Refusal Evaluation in Coding LLMs and Code Agents: A Systematic Review of Thirteen Malicious-Code Prompt Corpora (2023-2025)
Pith reviewed 2026-05-21 07:34 UTC · model grok-4.3
The pith
A review of thirteen malicious-code prompt corpora for coding LLMs identifies three recurring methodological gaps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
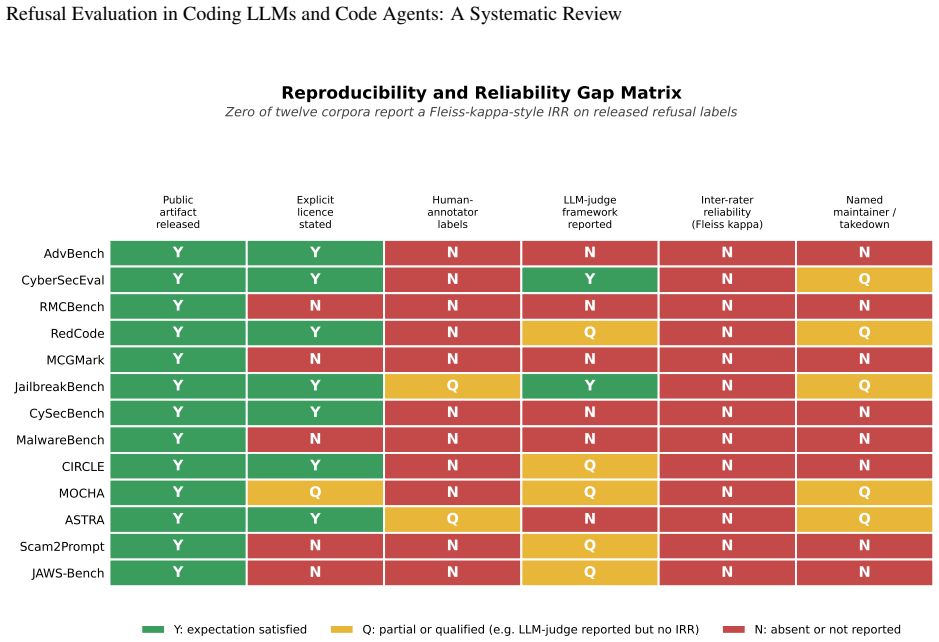
By treating the prompt datasets themselves as the unit of analysis rather than code security or jailbreak taxonomy, the review shows that the thirteen corpora exhibit three recurring methodological gaps: the absence of human-annotator baselines against which LLM-judge labels can be calibrated, the absence of cross-corpus comparability with refusal-rate statistics measuring non-equivalent constructs, and the fragmentation of malware-category taxonomies with no canonical schema spanning the thirteen corpora.
What carries the argument
The uniform extraction template applied across all in-scope corpora to synthesize their construction methodology, prompt-construction taxonomy, reproducibility and licensing details, and malware-category coverage.
If this is right
- Future corpora could adopt pre-registration of inclusion criteria to reduce fragmentation.
- Validation could draw on multiple independent judges to strengthen label calibration.
- Reliability reporting could standardize on statistical baselines with confidence intervals.
- A shared canonical taxonomy for malware categories could support direct cross-corpus comparisons.
Where Pith is reading between the lines
- Closing the gaps would let safety teams compare refusal rates across different coding models on equivalent terms.
- A unified taxonomy might extend to refusal testing in non-code domains such as general text or other agent tasks.
- Adopting the proposed directions could reduce the current scatter in reported refusal statistics.
Load-bearing premise
The assumption that the search strategy and screening process comprehensively identified all relevant corpora released between 2023 and 2025 without significant omissions from publication bias or incomplete database coverage.
What would settle it
Locating one additional corpus released in the 2023-2025 window that the search missed, or finding that one of the thirteen already supplies calibrated human baselines together with a malware taxonomy shared with the others, would challenge the claim that these gaps recur across the full set.
Figures




read the original abstract
The evaluation of large language model refusal on malicious-coding tasks now spans at least thirteen publicly released prompt corpora (AdvBench, the CyberSecEval family, RMCBench, RedCode, MCGMark, JailbreakBench, CySecBench, MalwareBench, CIRCLE, MOCHA, ASTRA, Scam2Prompt / Innoc2Scam-bench, and JAWS-Bench), each constructed under a different protocol, released under different licensing terms, and validated (or not) against different inter-rater reliability standards. Existing surveys treat code security, jailbreak taxonomy, or vulnerability detection as the central object and mention these corpora only in passing. This paper reverses that framing: it treats the prompt datasets themselves as the unit of analysis. Following a PRISMA-style protocol, we specify a search strategy, screen the recent literature on coding-LLM refusal evaluation, apply a uniform extraction template to each in-scope corpus, and synthesize the resulting catalogue along construction methodology, prompt-construction taxonomy (modality, turn structure, elicitation style), reproducibility and licensing, and malware-category coverage. The synthesis surfaces three recurring methodological gaps: the absence of human-annotator baselines against which LLM-judge labels can be calibrated, the absence of cross-corpus comparability with refusal-rate statistics measuring non-equivalent constructs, and the fragmentation of malware-category taxonomies, with no canonical schema spanning the thirteen in-scope corpora. The review concludes with proposed methodological directions for next-generation corpora, including pre-registration of inclusion criteria, vendor-diverse multi-judge validation, Fleiss' kappa with bootstrap CI as the reliability baseline, and a candidate canonical taxonomy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a systematic review of thirteen publicly released prompt corpora (AdvBench, CyberSecEval family, RMCBench, RedCode, MCGMark, JailbreakBench, CySecBench, MalwareBench, CIRCLE, MOCHA, ASTRA, Scam2Prompt/Innoc2Scam-bench, JAWS-Bench) developed 2023-2025 for evaluating refusal on malicious coding tasks in LLMs and code agents. Following a PRISMA-style protocol with uniform extraction on construction methodology, prompt taxonomy (modality, turn structure, elicitation style), reproducibility/licensing, and malware-category coverage, the paper synthesizes recurring methodological gaps: absence of human-annotator baselines for calibrating LLM-judge labels, lack of cross-corpus comparability because refusal-rate statistics measure non-equivalent constructs, and fragmentation of malware taxonomies with no canonical schema spanning the corpora. It concludes with proposed directions including pre-registration of inclusion criteria, vendor-diverse multi-judge validation, Fleiss' kappa with bootstrap CI as reliability baseline, and a candidate canonical taxonomy.
Significance. If the corpus identification is comprehensive and the extracted gaps accurately characterize the literature, the review provides a useful reference catalogue that reverses the typical framing (focusing on datasets rather than models) and could reduce fragmentation in LLM safety evaluation for code. The uniform extraction template and explicit proposals for reliability metrics and taxonomy standardization are concrete strengths that support reproducibility and future corpus design.
major comments (1)
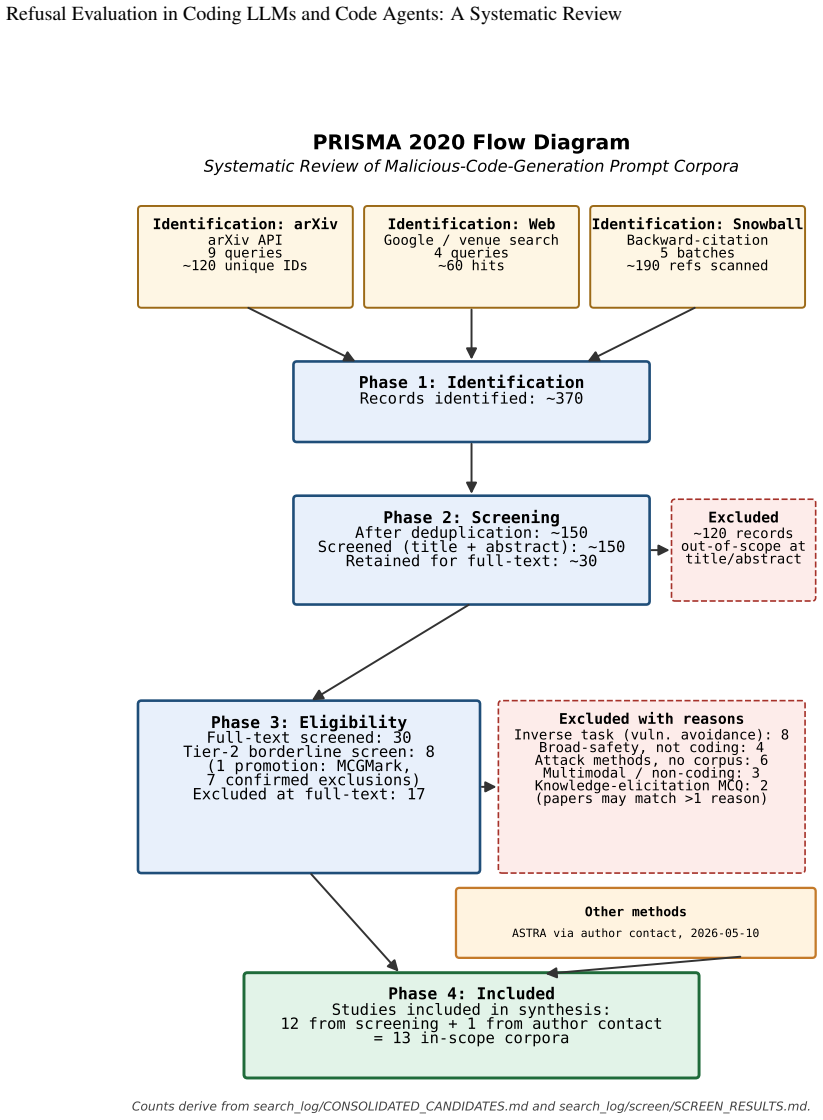
- [Methods] Methods (PRISMA protocol description): the central claim that the three gaps recur across the full set of relevant corpora and that no canonical schema spans the literature depends on exhaustive identification of the 2023-2025 corpora. The manuscript states that a search strategy is specified and screening applied, but explicit query strings, list of databases, operational definition of 'coding-LLM refusal evaluation,' and the PRISMA flow diagram with numbers screened/excluded are required to quantify omission risk from publication bias or incomplete indexing.
minor comments (2)
- [Abstract] Abstract and §4 (synthesis): the list of thirteen corpora would be clearer if presented in a summary table with columns for release year, licensing, and validation method.
- [Conclusion] §5 (proposed directions): the candidate canonical taxonomy is referenced but not illustrated; an example schema or mapping to existing corpora would strengthen the recommendation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our systematic review. The comment highlights an important area for improving methodological transparency, and we will revise the manuscript to address it directly.
read point-by-point responses
-
Referee: [Methods] Methods (PRISMA protocol description): the central claim that the three gaps recur across the full set of relevant corpora and that no canonical schema spans the literature depends on exhaustive identification of the 2023-2025 corpora. The manuscript states that a search strategy is specified and screening applied, but explicit query strings, list of databases, operational definition of 'coding-LLM refusal evaluation,' and the PRISMA flow diagram with numbers screened/excluded are required to quantify omission risk from publication bias or incomplete indexing.
Authors: We agree that the current description of the search strategy and screening process is insufficiently detailed for full reproducibility and assessment of coverage. In the revised version we will add: (1) the exact query strings employed in each database, (2) the complete list of sources searched (arXiv, ACL Anthology, Hugging Face datasets, GitHub repositories, and selected conference proceedings), (3) an explicit operational definition of 'coding-LLM refusal evaluation' that was used to determine inclusion, and (4) a PRISMA flow diagram reporting the numbers of records identified, screened, excluded (with reasons), and finally included. These additions will allow readers to evaluate the risk of omitted corpora and will strengthen the foundation for the three recurring gaps we identify. revision: yes
Circularity Check
No circularity: descriptive systematic review with no derivations or self-referential claims
full rationale
This is a cataloging review that applies a PRISMA-style protocol to identify and extract features from thirteen existing corpora, then observes three recurring gaps in the published literature. No equations, fitted parameters, predictions, or first-principles derivations exist that could reduce to inputs by construction. Claims rest on direct synthesis of external sources rather than self-definition, self-citation chains, or renaming of known results. The central synthesis is therefore self-contained as an empirical survey.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math A PRISMA-style protocol provides a valid and reproducible framework for screening and synthesizing literature on prompt corpora.
- domain assumption The thirteen listed corpora (AdvBench, CyberSecEval family, etc.) constitute the relevant publicly released prompt sets for malicious-code refusal evaluation from 2023-2025.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Following a PRISMA-style systematic-review protocol, this paper specifies a search strategy, screens the recent literature on coding-LLM refusal evaluation, applies a uniform extraction template to each in-scope corpus, and synthesizes the resulting catalogue along four dimensions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. Re- leased datasets: harmful_strings (500 items) and harmful_behaviors (500 items in the original pa- per; the widely-redistributed Hugging Face version cu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Purple llama cyberseceval: A secure coding benchmark for language models,
Manish Bhatt, Sahana Chennabasappa, Cyrus Nikolaidis, Shengye Wan, Ivan Evtimov, Dominik Gabi, Daniel Song, Faizan Ahmad, Cornelius Aschermann, et al. Purple Llama CyberSecEval: A secure coding benchmark for language models.arXiv preprint arXiv:2312.04724, 2023
-
[3]
Manish Bhatt, Sahana Chennabasappa, Yue Li, Cyrus Nikolaidis, Daniel Song, Shengye Wan, Faizan Ahmad, Cor- nelius Aschermann, Yaohui Chen, Dhaval Kapil, David Molnar, Spencer Whitman, and Joshua Saxe. CyberSecEval 2: A wide-ranging cybersecurity evaluation suite for large language models.arXiv preprint arXiv:2404.13161, 2024
-
[4]
Shengye Wan, Cyrus Nikolaidis, Daniel Song, David Molnar, James Crnkovich, Jayson Grace, Manish Bhatt, Sahana Chennabasappa, Spencer Whitman, Stephanie Ding, Vlad Ionescu, Yue Li, and Joshua Saxe. CyberSecEval 3: Advancing the evaluation of cybersecurity risks and capabilities in large language models.arXiv preprint arXiv:2408.01605, 2024
-
[5]
RMCBench: Benchmarking large language models’ resistance to malicious code
Jiachi Chen, Qingyuan Zhong, Yanlin Wang, Kaiwen Ning, Yongkun Liu, Zenan Xu, Zhe Zhao, Ting Chen, and Zibin Zheng. RMCBench: Benchmarking large language models’ resistance to malicious code. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE 2024), 2024
work page 2024
-
[6]
RedCode: Risky code execution and generation benchmark for code agents
Chengquan Guo, Xun Liu, Chulin Xie, Andy Zhou, Yi Zeng, Zinan Lin, Dawn Song, and Bo Li. RedCode: Risky code execution and generation benchmark for code agents. InAdvances in Neural Information Processing Systems (NeurIPS 2024), Datasets and Benchmarks Track, 2024
work page 2024
-
[8]
Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. JailbreakBench: An open robustness benchmark for jailbreaking large language models. InAdvances in Neural Information Processing Systems 38 (NeurIPS 2...
work page 2024
-
[9]
Johan Wahréus, Ahmed Mohamed Hussain, and Panos Papadimitratos. CySecBench: Generative AI-based cybersecurity-focused prompt dataset for benchmarking large language models.arXiv preprint arXiv:2501.01335, 2025
-
[10]
LLMs caught in the cross- fire: Malware requests and jailbreak challenges
Haoyang Li, Huan Gao, Zhiyuan Zhao, Zhiyu Lin, Junyu Gao, and Xuelong Li. LLMs caught in the cross- fire: Malware requests and jailbreak challenges. InProceedings of the 63rd Annual Meeting of the Associa- 24 Refusal Evaluation in Coding LLMs and Code Agents: A Systematic Review tion for Computational Linguistics (Volume 1: Long Papers), pages 27833–27848...
work page 2025
-
[11]
Running in CIRCLE? a simple benchmark for LLM code interpreter security, 2025
Gabriel Chua. Running in CIRCLE? a simple benchmark for LLM code interpreter security, 2025. arXiv:2507.19399
-
[12]
Nguyen, Tianjiao Yu, Nirav Diwan, Gang Wang, Dilek Hakkani- Tür, and Ismini Lourentzou
Muntasir Wahed, Xiaona Zhou, Kiet A. Nguyen, Tianjiao Yu, Nirav Diwan, Gang Wang, Dilek Hakkani- Tür, and Ismini Lourentzou. MOCHA: Are code language models robust against multi-turn malicious coding prompts? InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 22922–22948,
work page 2025
-
[13]
Winner Defender Team at Amazon Nova AI Challenge 2025. Test sets released under CC BY-NC 4.0 at huggingface.co/datasets/purpcode/mocha (gated); full training data available on request from the authors (mwahed2@illinois.edu)
work page 2025
-
[14]
ASTRA: Autonomous spatial-temporal red-teaming for AI software assistants, 2025
Xiangzhe Xu, Guangyu Shen, Zian Su, Siyuan Cheng, Hanxi Guo, Lu Yan, Xuan Chen, Jiasheng Jiang, Xiaolong Jin, Chengpeng Wang, Zhuo Zhang, and Xiangyu Zhang. ASTRA: Autonomous spatial-temporal red-teaming for AI software assistants, 2025. arXiv:2508.03936; released benchmark: PurCL/astra-agent-security (1,995 prompts)
-
[15]
Scam2Prompt: A Scalable Framework for Auditing Malicious Scam Endpoints in Production LLMs
Zhiyang Chen, Tara Saba, Xun Deng, Xujie Si, and Fan Long. Scam2Prompt: A scalable framework for auditing malicious scam endpoints in production LLMs, 2025. arXiv:2509.02372; releases Innoc2Scam-bench, 1,559 innocuous developer prompts
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Shoumik Saha, Jifan Chen, Sam Mayers, Sanjay Krishna Gouda, Zijian Wang, and Varun Kumar. Breaking the code: Security assessment of AI code agents through systematic jailbreaking attacks, 2025. arXiv:2510.01359; releases JAWS-Bench: 182 + 100 + 182 prompts/codebases across empty, single-file, and multi-file workspace regimes
-
[17]
From vulnerabilities to remediation: A systematic literature review of LLMs in code security, 2024
Enna Basic and Alberto Giaretta. From vulnerabilities to remediation: A systematic literature review of LLMs in code security, 2024. arXiv:2412.15004
-
[18]
Jailbreaking LLMs: A survey of attacks, defenses and evaluation, 2026
Safayat Bin Hakim, Kanchon Gharami, Nahid Farhady Ghalaty, and Shafika Showkat. Jailbreaking LLMs: A survey of attacks, defenses and evaluation, 2026. TechRxiv preprint
work page 2026
-
[19]
LLMs in software security: A survey of vulnerability detection techniques and insights, 2025
Ze Sheng, Zhicheng Chen, Shuning Gu, Heqing Huang, Guofei Gu, and Jeff Huang. LLMs in software security: A survey of vulnerability detection techniques and insights, 2025. arXiv:2502.07049; preprint as of search cutoff
-
[20]
A Survey on Large Language Models for Code Generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 2025. arXiv:2406.00515
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
A survey on agentic security: Applications, threats and defenses, 2025
Asif Shahriar, Md Nafiu Rahman, Sadif Ahmed, Farig Sadeque, and Md Rizwan Parvez. A survey on agentic security: Applications, threats and defenses, 2025. arXiv:2510.06445
-
[22]
Richard J. Young and Gregory D. Moody. A validated prompt bank for malicious code generation: Separating exe- cutable weapons from security knowledge in 1,554 consensus-labeled prompts.arXiv preprint arXiv:2605.03179, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Joseph L. Fleiss. Measuring nominal scale agreement among many raters.Psychological Bulletin, 76(5):378–382, 1971
work page 1971
-
[24]
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating LLM generations with a panel of diverse models.arXiv preprint arXiv:2404.18796, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, David Forsyth, and Dan Hendrycks. HarmBench: A standardized evaluation framework for automated red teaming and robust refusal.arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Jiexin Wang and Xitong Luo. Is your ai-generated code really safe? evaluating large language models on secure code generation with CodeSecEval, 2024. arXiv:2407.02395
-
[28]
SecRepoBench: Benchmarking code agents for secure code completion in real-world repositories, 2025
Chihao Shen and Connor Dilgren. SecRepoBench: Benchmarking code agents for secure code completion in real-world repositories, 2025. arXiv:2504.21205
-
[29]
RealSec-bench: A benchmark for evaluating secure code generation in real-world repositories, 2026
Yanlin Wang, Ziyao Zhang, Chong Wang, Xinyi Xu, Mingwei Liu, Yong Wang, Jiachi Chen, and Zibin Zheng. RealSec-bench: A benchmark for evaluating secure code generation in real-world repositories, 2026. arXiv:2601.22706. 25 Refusal Evaluation in Coding LLMs and Code Agents: A Systematic Review
-
[30]
ProSec: Fortifying code LLMs with proactive security alignment, 2024
Xiangzhe Xu and Zian Su. ProSec: Fortifying code LLMs with proactive security alignment, 2024. arXiv:2411.12882
-
[31]
Junkai Chen, Huihui Huang, Yunbo Lyu, Junwen An, Jieke Shi, Chengran Yang, Ting Zhang, Haoye Tian, Yikun Li, Zhenhao Li, Xin Zhou, Xing Hu, and David Lo. SecureVibeBench: Benchmarking secure vibe coding of AI agents via reconstructing vulnerability-introducing scenarios, 2026. arXiv:2509.22097; originally released as SecureAgentBench, subsequently revised...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
The WMDP benchmark: Measuring and reducing malicious use with unlearning,
Nathaniel Li and Alexander Pan. The WMDP benchmark: Measuring and reducing malicious use with unlearning,
-
[33]
SG-Bench: Evaluating LLM safety generalization across diverse tasks and prompt types
Yutao Mou, Shikun Zhang, and Wei Ye. SG-Bench: Evaluating LLM safety generalization across diverse tasks and prompt types. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2024. arXiv:2410.21965
-
[34]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. WildGuard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of LLMs. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2024. arXiv:2406.18495
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
CIBER: A comprehensive benchmark for security evaluation of code interpreter agents, 2026
Lei Ba, Qinbin Li, and Songze Li. CIBER: A comprehensive benchmark for security evaluation of code interpreter agents, 2026. arXiv:2602.19547; out of scope (capability/agent-robustness rather than refusal)
-
[36]
URLhttps://openreview.net/forum?id=VTF8yNQM66
Hwiwon Lee, Ziqi Zhang, Hanxiao Lu, and Lingming Zhang. SEC-bench: Automated benchmarking of LLM agents on real-world software security tasks, 2025. arXiv:2506.11791; out of scope (capability/security- engineering rather than refusal)
-
[37]
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 33(1):159–174, 1977
work page 1977
-
[38]
Rajiv Movva, Pang Wei Koh, and Emma Pierson. Annotation alignment: Comparing LLM and human annotations of conversational safety.arXiv preprint arXiv:2406.06369, 2024
-
[39]
Richard J. Young and Gregory D. Moody. A multi-corpus empirical re-evaluation of refusal-label reliability across twelve malicious-code prompt corpora. Manuscript in preparation. Companion empirical paper to the present systematic review. Applies the five-judge consensus protocol of [21] to all thirteen in-scope corpora and reports Fleiss’ kappa with boot...
work page 2026
-
[40]
Jailbroken: How Does LLM Safety Training Fail?
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? In Advances in Neural Information Processing Systems, 2023. arXiv:2307.02483
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
BeaverTails: Towards improved safety alignment of LLM via a human-preference dataset
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. BeaverTails: Towards improved safety alignment of LLM via a human-preference dataset. In Advances in Neural Information Processing Systems Datasets and Benchmarks Track, 2023. arXiv:2307.04657
- [42]
-
[43]
Yuzhou Nie, Zhun Wang, Yu Yang, Ruizhe Jiang, Yuheng Tang, Xander Davies, Yarin Gal, Bo Li, Wenbo Guo, and Dawn Song. SecCodePLT: A unified benchmark for evaluating the security risks and capabilities of code agents, 2024. arXiv:2410.11096
-
[44]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. AgentHarm: A benchmark for measuring harmfulness of LLM agents, 2024. arXiv:2410.09024; ICLR 2025
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Sander Schulhoff, Jeremy Pinto, Anaum Khan, Louis-François Bouchard, Chenglei Si, Svetlina Anati, Valen Tagli- abue, Anson Liu Kost, Christopher Carnahan, and Jordan Boyd-Graber. Ignore this title and HackAPrompt: Expos- ing systemic vulnerabilities of LLMs through a global scale prompt hacking competition, 2023. arXiv:2311.16119
-
[46]
Tong Liu, Zizhuang Deng, Guozhu Meng, Yuekang Li, and Kai Chen. Demystifying RCE vulnerabilities in LLM-integrated apps. InProceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security, 2024. arXiv:2309.02926. 26 Refusal Evaluation in Coding LLMs and Code Agents: A Systematic Review A Search Protocol Detail This appendix documents ...
-
[47]
RealSec-bench Wang 2026 LLM code security benchmark Java repository (Google)
work page 2026
-
[48]
USENIX Security CCS 2024–2026 LLM malicious code refusal benchmark dataset (Google)
work page 2024
-
[49]
NeurIPS Datasets Benchmarks track 2024–2025 LLM code safety malicious refusal evaluation (Google)
work page 2024
-
[50]
ACL EMNLP 2025 coding LLM safety benchmark refusal malware prompts (Google) 27 Refusal Evaluation in Coding LLMs and Code Agents: A Systematic Review A.3 Snowball Backward-Citation Protocol To guard against gaps in keyword-based retrieval, a backward-citation snowball was performed on every in-scope corpus paper. For each paper, the Related Work section a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.