Specifying AI-SDLC Processes: A Protocol Language for Human-Agent Boundaries
Pith reviewed 2026-06-30 11:47 UTC · model grok-4.3
The pith
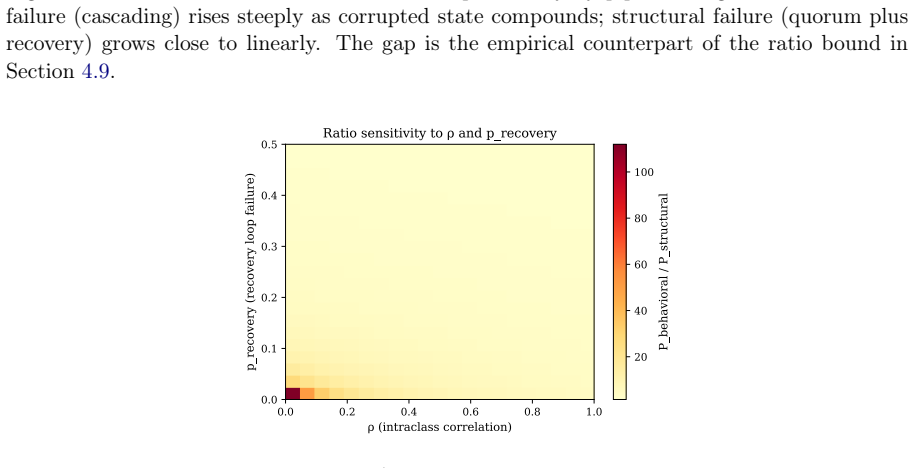
A protocol language for AI-SDLC processes uses structural enforcement via validation tokens and capability boundaries to bound system failure rates at the weighted product of agent and validator rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
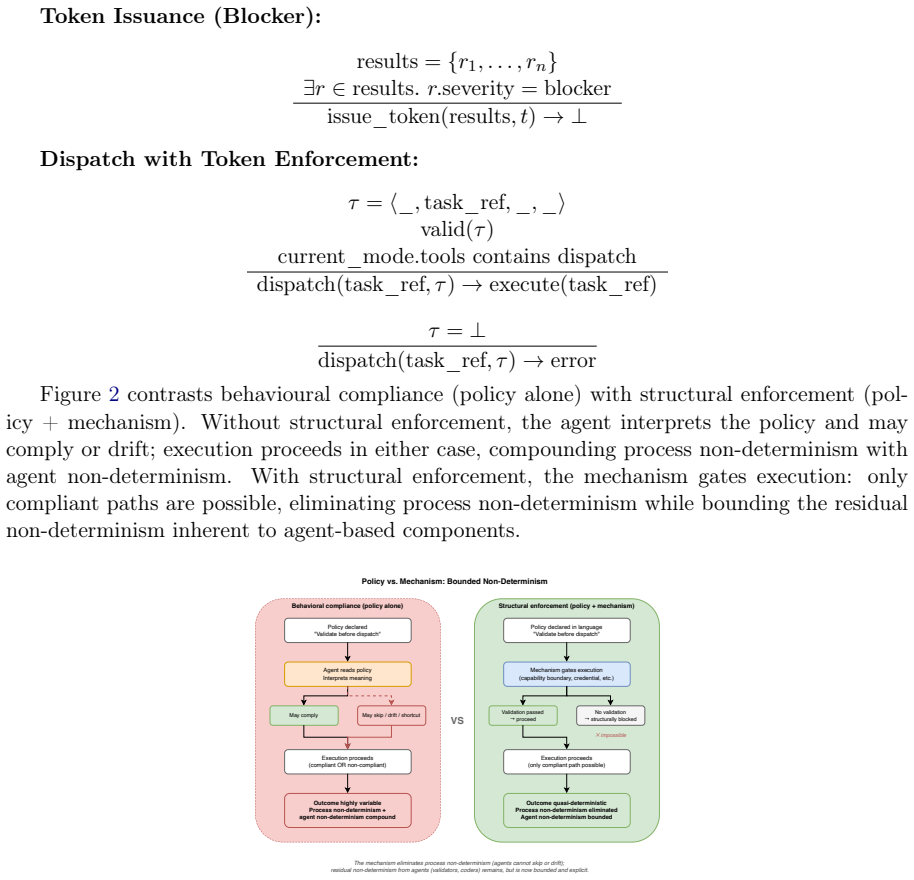
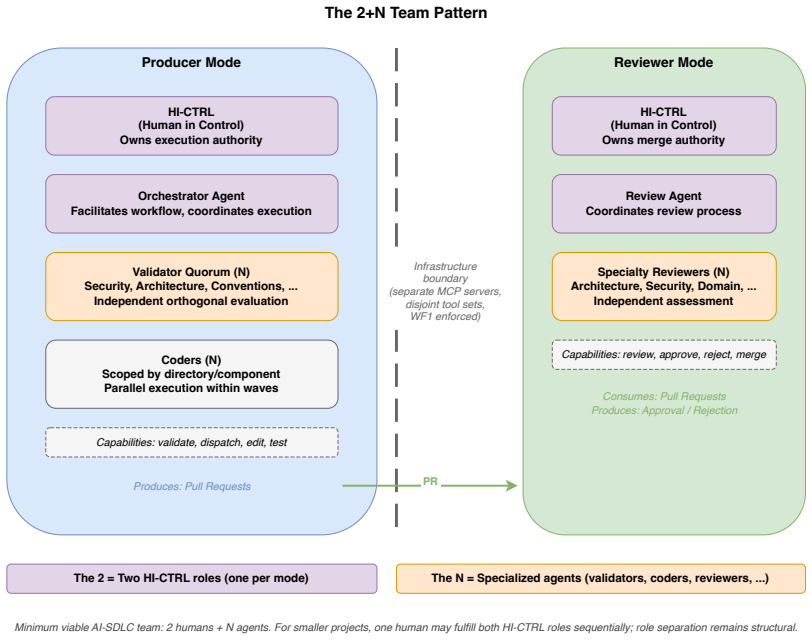
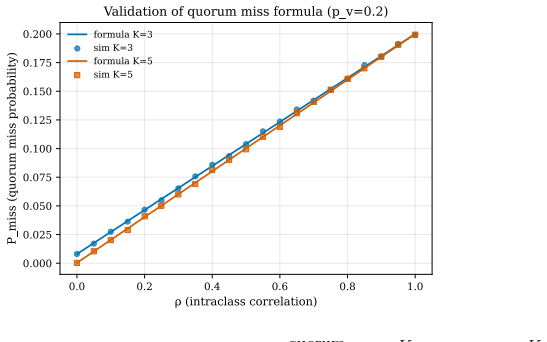
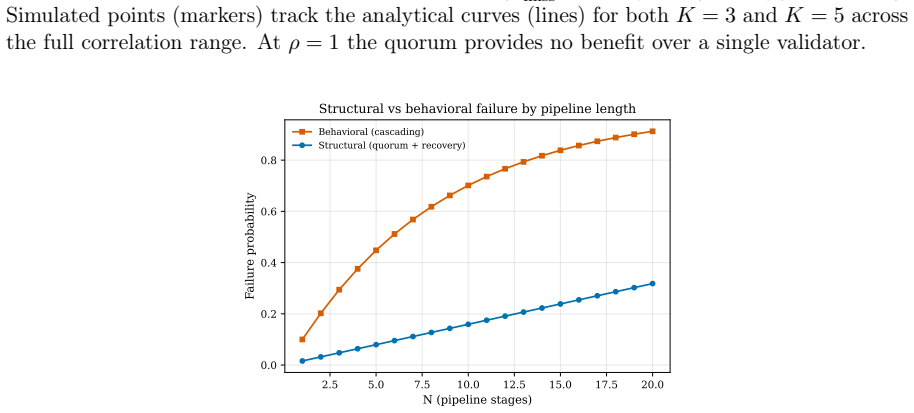
The paper establishes a protocol language for AI-SDLC with formal syntax, well-formedness conditions, operational semantics, and enforcement invariants. By distinguishing policy from mechanism, implementations can bound non-determinism using validation tokens and capability boundaries. This yields three results: structural enforcement bounds failure rates at a weighted product of agent and validator rates while behavioral compliance permits cumulative or near-saturating growth; the 2+N team pattern formalizes Separation of Duties for AI-SDLC; and Kleene closure of orchestration loops and reflexive protocol-adherence validation emerge as design properties.
What carries the argument
The protocol language with its operational semantics and enforcement invariants, which realize structural enforcement through validation tokens and capability boundaries to bound non-determinism.
If this is right
- Structural enforcement bounds system failure rates at a weighted product of agent and validator rates.
- Behavioral compliance permits cumulative or near-saturating growth in failure rates.
- The 2+N team pattern formalizes classical Separation of Duties for AI-SDLC.
- Kleene closure of orchestration loops and reflexive protocol-adherence validation emerge as design properties rather than special-case constructs.
Where Pith is reading between the lines
- The language could extend to governance of agent teams in domains other than software development where similar responsibility boundaries are required.
- Practical implementations may show whether the stated bounds on non-determinism hold when agents exhibit partial observability or learning during execution.
- The distinction between policy and mechanism offers a route to auditability that could be tested by generating compliance logs directly from the protocol state.
Load-bearing premise
The proposed language's operational semantics and enforcement invariants can be realized through primitives such as validation tokens and capability boundaries in a way that bounds non-determinism.
What would settle it
An implemented AI-SDLC system using the protocol language in which measured failure rates under structural enforcement exceed the weighted product of agent and validator rates.
Figures




read the original abstract
AI agents now participate as first-class team members across the software development lifecycle, yet no specification language exists for expressing the human-agent responsibility boundaries, approval gates, and governance constraints this collaboration requires. Existing approaches encode process in agent prompts (subject to drift), target adjacent domains (workflow management, business processes), or address only fragments (access control, approval gates). We propose a domain-specific language for specifying AI-SDLC processes as protocols, with formal syntax, well-formedness conditions, operational semantics, and enforcement invariants. The language distinguishes policy (declared intent) from mechanism (structural enforcement), enabling implementations to bound process non-determinism through primitives such as validation tokens and capability boundaries. Three results follow. A failure rate analysis shows that structural enforcement bounds system failure rates at a weighted product of agent and validator rates, while behavioral compliance permits cumulative or near-saturating growth. The 2+N team pattern (two human-in-control roles plus N specialized agent members) formalizes classical Separation of Duties for AI-SDLC. Kleene closure of orchestration loops and reflexive protocol-adherence validation emerge as design properties rather than special-case constructs. We position the contribution against multi-agent frameworks (MetaGPT), workflow specification (FlowAgent, BPMN extensions), and capability-based security (SAGA): the novelty lies in the specific integration, not any single primitive. A working implementation demonstrates feasibility; empirical evaluation is future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a domain-specific protocol language for AI-SDLC processes that distinguishes policy (declared intent) from mechanism (structural enforcement). It supplies formal syntax, well-formedness conditions, operational semantics, and enforcement invariants using primitives such as validation tokens and capability boundaries. Three results are claimed: a failure-rate analysis in which structural enforcement bounds system failure rates at a weighted product of agent and validator rates (while behavioral compliance permits cumulative growth); formalization of the 2+N team pattern as Separation of Duties; and emergence of design properties including Kleene closure of orchestration loops and reflexive protocol-adherence validation. A feasibility implementation is presented; empirical evaluation is stated as future work.
Significance. If the failure-rate bound can be rigorously derived from the operational semantics and invariants, the work would supply a concrete integration of process specification with capability-based enforcement that is absent from existing multi-agent frameworks and workflow languages. The policy-mechanism distinction and the 2+N pattern are cleanly stated contributions that could serve as reference points for governance of human-agent teams.
major comments (2)
- [Abstract] Abstract (failure-rate analysis paragraph): the central quantitative claim states that structural enforcement bounds failure rates at a weighted product of agent and validator rates, yet no probabilistic model, independence assumptions, equations, or derivation linking validation tokens and capability boundaries to failure events is supplied. The manuscript explicitly defers empirical evaluation and provides only a feasibility implementation, leaving the bound as an informal assertion rather than a consequence of the stated syntax and invariants.
- [Abstract / operational semantics] Abstract (three results paragraph) and operational-semantics section: the claim that the language primitives eliminate all other failure paths (required for the product bound to hold) is not accompanied by an explicit invariant or proof sketch showing that non-determinism is confined to the agent and validator components.
minor comments (1)
- [Related work] The positioning against MetaGPT, FlowAgent, BPMN, and SAGA is clear, but the manuscript would benefit from a short table contrasting the new language's primitives with those frameworks.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our formal results. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (failure-rate analysis paragraph): the central quantitative claim states that structural enforcement bounds failure rates at a weighted product of agent and validator rates, yet no probabilistic model, independence assumptions, equations, or derivation linking validation tokens and capability boundaries to failure events is supplied. The manuscript explicitly defers empirical evaluation and provides only a feasibility implementation, leaving the bound as an informal assertion rather than a consequence of the stated syntax and invariants.
Authors: We agree that the failure-rate bound is summarized at a high level in the abstract and requires an explicit probabilistic model and derivation to be presented as a consequence of the syntax and invariants. The manuscript defines the relevant operational semantics and enforcement invariants, but the probabilistic analysis linking them to the weighted product bound is not fully expanded. In the revision we will add the probabilistic model, independence assumptions, equations, and derivation in the failure-rate analysis section, making the bound a direct consequence of the formal elements while retaining the statement that empirical evaluation is future work. revision: yes
-
Referee: [Abstract / operational semantics] Abstract (three results paragraph) and operational-semantics section: the claim that the language primitives eliminate all other failure paths (required for the product bound to hold) is not accompanied by an explicit invariant or proof sketch showing that non-determinism is confined to the agent and validator components.
Authors: The operational semantics and well-formedness conditions are intended to confine non-determinism to agent and validator actions via the invariants on validation tokens and capability boundaries. However, we acknowledge that an explicit invariant statement and proof sketch are not provided. We will add both to the operational-semantics section in the revised manuscript to rigorously establish the confinement of failure paths. revision: yes
Circularity Check
No circularity: claims presented as consequences of independent semantics
full rationale
The abstract defines a DSL with syntax, well-formedness, operational semantics and enforcement invariants, then states that three results (including the weighted-product failure bound) follow from those definitions. No equations, fitted parameters, self-citations, or ansatzes are quoted that would make any result equivalent to its inputs by construction. The failure-rate claim is asserted as an analysis outcome rather than a redefinition or statistical fit; the paper explicitly defers empirical evaluation. Because no load-bearing step reduces to a self-referential input, the derivation chain is treated as self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard mathematical definitions of syntax, operational semantics, and invariants suffice to support the claimed enforcement properties.
invented entities (1)
-
AI-SDLC protocol language with policy-mechanism distinction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Measuring AI Agent Autonomy in Practice
[Anthropic(2026)] Anthropic. Measuring AI Agent Autonomy in Practice. Anthropic Research,
2026
-
[2]
[Ait et al.(2024)] Ait, A., Cánovas Izquierdo, J. L., & Cabot, J. Towards Modeling Human- Agentic Collaborative Workflows: A BPMN Extension. arXiv preprint arXiv:2412.05958,
-
[3]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
[AutoGen(2023)] Wu, Q., Bansal, G., Zhang, J., et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. arXiv preprint arXiv:2308.08155,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
M.Team Roles at Work, 2nd ed
[Belbin(2012)] Belbin, R. M.Team Roles at Work, 2nd ed. Routledge,
2012
-
[5]
A., & Eloff, J
[Botha & Eloff(2001)] Botha, R. A., & Eloff, J. H. P. Separation of Duties for Access Control Enforcement in Workflow Environments.IBM Systems Journal, 40(3), 666–682,
2001
-
[6]
Analyzing Autonomous Software Engi- neering Agents
[Bouzenia & Pradel(2025)] Bouzenia, I., & Pradel, M. Analyzing Autonomous Software Engi- neering Agents. InInternational Conference on Software Engineering,
2025
-
[7]
Business Process Model and Notation (BPMN), Version 2.0.2
[BPMN(2013)] Object Management Group. Business Process Model and Notation (BPMN), Version 2.0.2. 2013.https://www.omg.org/spec/BPMN/2.0.2/ [CodeAnt AI(2025)] CodeAnt AI. Code Review Best Practices. 2025.https://www.codeant.ai [CrewAI(2024)] CrewAI. CrewAI: Framework for Orchestrating Role-Playing Autonomous AI Agents. 2024.https://www.crewai.com/ 25 [DeMa...
2013
-
[8]
B., & Van Horn, E
[Dennis & Van Horn(1966)] Dennis, J. B., & Van Horn, E. C. Programming Semantics for Multiprogrammed Computations.Communications of the ACM, 9(3), 143–155,
1966
-
[9]
Agentic Development Lifecycle (ADLC): A New Model for AI Systems Beyond SDLC
[EPAM Systems(2026)] EPAM Systems. Agentic Development Lifecycle (ADLC): A New Model for AI Systems Beyond SDLC. EPAM Technical Report, February
2026
-
[10]
CreateYourAI-EnhancedSDLCTransformation 90-Plus-Day Roadmap
[Forrester Research(2025)] ForresterResearch. CreateYourAI-EnhancedSDLCTransformation 90-Plus-Day Roadmap. Forrester Research Report, December
2025
-
[11]
Security Implications of Large Language Model Code Assistants: A User Study.ACM Transactions on Software Engineering and Methodology, 33(4),
[Fu et al.(2024)] Fu, M., van Tonder, R., Gulwani, S., Mechtaev, S., & Tomasic, N. Security Implications of Large Language Model Code Assistants: A User Study.ACM Transactions on Software Engineering and Methodology, 33(4),
2024
-
[12]
AI SDLC: Redefining Developer Work
[Grid Dynamics(2026)] Grid Dynamics. AI SDLC: Redefining Developer Work. January
2026
-
[13]
https://www.griddynamics.com [Hong et al.(2024)] Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Zhang, C., Wang, J., Wang, Z., Yau, S. K. S., Lin, Z., et al. MetaGPT: Meta Programming for a Multi- Agent Collaborative Framework. InInternational Conference on Learning Representations (ICLR),
2024
-
[14]
Silent Failures in AI Code Generation.IEEE Spec- trum, January
[IEEE Spectrum(2025)] IEEE Spectrum. Silent Failures in AI Code Generation.IEEE Spec- trum, January
2025
-
[15]
[Kleene(1956)] Kleene, S. C. Representation of Events in Nerve Nets and Finite Automata. In Shannon, C. E., & McCarthy, J. (eds.),Automata Studies, 3–41. Princeton University Press,
1956
-
[16]
LangGraph: Multi-Agent Workflows
[LangChain(2024)] LangChain. LangGraph: Multi-Agent Workflows. 2024.https://www. langchain.com/langgraph [LangChain(2026)] LangChain. Human-in-the-Loop Middleware. 2026.https://docs. langchain.com/ [Li et al.(2022)] Li, A. S., Safavi-Naini, R., & Fong, P. W. L. A Capability-based Distributed Authorization System to Enforce Context-aware Permission Sequenc...
-
[17]
Security and Privacy Controls for Information Systems and Organizations
[NIST(2020)] National Institute of Standards and Technology. Security and Privacy Controls for Information Systems and Organizations. NIST Special Publication 800-53 Rev. 5,
2020
-
[18]
Agentic SDLC: A Complete Guide
[Pandit(2025)] Pandit, R. Agentic SDLC: A Complete Guide. November 2025.https: //rajatpandit.com [Pearce et al.(2022)] Pearce, H., Ahmad, B., Tan, B., Dolan-Gavitt, B., & Karri, R. Asleep at the Keyboard? Assessing the Security of GitHub Copilot’s Code Contributions. InIEEE Symposium on Security and Privacy,
2025
-
[19]
[Ran The Builder(2026)] Ran The Builder. AI-Driven SDLC: Build Secure, Scalable Software with AI. February 2026.https://ranthebuilder.cloud [Shi et al.(2025)] Shi, Y., Cai, S., Xu, Z., Qin, Y., Hu, X., Xu, J., Liao, Y., Lu, Y., Wang, S., Xiong, L., Lin, J., Liu, Z., & Qiu, X. FlowAgent: Achieving Compliance and Flexibility for Workflow Agents. arXiv prepr...
-
[20]
Audit Trail Complications in AI Code Generation
26 [SitePoint(2026)] SitePoint. Audit Trail Complications in AI Code Generation. 2026.https: //www.sitepoint.com [Token Security(2026)] Token Security. The Shift From Credentials to Capabilities in AI Access Control Systems. 2026.https://www.token.security/blog/ [van der Aalst & ter Hofstede(2005)] van der Aalst, W. M. P., & ter Hofstede, A. H. M. YAWL: Y...
2026
-
[21]
SAGA: A security architecture for governing AI agentic systems,
[Waxell(2026)] Waxell. Human-in-the-Loop vs Human-on-the-Loop for AI Agents. 2026.https: //www.waxell.ai/blog/human-in-the-loop-vs-human-on-the-loop-ai-agents [Yao et al.(2025)] Yao, Y., et al. SAGA: A Security Architecture for Governing AI Agentic Systems. arXiv preprint arXiv:2504.21034,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.