DysLexLens: A Low-Resource LLM Framework for Analysing Dyslexic Learners Insights from Online Forums
Pith reviewed 2026-06-29 01:09 UTC · model grok-4.3
The pith
DysLexLens converts noisy Reddit posts on dyslexia and AI into traceable, verifiable insights using dictionary-driven corpora and knowledge-graph reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DysLexLens is an end-to-end architecture that transforms noisy social media posts into a dictionary-driven corpora, provides knowledge-graph-based question reasoning, generates verifiable query responses, and enables response evaluation through quantitative and human-grounded assessment. It demonstrates this on dyslexia-related Reddit data with 30 questions, showing potential for other low-resource contexts.
What carries the argument
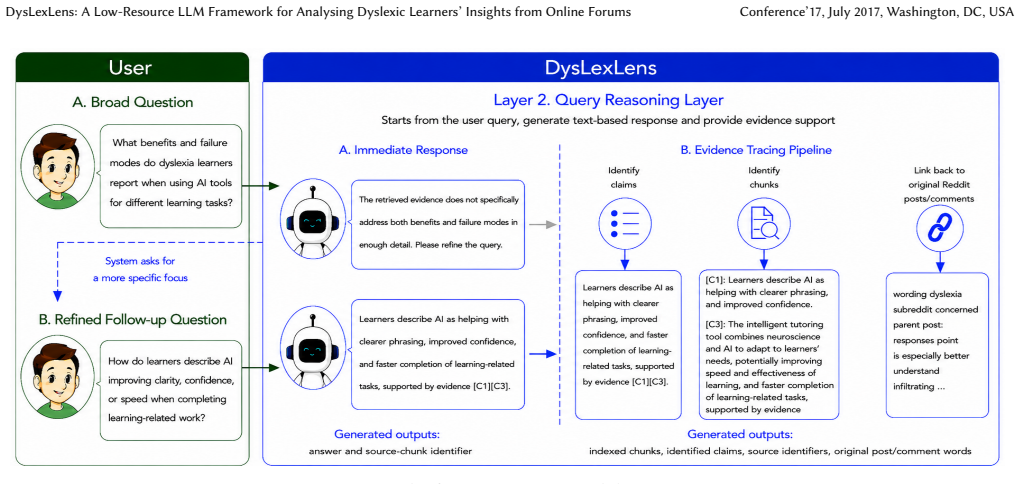
Dictionary-driven filtering combined with knowledge-graph-based query reasoning within the DysLexLens framework to build focused corpora and generate evidence-traceable responses from forum data.
If this is right
- Produces more relevant data from noisy forums by filtering with a dyslexia-AI dictionary.
- Uncovers patterns in dyslexic learners' AI use through LLM-assisted semantic analysis and KG reasoning.
- Measures performance with RAGAS and Query Robustness metrics.
- Validates responses for hallucination and evidence alignment using structured guidelines.
- Allows general application to other low-resource forum analysis tasks.
Where Pith is reading between the lines
- The method could extend to analyzing other neurodiverse groups' interactions with technology.
- Future work might test if the same dictionary approach works across different languages or platforms.
- Integration with more advanced knowledge graphs could improve the depth of insights into user experiences.
Load-bearing premise
The dictionary-driven filtering method produces a corpus that is both sufficiently complete and free of systematic bias relative to the full set of dyslexia-and-AI discussions.
What would settle it
A direct comparison where human experts review the original unfiltered posts and find that key themes about dyslexic learners' AI experiences are missing or misrepresented in the DysLexLens-generated responses would falsify the framework's reliability.
Figures

read the original abstract
Dyslexic learners increasingly use artificial intelligence (AI) tools to support reading, writing, organisation, and study-related tasks. However, their lived experiences with these tools remain largely underexamined. This paper proposes DysLexLens, a low-resource LLM framework, designed to analyse dyslexic learners experience with AI through online forum discussions. DysLexLens is designed as an end-to-end, evidence-traceable architecture which transforms noisy social media posts into a dictionary-driven corpora, provides knowledge-graph (KG)-based question reasoning, generates verifiable query responses, and enables response evaluation through quantitative and human-grounded assessment. DysLexLens has four key features. First, it employs a dictionary-driven filtering method to construct a more focused Reddit corpus on dyslexia and AI, filtering out noisy and weakly related posts to improve the relevance of data collected from low-resource forum contexts. Second, it integrates LLM-assisted semantic analysis with KG-based query reasoning to uncover meaningful patterns. Third, it has quantitative evaluation metrics (RAGAS and Query Robustness) to measure LLM-generated response performance. Fourth, it provides structured qualitative validation guidelines for assessing response quality, with a specific focus on hallucination and evidence alignment. We demonstrate the effectiveness of DysLexLens using dyslexia-related Reddit forum data and 30 questions. The results show its potential generalisability to other low-resource forum data contexts. DysLexLens, sample data, questions and evaluation results are available at Github to support reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DysLexLens, a low-resource LLM framework for analyzing dyslexic learners' experiences with AI from online forums. It describes an end-to-end architecture that applies dictionary-driven filtering to Reddit posts to build a focused corpus, integrates LLM-assisted semantic analysis with knowledge-graph-based query reasoning, generates responses, and evaluates them using RAGAS, Query Robustness metrics, and qualitative guidelines focused on hallucination and evidence alignment. The framework is demonstrated on dyslexia-related Reddit data and 30 questions, with claims of effectiveness and potential generalisability to other low-resource forum contexts; code, data, and results are released on GitHub.
Significance. If the core pipeline holds after validation, the work provides a traceable method for extracting insights from noisy low-resource social media data on specialized topics, combining filtering, KG reasoning, and mixed quantitative/qualitative evaluation. The explicit release of the framework, sample data, questions, and evaluation results on GitHub is a clear strength supporting reproducibility and extension.
major comments (2)
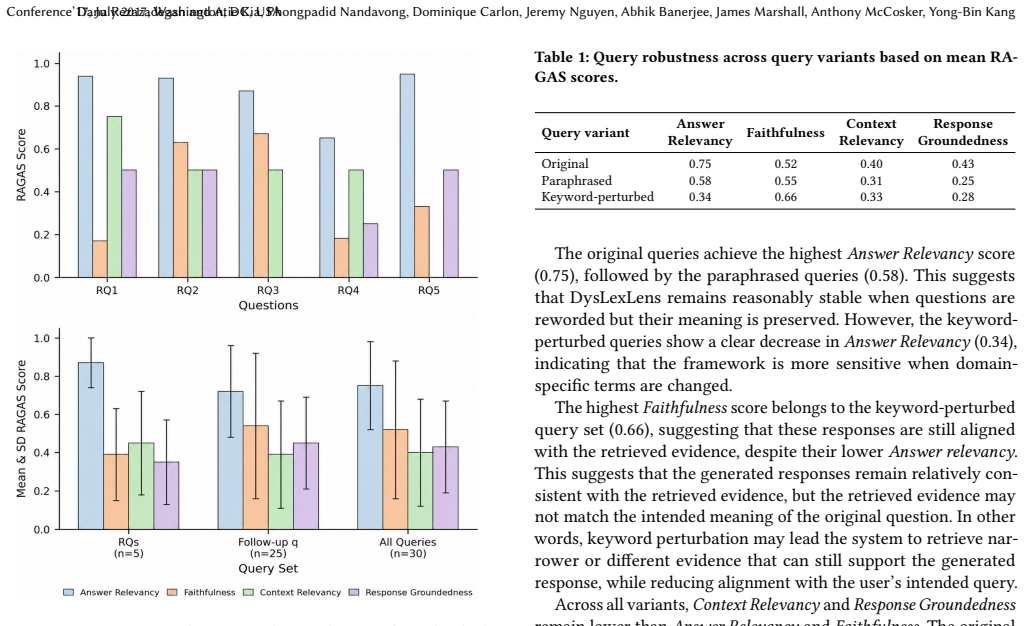
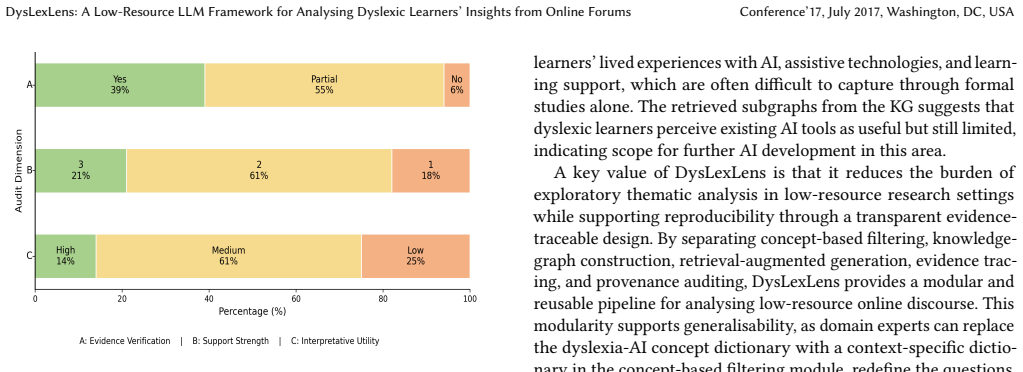
- [§3] §3 (Dictionary-driven filtering): No precision, recall, inter-annotator agreement, or pre-/post-filtering topic distribution comparison is reported for the dictionary method. This is load-bearing because the filtered corpus is the sole input to all downstream KG reasoning, response generation, RAGAS evaluation, and human assessment; without evidence of completeness or lack of systematic bias, the representativeness of the resulting patterns cannot be assessed.
- [Results] Results section (demonstration on 30 questions): The manuscript states that results demonstrate effectiveness and generalisability but supplies no specific quantitative scores, error analysis, baseline comparisons, or statistical tests. This prevents evaluation of the central claim that the framework produces verifiable, high-quality responses.
minor comments (2)
- [Abstract / §1] The abstract and introduction use 'dictionary-driven corpora' and 'verifiable query responses' without defining the exact dictionary construction process or the criteria for verifiability in the main text.
- [Figures / Tables] Figure captions and table headers could more explicitly link each component (filtering, KG, RAGAS) to the evaluation metrics used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, acknowledging the need for stronger validation evidence.
read point-by-point responses
-
Referee: [§3] §3 (Dictionary-driven filtering): No precision, recall, inter-annotator agreement, or pre-/post-filtering topic distribution comparison is reported for the dictionary method. This is load-bearing because the filtered corpus is the sole input to all downstream KG reasoning, response generation, RAGAS evaluation, and human assessment; without evidence of completeness or lack of systematic bias, the representativeness of the resulting patterns cannot be assessed.
Authors: We agree that the absence of precision, recall, inter-annotator agreement, and topic distribution comparisons is a limitation, as the filtering step underpins all subsequent analyses. In the revised manuscript we will report these metrics from a sampled human annotation study (including IAA) and include pre-/post-filtering topic distribution comparisons to demonstrate completeness and absence of systematic bias. revision: yes
-
Referee: [Results] Results section (demonstration on 30 questions): The manuscript states that results demonstrate effectiveness and generalisability but supplies no specific quantitative scores, error analysis, baseline comparisons, or statistical tests. This prevents evaluation of the central claim that the framework produces verifiable, high-quality responses.
Authors: We acknowledge that the results section currently lacks the requested quantitative detail. The revised version will expand this section to report specific RAGAS and Query Robustness scores, include error analysis, add baseline comparisons where feasible, and present appropriate statistical tests to support the claims of effectiveness and generalisability. revision: yes
Circularity Check
No significant circularity; pipeline evaluated on external benchmarks
full rationale
The paper describes a constructed end-to-end pipeline (dictionary filtering of Reddit posts, KG reasoning, RAGAS/Query Robustness metrics, human evaluation) without equations, fitted parameters, or self-referential definitions. All evaluation steps reference external metrics and human assessment rather than reducing to the input corpus by construction. No load-bearing self-citations or uniqueness theorems are invoked in the provided text. The framework is self-contained against external benchmarks, consistent with a normal non-circular methodological contribution.
Axiom & Free-Parameter Ledger
invented entities (1)
-
DysLexLens framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gunilla Almgren Bäck, Emma Lindeblad, Carina Elmqvist, and Idor Svensson
-
[2]
Disability and Rehabilitation: Assistive Technology 19, 4 (2024), 1217–1227
Dyslexic students’ experiences in using assistive technology to support written language skills: a five-year follow-up. Disability and Rehabilitation: Assistive Technology 19, 4 (2024), 1217–1227
2024
-
[3]
Brian Bauer, Raquel Norel, Alex Leow, Zad Abi Rached, Bo Wen, and Guillermo Cecchi. 2024. Using large language models to understand suicidality in a social media–based taxonomy of mental health disorders: Linguistic analysis of reddit posts. JMIR mental health 11 (2024), e57234
2024
-
[4]
Richard Bolden and Jean Moscarola. 2000. Bridging the quantitative-qualitative divide: the lexical approach to textual data analysis. Social science computer review 18, 4 (2000), 450–460
2000
-
[5]
Hugh W Catts, Nicole Patton Terry, Christopher J Lonigan, Donald L Compton, Richard K Wagner, Laura M Steacy, Kelly Farquharson, and Yaacov Petscher. 2024. Revisiting the definition of dyslexia. Annals of Dyslexia 74, 3 (2024), 282–302
2024
-
[6]
Medini Chopra, Anindita Chatterjee, Lipika Dey, and Partha Pratim Das. 2024. Deciphering psycho-social effects of Eating Disorder: Analysis of Reddit Posts using Large Language Model (LLM) s and Topic Modeling. InProceedings of the 4th International Conference on Natural Language Processing for Digital Humanities . 156–164
2024
-
[7]
Xiang Deng, Vasilisa Bashlovkina, Feng Han, Simon Baumgartner, and Michael Bendersky. 2023. LLMs to the Moon? Reddit Market Sentiment Analysis with Large Language Models. In Companion Proceedings of the ACM Web Conference 2023 (Austin, TX, USA) (WWW ’23 Companion). Association for Computing Machinery, New York, NY, USA, 1014–1019. doi:10.1145/3543873.3587605
-
[8]
Xiang Deng, Vasilisa Bashlovkina, Feng Han, Simon Baumgartner, and Michael Bendersky. 2023. What do LLMs Know about Financial Markets? A Case Study on Reddit Market Sentiment Analysis. In Companion Proceedings of the ACM Web Conference 2023 (Austin, TX, USA) (WWW ’23 Companion). Association for Computing Machinery, New York, NY, USA, 107–110. doi:10.1145/...
-
[9]
Katharina Galuschka, Ruth Görgen, Julia Kalmar, Stefan Haberstroh, Xenia Schmalz, and Gerd Schulte-Körne. 2020. Effectiveness of Spelling Interventions for Learners with Dyslexia: A Meta-Analysis and Systematic Review.Educational Psychologist 55, 1 (Jan. 2020), 1–20. doi:10.1080/00461520.2019.1659794
-
[10]
Katharina Galuschka, Elena Ise, Kathrin Krick, and Gerd Schulte-Körne. 2014. Ef- fectiveness of Treatment Approaches for Children and Adolescents with Reading Disabilities: A Meta-Analysis of Randomized Controlled Trials. PLoS ONE 9, 2 (Feb. 2014), e89900. doi:10.1371/journal.pone.0089900
-
[11]
Georgiou, Dalia Martinez, Ana Paula Alves Vieira, Andrea Antoniuk, Sandra Romero, and Kan Guo
George K. Georgiou, Dalia Martinez, Ana Paula Alves Vieira, Andrea Antoniuk, Sandra Romero, and Kan Guo. 2022. A Meta-Analytic Review of Comprehension Deficits in Students with Dyslexia. Annals of Dyslexia 72, 2 (July 2022), 204–248. doi:10.1007/s11881-021-00244-y
-
[12]
Angelique Aitken, Michael Hebert, April Camping, Tanya Santangelo, Karen R
Steve Graham, A. Angelique Aitken, Michael Hebert, April Camping, Tanya Santangelo, Karen R. Harris, Kristi Eustice, Joseph D. Sweet, and Clarence Ng
-
[13]
Journal of Educational Psychology 113, 8 (Nov
Do Children with Reading Difficulties Experience Writing Difficulties? A Meta-Analysis. Journal of Educational Psychology 113, 8 (Nov. 2021), 1481–1506. doi:10.1037/edu0000643
-
[14]
Charlotte H. Hamilton Clark. 2024. Dyslexia Concealment in Higher Education: Exploring Students’ Disclosure Decisions in the Face of UK Universities’ Ap- proach to Dyslexia. Journal of Research in Special Educational Needs 24, 4 (Oct. 2024), 922–935. doi:10.1111/1471-3802.12683
-
[15]
Kyuha Jung, Gyuho Lee, Yuanhui Huang, and Yunan Chen. 2025. ’I’ve talked to ChatGPT about my issues last night. ’: Examining Mental Health Conversations with Large Language Models through Reddit Analysis. Proc. ACM Hum.-Comput. Interact. 9, 7, Article CSCW356 (Oct. 2025), 25 pages. doi:10.1145/3757537
-
[16]
Efstathios Kaloudis, Victoria Kouti, Foteini-Maria Triantafillou, Patroklos Ven- touris, Rafail Pavlidis, and Vasiliki Bountziouka. 2025. AI-Powered Analysis of Weight Loss Reports from Reddit: Unlocking Social Media’s Potential in Dietary Assessment. Nutrients 17, 5 (2025), 818
2025
-
[17]
Seoyun Kim, Junyeop Cha, Dongjae Kim, and Eunil Park. 2023. Understand- ing mental health issues in different subdomains of social networking services: computational analysis of text-based Reddit posts. Journal of Medical Internet Research 25 (2023), e49074
2023
-
[18]
Lotte Thereza Kok. 2022. Developing a Dyslectic Identity on Reddit A thematic analysis of /r/Dyslexia. Master’s thesis. http://hdl.handle.net/2105/65001
2022
-
[19]
Udo Kuckartz. 2019. Qualitative text analysis: A systematic approach. In Com- pendium for early career researchers in mathematics education . Springer, 181–197
2019
-
[20]
Rebeka Lerga, Sanja Candrlic, and Alen Jakupovic. 2021. A Review on Assistive Technologies for Students with Dyslexia. CSEDU (2) (2021), 64–72
2021
-
[21]
Shaping ChatGPT into my Digital Therapist
Xiaochen Luo, Smita Ghosh, Jacqueline L Tilley, Patrica Besada, Jinqiu Wang, and Yangyang Xiang. 2025. “Shaping ChatGPT into my Digital Therapist”: A thematic analysis of social media discourse on using generative artificial intelligence for mental health. Digital health 11 (2025), 20552076251351088
2025
-
[22]
G Reid Lyon, Sally E Shaywitz, and Bennett A Shaywitz. 2003. A definition of dyslexia. Annals of dyslexia 53, 1 (2003), 1–14
2003
-
[23]
Thom Nevill and Martin Forsey. 2023. The Social Impact of Schooling on Students with Dyslexia: A Systematic Review of the Qualitative Research on the Primary and Secondary Education of Dyslexic Students. Educational Research Review 38 (Feb. 2023), 100507. doi:10.1016/j.edurev.2022.100507
-
[24]
Andrea Paglialunga and Sergio Melogno. 2025. The Effectiveness of Artificial Intelligence-Based Interventions for Students with Learning Disabilities: A Sys- tematic Review. Brain Sciences 15, 8 (July 2025), 806. doi:10.3390/brainsci15080806
-
[25]
Helen Ross. 2021. ‘I’m Dyslexic but What Does That Even Mean?’: Young People’s Experiences of Dyslexia Support Interventions in Mainstream Class- rooms. Scandinavian Journal of Disability Research 23, 1 (Oct. 2021), 284–294. doi:10.16993/sjdr.782
-
[26]
Sidharta Sidharta, Hady Pranoto, Frederik Masri Gasa, Nur Kholis, and Ardvin Kester S. Ong. 2025. Analysis of Public Sentiment on the 17+8 People’s Demands Issue Using IndoBERT and DistilBERT with LLM-Based Data Annotation. In 2025 International Conference on Informatics, Multimedia, Cyber and Information System (ICIMCIS). 575–580. doi:10.1109/ICIMCIS6850...
-
[27]
Christelle Smith and MJ Hattingh. 2020. Assistive technologies for students with dyslexia: a systematic literature review. In International Conference on Innovative Technologies and Learning. Springer, 504–513
2020
-
[28]
Snowling, Charles Hulme, and Kate Nation
Margaret J. Snowling, Charles Hulme, and Kate Nation. 2020. Defining and Understanding Dyslexia: Past, Present and Future. Oxford Review of Education 46, 4 (July 2020), 501–513. doi:10.1080/03054985.2020.1765756
-
[29]
Richard K Wagner, Fotena A Zirps, Ashley A Edwards, Sarah G Wood, Rachel E Joyner, Betsy J Becker, Guangyun Liu, and Bethany Beal. 2020. The prevalence of dyslexia: A new approach to its estimation. Journal of learning disabilities 53, 5 (2020), 354–365
2020
-
[30]
Andrew Walker, Jerik Leung, Aishwarya Alagappan, Swati Rajwal, Sahithi Lakamana, Tricia Park, Nathan Le, Anushka Irani, Abeed Sarker, Titilola Falasinnu, and Selen Bozkurt. 2026. Centering Patient Voices in Lupus Pain: A Biopsychosocial Analysis of Reddit Narratives Using Large Language Models. Arthritis Care & Research 78, 1 (2026), 123–133. arXiv:https:...
-
[31]
Jia Rong Yap, Thirishankari Aruthanan, and Mellisa Chin. 2025. Artificial Intelli- gence in Dyslexia Research and Education: A Scoping Review. IEEE Access 13 (2025), 7123–7134. doi:10.1109/ACCESS.2025.3526189
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.