Recognition: 2 theorem links
· Lean TheoremFine-tuning is Not Enough: A Parallel Framework for Collaborative Imitation and Reinforcement Learning in End-to-end Autonomous Driving
Pith reviewed 2026-05-15 11:52 UTC · model grok-4.3
The pith
PaIR-Drive runs imitation and reinforcement learning in parallel branches to exceed sequential fine-tuning limits in end-to-end autonomous driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
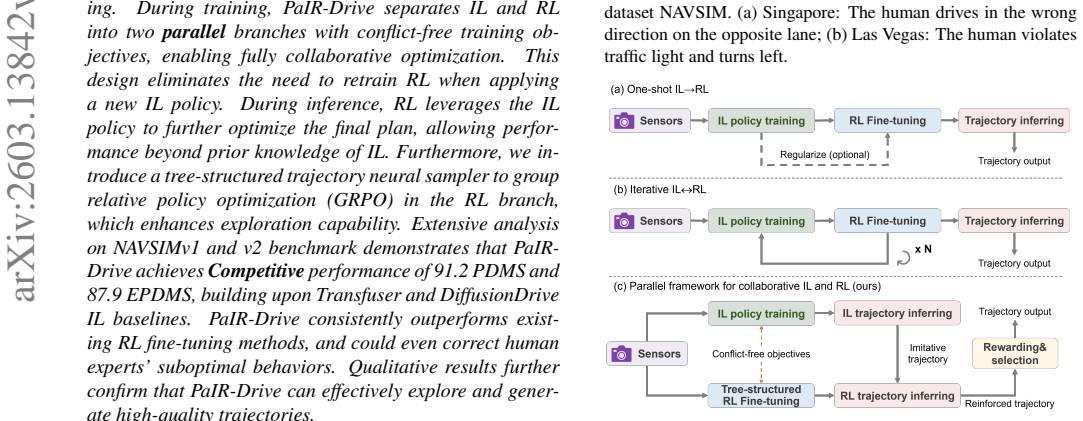
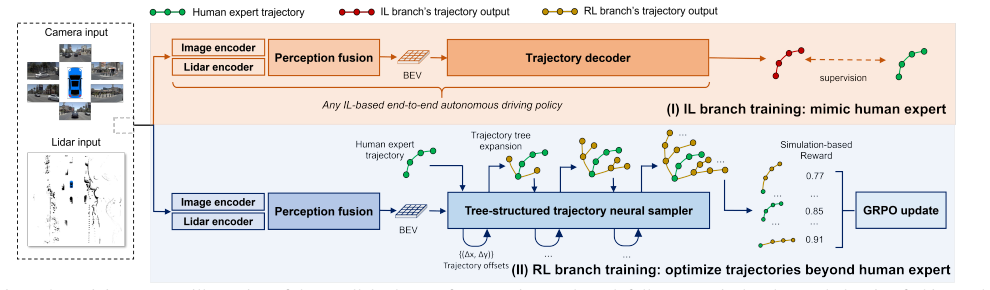
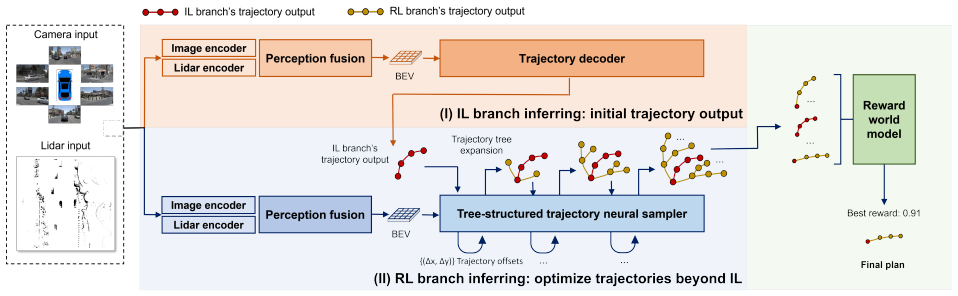
PaIR-Drive separates IL and RL into parallel branches with conflict-free training objectives, enabling fully collaborative optimization during training and RL-based refinement of the final plan at inference time through a tree-structured trajectory neural sampler that supports grouped relative policy optimization.
What carries the argument
Parallel IL-RL branches with conflict-free objectives plus tree-structured trajectory neural sampler for GRPO in the RL branch
If this is right
- No need to retrain the RL branch when swapping in a new IL policy
- Performance can exceed the quality of the original human demonstrations
- Suboptimal behaviors in human expert data can be corrected by the RL branch
- Exploration in the RL branch is strengthened by the tree-structured sampler
Where Pith is reading between the lines
- The same parallel-branch pattern could be tested in other robotics domains where demonstration data and trial-and-error learning are combined
- Avoiding sequential fine-tuning may reduce hidden sample-inefficiency costs that arise when RL starts from a drifted IL policy
- Dynamic weighting between the two branches could be explored for different driving scenarios without changing the core architecture
Load-bearing premise
Imitation learning and reinforcement learning can be trained in fully separate parallel branches with conflict-free objectives while still enabling effective collaborative optimization and inference-time refinement without integration instabilities or reduced sample efficiency.
What would settle it
If side-by-side runs on NAVSIM show that the parallel branches produce lower PDMS scores than standard sequential RL fine-tuning, or if the RL refinement step fails to improve the trajectory quality produced by the IL policy alone.
Figures



read the original abstract
End-to-end autonomous driving is typically built upon imitation learning (IL), yet its performance is constrained by the quality of human demonstrations. To overcome this limitation, recent methods incorporate reinforcement learning (RL) through sequential fine-tuning. However, such a paradigm remains suboptimal: sequential RL fine-tuning can introduce policy drift and often leads to a performance ceiling due to its dependence on the pretrained IL policy. To address these issues, we propose PaIR-Drive, a general Parallel framework for collaborative Imitation and Reinforcement learning in end-to-end autonomous driving. During training, PaIR-Drive separates IL and RL into two parallel branches with conflict-free training objectives, enabling fully collaborative optimization. This design eliminates the need to retrain RL when applying a new IL policy. During inference, RL leverages the IL policy to further optimize the final plan, allowing performance beyond prior knowledge of IL. Furthermore, we introduce a tree-structured trajectory neural sampler to group relative policy optimization (GRPO) in the RL branch, which enhances exploration capability. Extensive analysis on NAVSIMv1 and v2 benchmark demonstrates that PaIR-Drive achieves Competitive performance of 91.2 PDMS and 87.9 EPDMS, building upon Transfuser and DiffusionDrive IL baselines. PaIR-Drive consistently outperforms existing RL fine-tuning methods, and could even correct human experts' suboptimal behaviors. Qualitative results further confirm that PaIR-Drive can effectively explore and generate high-quality trajectories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
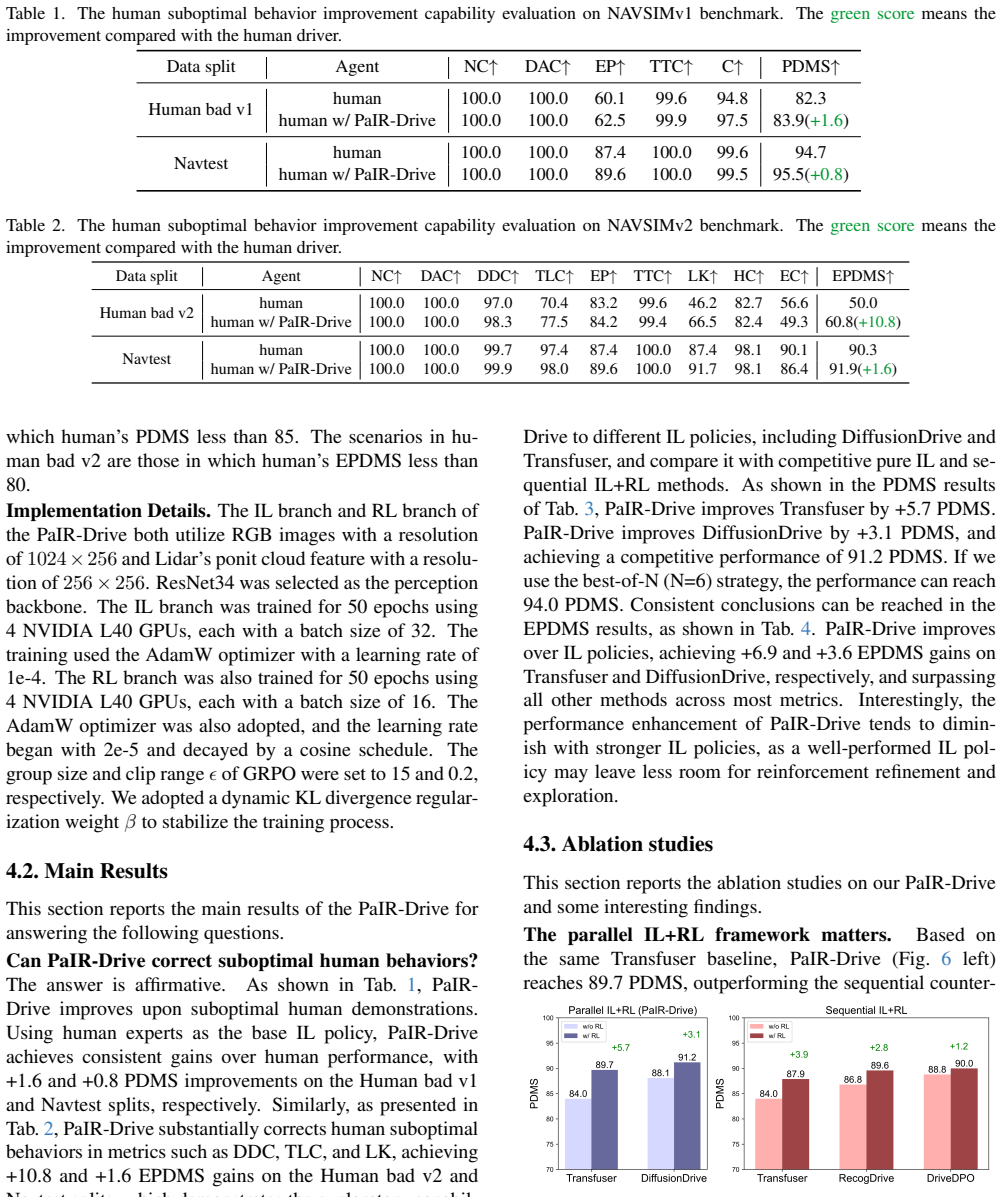
Summary. The manuscript proposes PaIR-Drive, a parallel framework for end-to-end autonomous driving that trains imitation learning (IL) and reinforcement learning (RL) in separate branches with conflict-free objectives. It introduces a tree-structured trajectory neural sampler for grouped relative policy optimization (GRPO) in the RL branch. The design claims to eliminate policy drift from sequential fine-tuning, enable collaborative optimization without retraining RL for new IL policies, and support inference-time plan refinement beyond the IL prior. On NAVSIMv1 and v2, PaIR-Drive reports 91.2 PDMS and 87.9 EPDMS when built on Transfuser and DiffusionDrive baselines, outperforming existing RL fine-tuning methods and correcting suboptimal human behaviors.
Significance. If the parallel architecture and GRPO sampler deliver the claimed gains without hidden instabilities, the work would provide a practical alternative to sequential IL-then-RL pipelines in autonomous driving. The ability to swap IL policies without retraining RL and to refine plans at inference time could improve sample efficiency and robustness in hybrid learning settings.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments: The central performance claims (91.2 PDMS, 87.9 EPDMS) and the statement that PaIR-Drive 'consistently outperforms existing RL fine-tuning methods' are presented without error bars, ablation tables, or details on data exclusion rules and statistical testing. These omissions make it impossible to evaluate whether the reported margins are load-bearing or within noise.
- [Methods] Methods: The assertion that IL and RL branches operate with 'conflict-free training objectives' enabling 'fully collaborative optimization' is load-bearing for the parallel-framework claim, yet no explicit formulation (loss terms, gradient isolation mechanism, or stability analysis) is referenced. Without this, the advantage over sequential fine-tuning remains an unverified architectural assertion.
- [Experiments] Experiments: The claim that PaIR-Drive 'could even correct human experts' suboptimal behaviors' is central to the motivation yet lacks quantitative per-scenario metrics or qualitative trajectory comparisons showing improvement over the IL baseline in the same episodes. This weakens the inference-time refinement argument.
minor comments (2)
- [Abstract] Abstract: The sentence 'achieves Competitive performance' contains an unnecessary capital 'C'; standardize to lowercase.
- [Methods] Notation: The acronym GRPO is introduced without expansion on first use; provide the full term 'Grouped Relative Policy Optimization' at its first appearance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments: The central performance claims (91.2 PDMS, 87.9 EPDMS) and the statement that PaIR-Drive 'consistently outperforms existing RL fine-tuning methods' are presented without error bars, ablation tables, or details on data exclusion rules and statistical testing. These omissions make it impossible to evaluate whether the reported margins are load-bearing or within noise.
Authors: We agree that error bars, ablation tables, and statistical details are necessary for robust evaluation. In the revised manuscript we will report means and standard deviations over multiple random seeds, add ablation tables for the parallel branches and GRPO sampler, specify data exclusion rules, and include the statistical tests used to assess significance of the reported gains over baselines. revision: yes
-
Referee: [Methods] Methods: The assertion that IL and RL branches operate with 'conflict-free training objectives' enabling 'fully collaborative optimization' is load-bearing for the parallel-framework claim, yet no explicit formulation (loss terms, gradient isolation mechanism, or stability analysis) is referenced. Without this, the advantage over sequential fine-tuning remains an unverified architectural assertion.
Authors: The IL branch optimizes a standard imitation loss on expert trajectories while the RL branch optimizes the GRPO objective using environment rewards; the branches maintain separate parameters and no gradients are propagated between them. We will add the explicit loss equations, describe the gradient isolation mechanism, and include a short stability analysis based on our training curves in the revised Methods section. revision: yes
-
Referee: [Experiments] Experiments: The claim that PaIR-Drive 'could even correct human experts' suboptimal behaviors' is central to the motivation yet lacks quantitative per-scenario metrics or qualitative trajectory comparisons showing improvement over the IL baseline in the same episodes. This weakens the inference-time refinement argument.
Authors: We will augment the Experiments section with per-scenario quantitative metrics comparing PaIR-Drive trajectories against both the IL baseline and human demonstrations, together with qualitative visualizations of specific episodes in which the RL refinement at inference time improves upon suboptimal human behaviors. revision: yes
Circularity Check
No significant circularity; framework is an independent architectural proposal validated on external benchmarks
full rationale
The paper introduces PaIR-Drive as a parallel IL-RL architecture with separate branches, conflict-free objectives, and a tree-structured GRPO sampler. Claims of performance gains (91.2 PDMS, 87.9 EPDMS on NAVSIM) are presented as empirical results from benchmark evaluations building on external baselines (Transfuser, DiffusionDrive), not as quantities derived by construction from fitted parameters or self-referential definitions. No equations, uniqueness theorems, or ansatzes are shown to reduce the central claims to tautologies or prior self-citations. The derivation chain is self-contained via architectural description and external validation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PaIR-Drive separates IL and RL into two parallel branches with conflict-free training objectives... tree-structured trajectory neural sampler to group relative policy optimization (GRPO)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PaIR-Drive achieves Competitive performance of 91.2 PDMS and 87.9 EPDMS... outperforms existing RL fine-tuning methods
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
DINO-VO: Learning Where to Focus for Enhanced State Estimation
DINO-VO achieves state-of-the-art monocular visual odometry accuracy and generalization by training a differentiable patch selector together with multi-task features and inverse-depth bundle adjustment.
-
RAD-2: Scaling Reinforcement Learning in a Generator-Discriminator Framework
RAD-2 uses a diffusion generator and RL discriminator to cut collision rates by 56% in closed-loop autonomous driving planning.
Reference graph
Works this paper leans on
-
[1]
From imitation to refinement- residual rl for precise assembly
Lars Ankile, Anthony Simeonov, Idan Shenfeld, Marcel Torne, and Pulkit Agrawal. From imitation to refinement- residual rl for precise assembly. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 01–
-
[2]
Efficient online reinforcement learning with offline data
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023. 2
work page 2023
-
[3]
Planrl: A motion planning and imita- tion learning framework to bootstrap reinforcement learning
Amisha Bhaskar, Zahiruddin Mahammad, Sachin R Jadhav, and Pratap Tokekar. Planrl: A motion planning and imita- tion learning framework to bootstrap reinforcement learning. arXiv preprint arXiv:2408.04054, 2024. 2, 3
-
[4]
Pseudo-simulation for autonomous driving.arXiv preprint arXiv:2506.04218,
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, et al. Pseudo-simulation for autonomous driving.arXiv preprint arXiv:2506.04218,
-
[5]
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z. Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen. Research: Learning to reason with search for llms via reinforcement learning.arXiv preprint arXiv:2503.19470,
work page internal anchor Pith review arXiv
-
[6]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Fast Policy Learning through Imitation and Reinforcement
Ching-An Cheng, Xinyan Yan, Nolan Wagener, and Byron Boots. Fast policy learning through imitation and reinforce- ment.arXiv preprint arXiv:1805.10413, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driv- ing.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):12878–12895, 2023. 3, 7
work page 2023
-
[9]
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706–28719, 2024. 5
work page 2024
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI and Daya Guo. Deepseek-r1: Incentiviz- ing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Openvlthinker: Complex vision- language reasoning via iterative sft-rl cycles
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. Openvlthinker: Complex vision- language reasoning via iterative sft-rl cycles. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025. 2
work page 2025
-
[12]
Reinforcement learning via implicit imitation guid- ance.arXiv preprint arXiv:2506.07505, 2025
Perry Dong, Alec M Lessing, Annie S Chen, and Chelsea Finn. Reinforcement learning via implicit imitation guid- ance.arXiv preprint arXiv:2506.07505, 2025. 2
-
[13]
Renju Feng, Ning Xi, Duanfeng Chu, Rukang Wang, Zejian Deng, Anzheng Wang, Liping Lu, Jinxiang Wang, and Yan- jun Huang. Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving. arXiv preprint arXiv:2504.19580, 2025. 7
-
[14]
POLICY FINE. In–ril: Interleaved reinforcement and imita- tion learning for policy fine-tuning.openreview.net, 2025. 2
work page 2025
-
[15]
Haoyu Fu, Diankun Zhang, Zongchuang Zhao, Jianfeng Cui, Dingkang Liang, Chong Zhang, Dingyuan Zhang, Hongwei Xie, Bing Wang, and Xiang Bai. Orion: A holistic end-to- end autonomous driving framework by vision-language in- structed action generation.arXiv preprint arXiv:2503.19755,
-
[16]
Hao Gao, Shaoyu Chen, Bo Jiang, Bencheng Liao, Yiang Shi, Xiaoyang Guo, Yuechuan Pu, Haoran Yin, Xiangyu Li, Xinbang Zhang, Ying Zhang, Wenyu Liu, Qian Zhang, and Xinggang Wang. Rad: Training an end-to-end driving pol- icy via large-scale 3dgs-based reinforcement learning.arXiv preprint arXiv:2502.13144, 2025. 2, 3
-
[17]
Yanchen Guan, Haicheng Liao, Zhenning Li, Jia Hu, Runze Yuan, Guohui Zhang, and Chengzhong Xu. World models for autonomous driving: An initial survey.IEEE Transac- tions on Intelligent Vehicles, 2024. 3
work page 2024
-
[18]
D. Guo, D. Yang, and H. Zhang. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature 645, 633–638., 2025. 2
work page 2025
-
[19]
Imita- tion bootstrapped reinforcement learning.arXiv, 2024
Hengyuan Hu, Suvir Mirchandani, and Dorsa Sadigh. Imita- tion bootstrapped reinforcement learning.arXiv, 2024. 2
work page 2024
-
[20]
Planning-oriented autonomous driv- ing
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, Lewei Lu, Xiaosong Jia, Qiang Liu, Jifeng Dai, Yu Qiao, and Hongyang Li. Planning-oriented autonomous driv- ing. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2023. 1, 2
work page 2023
-
[21]
Zhiyu Huang, Jingda Wu, and Chen Lv. Efficient deep reinforcement learning with imitative expert priors for au- tonomous driving.IEEE Transactions on Neural Networks and Learning Systems, 34(10):7391–7403, 2022. 2
work page 2022
-
[22]
Diffvla: Vision-language guided diffusion planning for autonomous driving,
Anqing Jiang, Yu Gao, Zhigang Sun, Yiru Wang, Jijun Wang, Jinghao Chai, Qian Cao, Yuweng Heng, Hao Jiang, Yunda Dong, et al. Diffvla: Vision-language guided dif- fusion planning for autonomous driving.arXiv preprint arXiv:2505.19381, 2025. 3
-
[23]
Vad: Vectorized scene representation for efficient autonomous driving.ICCV, 2023
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving.ICCV, 2023. 1, 2
work page 2023
-
[24]
Bo Jiang, Shaoyu Chen, Qian Zhang, Wenyu Liu, and Xing- gang Wang. Alphadrive: Unleashing the power of vlms in autonomous driving via reinforcement learning and reason- ing.arXiv preprint arXiv:2503.07608, 2025. 3
-
[25]
Byung-Kwan Lee, Ryo Hachiuma, Yong Man Ro, Yu- Chiang Frank Wang, and Yueh-Hua Wu. Unified rein- forcement and imitation learning for vision-language mod- els.arXiv e-prints, pages arXiv–2510, 2025. 2
work page 2025
-
[26]
F. Leiva and J. Ruiz-del Solar. Combining rl and il using a dynamic, performance-based modulation over learning sig- nals and its application to local planning.arXiv preprint arXiv:2405.09760., 2024. 2
-
[27]
Papl-slam: Principal axis-anchored monocu- lar point-line slam.IEEE Robotics and Automation Letters,
Guanghao Li, Yu Cao, Qi Chen, Xin Gao, Yifan Yang, and Jian Pu. Papl-slam: Principal axis-anchored monocu- lar point-line slam.IEEE Robotics and Automation Letters,
-
[28]
Guanghao Li, Kerui Ren, Linning Xu, Zhewen Zheng, Changjian Jiang, Xin Gao, Bo Dai, Jian Pu, Mulin Yu, and Jiangmiao Pang. Artdeco: Toward high-fidelity on-the-fly reconstruction with hierarchical gaussian structure and feed- forward guidance. InThe Fourteenth International Confer- ence on Learning Representations, 2026. 3
work page 2026
-
[29]
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Hongchen Li, Tianyu Li, Jiazhi Yang, Haochen Tian, Cao- jun Wang, Lei Shi, Mingyang Shang, Zengrong Lin, Gao- qiang Wu, Zhihui Hao, et al. Plannerrft: Reinforcing diffu- sion planners through closed-loop and sample-efficient fine- tuning.arXiv preprint arXiv:2601.12901, 2026. 3
-
[31]
Jingyu Li, Junjie Wu, Dongnan Hu, Xiangkai Huang, Bin Sun, Zhihui Hao, Xianpeng Lang, Xiatian Zhu, and Li Zhang. Sgdrive: Scene-to-goal hierarchical world cognition for autonomous driving.arXiv preprint arXiv:2601.05640,
-
[32]
arXiv preprint arXiv:2406.08481 (2024)
Yingyan Li, Lue Fan, Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang, and Tieniu Tan. Enhancing end-to-end autonomous driving with latent world model.arXiv preprint arXiv:2406.08481, 2024. 3
-
[33]
Yue Li, Meng Tian, Dechang Zhu, Jiangtong Zhu, Zhenyu Lin, Zhiwei Xiong, and Xinhai Zhao. Drive-r1: Bridging reasoning and planning in vlms for autonomous driving with reinforcement learning.arXiv preprint arXiv:2506.18234,
-
[34]
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online tra- jectory evaluation via bev world model.arXiv preprint arXiv:2504.01941, 2025. 7
-
[35]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, Kun Ma, Guang Chen, Hangjun Ye, Wenyu Liu, and Xinggang Wang. Recogdrive: A reinforced cog- nitive framework for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052, 2025. 2, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-mdp: End-to-end multimodal planning with multi- target hydra-distillation.arXiv preprint arXiv:2406.06978,
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M. Alvarez. Is ego status all you need for open- loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14864–14873, 2024. 2
work page 2024
-
[38]
Cirl: Controllable imitative reinforcement learning for vision-based self-driving
Xiaodan Liang, Tairui Wang, Luona Yang, and Eric Xing. Cirl: Controllable imitative reinforcement learning for vision-based self-driving. InProceedings of the European conference on computer vision (ECCV), pages 584–599,
-
[39]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving.CVPR,
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, and Xinggang Wang. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving.CVPR,
-
[40]
Qingran Lin, Fengwei Yang, and Chaolun Zhu. Harnessing the power of foundation models for accurate material classi- fication.arXiv preprint arXiv:2603.17390, 2026. 3
-
[41]
Haochen Liu, Tianyu Li, Haohan Yang, Li Chen, Caojun Wang, Ke Guo, Haochen Tian, Hongchen Li, Hongyang Li, and Chen Lv. Reinforced refinement with self-aware expan- sion for end-to-end autonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026. 3
work page 2026
-
[42]
Xuefeng Liu, Takuma Yoneda, Rick L Stevens, Matthew R Walter, and Yuxin Chen. Blending imitation and reinforce- ment learning for robust policy improvement.arXiv preprint arXiv:2310.01737, 2023. 2
-
[43]
Yiren Lu, Justin Fu, George Tucker, Xinlei Pan, Eli Bron- stein, Rebecca Roelofs, Benjamin Sapp, Brandyn White, Aleksandra Faust, Shimon Whiteson, Dragomir Anguelov, and Sergey Levine. Imitation is not enough: Robustifying imitation with reinforcement learning for challenging driv- ing scenarios. In2023 IEEE/RSJ International Conference on Intelligent Rob...
work page 2023
-
[44]
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Yanhao Li, et al. Learning what reinforcement learning can’t: Interleaved online fine-tuning for hardest questions. arXiv preprint arXiv:2506.07527, 2025. 2
-
[45]
Shuyao Shang, Yuntao Chen, Yuqi Wang, Yingyan Li, and Zhaoxiang Zhang. Drivedpo: Policy learning via safety dpo for end-to-end autonomous driving.arXiv preprint arXiv:2509.17940, 2025. 7
-
[46]
Hume: Introducing system-2 thinking in visual-language- action model
Haoming Song, Delin Qu, Yuanqi Yao, Qizhi Chen, Qi Lv, Yiwen Tang, Modi Shi, Guanghui Ren, Maoqing Yao, Bin Zhao, et al. Hume: Introducing system-2 thinking in visual- language-action model.arXiv preprint arXiv:2505.21432,
-
[47]
Xiaolong Tang, Meina Kan, Shiguang Shan, and Xilin Chen. Plan-r1: Safe and feasible trajectory planning as language modeling.arXiv preprint arXiv:2505.17659, 2025. 2
-
[48]
Lingguang Wang, ¨Omer S ¸ahin Tas ¸, Marlon Steiner, and Christoph Stiller. Flowdrive: moderated flow matching with data balancing for trajectory planning.arXiv preprint arXiv:2509.21961, 2025. 3
-
[49]
Language-grounded decoupled action representation for robotic manipulation, 2026
Wuding Weng, Tongshu Wu, Liucheng Chen, Siyu Xie, Zheng Wang, Xing Xu, Jingkuan Song, and Heng Tao Shen. Language-grounded decoupled action representation for robotic manipulation, 2026. 3
work page 2026
-
[50]
Pengyuan Wu, Pingrui Zhang, Zhigang Wang, Dong Wang, Bin Zhao, and Xuelong Li. Closed-loop action chunks with dynamic corrections for training-free diffusion policy.arXiv preprint arXiv:2603.01953, 2026. 3
-
[51]
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. Goalflow: Goal- driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1602–1611, 2025. 3
work page 2025
-
[52]
Iterative regularized policy optimization with imper- fect demonstrations
Gong Xudong, Feng Dawei, Kele Xu, Yuanzhao Zhai, Chengkang Yao, Weijia Wang, Bo Ding, and Huaimin Wang. Iterative regularized policy optimization with imper- fect demonstrations. InForty-first International Conference on Machine Learning, 2024. 2
work page 2024
-
[53]
Dongkun Zhang, Jiaming Liang, Ke Guo, Sha Lu, Qi Wang, Rong Xiong, Zhenwei Miao, and Yue Wang. Carplanner: Consistent auto-regressive trajectory planning for large-scale reinforcement learning in autonomous driving. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 17239–17248, 2025. 3
work page 2025
-
[54]
Pingrui Zhang, Yifei Su, Pengyuan Wu, Dong An, Li Zhang, Zhigang Wang, Dong Wang, Yan Ding, Bin Zhao, and Xue- long Li. Cross from left to right brain: Adaptive text dreamer for vision-and-language navigation.arXiv preprint arXiv:2505.20897, 2025. 3
-
[55]
Diffusion-based planning for autonomous driving with flexible guidance
Yinan Zheng, Ruiming Liang, Kexin ZHENG, Jinliang Zheng, Liyuan Mao, Jianxiong Li, Weihao Gu, Rui Ai, Shengbo Eben Li, Xianyuan Zhan, et al. Diffusion-based planning for autonomous driving with flexible guidance. In The Thirteenth International Conference on Learning Rep- resentations, 2025. 3
work page 2025
-
[56]
World4drive: End-to-end au- tonomous driving via intention-aware physical latent world model
Yupeng Zheng, Pengxuan Yang, Zebin Xing, Qichao Zhang, Yuhang Zheng, Yinfeng Gao, Pengfei Li, Teng Zhang, Zhongpu Xia, Peng Jia, et al. World4drive: End-to-end au- tonomous driving via intention-aware physical latent world model. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 28632–28642, 2025. 3
work page 2025
-
[57]
Zewei Zhou, Tianhui Cai, Seth Z. Zhao, Yun Zhang, Zhiyu Huang, Bolei Zhou, and Jiaqi Ma. Autovla: A vision- language-action model for end-to-end autonomous driving with adaptive reasoning and reinforcement fine-tuning.arXiv preprint arXiv:2506.13757, 2025. 2, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.