Wolfpack Adversarial Attack for Robust Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-23 03:21 UTC · model grok-4.3
The pith
A wolfpack-inspired attack disrupts cooperation in multi-agent reinforcement learning by targeting a lead agent and its supporters, while WALL training builds defenses through system-wide collaboration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
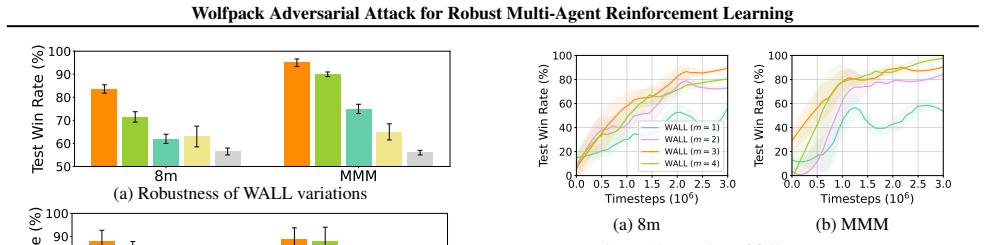
The Wolfpack Adversarial Attack framework, inspired by wolf hunting strategies, targets an initial agent and its assisting agents to disrupt cooperation in cooperative multi-agent reinforcement learning. The Wolfpack-Adversarial Learning for MARL (WALL) framework trains robust policies to defend against the proposed Wolfpack attack by fostering systemwide collaboration.
What carries the argument
Wolfpack Adversarial Attack, which selects and strikes a primary victim agent followed by coordinated strikes on its cooperative supporters to break team performance.
If this is right
- Coordinated attacks that follow a lead-and-support pattern cause greater performance drops than independent attacks in cooperative settings.
- Policies trained with the WALL framework retain higher team rewards when subjected to the Wolfpack attack.
- Encouraging system-wide collaboration during training produces defenses that address targeted disruptions of cooperation.
- Standard robust training methods leave cooperative MARL vulnerable to attacks that exploit agent interdependencies.
Where Pith is reading between the lines
- The attack pattern could be adapted to test robustness in non-cooperative or mixed MARL environments.
- Deployment in physical systems would need additional validation against noise and partial observability not present in the reported simulations.
- If the attack generalizes across algorithms, it points toward the value of attack-aware training as a standard practice rather than an add-on.
Load-bearing premise
The wolf-hunting analogy produces an attack that is meaningfully more effective than prior coordinated attacks in cooperative MARL settings, and the experimental scenarios used are representative of real deployment conditions.
What would settle it
A side-by-side test measuring total team reward loss under the Wolfpack attack versus existing coordinated attacks on a standard cooperative MARL benchmark such as multi-agent particle environments would show whether the new attack is distinctly more damaging.
Figures







read the original abstract
Traditional robust methods in multi-agent reinforcement learning (MARL) often struggle against coordinated adversarial attacks in cooperative scenarios. To address this limitation, we propose the Wolfpack Adversarial Attack framework, inspired by wolf hunting strategies, which targets an initial agent and its assisting agents to disrupt cooperation. Additionally, we introduce the Wolfpack-Adversarial Learning for MARL (WALL) framework, which trains robust MARL policies to defend against the proposed Wolfpack attack by fostering systemwide collaboration. Experimental results underscore the devastating impact of the Wolfpack attack and the significant robustness improvements achieved by WALL. Our code is available at https://github.com/sunwoolee0504/WALL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Wolfpack Adversarial Attack framework for cooperative multi-agent reinforcement learning (MARL), modeled on wolf-hunting tactics that target an initial agent together with its assisting agents to disrupt cooperation. It further introduces the Wolfpack-Adversarial Learning for MARL (WALL) defense that trains policies to foster system-wide collaboration against such attacks. Experimental results are presented to demonstrate the attack's impact and WALL's robustness gains, accompanied by a public code release.
Significance. If the reported experimental outcomes hold under scrutiny, the work supplies a concrete attack heuristic and matching defense for robust cooperative MARL, with the code release constituting a clear strength for reproducibility. The wolf-hunting analogy itself does not introduce internal circularity or hidden modeling assumptions that would invalidate the empirical claims; the reader's weakest-assumption concern therefore does not land as a load-bearing flaw. Significance remains moderate because the contribution is incremental and its practical value hinges on comparative performance against prior coordinated attacks, which the manuscript addresses empirically rather than by construction.
minor comments (3)
- The abstract asserts 'devastating impact' and 'significant robustness improvements' without any numerical values, baseline names, or statistical qualifiers; adding one or two representative metrics would strengthen the summary paragraph.
- Notation for the attack parameters (e.g., coordination radius or target-selection rule) should be introduced once in the method section and used consistently thereafter to avoid reader confusion.
- Figure captions in the experimental section would benefit from explicit statements of the number of independent runs and whether shaded regions represent standard error or deviation.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the Wolfpack Adversarial Attack and WALL framework, as well as for the recommendation of minor revision and for noting the value of the public code release. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical proposal introducing a new attack heuristic (Wolfpack, inspired by wolf hunting) and defense (WALL) for cooperative MARL, supported by experiments and public code. No derivation chain, equations, fitted parameters, or predictions are present that reduce claimed results to inputs by construction. No self-citation load-bearing steps or ansatz smuggling appear in the provided text; the central claims rest on external experimental validation rather than internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-agent environments can be modeled as cooperative Markov decision processes where agents share a joint reward.
Forward citations
Cited by 1 Pith paper
-
Interaction-Breaking Adversarial Learning Framework for Robust Multi-Agent Reinforcement Learning
The IBAL framework builds information-theoretic attacks that break agent interactions in MARL and trains policies to stay robust under observation and action perturbations.
Reference graph
Works this paper leans on
-
[1]
Towards minimax Optimality of Model-based Robust Reinforcement Learning
Clavier, P., Pennec, E. L., and Geist, M. Towards minimax optimality of model-based robust reinforcement learning. arXiv preprint arXiv:2302.05372,
-
[2]
Explaining and Harnessing Adversarial Examples
Goodfellow, I. J., Shlens, J., and Szegedy, C. Explain- ing and harnessing adversarial examples.arXiv preprint arXiv:1412.6572,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
10 Wolfpack Adversarial Attack for Robust Multi-Agent Reinforcement Learning Han, S., Su, S., He, S., Han, S., Yang, H., Zou, S., and Miao, F. What is the solution for state-adversarial multi-agent re- inforcement learning?arXiv preprint arXiv:2212.02705,
-
[4]
Robust multi-agent reinforcement learning with state uncertainty
He, S., Han, S., Su, S., Han, S., Zou, S., and Miao, F. Robust multi-agent reinforcement learning with state uncertainty. arXiv preprint arXiv:2307.16212,
-
[5]
Herremans, S., Anwar, A., and Mercelis, S. Robust model- based reinforcement learning with an adversarial auxiliary model.arXiv preprint arXiv:2406.09976,
-
[6]
Adversarial Attacks on Neural Network Policies
Huang, S., Papernot, N., Goodfellow, I., Duan, Y ., and Abbeel, P. Adversarial attacks on neural network policies. arXiv preprint arXiv:1702.02284,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Kobayashi, T. Lira: Light-robust adversary for model-based reinforcement learning in real world.arXiv preprint arXiv:2409.19617,
-
[8]
Li, S., Guo, J., Xiu, J., Xu, R., Yu, X., Wang, J., Liu, A., Yang, Y ., and Liu, X. Byzantine robust cooperative multi- agent reinforcement learning as a bayesian game.arXiv preprint arXiv:2305.12872, 2023a. Li, S., Xu, R., Guo, J., Feng, P., Wang, J., Liu, A., Yang, Y ., Liu, X., and Lv, W. Mir2: Towards provably robust multi-agent reinforcement learning...
-
[9]
Liu, Q., Kuang, Y ., and Wang, J. Robust deep reinforcement learning with adaptive adversarial perturbations in action space.arXiv preprint arXiv:2405.11982,
-
[10]
J., Levine, N., Jeong, R., Shi, Y ., Kay, J., Abdolmaleki, A., Springenberg, J
Mankowitz, D. J., Levine, N., Jeong, R., Shi, Y ., Kay, J., Abdolmaleki, A., Springenberg, J. T., Mann, T., Hester, T., and Riedmiller, M. Robust reinforcement learning for continuous control with model misspecification.arXiv preprint arXiv:1906.07516,
-
[11]
Robust Deep Reinforcement Learning with Adversarial Attacks
Pattanaik, A., Tang, Z., Liu, S., Bommannan, G., and Chowdhary, G. Robust deep reinforcement learning with adversarial attacks.arXiv preprint arXiv:1712.03632,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Rakhsha, A., Zhang, X., Zhu, X., and Singla, A. Reward poisoning in reinforcement learning: Attacks against un- known learners in unknown environments.arXiv preprint arXiv:2102.08492,
-
[13]
S., Farquhar, G., Nardelli, N., Rudner, T
Samvelyan, M., Rashid, T., De Witt, C. S., Farquhar, G., Nardelli, N., Rudner, T. G., Hung, C.-M., Torr, P. H., Foerster, J., and Whiteson, S. The starcraft multi-agent challenge.arXiv preprint arXiv:1902.04043,
-
[14]
Shi, L., Mazumdar, E., Chi, Y ., and Wierman, A. Sample- efficient robust multi-agent reinforcement learning in the face of environmental uncertainty.arXiv preprint arXiv:2404.18909,
-
[15]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Sunehag, P., Lever, G., Gruslys, A., Czarnecki, W. M., Zam- baldi, V ., Jaderberg, M., Lanctot, M., Sonnerat, N., Leibo, J. Z., Tuyls, K., et al. Value-decomposition networks for cooperative multi-agent learning.arXiv preprint arXiv:1706.05296,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Robust reinforcement learning using adversar- ial populations.arXiv preprint arXiv:2008.01825,
Vinitsky, E., Du, Y ., Parvate, K., Jang, K., Abbeel, P., and Bayen, A. Robust reinforcement learning using adversar- ial populations.arXiv preprint arXiv:2008.01825,
-
[17]
Qplex: Duplex dueling multi-agent q-learning
Wang, J., Liu, Y ., and Li, B. Reinforcement learning with perturbed rewards. InProceedings of the AAAI confer- ence on artificial intelligence, volume 34, pp. 6202–6209, 2020a. Wang, J., Ren, Z., Liu, T., Yu, Y ., and Zhang, C. Qplex: Duplex dueling multi-agent q-learning.arXiv preprint arXiv:2008.01062, 2020b. Wang, S., Chen, W., Huang, L., Zhang, F., Z...
-
[18]
Xu, Y ., Zeng, Q., and Singh, G. Efficient reward poisoning attacks on online deep reinforcement learning.arXiv preprint arXiv:2205.14842,
-
[19]
Reward poisoning attack against offline reinforcement learning.arXiv preprint arXiv:2402.09695,
Xu, Y ., Gumaste, R., and Singh, G. Reward poisoning attack against offline reinforcement learning.arXiv preprint arXiv:2402.09695,
- [20]
-
[21]
Ye, C., He, J., Gu, Q., and Zhang, T. Towards robust model- based reinforcement learning against adversarial corrup- tion.arXiv preprint arXiv:2402.08991,
-
[22]
Robust deep reinforcement learning against adversarial perturbations on state observations
Zhang, H., Chen, H., Xiao, C., Li, B., Liu, M., Boning, D., and Hsieh, C.-J. Robust deep reinforcement learning against adversarial perturbations on state observations. Advances in Neural Information Processing Systems, 33: 21024–21037, 2020a. Zhang, H., Chen, H., Boning, D., and Hsieh, C.-J. Robust reinforcement learning on state observations with learne...
-
[23]
is a widely used benchmark suite consisting of multi-agent scenarios. Agents are modeled as particles capable of movement and interaction, governed by simple physical dynamics. MPE includes both cooperative and competitive tasks, with each scenario sharing a continuous state space and typically partial observability. A standardized implementation of MPE i...
work page 2021
-
[24]
The enemy features describe each observed enemy, including available action flag, distance to the agent, relativex and y positions, health, shield (if applicable), and unit type. The ally features encode the same types of information for all visible allies, excluding the observing agent. Finally, the own features contain the observing agent’s own health, ...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.