ReasonRank: Empowering Passage Ranking with Strong Reasoning Ability
Pith reviewed 2026-05-18 23:50 UTC · model grok-4.3
The pith
A reranker trained on synthesized reasoning data and multi-view rewards outperforms baselines in passage ranking while running faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
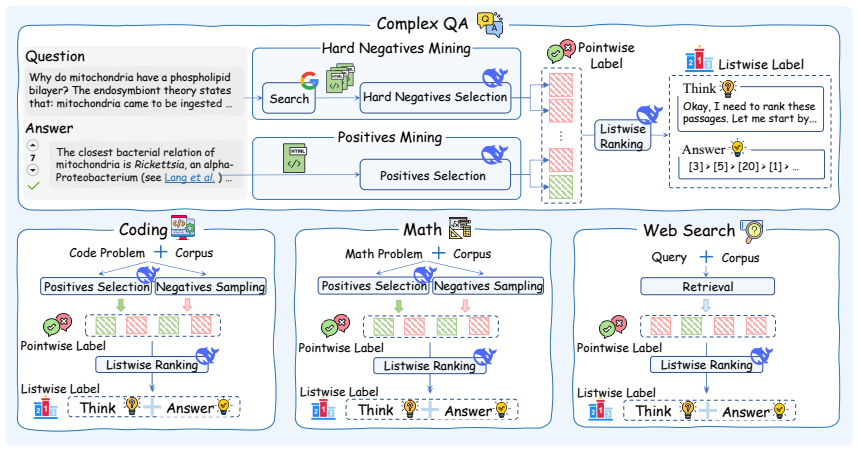
The authors develop ReasonRank by first creating an automated framework that draws queries and passages from varied domains to produce reasoning-intensive training labels, then applying a two-stage process of cold-start supervised fine-tuning followed by reinforcement learning that uses a multi-view ranking reward matched to the multi-turn character of listwise ranking; the resulting model delivers stronger performance than prior rerankers and lower latency than pointwise alternatives.
What carries the argument
The multi-view ranking reward that scores the quality of multi-turn listwise ranking decisions from multiple perspectives during reinforcement learning.
If this is right
- The model significantly outperforms existing listwise and pointwise rerankers on standard passage ranking benchmarks.
- It delivers the performance gains at substantially lower latency than pointwise rerankers.
- Enhanced reasoning ability allows better results on ranking scenarios that require handling intricate query-passage relationships.
- The two-stage training with the multi-view reward improves ranking decisions across the iterative listwise process.
Where Pith is reading between the lines
- The same synthesis and reward design could be tried on other retrieval or recommendation tasks that benefit from explicit reasoning steps.
- Lower observed latency opens the door to deploying such models in latency-sensitive production search systems without sacrificing quality.
- The multi-turn reward structure might transfer to sequential decision tasks outside ranking, such as multi-step planning or dialogue response selection.
Load-bearing premise
Automatically generated reasoning labels from diverse sources are high-quality enough to train rerankers that generalize to complex ranking problems.
What would settle it
Testing the trained reranker on a fresh set of complex ranking queries drawn from domains outside the synthesis process and checking whether accuracy and latency gains over baselines remain or disappear.
Figures




read the original abstract
Large Language Model (LLM) based listwise ranking has shown superior performance in many passage ranking tasks. With the development of Large Reasoning Models (LRMs), many studies have demonstrated that step-by-step reasoning during test-time helps improve listwise ranking performance. However, due to the scarcity of reasoning-intensive training data, existing rerankers perform poorly in many complex ranking scenarios, and the ranking ability of reasoning-intensive rerankers remains largely underdeveloped. In this paper, we first propose an automated reasoning-intensive training data synthesis framework, which sources training queries and passages from diverse domains and applies DeepSeek-R1 to generate high-quality training labels. To empower the listwise reranker with strong reasoning ability, we further propose a two-stage training approach, which includes a cold-start supervised fine-tuning (SFT) stage and a reinforcement learning (RL) stage. During the RL stage, we design a novel multi-view ranking reward tailored to the multi-turn nature of listwise ranking. Extensive experiments demonstrate that our trained reasoning-intensive reranker \textbf{ReasonRank} outperforms existing baselines significantly and also achieves much lower latency than the pointwise reranker. Our codes are available at https://github.com/8421BCD/ReasonRank.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReasonRank, a listwise reranker empowered with reasoning abilities through an automated training data synthesis framework that uses DeepSeek-R1 to generate reasoning-intensive labels from diverse domain queries and passages. It employs a two-stage training approach consisting of supervised fine-tuning (SFT) for cold-start and reinforcement learning (RL) with a novel multi-view ranking reward tailored to the multi-turn nature of listwise ranking. The paper claims that this results in significant outperformance over existing baselines and lower latency than pointwise rerankers.
Significance. If the empirical results hold, this work addresses a key limitation in LLM-based ranking by developing reasoning capabilities for complex scenarios where current rerankers underperform. The combination of automated synthesis and multi-view reward could provide a scalable way to train more capable ranking models, potentially improving retrieval systems in information retrieval applications. The reported latency advantages would be particularly valuable for practical deployment.
major comments (1)
- [Automated Reasoning-Intensive Training Data Synthesis Framework] The automated synthesis framework (described in the methods section) applies DeepSeek-R1 to produce reasoning labels but reports no quantitative metrics on label fidelity, no human validation of reasoning chains, and no ablation removing the reasoning component to confirm that gains are attributable to it rather than data artifacts. This is load-bearing for the central claim that the two-stage SFT+RL process successfully imparts strong reasoning ability for complex ranking scenarios.
minor comments (1)
- [Abstract] The abstract states that ReasonRank 'achieves much lower latency than the pointwise reranker' without specifying the exact latency values, the pointwise baseline model, or the hardware/setup used for measurement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights an important area for strengthening our claims. We respond to the major comment below and commit to revisions that directly address the concerns raised.
read point-by-point responses
-
Referee: [Automated Reasoning-Intensive Training Data Synthesis Framework] The automated synthesis framework (described in the methods section) applies DeepSeek-R1 to produce reasoning labels but reports no quantitative metrics on label fidelity, no human validation of reasoning chains, and no ablation removing the reasoning component to confirm that gains are attributable to it rather than data artifacts. This is load-bearing for the central claim that the two-stage SFT+RL process successfully imparts strong reasoning ability for complex ranking scenarios.
Authors: We agree that the current version lacks explicit quantitative validation of the synthesized labels and an ablation isolating the reasoning component, which would more rigorously support attribution of gains to reasoning ability. In the revised manuscript we will add: (1) quantitative fidelity metrics, including agreement scores between DeepSeek-R1 outputs and human raters on a sampled subset of 300 query-passage pairs; (2) human validation results where annotators assess reasoning chain coherence, relevance to ranking decisions, and overall quality using a standardized rubric; and (3) an ablation experiment training a control model on non-reasoning labels (direct ranking supervision) and comparing its performance against ReasonRank on the same test sets. These additions will provide direct evidence that performance improvements derive from the reasoning-intensive data rather than artifacts. We believe the existing empirical gains and the design of the multi-view reward already indicate the value of the approach, but the requested analyses will make this explicit. revision: yes
Circularity Check
No circularity: empirical results rest on external baselines and standard training pipeline
full rationale
The paper presents an automated data synthesis step using DeepSeek-R1 followed by standard two-stage SFT+RL training and reports performance via direct comparison to external baselines. No derivation reduces to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing self-citation or uniqueness theorem is invoked. The multi-view reward is defined explicitly for the listwise setting rather than being smuggled in or self-referential. Central claims are therefore falsifiable against held-out test sets and independent rerankers.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-view ranking reward formulation
axioms (1)
- domain assumption DeepSeek-R1 produces high-quality reasoning labels suitable for training rerankers on complex queries
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we propose a two-stage post-training approach, which includes a cold-start supervised fine-tuning (SFT) stage ... and a reinforcement learning (RL) stage ... multi-view ranking reward ... NDCG@10 + ϕ ∗ Recall@10 + γ ∗ RBO
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 7 Pith papers
-
Very Efficient Listwise Multimodal Reranking for Long Documents
ZipRerank delivers state-of-the-art multimodal listwise reranking accuracy for long documents at up to 10x lower latency via early interaction and single-pass scoring.
-
A Survey of Reasoning-Intensive Retrieval: Progress and Challenges
A survey that categorizes RIR benchmarks by domain and modality, proposes a taxonomy for integrating reasoning into retrieval pipelines, and outlines key challenges.
-
Learning from Emptiness: De-biasing Listwise Rerankers with Content-Agnostic Probability Calibration
CapCal de-biases generative listwise rerankers via content-agnostic placeholder-based bias estimation and entropy-adaptive logit rectification, yielding over 10-point NDCG gains on lightweight models across 10 benchma...
-
ReasonEmbed: Enhanced Text Embeddings for Reasoning-Intensive Document Retrieval
ReasonEmbed achieves a new high of 38.1 nDCG@10 on the BRIGHT benchmark for reasoning-intensive retrieval by combining a triviality-resistant data synthesis method with dynamic per-sample training weights.
-
Context Convergence Improves Answering Inferential Questions
Passages made from high-convergence sentences improve LLM performance on inferential questions compared to cosine similarity selection.
-
Rich-Media Re-Ranker: A User Satisfaction-Driven LLM Re-ranking Framework for Rich-Media Search
A re-ranking system for rich-media search that plans query intents from sessions, adds visual signals from VLMs, and uses an LLM to score results on multiple facets before multi-task RL adaptation, with reported gains...
-
GroupRank: A Groupwise Paradigm for Effective and Efficient Passage Reranking with LLMs
GroupRank uses groupwise LLM reranking with answer-free data synthesis and a group-ranking reward to reach 65.2 NDCG@10 on BRIGHT while providing 6.4x faster inference than listwise baselines.
Reference graph
Works this paper leans on
-
[1]
OpenAI o1 System Card. CoRR, abs/2412.16720. Li, L.; Zhou, X.; and Liu, Z. 2025. R2MED: A Bench- mark for Reasoning-Driven Medical Retrieval. CoRR, abs/2505.14558. Liang, P.; Bommasani, R.; Lee, T.; Tsipras, D.; Soylu, D.; Yasunaga, M.; Zhang, Y .; Narayanan, D.; Wu, Y .; Kumar, A.; Newman, B.; Yuan, B.; Yan, B.; Zhang, C.; Cosgrove, C.; Manning, C. D.; R...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Large Language Models are Effective Text Rankers with Pairwise Ranking Prompting. CoRR, abs/2306.17563. Rasley, J.; Rajbhandari, S.; Ruwase, O.; and He, Y . 2020. DeepSpeed: System Optimizations Enable Training Deep Learning Models with Over 100 Billion Parameters. KDD ’20. Sachan, D. S.; Lewis, M.; Joshi, M.; Aghajanyan, A.; Yih, W.; Pineau, J.; and Zett...
-
[3]
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and Efficient Foundation Language Models. CoRR, abs/2302.13971. Wang, L.; Yang, N.; Huang, X.; Yang, L.; Majumder, R.; and Wei, F. 2024. Improving Text Embeddings with Large Language Models. In ACL (1), 11897–11916. Association for Computational Linguistics. Wang, X.; Wei, J.; Schuurmans, D.; Le, Q. V .; Chi, E. H.; Narang, S.; Chowdhery, A.; ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
ListT5: Listwise Reranking with Fusion-in-Decoder Improves Zero-shot Retrieval. In ACL (1), 2287–2308. As- sociation for Computational Linguistics. Yoon, S.; Kim, G.; Cho, G.; and Hwang, S. 2025. Acu- Rank: Uncertainty-Aware Adaptive Computation for List- wise Reranking. CoRR, abs/2505.18512. Zhang, L.; Wang, B.; Qiu, X.; Reddy, S.; and Agrawal, A
-
[5]
REARANK: Reasoning Re-ranking Agent via Rein- forcement Learning. CoRR, abs/2505.20046. Zheng, Y .; Zhang, R.; Zhang, J.; Ye, Y .; Luo, Z.; and Ma, Y
-
[6]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. CoRR, abs/2403.13372. Zhu, Y .; Yuan, H.; Wang, S.; Liu, J.; Liu, W.; Deng, C.; Dou, Z.; and Wen, J. 2023. Large Language Models for Informa- tion Retrieval: A Survey. CoRR, abs/2308.07107. Zhu, Y .; Zhang, P.; Zhang, C.; Chen, Y .; Xie, B.; Liu, Z.; Wen, J.; and Dou, Z. 2024. INTERS: Un...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
ACM. Benchmarks and Baselines Benchmarks In our experiments, we utilize three IR benchmarks for eval- uation: BRIGHT (Su et al. 2025), R2MED (Li, Zhou, and Liu 2025), and BEIR (Thakur et al. 2021). Each of these benchmarks is instrumental in assessing different aspects of our retrieval models, ensuring a comprehensive evaluation across varied scenarios. T...
work page 2025
-
[8]
and FlashAttention2 (Dao 2023) for our training. We apply mixed precision BF16 for training, set the maximum reasoning length as 3072, and train the model for 5 epochs. As for Qwen2.5-32B-Instruct, we use LoRA (Hu et al
work page 2023
-
[9]
The lora parameters rank and alpha are both set to 32
for efficient SFT. The lora parameters rank and alpha are both set to 32. We set learning rate to 1e-4 and batch size per GPU to 1 with gradient accumulation steps of 8. We use DeepSpeed ZeRO-3 (Rasley et al. 2020) with mixed precision BF16 and train the model for 4 epochs. Multi-view Ranking based RL RL has been shown in many works (Dong et al. 2025a; So...
work page 2020
-
[10]
passages retrieved by ReasonIR. The ranking prompt used by R1 is the same as the prompt used when generating listwise labels based on R1. The results are shown in Ta- ble 9. From the results, we can see that ReasonRank (32B) achieves comparable performance to DeepSeek-R1 (34.18 vs 34.13) and surpasses DeepSeek-R1 on 7 datasets (Eco- nomics, Robotics, Biol...
work page 2024
-
[11]
[3] explains the offset and geodetic systems
is definitely top as it directly answers the movement and GPS. [3] explains the offset and geodetic systems. [11] is about why it moved, so very relevant. [8] explains Earth drift causes. [7] and [18] mention BIH and IERS, which decide references
-
[12]
talks about reference frames. [14] about WGS. [10] historical context. Others less so. So the order might be [1] > [3] > [11] > [8] > [7] > [18] > [2] > [14] > [10] > [9] > [4] > [5] > [16] > [12] > [17] > [20] >
-
[13]
> [6] > [19] > [15] </think> <answer>
-
[14]
The model first analyzes the search query and considers the criteria that make a passage relevant
> [3] > [11] > [8] > [7] > [18] > [2] > [14] > [10] > [9] > [4] > [5] > [16] > [12] > [17] > [20] > [13] > [6] > [19] > [15] </answer> Table 12: Case on Biology. The model first analyzes the search query and considers the criteria that make a passage relevant. Then, it examines some relevant passages and compares them to the criteria. Finally, it quickly ...
-
[15]
The model successfully rank the passage with relatively short reasoning length
> [1] > [5] > [6] > [8] > [2] > [15] > [16] > [10] > [3] > [7] > [12] > [20] > [18] > [9] > [11] > [13] > [14] > [17] > [19] </answer> Table 13: Case study on Robotics. The model successfully rank the passage with relatively short reasoning length. Query ROS2: Adding parameters to Y AML launch file How do I use a Y AML launch file to pass parameters to a ...
-
[16]
> [3] > [8] > [13] > [14] > [15] > [16] > [17] > [18] > [6] > [5] > [19] > [1] > [10] > [11] > [9] > [4] > [7] > [12] > [20] </answer> Table 14: Case on LeetCode. The model rethinks its initial ranking and repeatedly verifies and compares the top-ranked pas- sages.. Query Given an ‘m x n‘ integers ‘matrix‘, return the length of the longest increasing path...
-
[17]
The problem in the query is a classic DP with memoization on the grid
> [19] > [8] > [7] > [15] > [1] > [3] > [6] > [20] > [4] > [9] > [10] > [13] > [16] > [17] > [11] > [14] > [5] > [18] > [12] But need to verify. The problem in the query is a classic DP with memoization on the grid. Passage [2] might be about counting all paths, which is a different problem but uses similar techniques. However, the code in [2] might not d...
-
[18]
We can see that the model first analyzes the search query
> [19] > [8] > [7] > [15] > [1] > [3] > [6] > [20] > [4] > [9] > [10] > [13] > [16] > [17] > [11] > [14] > [5] > [18] > [12] </answer> Table 15: Case on AoPS. We can see that the model first analyzes the search query. Then, it looks at each passage and judges their relevance. Finally, it takes a closer look at the most relevant ones and makes a detailed c...
-
[19]
Might be relevant since the problem involves chords and circle properties
Talks about a circle, chord lengths, power of a point. Might be relevant since the problem involves chords and circle properties
-
[20]
Could be relevant as it’s about triangle geometry with circle
Involves triangle inscribed in a circle, tangents, and intersections. Could be relevant as it’s about triangle geometry with circle
-
[21]
Less relevant, seems more about trapezoids and tangents
Circles intersecting, common tangents, trapezoid area. Less relevant, seems more about trapezoids and tangents
-
[22]
Maybe somewhat related but not directly
Circumcenter and distance calculation. Maybe somewhat related but not directly
- [23]
- [24]
- [25]
- [26]
- [27]
-
[28]
Maybe trigonometry, but not directly
Perimeter with Law of Cosines. Maybe trigonometry, but not directly
- [29]
-
[30]
Could be relevant as it involves circumcircle and intersections
Circumcircle and tangents. Could be relevant as it involves circumcircle and intersections
- [31]
- [32]
- [33]
- [34]
-
[35]
Maybe involves some circle theorems
Tangent and angle bisector. Maybe involves some circle theorems
- [36]
- [37]
-
[38]
Circle tangent to parabola. Not relevant. So the most relevant ones are probably [1], [2], [12], [17], maybe [4], [20]. Passage [1] discusses chord lengths and power of a point, which might be useful here since the problem involves ST as a chord. Passage [2] is about triangle inscribed in a circle with tangents and intersections, which is very similar to ...
-
[39]
The model first attempts to solve the problem, then checks the candidate passages
> [1] > [12] > [17] > [4] > [20] > [8] > [14] > [18] > [5] > [3] > [6] > [7] > [10] > [13] > [9] > [15] > [16] > [19] > [11] </answer> Table 16: Case study on TheoremQA-Theorems. The model first attempts to solve the problem, then checks the candidate passages. Query You are working with four possible machines, each of which is represented by a matrix tha...
-
[40]
talks about bounded projections, which might be related but less directly. Passage [6] explains linear transformations as matrix products, which is relevant for understanding how these matrices act. Passage [9] involves inner products and matrix factors, which could relate to the projection formula. Passage [14] is about matrix products as linear transfor...
-
[41]
> [3] > [8] > [17] > [6] > [20] > [9] > [14] > [12] > [1] > [7] > [10] > [18] > [13] > [15] > [4] > [5] > [11] > [16] > [19] </answer>
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.