of author-proposed rankings. This procedure measures inter-rater agreement with the proposals, not correctness against the Nicomachean Ethics (e.g., courage as the mean between fear and confidence, or justice as giving each their due). No derivation from primary texts, no expert-philosopher validation, and no check that the five-response sets instantiate the relevant means/vices is described. Because the downstream Borda profiles and 90.3% consistency claim are scored against these orderings, the issue is load-bearing for the central 'Aristotelian virtue profiling' assertion.
- [Dilemma and virtue mapping section] The seven dilemmas are presented as instantiating the five virtues, yet the manuscript provides no explicit mapping showing how each dilemma's response set realizes the Aristotelian mean/vice structure for the targeted virtue. Without this, it is unclear whether differences in LLM rankings reflect virtue expression or merely surface-level response preferences.
minor comments (2)
- [Abstract] The abstract states 'more than 100 respondent evaluations per ordering' but does not report exact N, demographic details, or inter-rater reliability beyond the 95% threshold; adding these would improve transparency.
- [Scoring section] Notation for normalized Borda alignment should be defined explicitly (e.g., formula and range) rather than left implicit.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address each major comment below and propose revisions where appropriate to strengthen the manuscript's clarity regarding its methodological foundations.
read point-by-point responses
-
Referee: [Abstract / reference-ordering section] the claim that retained orderings constitute 'operational ground truth' for Aristotelian virtues rests on ≥95% human confirmation of author-proposed rankings. This procedure measures inter-rater agreement with the proposals, not correctness against the Nicomachean Ethics. No derivation from primary texts, no expert-philosopher validation, and no check that the five-response sets instantiate the relevant means/vices is described. The issue is load-bearing for the central 'Aristotelian virtue profiling' assertion.
Authors: We agree that the reference orderings originate from author proposals validated by high human agreement rather than derivation from the Nicomachean Ethics or expert-philosopher review. The phrase 'operational ground truth' was meant to denote a reproducible empirical benchmark but can overstate the philosophical grounding. In revision we will replace it with 'human-validated reference orderings' and add a limitations subsection explicitly noting the absence of direct textual derivation or expert validation. This preserves the empirical contribution while accurately representing the method's scope. revision: yes
-
Referee: [Dilemma and virtue mapping section] The seven dilemmas are presented as instantiating the five virtues, yet the manuscript provides no explicit mapping showing how each dilemma's response set realizes the Aristotelian mean/vice structure for the targeted virtue. Without this, it is unclear whether differences in LLM rankings reflect virtue expression or merely surface-level response preferences.
Authors: We acknowledge that the manuscript does not supply explicit per-dilemma mappings linking response sets to the Aristotelian mean/vice structure. The dilemmas were constructed to target the virtues via author interpretation, but this structure was not documented. We will add an appendix providing these mappings for all seven dilemmas, with brief justifications for how each response set spans the relevant mean. This addition will clarify the intended connection to virtue expression. revision: yes
Circularity Check
No significant circularity; external human validation anchors the reference orderings
full rationale
The paper defines reference orderings by first proposing them and then retaining only those confirmed by ≥95% of >100 independent human respondents per ordering. LLM rankings are then scored against these externally validated orderings via normalized Borda alignment. No step reduces the reported LLM virtue profiles or consistency statistics (e.g., 90.3% mean rank consistency) to quantities fitted from the LLM data itself, nor does any load-bearing premise rest on self-citation chains or self-definitional loops. The human confirmation step functions as an independent benchmark rather than an internal fit.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The authors' initial proposed orderings of responses correctly capture the degree to which each response expresses a given Aristotelian virtue.
- ad hoc to paper A 95% confirmation rate by respondents is sufficient to establish operational ground truth for the orderings.
Reference graph
Works this paper leans on
-
[1]
1999 , url=
Nicomachean Ethics , author=. 1999 , url=
1999
-
[2]
1999 , url=
On Virtue Ethics , author=. 1999 , url=
1999
-
[3]
2011 , url=
Intelligent Virtue , author=. 2011 , url=
2011
-
[4]
2021 , url=
Dan Hendrycks and Collin Burns and Steven Basart and Andrew Critch and Jerry Li and Dawn Song and Jacob Steinhardt , booktitle=. 2021 , url=
2021
-
[5]
2021 , eprint=
Scruples: A Corpus of Community Ethical Judgments on 32,000 Real-Life Anecdotes , author=. 2021 , eprint=
2021
-
[6]
, title =
Scherrer, Nino and Shi, Claudia and Feder, Amir and Blei, David M. , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[7]
Marwa Abdulhai and Gregory Serapio-Garcia and Clément Crepy and Daria Valter and John Canny and Natasha Jaques , year=. 2310.15337 , archivePrefix=
-
[8]
2025 , eprint=
Modeling Annotator Disagreement with Demographic-Aware Experts and Synthetic Perspectives , author=. 2025 , eprint=
2025
-
[9]
Polarized Opinion Detection Improves the Detection of Toxic Language
Pavlopoulos, John and Likas, Aristidis. Polarized Opinion Detection Improves the Detection of Toxic Language. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.eacl-long.117
-
[10]
Can Robotic
Constantinescu, Mihaela and Crisp, Roger , journal=. Can Robotic. 2022 , doi=
2022
-
[11]
The Stanford Encyclopedia of Philosophy , editor=
Aristotle's Ethics , author=. The Stanford Encyclopedia of Philosophy , editor=. 2021 , url=
2021
-
[12]
2026 , howpublished =
OpenRouter API Reference: Chat Completion , author =. 2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.