From Structure to Synergy: A Survey of Vision-Language Perception Paradigm Evolution in Multimodal Large Language Models
Pith reviewed 2026-06-26 01:49 UTC · model grok-4.3
The pith
MLLM perception is formalized as a single unified vision-language capability that evolves through five distinct paradigms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
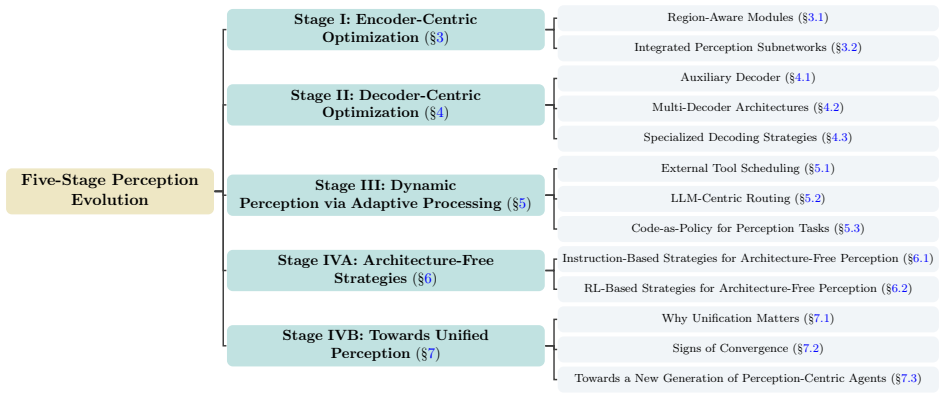
MLLM perception is an intrinsic, unified vision-language capability analogous to human innate perception; the paper introduces a five-stage taxonomy that traces its paradigm evolution from early separate structures to synergistic integration and identifies open challenges toward general unified multimodal intelligence.
What carries the argument
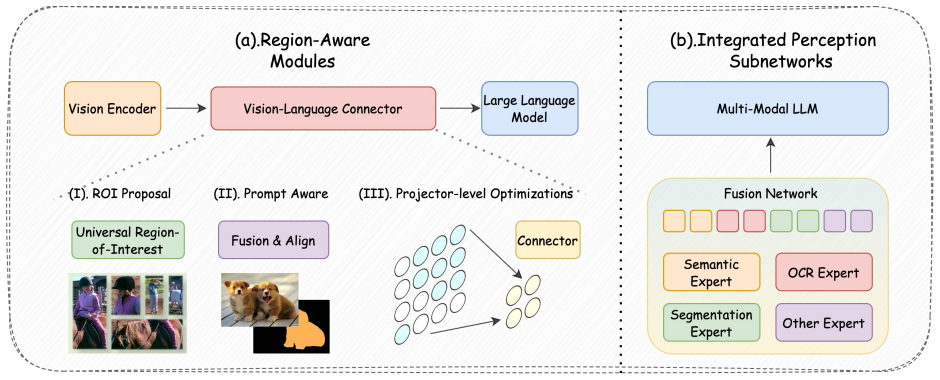
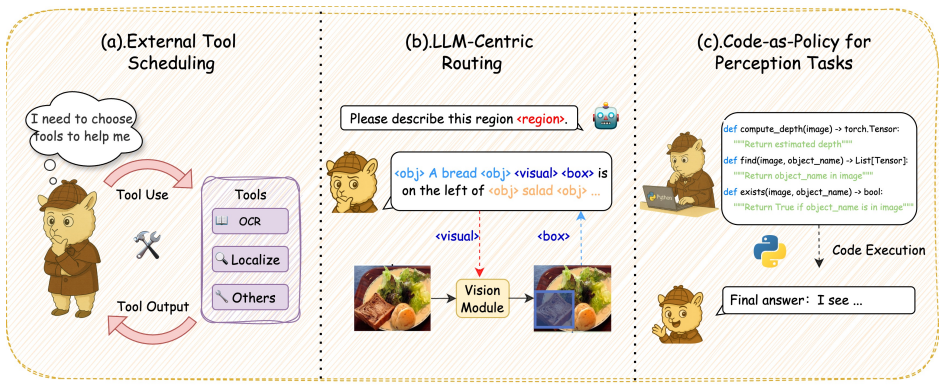
A five-stage taxonomy tracing the paradigm evolution of MLLM perception from structure to synergy.
If this is right
- Design of future MLLMs will treat perception as one integrated module rather than separate vision and language components.
- Evaluation benchmarks will shift toward measuring cross-modal synergy instead of isolated modality performance.
- Research roadmaps will prioritize methods that advance the later stages of the taxonomy.
- Progress toward general multimodal intelligence will be measured by how well models achieve unified perception.
Where Pith is reading between the lines
- The taxonomy could be tested by checking whether new models fit cleanly into one of the five stages or require an additional stage.
- Insights from this survey might suggest concrete experiments that combine perception tasks across stages to measure synergy gains.
- If the unified lens holds, it would imply that separate vision-only or language-only improvements are insufficient for the next generation of models.
Load-bearing premise
Existing surveys are too fragmented because they examine vision and language separately, so a single unified vision-language lens is the right way to track how perception develops in these models.
What would settle it
Discovery of an earlier survey that already presents a unified five-stage taxonomy of vision-language perception in MLLMs would falsify the claim that this is the first such systematic treatment.
Figures

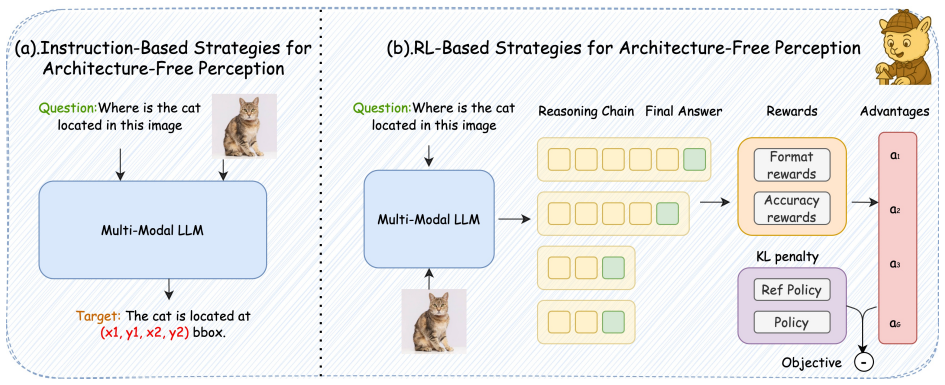
read the original abstract
Multimodal Large Language Models (MLLMs) have recently made remarkable progress in unifying vision-language understanding and reasoning, especially following the introduction of models such as OpenAI's O-series and DeepSeek's R-series, which have driven a paradigm shift toward perception-centric intelligence. However, there remains a lack of systematic surveys that examine perception from a truly unified vision-language perspective -- one that treats vision and language as an inseparable modality. Existing reviews are often fragmented, focusing separately on either vision or language, and thus rarely capture the cross-modal evolution of perception as an integrated capability. To bridge this gap, we present the first systematic survey of unified vision-language perception in MLLMs. Specifically, we (1) formalize MLLM perception as an intrinsic, unified vision-language capability analogous to human innate perception, (2) introduce a five-stage taxonomy tracing the paradigm evolution of MLLM perception and survey representative methods and milestones at each phase, and (3) identify open challenges and outline promising research directions toward truly general, unified multimodal intelligence. We hope our study will provide both a foundational understanding and an actionable roadmap to foster further innovation on the path toward artificial general intelligence (AGI).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey on vision-language perception in Multimodal Large Language Models (MLLMs). It formalizes MLLM perception as an intrinsic, unified vision-language capability analogous to human innate perception, claims to be the first systematic survey from this unified perspective, introduces a five-stage taxonomy tracing paradigm evolution, surveys representative methods and milestones at each stage, and identifies open challenges with future research directions toward general multimodal intelligence and AGI.
Significance. If the five-stage taxonomy is well-motivated and the survey comprehensively covers the literature without major omissions, the work could provide a useful organizational lens for the field, highlighting the shift to perception-centric models following recent O-series and R-series models. The unified-modality framing may help consolidate fragmented prior reviews, though its value depends on explicit comparisons to existing surveys.
major comments (1)
- [Abstract] Abstract: The assertion that 'existing reviews are often fragmented, focusing separately on either vision or language' is central to the novelty claim but lacks supporting citations or a dedicated comparison subsection; without this, the justification for the five-stage taxonomy as filling a unique gap remains under-supported.
minor comments (2)
- The five-stage taxonomy should include explicit classification criteria or decision rules for assigning methods to stages to enhance reproducibility.
- Consider adding a summary table listing the five stages, key models/milestones, and representative papers for improved readability.
Simulated Author's Rebuttal
Thank you for the constructive review and the minor revision recommendation. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'existing reviews are often fragmented, focusing separately on either vision or language' is central to the novelty claim but lacks supporting citations or a dedicated comparison subsection; without this, the justification for the five-stage taxonomy as filling a unique gap remains under-supported.
Authors: We agree the abstract claim would be strengthened by explicit citations and a brief comparison. In revision we will (1) add 3-4 representative citations to prior surveys that treat vision or language in isolation and (2) insert a short paragraph in the introduction that contrasts those works with our unified perception framing, thereby better motivating the five-stage taxonomy. revision: yes
Circularity Check
No significant circularity; survey with no derivation chain
full rationale
This is a literature review paper that formalizes a concept and proposes a five-stage taxonomy based on surveying existing external work. No equations, predictions, fitted parameters, or load-bearing self-citations appear in the provided text or abstract. The central claims are organizational and do not reduce to any input by construction, satisfying the criteria for a self-contained survey with score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Wang, L. Yuan, Y. Zhang, H. Sun, Tarsier: Recipes for training and evaluating large video description models, arXiv preprint arXiv:2407.00634 (2024)
arXiv 2024
-
[2]
W. Chai, E. Song, Y. Du, C. Meng, V. Madhavan, O. Bar-Tal, J.-N. Hwang, S. Xie, C. D. Manning, Auroracap: Efficient, performant video detailed captioning and a new benchmark, arXiv preprint arXiv:2410.03051 (2024)
arXiv 2024
-
[3]
L. Yu, P. Poirson, S. Yang, A. C. Berg, T. L. Berg, Modeling context in referring expressions, in: European conference on computer vision, Springer, 2016, pp. 69–85
2016
-
[4]
X. Lai, Z. Tian, Y. Chen, Y. Li, Y. Yuan, S. Liu, J. Jia, Lisa: Reasoning segmentation via large language model, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9579–9589
2024
-
[5]
Y. Liu, H. Duan, Y. Zhang, B. Li, S. Zhang, W. Zhao, Y. Yuan, J. Wang, C. He, Z. Liu, et al., Mmbench: Is your multi-modal model an all-around player?, in: European conference on computer vision, Springer, 2024, pp. 216–233
2024
-
[6]
A. Masry, D. X. Long, J. Q. Tan, S. Joty, E. Hoque, Chartqa: A benchmark for question answering about charts with visual and logical reasoning, arXiv preprint arXiv:2203.10244 (2022)
Pith/arXiv arXiv 2022
-
[7]
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft coco: Common objects in context, in: European conference on computer vision, Springer, 2014, pp. 740–755. 29
2014
-
[8]
P. Wu, S. Xie, V?: Guided visual search as a core mechanism in multimodal llms, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2024, pp. 13084–13094
2024
-
[9]
J. Chen, T. Liang, S. Siu, Z. Wang, K. Wang, Y. Wang, Y. Ni, W. Zhu, Z. Jiang, B. Lyu, et al., Mega-bench: Scaling multimodal evaluation to over 500 real-world tasks, arXiv preprint arXiv:2410.10563 (2024)
arXiv 2024
-
[10]
M.A.L.Ralph, E.Jefferies, K.Patterson, T.T.Rogers, Theneuralandcomputational bases of semantic cognition, Nature reviews neuroscience 18 (2017) 42–55
2017
-
[11]
Sapkota, M
R. Sapkota, M. Karkee, Object detection with multimodal large vision-language mod- els: An in-depth review, Available at SSRN 5233953 (2025)
2025
-
[12]
Y. Shen, C. Li, F. Xiong, J.-O. Jeong, T. Wang, M. Latman, M. Unberath, Reasoning segmentationforimagesandvideos: Asurvey, arXivpreprintarXiv:2505.18816(2025)
arXiv 2025
-
[13]
Y.Wang, S.Wu, Y.Zhang, S.Yan, Z.Liu, J.Luo, H.Fei, Multimodalchain-of-thought reasoning: A comprehensive survey, arXiv preprint arXiv:2503.12605 (2025)
Pith/arXiv arXiv 2025
-
[14]
Q. Chen, L. Qin, J. Liu, D. Peng, J. Guan, P. Wang, M. Hu, Y. Zhou, T. Gao, W. Che, Towards reasoning era: A survey of long chain-of-thought for reasoning large language models, arXiv preprint arXiv:2503.09567 (2025)
Pith/arXiv arXiv 2025
-
[15]
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al., Training verifiers to solve math word problems, arXiv preprint arXiv:2110.14168 (2021)
Pith/arXiv arXiv 2021
-
[16]
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. W. He, V. Myers, M. J. Kim, M. Du, et al., Bridgedata v2: A dataset for robot learning at scale, in: Conference on Robot Learning, PMLR, 2023, pp. 1723–1736
2023
-
[17]
Z. Guo, R. Xu, Y. Yao, J. Cui, Z. Ni, C. Ge, T.-S. Chua, Z. Liu, G. Huang, Llava- uhd: an lmm perceiving any aspect ratio and high-resolution images, in: European Conference on Computer Vision, Springer, 2024, pp. 390–406
2024
-
[18]
D. Liu, R. Zhang, L. Qiu, S. Huang, W. Lin, S. Zhao, S. Geng, Z. Lin, P. Jin, K. Zhang, et al., Sphinx-x: Scaling data and parameters for a family of multi-modal large lan- guage models, arXiv preprint arXiv:2402.05935 (2024)
arXiv 2024
-
[19]
C. X. Liang, P. Tian, C. H. Yin, Y. Yua, W. An-Hou, L. Ming, T. Wang, Z. Bi, M. Liu, A comprehensive survey and guide to multimodal large language models in vision-language tasks, arXiv preprint arXiv:2411.06284 (2024)
arXiv 2024
-
[20]
D. Caffagni, F. Cocchi, L. Barsellotti, N. Moratelli, S. Sarto, L. Baraldi, M. Cornia, R. Cucchiara, The revolution of multimodal large language models: a survey, arXiv preprint arXiv:2402.12451 (2024). 30
arXiv 2024
- [21]
-
[22]
T. Wang, Z. Jiang, Z. He, S. Tong, W. Yang, Y. Zheng, Z. Li, Z. He, H. Gong, Towards hierarchicalmulti-steprewardmodelsforenhanced reasoninginlargelanguage models, arXiv preprint arXiv:2503.13551 (2025)
Pith/arXiv arXiv 2025
-
[23]
C. Zhou, M. Wang, Y. Ma, C. Wu, W. Chen, Z. Qian, X. Liu, Y. Zhang, J. Wang, H. Xu, et al., From perception to cognition: A survey of vision-language interac- tive reasoning in multimodal large language models, arXiv preprint arXiv:2509.25373 (2025)
arXiv 2025
-
[24]
K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask r-cnn, in: Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961–2969
2017
-
[25]
X. Zhao, X. Li, H. Duan, H. Huang, Y. Li, K. Chen, H. Yang, Mg-llava: Towards multi-granularity visual instruction tuning, arXiv preprint arXiv:2406.17770 (2024)
arXiv 2024
-
[26]
Zhang, X
Y. Zhang, X. Huang, J. Ma, Z. Li, Z. Luo, Y. Xie, Y. Qin, T. Luo, Y. Li, S. Liu, et al., Recognize anything: A strong image tagging model, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 1724–1732
2024
-
[27]
Minderer, A
M. Minderer, A. Gritsenko, N. Houlsby, Scaling open-vocabulary object detection, Advances in Neural Information Processing Systems 36 (2023) 72983–73007
2023
- [28]
-
[29]
C. Ma, Y. Jiang, J. Wu, Z. Yuan, X. Qi, Groma: Localized visual tokenization for grounding multimodal large language models, in: European Conference on Computer Vision, Springer, 2024, pp. 417–435
2024
-
[30]
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, J. Dai, Deformable detr: Deformable trans- formers for end-to-end object detection, arXiv preprint arXiv:2010.04159 (2020)
Pith/arXiv arXiv 2010
-
[31]
W. Wang, Y. Ren, H. Luo, T. Li, C. Yan, Z. Chen, W. Wang, Q. Li, L. Lu, X. Zhu, et al., The all-seeing project v2: Towards general relation comprehension of the open world, in: European Conference on Computer Vision, Springer, 2024, pp. 471–490
2024
-
[32]
J. Qiu, Y. Zhang, X. Tang, L. Xie, T. Ma, P. Yan, D. Doermann, Q. Ye, Y. Tian, Artemis: Towards referential understanding in complex videos, Advances in Neural Information Processing Systems 37 (2024) 114321–114347
2024
-
[33]
Y. Yuan, W. Li, J. Liu, D. Tang, X. Luo, C. Qin, L. Zhang, J. Zhu, Osprey: Pixel understanding with visual instruction tuning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 28202–28211. 31
2024
-
[34]
H. Hua, Q. Liu, L. Zhang, J. Shi, S. Y. Kim, Z. Zhang, Y. Wang, J. Zhang, Z. Lin, J. Luo, Finecaption: Compositional image captioning focusing on wherever you want at any granularity, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 24763–24773
2025
-
[35]
W. Lin, X. Wei, R. An, P. Gao, B. Zou, Y. Luo, S. Huang, S. Zhang, H. Li, Draw- and-understand: Leveraging visual prompts to enable mllms to comprehend what you want, arXiv preprint arXiv:2403.20271 (2024)
arXiv 2024
-
[36]
H. You, H. Zhang, Z. Gan, X. Du, B. Zhang, Z. Wang, L. Cao, S.-F. Chang, Y. Yang, Ferret: Refer and ground anything anywhere at any granularity, arXiv preprint arXiv:2310.07704 (2023)
Pith/arXiv arXiv 2023
-
[37]
W. Tang, Y. Sun, Q. Gu, Z. Li, Visual position prompt for mllm based visual ground- ing, arXiv preprint arXiv:2503.15426 (2025)
arXiv 2025
-
[38]
Q. Guo, S. De Mello, H. Yin, W. Byeon, K. C. Cheung, Y. Yu, P. Luo, S. Liu, Regiongpt: Towards region understanding vision language model, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13796–13806
2024
-
[39]
Zhang, P
S. Zhang, P. Sun, S. Chen, M. Xiao, W. Shao, W. Zhang, Y. Liu, K. Chen, P. Luo, Gpt4roi: Instruction tuning large language model on region-of-interest, in: European Conference on Computer Vision, Springer, 2025, pp. 52–70
2025
-
[40]
M. Cai, H. Liu, S. K. Mustikovela, G. P. Meyer, Y. Chai, D. Park, Y. J. Lee, Vip-llava: Makinglargemultimodalmodelsunderstandarbitraryvisualprompts, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12914–12923
2024
-
[41]
G. Chen, L. Shen, R. Shao, X. Deng, L. Nie, Lion: Empowering multimodal large language model with dual-level visual knowledge, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26540–26550
2024
-
[42]
Dwibedi, V
D. Dwibedi, V. Jain, J. J. Tompson, A. Zisserman, Y. Aytar, Flexcap: Describe anything in images in controllable detail, Advances in Neural Information Processing Systems 37 (2024) 111172–111198
2024
-
[43]
H. Liu, C. Li, Q. Wu, Y. J. Lee, Visual instruction tuning, Advances in neural information processing systems 36 (2023) 34892–34916
2023
-
[44]
Z. Peng, W. Wang, L. Dong, Y. Hao, S. Huang, S. Ma, F. Wei, Kosmos-2: Grounding multimodal large language models to the world, arXiv preprint arXiv:2306.14824 (2023). 32
Pith/arXiv arXiv 2023
-
[45]
J. Cha, W. Kang, J. Mun, B. Roh, Honeybee: Locality-enhanced projector for mul- timodal llm, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13817–13827
2024
-
[46]
A.-L. Wang, B. Shan, W. Shi, K.-Y. Lin, X. Fei, G. Tang, L. Liao, J. Tang, C. Huang, W.-S. Zheng, Pargo: Bridging vision-language with partial and global views, in: Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, 2025, pp. 7491–7499
2025
-
[47]
Zhang, Z
Y. Zhang, Z. Ma, X. Gao, S. Shakiah, Q. Gao, J. Chai, Groundhog: Grounding large language models to holistic segmentation, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 14227–14238
2024
-
[48]
Z. Yao, X. Cheng, Z. Huang, L. Li, Countllm: Towards generalizable repetitive action counting via large language model, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 19143–19153
2025
-
[49]
H. Wang, Y. Ye, Y. Wang, Y. Nie, C. Huang, Elysium: Exploring object-level per- ception in videos via mllm, in: European Conference on Computer Vision, Springer, 2024, pp. 166–185
2024
-
[50]
S. Ren, L. Yao, S. Li, X. Sun, L. Hou, Timechat: A time-sensitive multimodal large language model for long video understanding, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14313–14323
2024
-
[51]
M. Shi, F. Liu, S. Wang, S. Liao, S. Radhakrishnan, Y. Zhao, D.-A. Huang, H. Yin, K. Sapra, Y. Yacoob, et al., Eagle: Exploring the design space for multimodal llms with mixture of encoders, arXiv preprint arXiv:2408.15998 (2024)
arXiv 2024
-
[52]
X. Fan, T. Ji, C. Jiang, S. Li, S. Jin, S. Song, J. Wang, B. Hong, L. Chen, G. Zheng, et al., Mousi: Poly-visual-expert vision-language models, arXiv preprint arXiv:2401.17221 (2024)
arXiv 2024
-
[53]
L. Shen, G. Chen, R. Shao, W. Guan, L. Nie, Mome: Mixture of multimodal experts for generalist multimodal large language models, Advances in neural information processing systems 37 (2024) 42048–42070
2024
-
[54]
J. Ma, J. Wang, J. Luo, P. Yu, G. Zhou, Sherlock: Towards multi-scene video ab- normal event extraction and localization via a global-local spatial-sensitive llm, in: Proceedings of the ACM on Web Conference 2025, 2025, pp. 4004–4013
2025
-
[55]
Y. Liu, Z. Zhao, Z. Zhuang, L. Tian, X. Zhou, J. Zhou, Points: Improving your vision- language model with affordable strategies, arXiv preprint arXiv:2409.04828 (2024)
arXiv 2024
- [56]
-
[57]
B.-K. Lee, B. Park, C. Won Kim, Y. Man Ro, Moai: Mixture of all intelligence for large language and vision models, in: European Conference on Computer Vision, Springer, 2024, pp. 273–302
2024
-
[58]
Y. Li, H. Wang, S. Yuan, M. Liu, D. Zhao, Y. Guo, C. Xu, G. Shi, W. Zuo, Myriad: Large multimodal model by applying vision experts for industrial anomaly detection, arXiv preprint arXiv:2310.19070 (2023)
arXiv 2023
-
[59]
H. Yin, Y. Ren, K. Yan, S. Ding, Y. Hao, Rod-mllm: Towards more reliable object detection in multimodal large language models, in: Proceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 14358–14368
2025
-
[60]
X. He, L. Wei, L. Xie, Q. Tian, Incorporating visual experts to resolve the information loss in multimodal large language models, arXiv preprint arXiv:2401.03105 (2024)
arXiv 2024
- [61]
-
[62]
J. Jain, J. Yang, H. Shi, Vcoder: Versatile vision encoders for multimodal large language models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27992–28002
2024
-
[63]
Kirillov, E
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. White- head, A. C. Berg, W.-Y. Lo, et al., Segment anything, in: Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[64]
Rasheed, M
H. Rasheed, M. Maaz, S. Shaji, A. Shaker, S. Khan, H. Cholakkal, R. M. Anwer, E. Xing, M.-H. Yang, F. S. Khan, Glamm: Pixel grounding large multimodal model, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, 2024, pp. 13009–13018
2024
-
[65]
R. Pi, L. Yao, J. Gao, J. Zhang, T. Zhang, Perceptiongpt: Effectively fusing visual perceptionintollm, in: ProceedingsoftheIEEE/CVFConferenceonComputerVision and Pattern Recognition, 2024, pp. 27124–27133
2024
-
[66]
Zhang, X
T. Zhang, X. Li, H. Fei, H. Yuan, S. Wu, S. Ji, C. C. Loy, S. Yan, Omg-llava: Bridging image-level, object-level, pixel-level reasoning and understanding, Advances in Neural Information Processing Systems 37 (2024) 71737–71767
2024
-
[67]
X. Li, H. Yuan, W. Li, H. Ding, S. Wu, W. Zhang, Y. Li, K. Chen, C. C. Loy, Omg-seg: Is one model good enough for all segmentation?, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 27948–27959
2024
-
[68]
J. He, Y. Wang, L. Wang, H. Lu, J.-Y. He, J.-P. Lan, B. Luo, X. Xie, Multi-modal instruction tuned llms with fine-grained visual perception, in: Proceedings of the 34 ieee/cvf conference on computer vision and pattern recognition, 2024, pp. 13980– 13990
2024
-
[69]
Zhang, Y
Z. Zhang, Y. Ma, E. Zhang, X. Bai, Psalm: Pixelwise segmentation with large multi- modal model, in: European Conference on Computer Vision, Springer, 2024, pp. 74–91
2024
-
[70]
Y.Tian, T.Ma, L.Xie, J.Qiu, X.Tang, Y.Zhang, J.Jiao, Q.Tian, Q.Ye, Chatterbox: Multi-round multimodal referring and grounding, arXiv preprint arXiv:2401.13307 (2024)
arXiv 2024
-
[71]
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, H.-Y. Shum, Dino: Detr with improved denoising anchor boxes for end-to-end object detection, arXiv preprint arXiv:2203.03605 (2022)
Pith/arXiv arXiv 2022
-
[72]
S. Yang, T. Qu, X. Lai, Z. Tian, B. Peng, S. Liu, J. Jia, Lisa++: An im- proved baseline for reasoning segmentation with large language model, arXiv preprint arXiv:2312.17240 (2023)
arXiv 2023
-
[73]
Y. Yang, P.-T. Jiang, J. Wang, H. Zhang, K. Zhao, J. Chen, B. Li, Empow- ering segmentation ability to multi-modal large language models, arXiv preprint arXiv:2403.14141 (2024)
arXiv 2024
-
[74]
D. Cai, X. Yang, Y. Liu, D. Wang, S. Feng, Y. Zhang, S. Poria, Pixel-level reasoning segmentation via multi-turn conversations, arXiv preprint arXiv:2502.09447 (2025)
arXiv 2025
-
[75]
X. Wang, S. Zhang, S. Li, K. Kallidromitis, K. Li, Y. Kato, K. Kozuka, T. Darrell, Segllm: Multi-round reasoning segmentation, arXiv preprint arXiv:2410.18923 (2024)
arXiv 2024
-
[76]
Z. Ren, Z. Huang, Y. Wei, Y. Zhao, D. Fu, J. Feng, X. Jin, Pixellm: Pixel reason- ing with large multimodal model, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26374–26383
2024
-
[77]
K. Han, Y. Hu, M. Qu, H. Shi, Y. Zhao, Y. Wei, Rose: Revolutionizing open-set dense segmentation with patch-wise perceptual large multimodal model, arXiv preprint arXiv:2412.00153 (2024)
arXiv 2024
-
[78]
Z. Xia, D. Han, Y. Han, X. Pan, S. Song, G. Huang, Gsva: Generalized segmentation via multimodal large language models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 3858–3869
2024
-
[79]
C. Wei, H. Tan, Y. Zhong, Y. Yang, L. Ma, Lasagna: Language-based segmentation assistant for complex queries, arXiv preprint arXiv:2404.08506 (2024)
arXiv 2024
-
[80]
C. Wei, Y. Zhong, H. Tan, Y. Zeng, Y. Liu, Z. Zhao, Y. Yang, Instructseg: Unifying instructedvisualsegmentationwithmulti-modallargelanguagemodels, arXivpreprint arXiv:2412.14006 (2024). 35
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.