Data Mixing Agent: Learning to Re-weight Domains for Continual Pre-training
Pith reviewed 2026-05-19 03:32 UTC · model grok-4.3
The pith
A reinforcement learning agent learns to automatically re-weight data domains for balanced continual pre-training of language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Data Mixing Agent is the first model-based, end-to-end framework that learns to re-weight domains through reinforcement learning on data mixing trajectories with feedback from an evaluation environment, outperforming strong baselines on math reasoning continual pre-training and generalizing across unseen source fields, target models, and domain spaces.
What carries the argument
The Data Mixing Agent, which parameterizes domain re-weighting heuristics and optimizes them end-to-end via reinforcement learning guided by evaluation feedback.
If this is right
- Outperforms strong baselines in achieving balanced performance across source and target field benchmarks.
- Generalizes well across unseen source fields, target models, and domain spaces without retraining.
- Adapts directly to the code generation field.
- Learned heuristics align with human intuitions.
- Achieves superior model performance with less source-field data.
Where Pith is reading between the lines
- The method could be extended to optimize mixtures involving more than two domains or additional data types.
- It opens the possibility of meta-learning domain mixing policies across multiple tasks simultaneously.
- Future experiments might replace full benchmark evaluations with faster proxy metrics to reduce training cost for the agent.
- This RL approach to data curation may influence how training data is selected in other stages of model development.
Load-bearing premise
Feedback signals from the evaluation environment on source and target benchmarks are reliable and generalizable enough to train an agent that transfers to new domains and models.
What would settle it
A test where the Data Mixing Agent trained on math reasoning data is applied to a new target domain such as biology and underperforms standard manual mixing strategies would challenge the generalization claim.
Figures


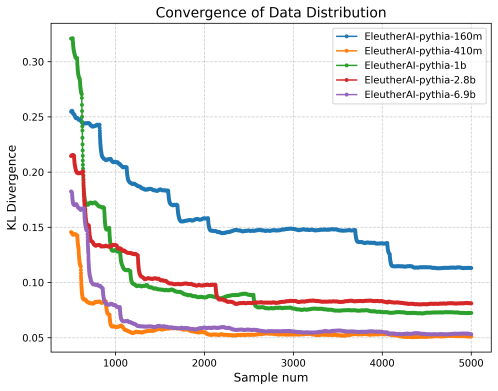



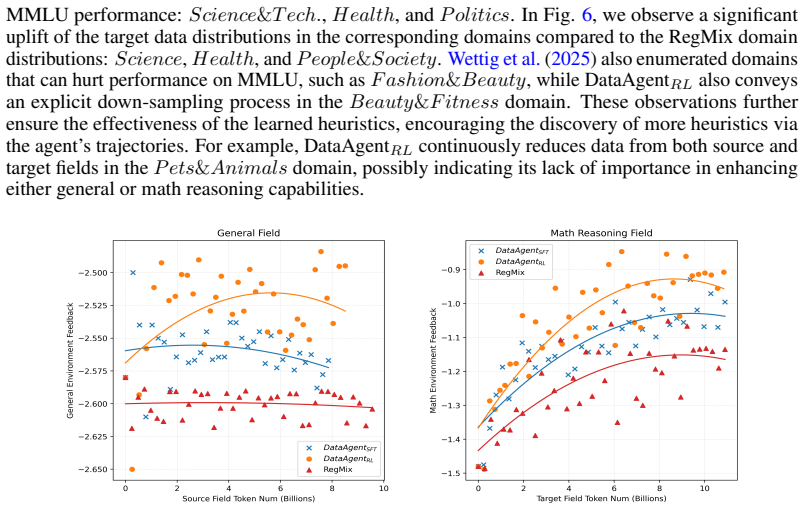
read the original abstract
Continual pre-training on small-scale task-specific data is an effective method for improving large language models in new target fields, yet it risks catastrophic forgetting of their original capabilities. A common solution is to re-weight training data mixtures from source and target fields on a domain space to achieve balanced performance. Previous domain reweighting strategies rely on manual designation with certain heuristics based on human intuition or empirical results. In this work, we prove that more general heuristics can be parameterized by proposing Data Mixing Agent, the first model-based, end-to-end framework that learns to re-weight domains. The agent learns generalizable heuristics through reinforcement learning on large quantities of data mixing trajectories with corresponding feedback from an evaluation environment. Experiments in continual pre-training on math reasoning show that Data Mixing Agent outperforms strong baselines in achieving balanced performance across source and target field benchmarks. Furthermore, it generalizes well across unseen source fields, target models, and domain spaces without retraining. Direct application to the code generation field also indicates its adaptability across target domains. Further analysis showcases the agents' well-aligned heuristics with human intuitions and their efficiency in achieving superior model performance with less source-field data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Data Mixing Agent, the first model-based end-to-end RL framework for learning to re-weight domains during continual pre-training of LLMs. The agent is trained on large numbers of data-mixing trajectories whose rewards are supplied by an evaluation environment on source and target benchmarks; the central claims are that the resulting policy outperforms strong baselines on math-reasoning continual pre-training, produces balanced performance, and generalizes without retraining to unseen source fields, target models, and domain spaces, with additional evidence of adaptability to code generation.
Significance. If the generalization results are robust, the work supplies an automated, learned alternative to the manual or heuristic-based domain-reweighting strategies currently used to mitigate catastrophic forgetting. The RL formulation with external benchmark feedback is a concrete step toward parameterizing more general mixing heuristics, and the reported cross-domain and cross-model transfer experiments, if quantitatively detailed, would constitute a useful empirical contribution to continual pre-training.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the claim of outperformance and generalization is stated without quantitative details on baselines, exact metrics, statistical significance, or number of runs. The central empirical support for both the balanced-performance and no-retraining claims therefore cannot yet be evaluated.
- [§5] §5 (Generalization experiments): the no-retraining transfer to unseen source fields and target models rests on the assumption that rewards from the fixed math-reasoning evaluation environment encode domain-invariant balancing rules rather than benchmark-specific optima. If the agent overfits to the metric surfaces of the training benchmarks, performance on truly novel fields or models would be expected to degrade; the manuscript should provide an ablation that isolates this risk (e.g., training on one set of metrics and testing on an orthogonal held-out metric suite).
minor comments (2)
- [§3] Clarify the exact formulation of the reward function and any scaling hyperparameters in the RL objective; these appear among the free parameters listed in the axiom ledger.
- [Table 3] Ensure that tables reporting cross-period or cross-model results include both mean and standard deviation across seeds so that the magnitude of improvement can be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving the presentation of our empirical results and the robustness of our generalization claims. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the claim of outperformance and generalization is stated without quantitative details on baselines, exact metrics, statistical significance, or number of runs. The central empirical support for both the balanced-performance and no-retraining claims therefore cannot yet be evaluated.
Authors: We agree that the abstract and Section 4 would benefit from greater quantitative specificity. In the revised manuscript we have expanded the abstract to report concrete performance deltas versus the strongest baselines, the primary metrics (e.g., accuracy on source and target benchmarks), and the number of evaluation runs. Section 4 now includes full tables with mean results and standard deviations over five independent random seeds, together with statistical significance tests (paired t-tests with p-values) against each baseline. These additions make the claims of outperformance and balanced performance directly verifiable from the text. revision: yes
-
Referee: [§5] §5 (Generalization experiments): the no-retraining transfer to unseen source fields and target models rests on the assumption that rewards from the fixed math-reasoning evaluation environment encode domain-invariant balancing rules rather than benchmark-specific optima. If the agent overfits to the metric surfaces of the training benchmarks, performance on truly novel fields or models would be expected to degrade; the manuscript should provide an ablation that isolates this risk (e.g., training on one set of metrics and testing on an orthogonal held-out metric suite).
Authors: We acknowledge the possibility that the learned policy could overfit to the particular metric surfaces of the math-reasoning benchmarks. While the current experiments already show transfer to unseen source fields, target models, and the distinct code-generation domain, we have added a targeted ablation in the revised Section 5. The agent is retrained using only a subset of the original metrics and then evaluated on a held-out orthogonal metric suite drawn from different reasoning tasks. The policy continues to produce balanced performance, indicating that the learned re-weighting heuristics capture more general balancing principles rather than benchmark-specific optima. We have also clarified the composition of the evaluation environment to emphasize its diversity. revision: yes
Circularity Check
No significant circularity in RL-based domain reweighting derivation
full rationale
The paper's core derivation introduces a Data Mixing Agent trained end-to-end via reinforcement learning on mixing trajectories, with rewards drawn from an external evaluation environment on source/target benchmarks. Generalization claims to unseen fields, models, and domain spaces rest on reported experimental outcomes rather than any reduction of the learned policy to a self-defined fit or tautological renaming. No load-bearing step equates a prediction to its own inputs by construction, and the framework remains self-contained against the stated benchmarks without invoking unverified self-citations or ansatzes as the sole justification.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL training hyperparameters and reward scaling
axioms (1)
- domain assumption Evaluation environment feedback accurately reflects downstream model utility on source and target tasks.
invented entities (1)
-
Data Mixing Agent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Data Mixing Agent, the first model-based, end-to-end framework that learns to re-weight domains... optimized in an off-policy reinforcement learning manner using the Conservative Q-Learning (CQL) algorithm
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
domain re-weighting as a Markov Decision Process (MDP)... action at ∈ R^N ... reward(M) = [Score(M, D1), ...]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Data Mixing for Large Language Models Pretraining: A Survey and Outlook
A survey that taxonomizes data mixing strategies for LLM pretraining into static rule-based, learning-based, and dynamic adaptive families while highlighting transferability challenges and evaluation gaps.
Reference graph
Works this paper leans on
-
[1]
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
Mathqa: Towards interpretable math word problem solving with operation-based formalisms. arXiv preprint arXiv:1905.13319 (2019). Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[2]
Program Synthesis with Large Language Models
Program synthesis with large language models. arXiv preprint arXiv:2108.07732 (2021). Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021). Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457 (2018). Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021). Shizhe Diao, Yu Yang, Yonggan Fu, Xin Dong, Dan Su, Markus Kliegl, Zijia Chen, Peter Bel- cak, Yoshi Suhara, Hongxu Yin, et al
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
CLIMB: CLustering-based Iterative Data Mixture Bootstrapping for Language Model Pre-training. arXiv preprint arXiv:2504.13161 (2025). Nan Du, Yanping Huang, Andrew M Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, et al
-
[7]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027 (2020). Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[8]
arXiv e-prints (2024), arXiv–2407
The llama 3 herd of models. arXiv e-prints (2024), arXiv–2407. 18 Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Yu Wu, YK Li, et al
work page 2024
-
[9]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
DeepSeek-Coder: When the Large Language Model Meets Programming–The Rise of Code Intelligence. arXiv preprint arXiv:2401.14196 (2024). Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Ja- cob Steinhardt
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300 (2020). Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[11]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 (2021). Jian Hu, Xibin Wu, Zilin Zhu, Weixun Wang, Dehao Zhang, Yu Cao, et al
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
Openrlhf: An easy-to-use, scalable and high-performance rlhf framework. arXiv preprint arXiv:2405.11143 (2024). Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186 (2024). Hamish Ivison, Yizhong Wang, Jiacheng Liu, Zeqiu Wu, Valentina Pyatkin, Nathan Lambert, Noah A Smith, Yejin Choi, and Hanna Hajishirzi
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Advances in neural information processing systems 37 (2024), 36602–36633
Unpacking dpo and ppo: Disentangling best practices for learning from preference feedback. Advances in neural information processing systems 37 (2024), 36602–36633. Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine
work page 2024
-
[15]
Advances in neural information processing systems 33 (2020), 1179–1191
Conservative q-learning for offline reinforcement learning. Advances in neural information processing systems 33 (2020), 1179–1191. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al
work page 2020
-
[16]
Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems 35 (2022), 3843–3857. Hao Li, Bowen Deng, Chang Xu, Zhiyuan Feng, Viktor Schlegel, Yu-Hao Huang, Yizheng Sun, Jingyuan Sun, Kailai Yang, Yiyao Yu, et al
work page 2022
-
[17]
MIRA: Medical Time Series Foundation Model for Real-World Health Data. arXiv preprint arXiv:2506.07584 (2025). Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Yitzhak Gadre, Hritik Bansal, Etash Guha, Sedrick Scott Keh, Kushal Arora, et al
-
[18]
Advances in Neural Information Processing Systems 37 (2024), 14200–14282
Datacomp-lm: In search of the next generation of training sets for language models. Advances in Neural Information Processing Systems 37 (2024), 14200–14282. Zhenghao Lin, Zihao Tang, Xiao Liu, Yeyun Gong, Yi Cheng, Qi Chen, Hang Li, Ying Xin, Ziyue Yang, Kailai Yang, et al
work page 2024
-
[19]
arXiv preprint arXiv:2501.13629 (2025)
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models. arXiv preprint arXiv:2501.13629 (2025). Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024a. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437 (2024). Jian Liu, Leyang Cui, H...
-
[20]
arXiv preprint arXiv:2007.08124 (2020)
Logiqa: A challenge dataset for machine reading comprehension with logical reasoning. arXiv preprint arXiv:2007.08124 (2020). Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guangtao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, and Min Lin. 2024b. Regmix: Data mixture as regression for language model pre-training. arXiv preprint arXiv:2407.01492 (2024). Yun Lu...
-
[21]
An Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
An empirical study of catastrophic forgetting in large language models during continual fine-tuning. arXiv preprint arXiv:2308.08747 (2023). 19 Zheheng Luo, Xin Zhang, Xiao Liu, Haoling Li, Yeyun Gong, Chen Qi, and Peng Cheng
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
arXiv preprint arXiv:2411.14318 (2024)
Velocitune: A Velocity-based Dynamic Domain Reweighting Method for Continual Pre-training. arXiv preprint arXiv:2411.14318 (2024). Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal
-
[23]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789 (2018). Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bha- gia, Yuling Gu, Shengyi Huang, Matt Jordan, et al
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
2 OLMo 2 Furious. arXiv preprint arXiv:2501.00656 (2024). Guilherme Penedo, Hynek Kydlíˇcek, Anton Lozhkov, Margaret Mitchell, Colin A Raffel, Leandro V on Werra, Thomas Wolf, et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Advances in Neural Information Processing Systems 37 (2024), 30811–30849
The fineweb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Processing Systems 37 (2024), 30811–30849. Alexey Rukhovich, Alexander Podolskiy, and Irina Piontkovskaya
work page 2024
-
[26]
arXiv preprint arXiv:2501.15556 (2025)
Commute Your Domains: Trajectory Optimality Criterion for Multi-Domain Learning. arXiv preprint arXiv:2501.15556 (2025). Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang
-
[27]
Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. arXiv preprint arXiv:1911.08731 (2019). Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[28]
Winogrande: An adversarial winograd schema challenge at scale. Commun. ACM 64, 9 (2021), 99–106. Takuma Seno and Michita Imai
work page 2021
-
[29]
Journal of Machine Learning Research 23, 315 (2022), 1–20
d3rlpy: An Offline Deep Reinforcement Learning Library. Journal of Machine Learning Research 23, 315 (2022), 1–20. http://jmlr.org/papers/v23/ 22-0017.html Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al
work page 2022
-
[30]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models. arXiv preprint arXiv:2402.03300 (2024). Zhiqiang Shen, Tianhua Tao, Liqun Ma, Willie Neiswanger, Zhengzhong Liu, Hongyi Wang, Bowen Tan, Joel Hestness, Natalia Vassilieva, Daria Soboleva, et al
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Slimpajama-dc: Understanding dat a combinations for llm training
Slimpajama-dc: Understanding data combinations for llm training. arXiv preprint arXiv:2309.10818 (2023). Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang
-
[32]
Continual learning of large language models: A comprehensive survey. Comput. Surveys (2024). Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro
work page 2024
-
[33]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053 (2019). Dan Su, Kezhi Kong, Ying Lin, Joseph Jennings, Brandon Norick, Markus Kliegl, Mostofa Patwary, Mohammad Shoeybi, and Bryan Catanzaro
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[34]
Nemotron-CC: Transforming Common Crawl into a Refined Long-Horizon Pretraining Dataset. arXiv preprint arXiv:2412.02595 (2024). Richard S Sutton, David McAllester, Satinder Singh, and Yishay Mansour
-
[35]
Advances in neural information processing systems 12 (1999)
Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems 12 (1999). Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al
work page 1999
-
[36]
Nejm Ai 1, 3 (2024), AIoa2300138
Towards generalist biomedical AI. Nejm Ai 1, 3 (2024), AIoa2300138. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin
work page 2024
-
[37]
Advances in neural information processing systems 30 (2017)
Attention is all you need. Advances in neural information processing systems 30 (2017). 20 Ke Wang, Houxing Ren, Aojun Zhou, Zimu Lu, Sichun Luo, Weikang Shi, Renrui Zhang, Linqi Song, Mingjie Zhan, and Hongsheng Li
work page 2017
-
[38]
Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning,
Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning. arXiv preprint arXiv:2310.03731 (2023). Johannes Welbl, Nelson F Liu, and Matt Gardner
-
[39]
Crowdsourcing Multiple Choice Science Questions
Crowdsourcing multiple choice science questions. arXiv preprint arXiv:1707.06209 (2017). Alexander Wettig, Kyle Lo, Sewon Min, Hannaneh Hajishirzi, Danqi Chen, and Luca Soldaini
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
arXiv preprint arXiv:2502.10341 (2025)
Organize the Web: Constructing Domains Enhances Pre-Training Data Curation. arXiv preprint arXiv:2502.10341 (2025). Xiangyu Xi, Deyang Kong, Jian Yang, Jiawei Yang, Zhengyu Chen, Wei Wang, Jingang Wang, Xunliang Cai, Shikun Zhang, and Wei Ye
-
[41]
arXiv preprint arXiv:2503.01506 (2025)
SampleMix: A Sample-wise Pre-training Data Mixing Strategey by Coordinating Data Quality and Diversity. arXiv preprint arXiv:2503.01506 (2025). Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen
-
[42]
arXiv preprint arXiv:2310.06694 (2023)
Sheared llama: Accelerating language model pre-training via structured pruning. arXiv preprint arXiv:2310.06694 (2023). Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, et al
-
[43]
Advances in Neural Information Processing Systems 37 (2024), 95716–95743
Finben: A holistic financial benchmark for large language models. Advances in Neural Information Processing Systems 37 (2024), 95716–95743. Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu
work page 2024
-
[44]
Advances in Neural Information Processing Systems 36 (2023), 69798–69818
Doremi: Optimizing data mixtures speeds up language model pretraining. Advances in Neural Information Processing Systems 36 (2023), 69798–69818. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al
work page 2023
-
[45]
Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025). An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122 (2024). Jiasheng Ye, Peiju Liu, Tianxiang Sun, Jun Zhan, Yunhua Zhou, and Xipeng Qiu
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Data mixing laws: Optimizing data mixtures by predicting language modeling performance, 2024
Data mixing laws: Optimizing data mixtures by predicting language modeling performance. arXiv preprint arXiv:2403.16952 (2024). Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu
-
[48]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284 (2023). Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
HellaSwag: Can a Machine Really Finish Your Sentence?
Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830 (2019). Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K Gupta, and Jingbo Shang
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[50]
Large language models for time series: A survey. arXiv preprint arXiv:2402.01801 (2024). 21
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.