A Nash Equilibrium Framework For Training-Free Multimodal Step Verification
Pith reviewed 2026-05-20 06:06 UTC · model grok-4.3
The pith
Modeling verification as a Nash equilibrium game among specialized judges yields closed-form scores that detect unstable reasoning steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
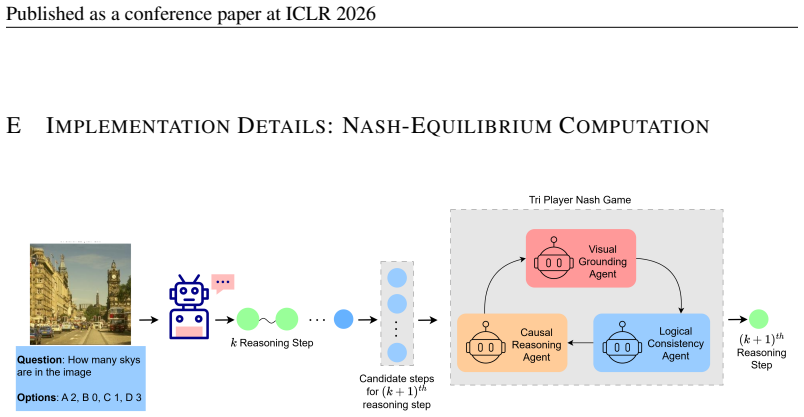
Treating step-wise verification as a coordination problem among specialized judges, formalized as a Nash equilibrium game in which agreement signals valid steps while disagreement reveals instability, admits a closed-form solution for equilibrium scores that enables disagreement-aware filtering and stability-conscious ranking of reasoning steps.
What carries the argument
Nash equilibrium game among specialized judges, solved via closed-form computation to convert agreement and disagreement into verification scores.
If this is right
- Disagreement among judges supplies an explicit signal for filtering invalid reasoning steps.
- Equilibrium scores enable ranking steps according to their inferred stability.
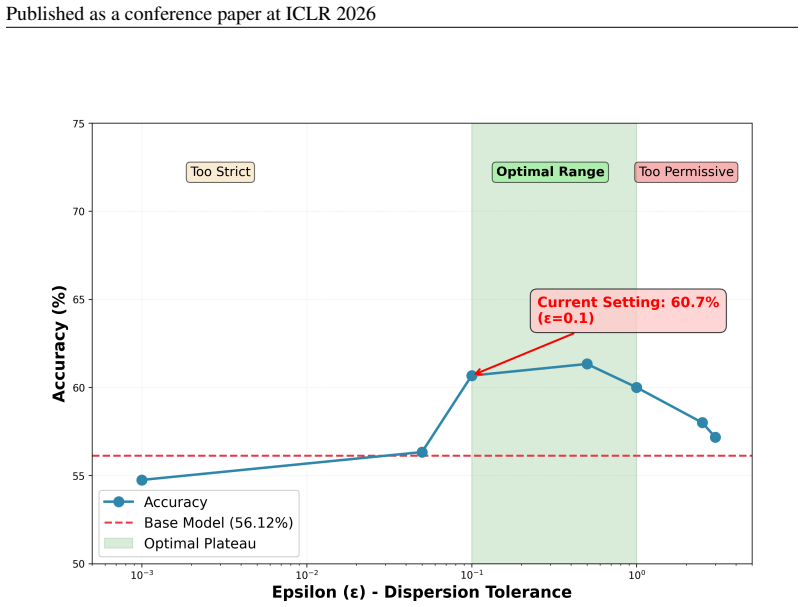
- The method delivers 2.4% to 5.2% gains over baseline models across six benchmarks.
- Performance remains competitive with learned critics without requiring labeled data or task-specific training.
- Cross-modal agreement functions as a verification signal distinct from average confidence alone.
Where Pith is reading between the lines
- The same equilibrium construction could be applied to multi-agent verification pipelines beyond multimodal reasoning.
- Integration into existing LLM pipelines might improve chain-of-thought reliability at negligible extra cost.
- Experiments on single-modality tasks would clarify whether cross-modal disagreement is essential to the observed gains.
Load-bearing premise
The interaction among judges can be modeled as a Nash equilibrium game whose agreement and disagreement patterns reliably indicate whether a reasoning step is valid.
What would settle it
If the equilibrium scores produce no accuracy gain over simple averaging when applied to the same six benchmarks and the same set of judge outputs, the claim that the game formulation improves verification would be refuted.
Figures










read the original abstract
Multimodal large language models often generate reasoning chains containing subtle errors that lead to incorrect answers. Current verification approaches have notable limitations. Learned critics need extensive labeled data and show inconsistent performance across different tasks. Meanwhile, existing training-free methods simply average scores from different sources, missing a key insight: when these scores disagree, that disagreement itself carries important information about whether a reasoning step is truly valid or not. We propose a training-free verification approach that treats step-wise verification as a coordination problem among specialized judges. We formalize these judges' interaction as a Nash equilibrium game where agreement signals valid steps while disagreement reveals instability. Our method computes equilibrium scores through a closed-form solution, enabling both disagreement-aware filtering and stability-conscious ranking of reasoning steps. Evaluated across six benchmarks, our approach achieves consistent improvements of 2.4% to 5.2% over baseline models and shows competitive performance against learned critics, demonstrating that cross-modal agreement (not just average confidence) provides robust verification signals without task-specific adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a training-free verification method for reasoning steps generated by multimodal LLMs. It models interactions among specialized judges as a non-cooperative Nash equilibrium game in which cross-modal agreement indicates valid steps and disagreement signals instability. A closed-form solution for equilibrium scores is derived from this game, supporting disagreement-aware filtering and stability-conscious ranking. Experiments across six benchmarks report consistent gains of 2.4%–5.2% over simple averaging baselines and competitive results against learned critics.
Significance. If the closed-form solution is rigorously shown to be a true Nash equilibrium (i.e., derived from explicit payoff functions with verified best-response properties), the work would supply a principled, parameter-free alternative to data-intensive learned verifiers. By treating disagreement itself as an informative signal rather than noise, the approach could improve robustness in multimodal reasoning without task-specific adaptation.
major comments (2)
- [§3.2, Eq. (7)] §3.2, Eq. (7): The closed-form equilibrium score is asserted to follow directly from the Nash game definition, yet the payoff functions (presumably encoding agreement/disagreement across modalities) are not stated explicitly. Without these definitions it is impossible to confirm that the reported expression satisfies the Nash condition that no judge can unilaterally deviate to increase its utility.
- [§4.2, Table 2] §4.2, Table 2: The reported 2.4–5.2% gains are shown relative to averaging baselines, but no ablation isolates the contribution of the equilibrium computation from simpler disagreement-based filtering. This leaves open whether the game-theoretic framing is load-bearing for the observed improvements.
minor comments (2)
- [§3] The notation for judge utilities and equilibrium scores should be introduced with a single consolidated table to avoid repeated re-definition across sections.
- [Figure 3] Figure 3 caption does not specify the exact disagreement metric used to color the stability ranking; adding this detail would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to clarify our contributions. We address each major comment below and describe the revisions we will implement.
read point-by-point responses
-
Referee: [§3.2, Eq. (7)] §3.2, Eq. (7): The closed-form equilibrium score is asserted to follow directly from the Nash game definition, yet the payoff functions (presumably encoding agreement/disagreement across modalities) are not stated explicitly. Without these definitions it is impossible to confirm that the reported expression satisfies the Nash condition that no judge can unilaterally deviate to increase its utility.
Authors: We appreciate the referee highlighting this point. The manuscript describes the judges' utilities in terms of agreement (positive payoff for alignment with cross-modal consensus) and disagreement (negative payoff for deviation), but does not present the payoff functions in explicit mathematical form. In the revised manuscript we will add explicit payoff definitions in §3.2, derive the best-response conditions, and verify that the closed-form solution in Eq. (7) satisfies the Nash equilibrium property. revision: yes
-
Referee: [§4.2, Table 2] §4.2, Table 2: The reported 2.4–5.2% gains are shown relative to averaging baselines, but no ablation isolates the contribution of the equilibrium computation from simpler disagreement-based filtering. This leaves open whether the game-theoretic framing is load-bearing for the observed improvements.
Authors: The referee correctly observes that the current experiments compare against averaging but do not isolate the equilibrium computation from a simpler disagreement filter. While the closed-form solution is designed to incorporate disagreement as a stability signal rather than mere noise, an explicit ablation would strengthen the presentation. We will add such an ablation to §4.2 in the revision, comparing the full Nash equilibrium scores against a non-game-theoretic disagreement filter that thresholds on cross-modal variance alone. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper formalizes judge interactions as a Nash equilibrium game and states that equilibrium scores are computed via a closed-form solution. No equations, payoff definitions, or self-citations are quoted in the provided text that reduce the claimed closed-form result to a direct renaming or fitting of the input judge scores by construction. The derivation is presented as introducing a new coordination framing rather than deriving outputs tautologically from inputs, making the central claim self-contained against external benchmarks. This is the most common honest finding when explicit reduction cannot be exhibited.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ui(si,s−i)=−(si−s̄−i)²−λi(si−ŝi)² … si*=s̄*−i+λiŝi/(1+λi)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Nash equilibrium game where agreement signals valid steps while disagreement reveals instability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Self-Rewarding Vision-Language Model via Reasoning Decomposition , author=. 2025 , eprint=
work page 2025
-
[2]
LLaVA-Critic-R1: Your Critic Model is Secretly a Strong Policy Model , author=. 2025 , eprint=
work page 2025
-
[3]
Dutta, Souradeep and Chen, Xin and Jha, Susmit and Sankaranarayanan, Sriram and Tiwari, Ashish , title =. Proceedings of the 22nd ACM International Conference on Hybrid Systems: Computation and Control , pages =. 2019 , isbn =. doi:10.1145/3302504.3313351 , abstract =
-
[4]
Visual Instruction Tuning , url =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , booktitle =. Visual Instruction Tuning , url =
- [5]
-
[6]
Evaluating Object Hallucination in Large Vision-Language Models
Evaluating Object Hallucination in Large Vision-Language Models , author=. arXiv preprint arXiv:2305.10355 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
A Survey on Hallucination in Large Vision-Language Models
Hallucination in Large Vision-Language Models: A Survey , author=. arXiv preprint arXiv:2402.00253 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning , author=. arXiv preprint arXiv:2410.08146 , year=
work page internal anchor Pith review arXiv
-
[10]
arXiv preprint arXiv:2310.16045 , year=
Woodpecker: Hallucination Correction for Multimodal Large Language Models , author=. arXiv preprint arXiv:2310.16045 , year=
-
[11]
AAAI Conference on Artificial Intelligence , year=
Detecting and Preventing Hallucinations in Large Vision Language Models , author=. AAAI Conference on Artificial Intelligence , year=
-
[12]
H., Chen, S., Zhang, R., Chen, J., Wu, X., Zhang, Z., Chen, Z., Li, J., Wan, X., and Wang, B
ALLAVA: Harnessing GPT4V-Synthesized Data for A Lite Vision-Language Model , author=. arXiv preprint arXiv:2402.11684 , year=
-
[13]
Proceedings of the National Academy of Sciences , volume=
Equilibrium Points in N-Person Games , author=. Proceedings of the National Academy of Sciences , volume=
-
[15]
arXiv preprint arXiv:2303.11301 , year=
Visual Reasoning with Multimodal Chain-of-Thought , author=. arXiv preprint arXiv:2303.11301 , year=
-
[17]
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
work page 2023
-
[18]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. arXiv preprint arXiv:2303.11366 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
MM-CRITIC: A Holistic Evaluation of Large Multimodal Models as Multimodal Critique , author=. 2025 , eprint=
work page 2025
-
[20]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Large Language Models as Judges , author=. arXiv preprint arXiv:2306.05685 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
G-Eval: NLG Evaluation using GPT-4 , author=. arXiv preprint arXiv:2303.16634 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
OCRBench: On the Hidden Mystery of OCR in Large Multimodal Models
Confidence Estimation in Vision-Language Models , author=. arXiv preprint arXiv:2305.07895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [23]
-
[24]
Twenty Lectures on Algorithmic Game Theory , author=
-
[25]
Multimodal Chain-of-Thought Reasoning in Language Models , author=. 2024 , eprint=
work page 2024
- [26]
-
[27]
M ^3 CoT: A Novel Benchmark for Multi-Domain Multi-step Multi-modal Chain-of-Thought , author=. 2024 , eprint=
work page 2024
-
[28]
Improving Factuality and Reasoning in Language Models through Multiagent Debate , author=. 2023 , eprint=
work page 2023
-
[29]
Counterfactual Self-Questioning for Stable Policy Optimization in Language Models , author=. 2025 , eprint=
work page 2025
- [30]
-
[31]
Math-Shepherd: Verifying and Reinforcing Mathematical Reasoning , author=. ACL , year=
-
[32]
OmegaPRM: Scalable Process Reward Modeling via Tree Search , author=. ICLR , year=
-
[33]
arXiv preprint arXiv:2502.13383 , year=
MM-Verify: Enhancing Multimodal Reasoning with Chain-of-Thought Verification , author=. arXiv preprint arXiv:2502.13383 , year=
-
[34]
VisualPRM400K: An Effective Dataset for Training Multimodal Process Reward Models , author=. ICLR , year=
-
[35]
MathVista: Evaluating Mathematical Reasoning in Visual Contexts , author=. ICLR , year=
-
[36]
MMMU: A Massive Multi-discipline Multimodal Understanding Benchmark , author=. CVPR , year=
-
[37]
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , author=. 2024 , eprint=
work page 2024
- [38]
-
[39]
Multimodal Chain-of-Thought Reasoning in Language Models
Multimodal Chain-of-Thought Reasoning in Language Models , author=. arXiv preprint arXiv:2302.00923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles , url =
Lakshminarayanan, Balaji and Pritzel, Alexander and Blundell, Charles , booktitle =. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles , url =
-
[41]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Improving Factuality and Reasoning in Language Models through Multi-Agent Debate , author=. arXiv preprint arXiv:2305.14325 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
arXiv preprint arXiv:2512.11099 , year=
VGent: Visual Grounding via Modular Design for Disentangling Reasoning and Prediction , author=. arXiv preprint arXiv:2512.11099 , year=
-
[43]
European Conference on Computer Vision (ECCV) , year=
LLaVA-Grounding: Grounded Visual Chat with Large Multimodal Models , author=. European Conference on Computer Vision (ECCV) , year=
-
[44]
arXiv preprint arXiv:2402.10884 , year=
Multi-modal Preference Alignment Remedies Degradation of Visual Instruction Tuning on Language Model , author=. arXiv preprint arXiv:2402.10884 , year=
-
[45]
arXiv preprint arXiv:2509.25848 , year=
More Thought, Less Accuracy? On the Dual Nature of Reasoning in Vision-Language Models , author=. arXiv preprint arXiv:2509.25848 , year=
-
[46]
MM-PRM: Enhancing Multimodal Mathematical Reasoning with Scalable Step-Level Supervision , author=. 2025 , eprint=
work page 2025
-
[47]
VisualPRM: An Effective Process Reward Model for Multimodal Reasoning , author=. 2025 , eprint=
work page 2025
-
[48]
Sherlock: Self-Correcting Reasoning in Vision-Language Models , author=. 2025 , eprint=
work page 2025
-
[49]
Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning , author=. 2025 , eprint=
work page 2025
-
[50]
Econometrica: Journal of the Econometric Society , pages=
Existence and uniqueness of equilibrium points for concave n-person games , author=. Econometrica: Journal of the Econometric Society , pages=. 1965 , publisher=
work page 1965
-
[51]
3DSRBench: A Comprehensive 3D Spatial Reasoning Benchmark , author=. 2025 , eprint=
work page 2025
-
[52]
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs , author=. 2024 , eprint=
work page 2024
-
[53]
BLINK: Multimodal Large Language Models Can See but Not Perceive , author=. 2024 , eprint=
work page 2024
-
[54]
Are We on the Right Way for Evaluating Large Vision-Language Models? , author=. 2024 , eprint=
work page 2024
- [55]
-
[56]
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking , author=. 2024 , eprint=
work page 2024
-
[57]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Weaver: Shrinking the Generation-Verification Gap by Scaling Compute for Verification , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
- [58]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.