Physics-informed Goal-Conditioned Reinforcement Learning under Hybrid Contact Dynamics
Pith reviewed 2026-06-29 06:49 UTC · model grok-4.3
The pith
Structural properties of contact interactions cause existing physics-informed goal-conditioned RL methods to degrade in manipulation, which contact-aware and hierarchical formulations address by applying biases selectively.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Contact interactions induce hybrid dynamics, mode-dependent controllability, and nonsmooth value landscapes that cause existing Pi-GCRL methods to degrade when applied naively to contact-rich manipulation. Motivated by this analysis, contact-aware and hierarchical formulations apply physics-informed inductive biases selectively across the manipulation problem, providing a principled step toward extending Pi-GCRL to contact-rich manipulation.
What carries the argument
Contact-aware and hierarchical formulations that apply physics-informed inductive biases selectively across the manipulation problem to handle hybrid contact dynamics.
If this is right
- Existing Pi-GCRL methods degrade on contact-rich manipulation due to hybrid dynamics and nonsmooth landscapes.
- Contact-aware formulations apply physics-informed biases only where they remain valid.
- Hierarchical formulations handle mode switches and controllability changes across contact modes.
- The approach extends reliable goal-conditioned learning from navigation domains to contact-rich robotic tasks.
- Selective application of inductive biases becomes necessary for problems with nonsmooth value landscapes.
Where Pith is reading between the lines
- The selective-bias pattern could apply to other hybrid systems such as legged locomotion or multi-body assembly.
- Integration with explicit contact-mode detection might further stabilize value learning in these settings.
- Real-robot experiments would test whether the hierarchical split reduces sample complexity compared with flat formulations.
Load-bearing premise
Contact interactions induce hybrid dynamics, mode-dependent controllability, and nonsmooth value landscapes that directly cause degradation in existing Pi-GCRL methods.
What would settle it
Experiments on contact-rich manipulation tasks that show no performance degradation when using existing Pi-GCRL methods or no improvement when using the contact-aware hierarchical formulations.
Figures


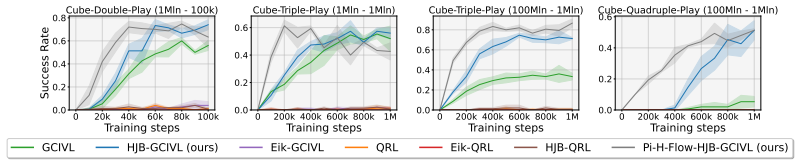
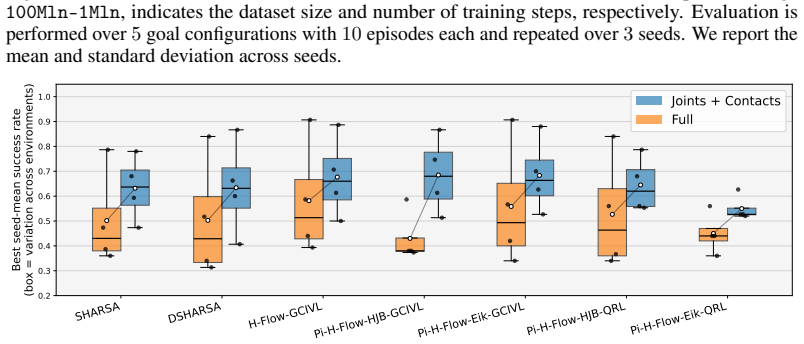

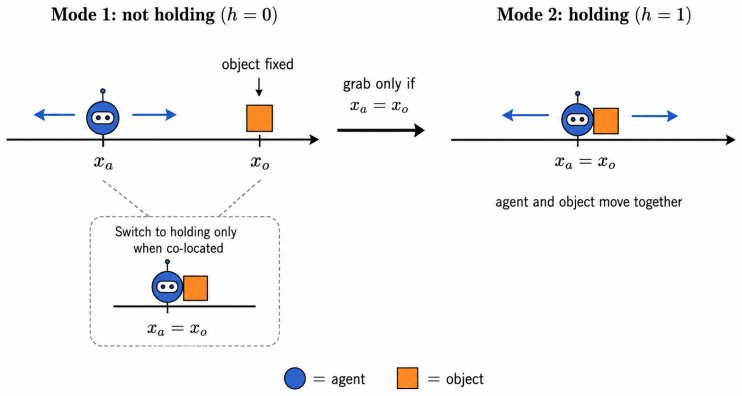
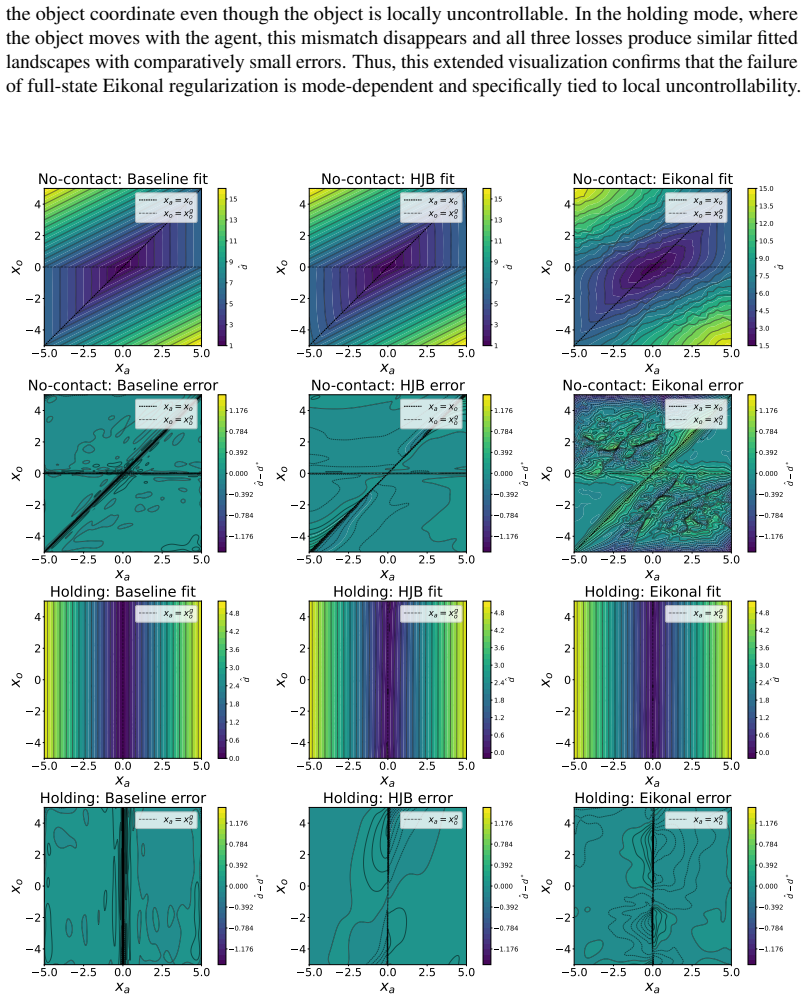



read the original abstract
Learning to reach arbitrary goals from sparse feedback requires agents to infer a rich notion of reachability across state--goal pairs. Goal-conditioned reinforcement learning (GCRL) tackles this challenge by learning policies that generalize across goals, but this generalization becomes increasingly difficult as the underlying dynamics become high-dimensional, hybrid, or contact-dependent. To address this issue, physics-informed GCRL (Pi-GCRL) introduces optimal-control-inspired inductive biases into goal-conditioned value learning. While Pi-GCRL methods have proven effective in navigation and object-free goal-reaching domains, their reliability in contact-rich tasks remains unclear, where contact interactions induce hybrid dynamics, mode-dependent controllability, and nonsmooth value landscapes. In this work, we show that these structural properties can cause existing Pi-GCRL methods to degrade when applied naively to contact-rich manipulation. Motivated by this analysis, we introduce contact-aware and hierarchical formulations that apply physics-informed inductive biases selectively across the manipulation problem. Our results provide a principled step toward extending Pi-GCRL to contact-rich manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that structural properties of contact-rich manipulation—hybrid dynamics, mode-dependent controllability, and nonsmooth value landscapes—cause existing physics-informed goal-conditioned RL (Pi-GCRL) methods to degrade when applied naively. Motivated by this analysis, it introduces contact-aware and hierarchical formulations that apply physics-informed inductive biases selectively across the manipulation problem.
Significance. If the claimed degradation is demonstrated and the new formulations are shown to mitigate it, the work would address a relevant gap in extending Pi-GCRL to realistic robotic contact tasks. The abstract, however, supplies no equations, derivations, experiments, or data, so the significance cannot be assessed from the provided text.
major comments (1)
- [Abstract] Abstract: the central claim that 'these structural properties can cause existing Pi-GCRL methods to degrade' is asserted without any supporting equations, experimental results, error bars, or data; the claim therefore cannot be verified or stress-tested for internal consistency.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'these structural properties can cause existing Pi-GCRL methods to degrade' is asserted without any supporting equations, experimental results, error bars, or data; the claim therefore cannot be verified or stress-tested for internal consistency.
Authors: We agree that the abstract, being a concise summary, does not contain the supporting equations, derivations, or experimental data. The full manuscript supplies this material: Section 3 analyzes the structural properties (hybrid dynamics, mode-dependent controllability, nonsmooth value landscapes) and their effect on Pi-GCRL; Sections 4–5 provide the theoretical arguments and empirical results (including error bars) showing degradation on contact-rich tasks and the benefit of the contact-aware and hierarchical formulations. To address the concern, we will revise the abstract to briefly reference the supporting analysis and results. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and provided text contain no equations, derivations, fitted parameters, or self-citations that form a load-bearing chain. Claims about structural properties causing degradation in Pi-GCRL methods and the introduction of contact-aware formulations are stated at a high level without any reduction to inputs by construction or renaming of known results. The derivation chain cannot be walked because no technical steps, proofs, or predictive claims are exhibited; this is the normal case of a self-contained high-level motivation with no internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D. A. Pomerleau. Alvinn: An autonomous land vehicle in a neural network.Advances in Neural Information Processing Systems, 1, 1988
1988
-
[2]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
Ibrahim, M
S. Ibrahim, M. Mostafa, A. Jnadi, H. Salloum, and P. Osinenko. Comprehensive overview of reward engineering and shaping in advancing reinforcement learning applications.IEEE Access, 12:175473–175500, 2024
2024
-
[7]
Giammarino, M
V . Giammarino, M. F. Dunne, K. N. Moore, M. E. Hasselmo, C. E. Stern, and I. C. Paschalidis. Combining imitation and deep reinforcement learning to human-level performance on a virtual foraging task.Adaptive Behavior, 32(3):251–263, 2024
2024
-
[8]
L. P. Kaelbling. Learning to achieve goals. InInternational Joint Conference on Artificial Intelligence, volume 2, pages 1094–8. Citeseer, 1993
1993
-
[9]
Schaul, D
T. Schaul, D. Horgan, K. Gregor, and D. Silver. Universal value function approximators. In International Conference on Machine Learning, pages 1312–1320. PMLR, 2015
2015
-
[10]
Andrychowicz, F
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, O. Pieter Abbeel, and W. Zaremba. Hindsight experience replay.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[11]
G. Yang, A. Zhang, A. Morcos, J. Pineau, P. Abbeel, and R. Calandra. Plan2vec: Unsupervised representation learning by latent plans. InLearning for Dynamics and Control, pages 935–946. PMLR, 2020
2020
-
[12]
T. Wang, A. Torralba, P. Isola, and A. Zhang. Optimal goal-reaching reinforcement learning via quasimetric learning. InInternational Conference on Machine Learning, pages 36411–36430. PMLR, 2023
2023
-
[13]
Settai, N
H. Settai, N. Takeishi, and T. Yairi. A temporal difference method for stochastic con- tinuous dynamics.Advances in Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=UKFg5yeZeX
2026
-
[14]
Giammarino, R
V . Giammarino, R. Ni, and A. H. Qureshi. Physics-informed value learner for offline goal- conditioned reinforcement learning.Advances in Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=LRYgQuz7kY
2026
-
[15]
Giammarino and A
V . Giammarino and A. H. Qureshi. Goal reaching with eikonal-constrained hierarchical quasi- metric reinforcement learning. InInternational Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=5WhsCB0Vty
2026
-
[16]
Tedrake.Robotic Manipulation
R. Tedrake.Robotic Manipulation. 2024. URLhttp://manipulation.mit.edu. 9
2024
-
[17]
Eysenbach, T
B. Eysenbach, T. Zhang, S. Levine, and R. R. Salakhutdinov. Contrastive learning as goal- conditioned reinforcement learning.Advances in Neural Information Processing Systems, 35: 35603–35620, 2022
2022
-
[18]
J. Y . Ma, J. Yan, D. Jayaraman, and O. Bastani. Offline goal-conditioned reinforcement learning via f-advantage regression.Advances in Neural Information Processing Systems, 35:310–323, 2022
2022
-
[19]
S. Park, D. Ghosh, B. Eysenbach, and S. Levine. Hiql: Offline goal-conditioned rl with latent states as actions.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[20]
Haramati, C
D. Haramati, C. Qi, T. Daniel, A. Zhang, A. Tamar, and G. Konidaris. Hierarchical entity- centric reinforcement learning with factored subgoal diffusion. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=TimC6hxVHj
2026
-
[21]
S. Park, K. Frans, D. Mann, B. Eysenbach, A. Kumar, and S. Levine. Horizon reduction makes rl scalable.Advances in Neural Information Processing Systems, 38:8350–8389, 2026
2026
-
[22]
H. Ahn, H. Choi, J. Han, and T. Moon. Option-aware temporally abstracted value for offline goal-conditioned reinforcement learning.Advances in Neural Information Processing Systems, 38:99833–99861, 2026
2026
-
[23]
Y . Chebotar, K. Hausman, Y . Lu, T. Xiao, D. Kalashnikov, J. Varley, A. Irpan, B. Eysenbach, R. Julian, C. Finn, et al. Actionable models: Unsupervised offline reinforcement learning of robotic skills.arXiv preprint arXiv:2104.07749, 2021
- [24]
-
[25]
R. Yang, L. Yong, X. Ma, H. Hu, C. Zhang, and T. Zhang. What is essential for unseen goal generalization of offline goal-conditioned rl? InInternational Conference on Machine Learning, pages 39543–39571. PMLR, 2023
2023
-
[26]
Mezghani, S
L. Mezghani, S. Sukhbaatar, P. Bojanowski, A. Lazaric, and K. Alahari. Learning goal- conditioned policies offline with self-supervised reward shaping. InConference on Robot Learning, pages 1401–1410. PMLR, 2023
2023
- [27]
-
[28]
E. Sontag. An abstract approach to dissipation. InProceedings of 1995 34th IEEE Conference on Decision and Control, volume 3, pages 2702–2703. IEEE, 1995
1995
-
[29]
B. Liu, Y . Feng, Q. Liu, and P. Stone. Metric residual network for sample efficient goal- conditioned reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 8799–8806, 2023
2023
-
[30]
Pitis, H
S. Pitis, H. Chan, K. Jamali, and J. Ba. An inductive bias for distances: Neural nets that respect the triangle inequality. InInternational Conference on Learning Representations
-
[31]
Durugkar, M
I. Durugkar, M. Tec, S. Niekum, and P. Stone. Adversarial intrinsic motivation for reinforcement learning.Advances in Neural Information Processing Systems, 34:8622–8636, 2021
2021
-
[32]
Lien, P.-C
Y .-H. Lien, P.-C. Hsieh, T.-M. Li, and Y .-S. Wang. Enhancing value function estimation through first-order state-action dynamics in offline reinforcement learning. InInternational Conference on Machine Learning, 2024. 10
2024
-
[33]
M. M. Noack and S. Clark. Acoustic wave and eikonal equations in a transformed metric space for various types of anisotropy.Heliyon, 3(3), 2017
2017
-
[34]
H. Viswanath, J. Lu, S. T. Bukhari, D. Conover, Z. Wang, and A. Bera. Physics informed viscous value representations.arXiv preprint arXiv:2602.23280, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Stepputtis, J
S. Stepputtis, J. Campbell, M. Phielipp, S. Lee, C. Baral, and H. Ben Amor. Language- conditioned imitation learning for robot manipulation tasks.Advances in Neural Information Processing Systems, 33:13139–13150, 2020
2020
-
[36]
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Y . J. Ma, V . Kumar, A. Zhang, O. Bastani, and D. Jayaraman. Liv: Language-image representa- tions and rewards for robotic control. InInternational Conference on Machine Learning, pages 23301–23320. PMLR, 2023
2023
- [38]
-
[39]
P. Zhou, W. Yao, Q. Luo, X. Zhou, and Y . Yang. Hyper-goalnet: Goal-conditioned manipulation policy learning with hypernetworks.Advances in Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=aWWRPyGMie
2026
-
[40]
Manganaris, V
A. Manganaris, V . Giammarino, and A. H. Qureshi. Automaton constrained q-learning.Ad- vances in Neural Information Processing Systems, 2026. URL https://openreview.net/ forum?id=DLt2Ep1S3q
2026
-
[41]
Hedlund and A
S. Hedlund and A. Rantzer. Optimal control of hybrid systems. InProceedings of the 38th IEEE Conference on Decision and Control (Cat. No. 99CH36304), volume 4, pages 3972–3977. IEEE, 1999
1999
-
[42]
L. Lyu, Y . Li, Y . Luo, F. Sun, T. Kong, J. Xu, and X. Ma. Flow-based policy for online reinforcement learning.Advances in Neural Information Processing Systems, 38:93967–93990, 2026
2026
-
[43]
S. Park, K. Frans, B. Eysenbach, and S. Levine. Ogbench: Benchmarking offline goal- conditioned rl. InInternational Conference on Learning Representations, volume 2025, pages 94937–94982, 2025
2025
-
[44]
A. Manganaris, J. Lu, A. H. Qureshi, and S. Jagannathan. Graph-of-constraints model predictive control for reactive multi-agent task and motion planning.arXiv preprint arXiv:2603.18400, 2026
-
[45]
R. S. Sutton and A. G. Barto.Reinforcement learning: An introduction. MIT press, 2018
2018
-
[46]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17868–17879, 2024. doi:10.1109/CVPR52733.2024.01692. 11 A Ethical Statement This work is primarily methodological and studies physics-informed value lear...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.